Python memory management
Have you ever wondered how the data you work with looks in the depths of Python? How variables are created and stored in memory? How and when are they removed? The material, the translation of which we publish, is devoted to researching the depths of Python, in the course of which we will try to find out the features of memory management in this language. After studying this article, you will understand how the low-level mechanisms of computers, especially those related to memory, work. You will understand how Python abstracts low-level operations and learn how it manages memory.

Knowing what is happening in Python will allow you to better understand some of the behaviors of this language. Hopefully, this will give you the opportunity to appreciate the tremendous work that is being done within the implementation of this language that you use so that your programs work exactly as you need.
Computer memory, at the very beginning of work with it, can be represented as an empty book intended for short stories. So far there is nothing on its pages, but very soon authors of stories will appear, each of whom will want to write down his story in this book.
')
Since one story cannot be written on top of another, authors should be attentive to what pages of the book they are writing on. Before writing anything down, they consult with the chief editor. He decides where exactly the authors can write stories.
Since the book we are talking about has been around for quite some time, many of the stories in it are already outdated. If no one reads a certain story or mentions it in their works, this story is removed from the book, freeing up space for new stories.
In general, it can be said that computer memory is very similar to such a book. In fact, continuous memory blocks of fixed length are even called pages, so we believe that the comparison of memory with a book is very successful.
Authors who write their stories in a book are different applications or processes that need to store data in memory. The chief editor, who decides on which particular pages of the book authors can write on, is the mechanism that manages memory. And the one who removes old stories from the book, making room for new ones, can be compared with the garbage collection mechanism.
Memory management is a process during the implementation of which programs write data to memory and read them from it. A memory manager is an entity that determines where exactly an application can place its data in memory. Since the number of fragments of memory that can be allocated to applications is not infinite, just as the number of pages in any book is not infinite, the memory manager servicing applications needs to find free fragments of memory and provide them to applications. This process, in which applications "give out" memory, is called memory allocation.
On the other hand, when certain data is no longer needed, you can delete it, or, in other words, free the memory it occupies. But what exactly is "isolated" and "free" when it comes to memory?
Somewhere in your computer there is a physical device that stores data used by Python programs while they are running. Before a certain Python object is in physical memory, the code has to go through many layers of abstraction.
One of the main such layers, which is located on top of the hardware (such as RAM or hard disk), is the operating system (OS). It executes (or refuses to execute) requests to read data from memory and to write data to memory.
On top of the OS is the application, in our case, one of the implementations of Python (this could be a software package included with your OS or downloaded from python.org ). It is this software package that handles memory management, ensuring the operation of your Python code. The focus of this article is on the algorithms and data structures that Python uses to manage memory.
The reference Python implementation is called CPython. It is written in C. When I first heard about it, it literally took me out of the rut. A programming language that is written in another language? Well, actually, this is not quite the case.
The Python specification is described in this document in plain English. However, by itself, this specification code written in Python, of course, cannot. For this you need something that, following the rules of this specification, will be able to interpret code written in Python.
In addition, you need something that can execute the interpreted code on the computer. The Python reference implementation solves both of these problems. It converts the code into instructions, which are then executed on the virtual machine.
Virtual machines are like ordinary computers created from silicon, metal, and other materials, but they are implemented by software. They are usually busy processing basic instructions, similar to commands written in Assembler .
Python is an interpreted language. Code written in Python is compiled into a set of instructions with which it is convenient to work with a computer, into a so-called byte code . These instructions are interpreted by the virtual machine when you run your program.
Have you ever seen files with the extension
It is important to note that, in addition to CPython, there are other implementations of Python. For example, when using IronPython, Python code is compiled into Microsoft CLR instructions. In Jython, code is compiled into Java bytecode and executed on a Java virtual machine. In the world of Python, there is such a thing as PyPy , but it is worthy of a separate article, so here we just mention it.
For the purposes of this article, I will focus on how memory management mechanisms work in the Python reference implementation, CPython.
It should be noted that although most of what we are going to talk about here will be valid for new versions of Python, this may change in the future. So pay attention to the fact that in this article I am guided by the most recent version of Python at the time of its writing - Python 3.7 .
So CPython is written in C, it interprets Python bytecode. What does this have to do with memory management? The fact is that the algorithms and data structures used for memory management exist in CPython code, written, as already mentioned, in C. In order to understand how memory management works in Python, you first need to understand CPython a little.
The C language in which CPython is written does not have built-in support for object-oriented programming. Because of this, a lot of interesting architectural solutions are used in the CPython code.
You may have heard that everything in Python is an object, even primitive data types like
A structure is a composite data type that can group data of different types. If we compare this with object-oriented programming, the structure is similar to a class that has attributes but no methods.
The reference counter is used to implement the garbage collection mechanism. Another
Each object has its own, unique for such an object, memory allocation mechanism, which knows how to get the memory necessary to store this object. In addition, each object has its own memory freeing mechanism, which also “frees” memory after it is no longer needed.
However, it should be noted that in all these conversations about the allocation and release of memory there is one important factor. The fact is that computer memory is a shared resource. If, at the same time, two different processes try to write something in the same memory area, something bad can happen.
Global Interpreter Lock (GIL) is a solution to a common problem that occurs when working with shared computer resources like memory. When two threads try to simultaneously modify the same resource, they can “collide” with each other. The result will be a mess and none of the streams will reach what they aspired to.
Let's go back to the book analogy again. Imagine that two authors decided without permission that it was their turn to take notes. But they also decided to take notes at the same time and on the same page.
Each of them does not pay attention to what the other is trying to write his own story. Together they begin to write the text on the page. As a result, two stories will be recorded there, one on top of the other, which will make the page completely unreadable.
One solution to this problem is a single global interpreter mechanism that blocks shared resources that a thread is working with. In our example, this is a “mechanism” that “blocks” a book page. Such a mechanism eliminates the situation described above, in which two authors simultaneously write text on the same page.
The GIL mechanism in Python accomplishes this by blocking the entire interpreter. As a result, nothing can interfere with the operation of the current thread. And when CPython is working with memory, it uses GIL to ensure that this work is done safely and efficiently.
This approach has strengths and weaknesses, and GIL is the subject of fierce debate in the Python community. To learn more about GIL you can take a look at this material .
Let us again return to the book analogy and imagine that some of the stories recorded in this book are hopelessly outdated. Nobody reads them, no one mentions them anywhere. And if no one reads any material and does not refer to it in his works, then you can get rid of this material by freeing up space for new texts.
These old, forgotten stories, can be compared with Python objects, whose reference counts are zero. These are the very counters that we talked about when discussing the structure of
Increasing the reference count is done for several reasons. For example, the counter is incremented in the event that an object stored in one variable was written into another variable:
It increases even when the object is passed to some function as an argument:
And here is another example of a situation in which the number in the link counter increases. This happens if the object is included in the list:
Python allows the programmer to find out the current value of the reference count of an object using the
Using it, you need to remember that passing an object to the
In any case, if the object is still used somewhere in the code, its reference count will be greater than 0. When the value of the counter drops to 0, a special function will come in, which “frees” the memory occupied by the object. This memory can then be used by other objects.
Let us now ask ourselves questions about what “freeing memory” is, and how other objects can use this memory. To answer these questions, let's talk about the memory management mechanisms in CPython.
Now we will talk about how the memory architecture is organized in CPython and how the memory management is performed there.
As already mentioned, there are several layers of abstraction between CPython and physical memory. The operating system abstracts the physical memory and creates a virtual memory layer with which applications can work (this also applies to Python).
The virtual memory manager of a specific operating system allocates a fragment of memory for the Python process. The dark gray areas in the next image are those fragments of memory that belong to the Python process.
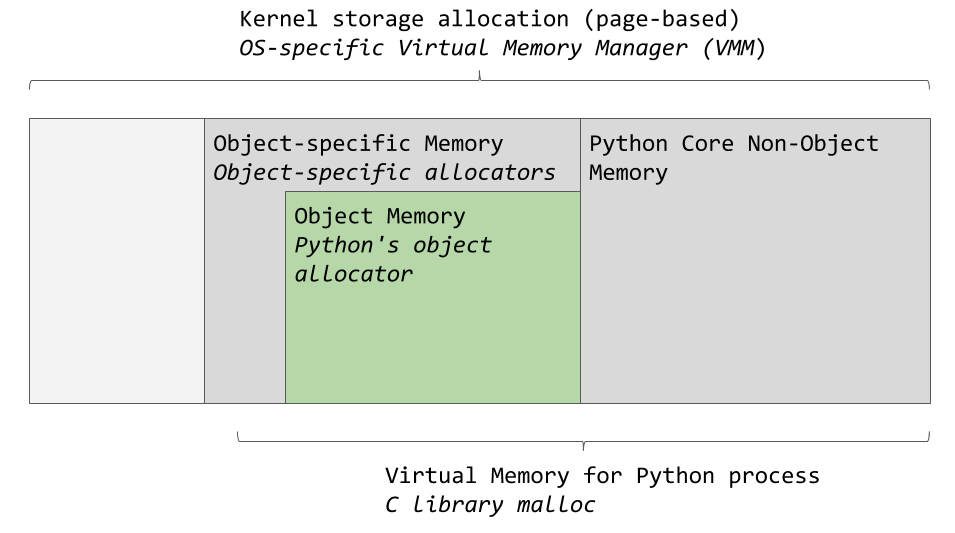
Memory areas used by CPython
Python uses some memory for internal use and for purposes not related to the allocation of memory for objects. Another piece of memory is used to store objects (these are values of
In CPython, there is a facility for allocating memory for objects, which is responsible for allocating memory in the area intended for storing objects. The most interesting thing happens exactly when this mechanism works. It is called when the object needs memory, or in cases when the memory needs to be freed.
Usually adding or deleting data in Python objects like
Comments in the source code describe the memory allocation tool as a “fast, specialized memory allocation tool for small blocks that is designed to be used over generic malloc”. In this case,
Let's discuss the memory allocation strategy used by CPython. First we will talk about the three entities - the so-called blocks (blocks), pools (pool) and arenas (arena), and how they are related to each other.
Arenas are the largest fragments of memory. They are aligned on the edges of the memory pages. The page border is the place where a continuous block of fixed-length memory used by the operating system ends. Python, when working with memory, assumes that the size of the system memory page is 256 KB.
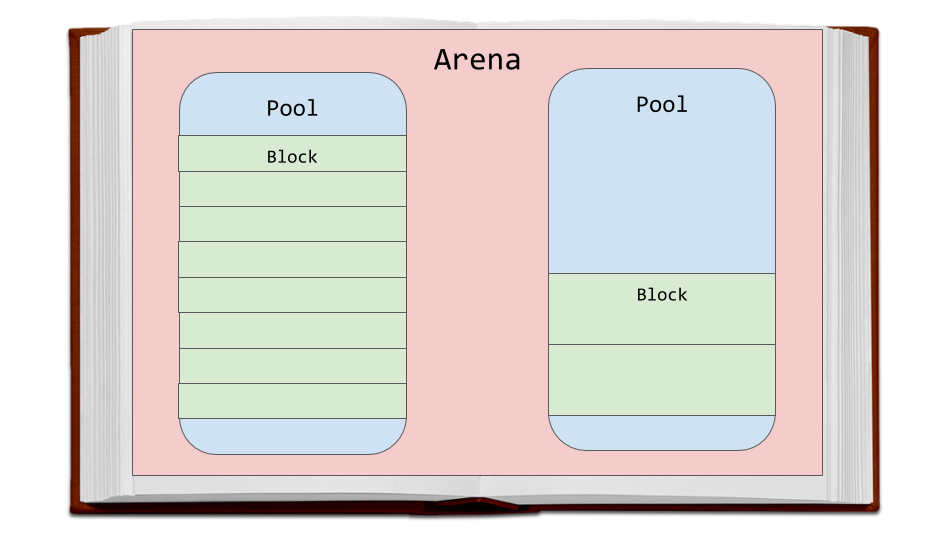
Arenas, pools and blocks
On the arenas there are pools, which are virtual memory pages of 4 KB in size. They resemble the pages of a book from our example. Pools are divided into small blocks of memory.
All blocks in the same pool belong to the same size class. The size class to which the block belongs determines the size of this block, which is selected based on the requested amount of memory. Here is a table taken from the source code, in which the data volumes are shown, the system's requests for saving in the system, the size of the allocated blocks and the identifiers of the size classes.
For example, if a save of 42 bytes is requested, the data will be placed in a 48-byte block.
Pools are made up of blocks belonging to the same size class. Each pool is associated with other pools containing blocks of the same size class with the use of a doubly linked list mechanism. With this approach, the memory allocation algorithm can easily find free space for a block of a given size, even if we are talking about finding free space in different pools.
The
The pools themselves must be in one of three states. Namely, they can be used (
The
Suppose that in a pool in the
Knowledge of this algorithm allows us to understand how the state of the pools changes during operation (and how the size classes change, the blocks belonging to which can be stored in them).
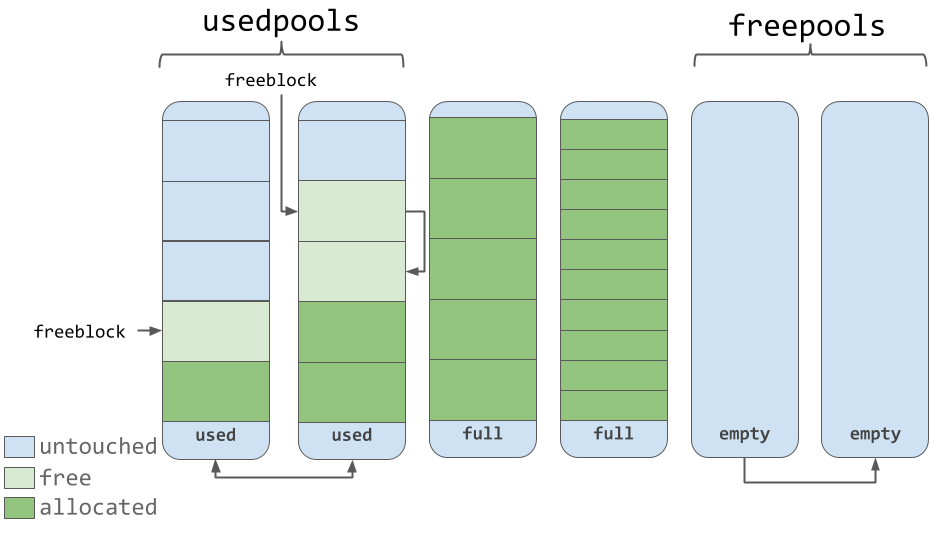
Used, full and empty pools
As can be understood from the previous illustration, pools contain pointers to the “free” blocks of memory that they contain. With regard to working with blocks, you need to note one small feature, which is indicated in the source code. The memory management system used in CPython, at all levels (arenas, pools, blocks), seeks to allocate memory only when absolutely necessary.
This means that pools can contain blocks that are in one of three states:
The
As the memory management tool makes the blocks “free”, they, acquiring the
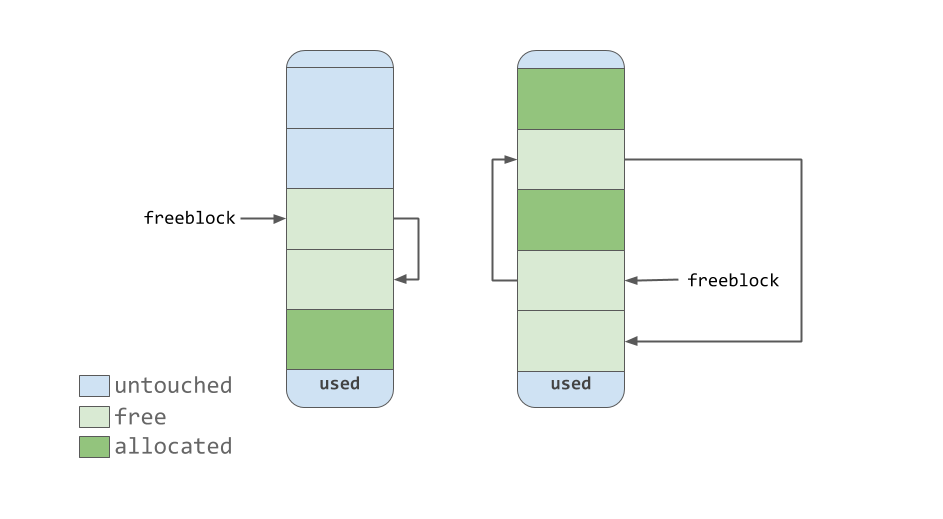
Freeblock single link list
Arenas contain pools. These pools, as already mentioned, can be in
Arenas are organized into a doubly linked list called
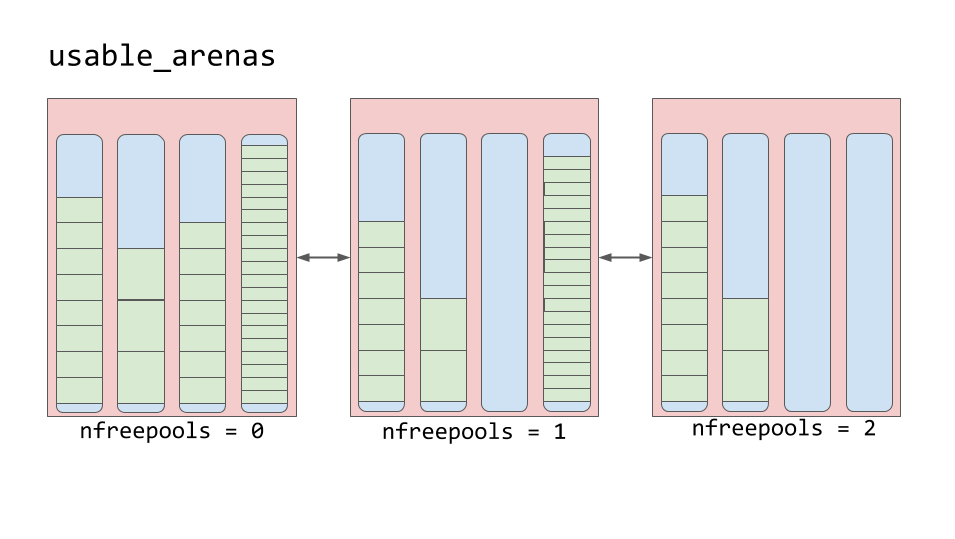
List usable_arenas
This means that the arena, which is stronger than the others filled with data, will be selected for placing new data in it. Why not the other way around? Why not post new data in the arena where the most free space is?
In fact, this feature leads us to the idea of a real liberation of memory. You may have noticed that quite often we used the concept of “freeing memory” here, enclosing it in quotes. The reason this was done is that, although the block can be considered “free”, the memory that it represents is not actually returned to the operating system. The Python process holds this chunk of memory and later uses it to store new data. The real release of memory is the return of its operating system, which can use it.
The arenas are the only entity in the scheme discussed here, the memory represented by which can be truly released. Common sense dictates that the above scheme of working with arenas is designed to allow those arenas that are almost empty to completely empty. With this approach, the fragment of memory that is represented by a completely empty arena can be truly freed, which will reduce the amount of memory consumed by Python.
Here is what you learned by reading this material:
Memory management is an integral part of the work of computer programs. Python solves almost all memory management tasks imperceptibly for a programmer. Python allows the person who writes in this language, to abstract from a set of the fine details concerning work with computers. This gives the programmer the opportunity to work at a higher level, to create his own code, without worrying about where his data is stored.
Dear readers! If you have experience in Python development, please tell us about how you approach the use of memory in your programs. For example, do you want to save it?

Knowing what is happening in Python will allow you to better understand some of the behaviors of this language. Hopefully, this will give you the opportunity to appreciate the tremendous work that is being done within the implementation of this language that you use so that your programs work exactly as you need.
Memory is an empty book
Computer memory, at the very beginning of work with it, can be represented as an empty book intended for short stories. So far there is nothing on its pages, but very soon authors of stories will appear, each of whom will want to write down his story in this book.
')
Since one story cannot be written on top of another, authors should be attentive to what pages of the book they are writing on. Before writing anything down, they consult with the chief editor. He decides where exactly the authors can write stories.
Since the book we are talking about has been around for quite some time, many of the stories in it are already outdated. If no one reads a certain story or mentions it in their works, this story is removed from the book, freeing up space for new stories.
In general, it can be said that computer memory is very similar to such a book. In fact, continuous memory blocks of fixed length are even called pages, so we believe that the comparison of memory with a book is very successful.
Authors who write their stories in a book are different applications or processes that need to store data in memory. The chief editor, who decides on which particular pages of the book authors can write on, is the mechanism that manages memory. And the one who removes old stories from the book, making room for new ones, can be compared with the garbage collection mechanism.
Memory management: the path from hardware to software
Memory management is a process during the implementation of which programs write data to memory and read them from it. A memory manager is an entity that determines where exactly an application can place its data in memory. Since the number of fragments of memory that can be allocated to applications is not infinite, just as the number of pages in any book is not infinite, the memory manager servicing applications needs to find free fragments of memory and provide them to applications. This process, in which applications "give out" memory, is called memory allocation.
On the other hand, when certain data is no longer needed, you can delete it, or, in other words, free the memory it occupies. But what exactly is "isolated" and "free" when it comes to memory?
Somewhere in your computer there is a physical device that stores data used by Python programs while they are running. Before a certain Python object is in physical memory, the code has to go through many layers of abstraction.
One of the main such layers, which is located on top of the hardware (such as RAM or hard disk), is the operating system (OS). It executes (or refuses to execute) requests to read data from memory and to write data to memory.
On top of the OS is the application, in our case, one of the implementations of Python (this could be a software package included with your OS or downloaded from python.org ). It is this software package that handles memory management, ensuring the operation of your Python code. The focus of this article is on the algorithms and data structures that Python uses to manage memory.
Python reference implementation
The reference Python implementation is called CPython. It is written in C. When I first heard about it, it literally took me out of the rut. A programming language that is written in another language? Well, actually, this is not quite the case.
The Python specification is described in this document in plain English. However, by itself, this specification code written in Python, of course, cannot. For this you need something that, following the rules of this specification, will be able to interpret code written in Python.
In addition, you need something that can execute the interpreted code on the computer. The Python reference implementation solves both of these problems. It converts the code into instructions, which are then executed on the virtual machine.
Virtual machines are like ordinary computers created from silicon, metal, and other materials, but they are implemented by software. They are usually busy processing basic instructions, similar to commands written in Assembler .
Python is an interpreted language. Code written in Python is compiled into a set of instructions with which it is convenient to work with a computer, into a so-called byte code . These instructions are interpreted by the virtual machine when you run your program.
Have you ever seen files with the extension
.pyc or folder __pycache__ ? In them is the same byte code, which is interpreted by the virtual machine.It is important to note that, in addition to CPython, there are other implementations of Python. For example, when using IronPython, Python code is compiled into Microsoft CLR instructions. In Jython, code is compiled into Java bytecode and executed on a Java virtual machine. In the world of Python, there is such a thing as PyPy , but it is worthy of a separate article, so here we just mention it.
For the purposes of this article, I will focus on how memory management mechanisms work in the Python reference implementation, CPython.
It should be noted that although most of what we are going to talk about here will be valid for new versions of Python, this may change in the future. So pay attention to the fact that in this article I am guided by the most recent version of Python at the time of its writing - Python 3.7 .
So CPython is written in C, it interprets Python bytecode. What does this have to do with memory management? The fact is that the algorithms and data structures used for memory management exist in CPython code, written, as already mentioned, in C. In order to understand how memory management works in Python, you first need to understand CPython a little.
The C language in which CPython is written does not have built-in support for object-oriented programming. Because of this, a lot of interesting architectural solutions are used in the CPython code.
You may have heard that everything in Python is an object, even primitive data types like
int and str . And this is true at the level of language implementation in CPython. There is a structure called PyObject , which is used by objects created in CPython.A structure is a composite data type that can group data of different types. If we compare this with object-oriented programming, the structure is similar to a class that has attributes but no methods.
PyObject is the ancestor of all Python objects. This structure contains only two fields:ob_refcnt- reference count.ob_typeis a pointer to another type.
The reference counter is used to implement the garbage collection mechanism. Another
PyObject field is a pointer to a specific type of object. This type is represented by another structure that describes a Python object (for example, it can be a dict or int ).Each object has its own, unique for such an object, memory allocation mechanism, which knows how to get the memory necessary to store this object. In addition, each object has its own memory freeing mechanism, which also “frees” memory after it is no longer needed.
However, it should be noted that in all these conversations about the allocation and release of memory there is one important factor. The fact is that computer memory is a shared resource. If, at the same time, two different processes try to write something in the same memory area, something bad can happen.
Global interpreter lock
Global Interpreter Lock (GIL) is a solution to a common problem that occurs when working with shared computer resources like memory. When two threads try to simultaneously modify the same resource, they can “collide” with each other. The result will be a mess and none of the streams will reach what they aspired to.
Let's go back to the book analogy again. Imagine that two authors decided without permission that it was their turn to take notes. But they also decided to take notes at the same time and on the same page.
Each of them does not pay attention to what the other is trying to write his own story. Together they begin to write the text on the page. As a result, two stories will be recorded there, one on top of the other, which will make the page completely unreadable.
One solution to this problem is a single global interpreter mechanism that blocks shared resources that a thread is working with. In our example, this is a “mechanism” that “blocks” a book page. Such a mechanism eliminates the situation described above, in which two authors simultaneously write text on the same page.
The GIL mechanism in Python accomplishes this by blocking the entire interpreter. As a result, nothing can interfere with the operation of the current thread. And when CPython is working with memory, it uses GIL to ensure that this work is done safely and efficiently.
This approach has strengths and weaknesses, and GIL is the subject of fierce debate in the Python community. To learn more about GIL you can take a look at this material .
Garbage collection
Let us again return to the book analogy and imagine that some of the stories recorded in this book are hopelessly outdated. Nobody reads them, no one mentions them anywhere. And if no one reads any material and does not refer to it in his works, then you can get rid of this material by freeing up space for new texts.
These old, forgotten stories, can be compared with Python objects, whose reference counts are zero. These are the very counters that we talked about when discussing the structure of
PyObject .Increasing the reference count is done for several reasons. For example, the counter is incremented in the event that an object stored in one variable was written into another variable:
numbers = [1, 2, 3] # = 1 more_numbers = numbers # = 2 It increases even when the object is passed to some function as an argument:
total = sum(numbers) And here is another example of a situation in which the number in the link counter increases. This happens if the object is included in the list:
matrix = [numbers, numbers, numbers] Python allows the programmer to find out the current value of the reference count of an object using the
sys module. To do this, use the following structure: sys.getrefcount(numbers) Using it, you need to remember that passing an object to the
getfefcount() method increases the value of the counter by 1.In any case, if the object is still used somewhere in the code, its reference count will be greater than 0. When the value of the counter drops to 0, a special function will come in, which “frees” the memory occupied by the object. This memory can then be used by other objects.
Let us now ask ourselves questions about what “freeing memory” is, and how other objects can use this memory. To answer these questions, let's talk about the memory management mechanisms in CPython.
CPython memory management mechanisms
Now we will talk about how the memory architecture is organized in CPython and how the memory management is performed there.
As already mentioned, there are several layers of abstraction between CPython and physical memory. The operating system abstracts the physical memory and creates a virtual memory layer with which applications can work (this also applies to Python).
The virtual memory manager of a specific operating system allocates a fragment of memory for the Python process. The dark gray areas in the next image are those fragments of memory that belong to the Python process.
Memory areas used by CPython
Python uses some memory for internal use and for purposes not related to the allocation of memory for objects. Another piece of memory is used to store objects (these are values of
int , dict , and other types). Please note that this is a simplified scheme. If you want to see the full picture - take a look at the source code of CPython , where everything that we are talking about is happening.In CPython, there is a facility for allocating memory for objects, which is responsible for allocating memory in the area intended for storing objects. The most interesting thing happens exactly when this mechanism works. It is called when the object needs memory, or in cases when the memory needs to be freed.
Usually adding or deleting data in Python objects like
list and int does not allow for one-time processing of very large amounts of information. Therefore, the memory allocator architecture is built with an eye to processing small amounts of data. In addition, this tool tends to not allocate memory until it becomes clear that it is absolutely necessary.Comments in the source code describe the memory allocation tool as a “fast, specialized memory allocation tool for small blocks that is designed to be used over generic malloc”. In this case,
malloc is a C library function for allocating memory.Let's discuss the memory allocation strategy used by CPython. First we will talk about the three entities - the so-called blocks (blocks), pools (pool) and arenas (arena), and how they are related to each other.
Arenas are the largest fragments of memory. They are aligned on the edges of the memory pages. The page border is the place where a continuous block of fixed-length memory used by the operating system ends. Python, when working with memory, assumes that the size of the system memory page is 256 KB.
Arenas, pools and blocks
On the arenas there are pools, which are virtual memory pages of 4 KB in size. They resemble the pages of a book from our example. Pools are divided into small blocks of memory.
All blocks in the same pool belong to the same size class. The size class to which the block belongs determines the size of this block, which is selected based on the requested amount of memory. Here is a table taken from the source code, in which the data volumes are shown, the system's requests for saving in the system, the size of the allocated blocks and the identifiers of the size classes.
| The amount of data in bytes | The volume of the selected block | idx size class |
| 1-8 | eight | 0 |
| 9-16 | sixteen | one |
| 17-24 | 24 | 2 |
| 25-32 | 32 | 3 |
| 33-40 | 40 | four |
| 41-48 | 48 | five |
| 49-56 | 56 | 6 |
| 57-64 | 64 | 7 |
| 65-72 | 72 | eight |
| ... | ... | ... |
| 497-504 | 504 | 62 |
| 505-512 | 512 | 63 |
For example, if a save of 42 bytes is requested, the data will be placed in a 48-byte block.
Pula
Pools are made up of blocks belonging to the same size class. Each pool is associated with other pools containing blocks of the same size class with the use of a doubly linked list mechanism. With this approach, the memory allocation algorithm can easily find free space for a block of a given size, even if we are talking about finding free space in different pools.
The
usedpools list allows you to keep track of all pools that have space for data belonging to a particular size class. When a block of a certain size is requested to be saved, the algorithm checks this list to find a list of pools storing blocks of the required size.The pools themselves must be in one of three states. Namely, they can be used (
used state), they can be filled ( full ) or empty ( empty ). There are free blocks in the pool used, in which data of a suitable size can be stored. All blocks of the filled pool are allocated for the data. An empty pool contains no data, and, if necessary, it can be assigned to store blocks belonging to any size class.The
freepools list stores information about all pools in the empty state. For example, if there are no usedpools records in the usedpools list that store blocks of 8 bytes in size (class with idx 0), then a new pool is initialized in the empty state, intended for storing such blocks. This new pool is added to the usedpools list, and it can be used to fulfill requests to save data received after its creation.Suppose that in a pool in the
full state, some blocks are released. This happens because the data stored in them is no longer needed. This pool will again be in the usedpools list and can be used for data of the corresponding size class.Knowledge of this algorithm allows us to understand how the state of the pools changes during operation (and how the size classes change, the blocks belonging to which can be stored in them).
Blocks
Used, full and empty pools
As can be understood from the previous illustration, pools contain pointers to the “free” blocks of memory that they contain. With regard to working with blocks, you need to note one small feature, which is indicated in the source code. The memory management system used in CPython, at all levels (arenas, pools, blocks), seeks to allocate memory only when absolutely necessary.
This means that pools can contain blocks that are in one of three states:
untouchedis a part of memory that has not yet been allocated.freeis a part of memory that has already been allocated, but was later made “free” by CPython and no longer contains any valuable data.allocatedis the part of memory that contains valuable data.
The
freeblock pointer points to a freeblock -linked list of free blocks of memory. In other words, this is a list of places where you can put data. If more than one free block is needed for data placement, the memory allocator will take several blocks from the pool in the untouched state.As the memory management tool makes the blocks “free”, they, acquiring the
free state, get to the top of the freeblock list. The blocks contained in this list do not necessarily represent a contiguous area of memory, similar to the one shown in the previous figure. They may, in fact, look like the one below.Freeblock single link list
Arenas
Arenas contain pools. These pools, as already mentioned, can be in
used , full or empty states. It should be noted that arenas do not have states similar to those that pools have.Arenas are organized into a doubly linked list called
usable_arenas . This list is sorted by the number of free pools available. The smaller in the arena of free pools - the closer arena to the top of the list.List usable_arenas
This means that the arena, which is stronger than the others filled with data, will be selected for placing new data in it. Why not the other way around? Why not post new data in the arena where the most free space is?
In fact, this feature leads us to the idea of a real liberation of memory. You may have noticed that quite often we used the concept of “freeing memory” here, enclosing it in quotes. The reason this was done is that, although the block can be considered “free”, the memory that it represents is not actually returned to the operating system. The Python process holds this chunk of memory and later uses it to store new data. The real release of memory is the return of its operating system, which can use it.
The arenas are the only entity in the scheme discussed here, the memory represented by which can be truly released. Common sense dictates that the above scheme of working with arenas is designed to allow those arenas that are almost empty to completely empty. With this approach, the fragment of memory that is represented by a completely empty arena can be truly freed, which will reduce the amount of memory consumed by Python.
Results
Here is what you learned by reading this material:
- What is memory management and why is it important.
- How does the reference implementation of Python, Cpython, written in the programming language C.
- What data structures and algorithms are used in CPython for memory management.
Memory management is an integral part of the work of computer programs. Python solves almost all memory management tasks imperceptibly for a programmer. Python allows the person who writes in this language, to abstract from a set of the fine details concerning work with computers. This gives the programmer the opportunity to work at a higher level, to create his own code, without worrying about where his data is stored.
Dear readers! If you have experience in Python development, please tell us about how you approach the use of memory in your programs. For example, do you want to save it?
Source: https://habr.com/ru/post/441568/
All Articles