How to recommend music that almost no one listened to. Yandex report
Almost all recommender systems have difficulty with new or rare content - since only a small fraction of users have interacted with it. In his report at the meeting “Yandex from the inside”, Daniel Burlakov shared a set of tricks that are used in the recommendations of Music, and sorted out the popular Singular Value Decomposition (SVD) model in detail.
- Hello! My name is Daniil Burlakov, I lead a team of recommendations in Media Services. Today I want to talk about some of the problems that we solve when we deal with recommendations in music.
We have a great team that makes recommendations not only for Yandex.Music, but also of all Media Services: this is Film Search, Poster. We solve many more technical problems than recommendations.
')

Today I want to tell you about the central product of Yandex. Music, our most important and favorite product is smart playlists, which, probably, many of you know and listen to.

I will briefly go over what kind of playlists and what content we fill them with.
The playlist of the day was conceived as a set of tracks that will be built for you every day so that you can download and listen to them even where there is no Internet. But it will be great for you, it will be with you, and it should be updated every day and contain something new. What suits you.
Deja vu - more interesting playlist. It is updated once a week, and there will be tracks that you have never listened to, and artists that you practically do not know or don’t know at all. Premiere - a selection of new products of your performers that you might like.

The second product is Yandex. Radio. In 2015, it started, we continue to develop it.
The idea is to allow the user to get a personalized stream of audio music without doing anything. In fact, I pressed one button and got a wonderful stream that will never end and will delight you for hours. He, unlike playlists, can already be tagged. You can, for example, turn on the radio by genre - rock or background music, if you do not want to be distracted while working. Or a fully personalized audio stream — what we call radio “On Your Wave.”

What problems do we face when we make these recommendations? We are faced with two major problems, quite typical of most recommender systems. These are cold users who have just arrived at our service and about which we still do not know anything, and cold content. This includes not only the tracks that have appeared recently, but also a great many rare tracks. There are more than 50 million tracks in the Yandex.Music catalog, not a single user has listened to many of them yet. Therefore, a problem arises: even if the track was released a long time ago, unfortunately, we may not know anything about this track and have no statistics.
Both problems were especially aggravated and became especially important for us, because Yandex.Music became an international service and began to go out in many countries. When entering each country, the local content of this country becomes, first of all, very important. It is clear that when you enter a new country, ignoring local music is rather unpleasant. It is necessary to recommend it, recommend it appropriately and understand the structure of this inner music. In fact, no one in Israel listens to Israeli music, and there are very few statistics on it, even if we have this content.
Let's go through these issues. Let's start with the problem of cold users. How can you solve it?

The first simplest solution is to not recommend anything to cold users. Indeed, the solution is very simple, you can simply ask about the obvious preferences. These are numerous wizards that can be presented to the user.
Before the user gets his first playlist of the day, we ask the user to go through such a wizard, indicating his preferences, a set of genres and artists that he would like.
As a result of this, the first user’s playlist becomes meaningful enough, fits the user, and most likely the user will fall in love with the first playlist.
Unfortunately, this approach can not always be done.

Our second product, Yandex.Radio, was conceived as a product that does not require effort from the user. He just wants to come and turn on the music without doing anything. Moreover, Yandex.Radio is embedded in many other systems, such as Yandex.Drive, where it is rather strange and inconvenient to simply force the user, sitting in the car, to call out a wizard if he first sat there.
Therefore, we went the other way. We start with recommendations, let's say, for the average user, so that the majority of users from the first tracks will get maximum pleasure, and they like the music. And we provide very fast personalization. Unlike the playlist you received and it has been with you all day, all your 60 tracks. And if, for example, we didn’t guess that your favorite genre is popular music (which will be a good guess to start with), then all 60 tracks will not be about you, and it will be sad, and most likely tomorrow you will not come back.
However, if we put the first track of popular music in the radio, and you say that you don’t want to listen to it, we will instantly personalize the next track for you and offer something different, for example, rock or another genre.
Actually, in fact, these two solutions close the problem of cold users to one degree or another.
How could by analogy solve the problem with the content? Solution number one, as well as about users, is not to recommend cold content. But here, unlike users, the content itself does not pick up and does not heat up. Thus, the problem is that if we do not collect statistics about him, then the artist’s new product, which has just been released, will not be delivered, and users who have not seen the new products of their artist will probably be upset.

The situation is similar with international content. We went to a new country, and not to recommend it, in fact, to ignore this content, obviously, does not suit us.
The second solution, if we act completely by analogy, to recommend it somehow on average. The simplest analogy is to slip this content to all users or recommend it as popular music. With the option to recommend on average it is generally not very clear what the average music is. This can be called popular music, but one can hardly say that all music is similar to each other so that it looks like popular music. Therefore, if you meet Beethoven’s composition between popular music, most people are unlikely to be happy to receive it. Therefore, this solution does not suit us either.

What else is there about the tracks? Together with the track itself from the copyright holder comes to us a lot of metadata, such as the genre of the track, artist, album and year of release. Let's go for a run. How could they be used? For example, a genre. The genre is not bad information which allows us to guess more or less. For example, the problem with Beethoven or a chanson that could happen to someone on the radio accidentally solves this: we know the genre of the track, and we are unlikely to send it to those whom it does not suit.
But unfortunately, he does not allow building a good recommendation, because the concept of the genre itself is quite subjective, and it does not allow building any good recommendations based on it. Naturally, there are many subgenres within the genres, and that is what the copyright holders send us.

The second problem is that an ordinary person can usually name a dozen genres, while the right holders send us many thousands of genres, and this is a big enough problem to somehow group them, find similar ones between them, and so on. Unfortunately, this problem is not always solved.
Then, obviously, there are problems with the fact that, unfortunately, right holders are often confused and make mistakes. And we have regular problems and reports about the fact that in radio rock we collect tracks that are popular, and the copyright holder put the rock genre on them. By analogy, we collect jazz and other radio stations. And we regularly have reports of users who ask to correct, because the track has flown on these radio stations with an error.
I want to offer you to guess the genre of the track.
This is not a soundtrack. This is metal. And we have a big problem when they send us such markup.
I propose to go to the next part and talk about the performers of the track. I have already said that there is a problem, that a new artist is coming out, a new track or album, and it should be recommended. In particular, information about the artist will always save us. We know that the user listened to this artist, and we can recommend him appropriately. So we do. However, there also have their own difficulties. For example, if we knew nothing about the performer himself or the user didn’t listen to him, then the information that such a performer of this track doesn’t tell us anything. Similarly with rare tracks. There was a rare track from a rare artist, we learned that now this rare track belongs to him. Unfortunately, again there is not a lot of information that will allow him to somehow recommend to other people who are not familiar with his work.

The second problem is covers and remixes. Again, vile rightholders intervene here and often make mistakes. In particular, when we have an original track and its cover, right holders often don’t bother to name these tracks in different ways, to sign that one of them is a remix, or even to put down different artists when they do.
I want to offer you two tracks in order to understand how different the sound of tracks are, which are called exactly the same. Thus we get two tracks that can be called similar, they have a relatively similar rhythm, a relatively similar text, but they are different. And for us this is the same track, because its name, performer and everything else is exactly the same.
Plus, we have such vile performers who are called composers and are usually put down by the right holders just like a fan. Only one Mozart was recorded more than a million songs. It is clear that for classical music lovers this will not be possible. If the user said that he likes Mozart, then we have millions of tracks, various re-performances of standard classical melodies. As a result, we practically can not do anything about it.

I want to tell you further how this problem could be solved, but first let us weaken our requirements. We wanted to recommend tracks that no one listened to, but now let's think about how to recommend just tracks that would be rare. This is where collaborative filtering comes to the rescue. How does it work and what do we get?
To begin, we need to create a matrix of user ratings, where users will be in rows, there will be tracks in columns, at the intersection of the column and the row there will be its rating. It is clear that for the most part of the matrix we do not know the feedback of users, users could not listen to our entire catalog even close.
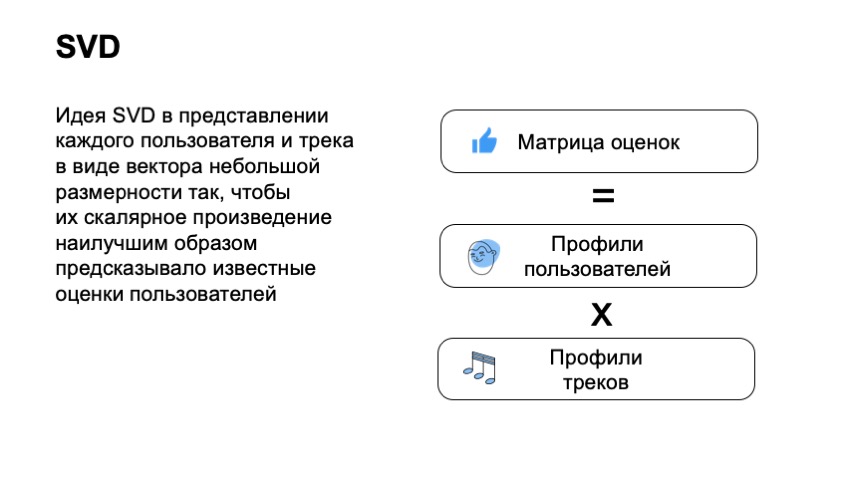
With this matrix, we want the user and the track to associate small, short enough vectors so that the scalar product of the user vector and the item vector predicts well the user rating. Thus, we get that for each item and for each user, we have to find two vectors so that their final product predicts the best for our estimate. For example, if in this case we would say that the user liked the track - this is 1, if he didn’t like it - 0. And in this case, we can actually apply the standard technique, SVD decomposition, and get the optimal vectors for users and tracks.

What does this give us? this gives us the next big plus. For most of the approaches, we cannot say that the two tracks are similar if no one listened to them together. Usually a significant part of the approaches is based on the fact that we have some users who have interacted with item A and B, and we see that they are similar as a result of this. SVD collaborative filtering allows us to do this even if no user has listened to two tracks together. They allow you to evaluate it pretty well. This is the first plus.
What does this give us? Having a track vector, we can recommend it to a much wider circle of people, and recommend much less popular tracks. And the main plus, we also get a vector representation of the tracks, which is very convenient to work with, with which you can quickly search for similar tracks.
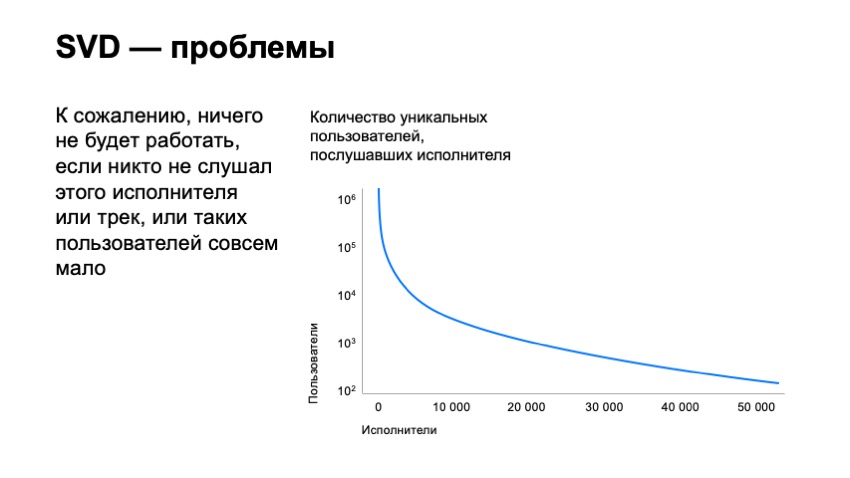
However, this does not solve all our problems. we have only slightly pushed the bar for the number of tracks that we can recommend. If we build a graph of the number of users who listened to the performers, sort the performers according to their popularity, we will see that millions of users listen to the top performers on our service. If we look at the 10 thousandth position of these artists, there will be only thousands of users. If we even look at the 50,000th artist, there will be only a hundred users. It is clear that his tracks will have only dozens of users who have listened to it, which actually makes it impossible to recommend them, since the SVD vector for such tracks will be extremely unstable and will not work.
How can we try to solve this? What do we want?
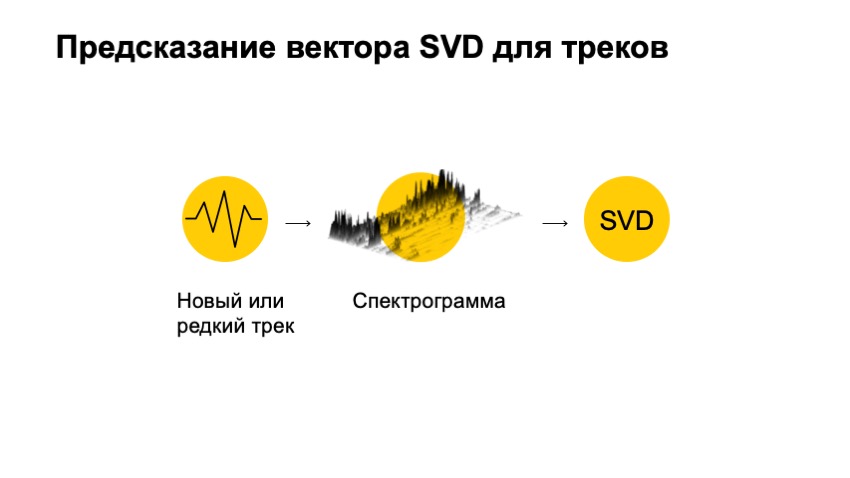
We want to take some rare, new track about which we know nothing, for example, a rare track from Israel, and we want to get some kind of vector representation for it that would be very similar to our SVD vector, which is very convenient to work with. and make recommendations.
The only thing that we did not consider is the audio of this track itself. Thanks to the audio, we could recommend the tracks. As if to us, using audio tracks, to receive vector SVD. First of all, we want to do a little transformation.
What is, in fact, audio? You can imagine a graph of stress. In any case, this is a one-dimensional set of numbers, with which it is rather inconvenient to work, it is very large and long, it represents little sense in itself. But we can check his spectrum, make Fourier transforms on it, very briefly, to see how similar it is to a particular type of sinusoid. How he looks like some of the sinusoids. And see how many sine waves in this graph, and do the same for each of the frequencies.
If we do this for the entire track as a whole, of course, we will get some information, but very little, it will speak very little, because, for example, transitions between parts of the track are very important for music, whereas in the spectrum we will to have an indirect view on the change of very large frequencies, which should be related to seconds, minutes, and this is rather inconvenient and poorly representable in the form of a spectrum.
Therefore, we go further and cut the track into small pieces. In each piece we do this transformation. As a result, we get such a picture, I drew it in three-dimensional form, so that it was more visible that we unwrapped the frequencies on the plane, and the energy, which was at that frequency at that time, in height. And got the so-called spectrogram.
How would we use this spectrogram to get the vector SVD? The answer nowadays is quite banal: let's take a neural network and train it to predict the SVD vector.
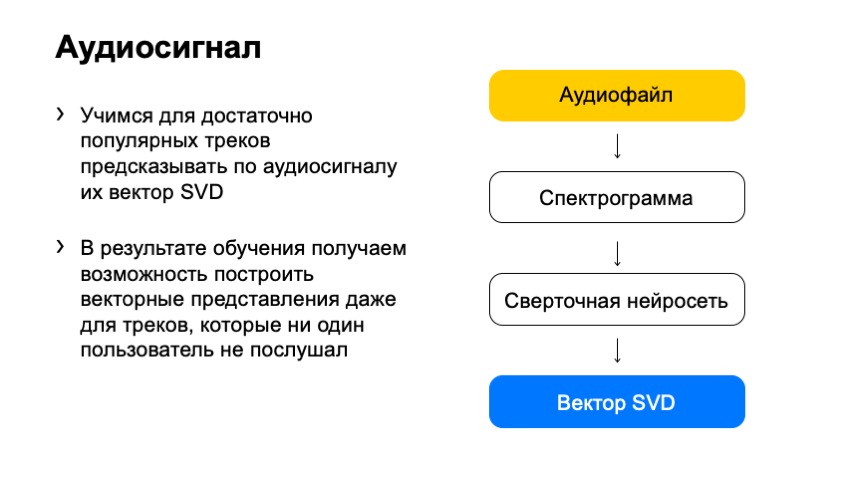
So we did. What have we chosen as training? Those tracks SVD, the vector of which we know for sure. We specially selected popular tracks, the feedback of which was large enough so that the SVD vector was already completely quiet, and we could clearly calculate it. And - they trained the neural network to predict these vectors.
What we got in the end? A network that can take any track already and predict its SVD vector. Got a very simple solution that works very well.
I want to show an example of a pair of tracks that we pulled out. One of these tracks is quite popular, and its SVD vector could be recognized quite accurately, and the second one is very unpopular. I want to suggest to guess which of these tracks is less popular and which one is more popular.
First track:
Second track:
When we applied it in production, we received a lot of great reviews. One of the playlists, Déjà Vu, where we have to embed tracks that the user did not listen to, organize for the user of discovery, improved significantly after we were able to apply this technology.
Of course, we applied this when entering new countries and also received many positive reviews. They noted that playlists are well personalized. In addition, the editors in Israel were quite surprised that the Russian service in Israel recommends not Russian performers in large quantities, but local and international music.

About the numbers that we managed to achieve. Most importantly, we wanted to achieve the number of new products for users in the audio stream, so that it becomes more diverse. , . , : . . . 1,5% . , . , - , , . , , .
: . , , , . . Thanks for attention.
Plus, we have such performers who are called composers and are usually put down by the owners simply as a fan. Only one Mozart was recorded more than a million songs.
- Hello! My name is Daniil Burlakov, I lead a team of recommendations in Media Services. Today I want to talk about some of the problems that we solve when we deal with recommendations in music.
We have a great team that makes recommendations not only for Yandex.Music, but also of all Media Services: this is Film Search, Poster. We solve many more technical problems than recommendations.
')
Today I want to tell you about the central product of Yandex. Music, our most important and favorite product is smart playlists, which, probably, many of you know and listen to.
I will briefly go over what kind of playlists and what content we fill them with.
The playlist of the day was conceived as a set of tracks that will be built for you every day so that you can download and listen to them even where there is no Internet. But it will be great for you, it will be with you, and it should be updated every day and contain something new. What suits you.
Deja vu - more interesting playlist. It is updated once a week, and there will be tracks that you have never listened to, and artists that you practically do not know or don’t know at all. Premiere - a selection of new products of your performers that you might like.
The second product is Yandex. Radio. In 2015, it started, we continue to develop it.
The idea is to allow the user to get a personalized stream of audio music without doing anything. In fact, I pressed one button and got a wonderful stream that will never end and will delight you for hours. He, unlike playlists, can already be tagged. You can, for example, turn on the radio by genre - rock or background music, if you do not want to be distracted while working. Or a fully personalized audio stream — what we call radio “On Your Wave.”
What problems do we face when we make these recommendations? We are faced with two major problems, quite typical of most recommender systems. These are cold users who have just arrived at our service and about which we still do not know anything, and cold content. This includes not only the tracks that have appeared recently, but also a great many rare tracks. There are more than 50 million tracks in the Yandex.Music catalog, not a single user has listened to many of them yet. Therefore, a problem arises: even if the track was released a long time ago, unfortunately, we may not know anything about this track and have no statistics.
Both problems were especially aggravated and became especially important for us, because Yandex.Music became an international service and began to go out in many countries. When entering each country, the local content of this country becomes, first of all, very important. It is clear that when you enter a new country, ignoring local music is rather unpleasant. It is necessary to recommend it, recommend it appropriately and understand the structure of this inner music. In fact, no one in Israel listens to Israeli music, and there are very few statistics on it, even if we have this content.
Let's go through these issues. Let's start with the problem of cold users. How can you solve it?
The first simplest solution is to not recommend anything to cold users. Indeed, the solution is very simple, you can simply ask about the obvious preferences. These are numerous wizards that can be presented to the user.
Before the user gets his first playlist of the day, we ask the user to go through such a wizard, indicating his preferences, a set of genres and artists that he would like.
As a result of this, the first user’s playlist becomes meaningful enough, fits the user, and most likely the user will fall in love with the first playlist.
Unfortunately, this approach can not always be done.
Our second product, Yandex.Radio, was conceived as a product that does not require effort from the user. He just wants to come and turn on the music without doing anything. Moreover, Yandex.Radio is embedded in many other systems, such as Yandex.Drive, where it is rather strange and inconvenient to simply force the user, sitting in the car, to call out a wizard if he first sat there.
Therefore, we went the other way. We start with recommendations, let's say, for the average user, so that the majority of users from the first tracks will get maximum pleasure, and they like the music. And we provide very fast personalization. Unlike the playlist you received and it has been with you all day, all your 60 tracks. And if, for example, we didn’t guess that your favorite genre is popular music (which will be a good guess to start with), then all 60 tracks will not be about you, and it will be sad, and most likely tomorrow you will not come back.
However, if we put the first track of popular music in the radio, and you say that you don’t want to listen to it, we will instantly personalize the next track for you and offer something different, for example, rock or another genre.
Actually, in fact, these two solutions close the problem of cold users to one degree or another.
How could by analogy solve the problem with the content? Solution number one, as well as about users, is not to recommend cold content. But here, unlike users, the content itself does not pick up and does not heat up. Thus, the problem is that if we do not collect statistics about him, then the artist’s new product, which has just been released, will not be delivered, and users who have not seen the new products of their artist will probably be upset.
The situation is similar with international content. We went to a new country, and not to recommend it, in fact, to ignore this content, obviously, does not suit us.
The second solution, if we act completely by analogy, to recommend it somehow on average. The simplest analogy is to slip this content to all users or recommend it as popular music. With the option to recommend on average it is generally not very clear what the average music is. This can be called popular music, but one can hardly say that all music is similar to each other so that it looks like popular music. Therefore, if you meet Beethoven’s composition between popular music, most people are unlikely to be happy to receive it. Therefore, this solution does not suit us either.
What else is there about the tracks? Together with the track itself from the copyright holder comes to us a lot of metadata, such as the genre of the track, artist, album and year of release. Let's go for a run. How could they be used? For example, a genre. The genre is not bad information which allows us to guess more or less. For example, the problem with Beethoven or a chanson that could happen to someone on the radio accidentally solves this: we know the genre of the track, and we are unlikely to send it to those whom it does not suit.
But unfortunately, he does not allow building a good recommendation, because the concept of the genre itself is quite subjective, and it does not allow building any good recommendations based on it. Naturally, there are many subgenres within the genres, and that is what the copyright holders send us.
The second problem is that an ordinary person can usually name a dozen genres, while the right holders send us many thousands of genres, and this is a big enough problem to somehow group them, find similar ones between them, and so on. Unfortunately, this problem is not always solved.
Then, obviously, there are problems with the fact that, unfortunately, right holders are often confused and make mistakes. And we have regular problems and reports about the fact that in radio rock we collect tracks that are popular, and the copyright holder put the rock genre on them. By analogy, we collect jazz and other radio stations. And we regularly have reports of users who ask to correct, because the track has flown on these radio stations with an error.
I want to offer you to guess the genre of the track.
Listen to the track
This is not a soundtrack. This is metal. And we have a big problem when they send us such markup.
I propose to go to the next part and talk about the performers of the track. I have already said that there is a problem, that a new artist is coming out, a new track or album, and it should be recommended. In particular, information about the artist will always save us. We know that the user listened to this artist, and we can recommend him appropriately. So we do. However, there also have their own difficulties. For example, if we knew nothing about the performer himself or the user didn’t listen to him, then the information that such a performer of this track doesn’t tell us anything. Similarly with rare tracks. There was a rare track from a rare artist, we learned that now this rare track belongs to him. Unfortunately, again there is not a lot of information that will allow him to somehow recommend to other people who are not familiar with his work.
The second problem is covers and remixes. Again, vile rightholders intervene here and often make mistakes. In particular, when we have an original track and its cover, right holders often don’t bother to name these tracks in different ways, to sign that one of them is a remix, or even to put down different artists when they do.
I want to offer you two tracks in order to understand how different the sound of tracks are, which are called exactly the same. Thus we get two tracks that can be called similar, they have a relatively similar rhythm, a relatively similar text, but they are different. And for us this is the same track, because its name, performer and everything else is exactly the same.
Plus, we have such vile performers who are called composers and are usually put down by the right holders just like a fan. Only one Mozart was recorded more than a million songs. It is clear that for classical music lovers this will not be possible. If the user said that he likes Mozart, then we have millions of tracks, various re-performances of standard classical melodies. As a result, we practically can not do anything about it.
I want to tell you further how this problem could be solved, but first let us weaken our requirements. We wanted to recommend tracks that no one listened to, but now let's think about how to recommend just tracks that would be rare. This is where collaborative filtering comes to the rescue. How does it work and what do we get?
To begin, we need to create a matrix of user ratings, where users will be in rows, there will be tracks in columns, at the intersection of the column and the row there will be its rating. It is clear that for the most part of the matrix we do not know the feedback of users, users could not listen to our entire catalog even close.
With this matrix, we want the user and the track to associate small, short enough vectors so that the scalar product of the user vector and the item vector predicts well the user rating. Thus, we get that for each item and for each user, we have to find two vectors so that their final product predicts the best for our estimate. For example, if in this case we would say that the user liked the track - this is 1, if he didn’t like it - 0. And in this case, we can actually apply the standard technique, SVD decomposition, and get the optimal vectors for users and tracks.
What does this give us? this gives us the next big plus. For most of the approaches, we cannot say that the two tracks are similar if no one listened to them together. Usually a significant part of the approaches is based on the fact that we have some users who have interacted with item A and B, and we see that they are similar as a result of this. SVD collaborative filtering allows us to do this even if no user has listened to two tracks together. They allow you to evaluate it pretty well. This is the first plus.
What does this give us? Having a track vector, we can recommend it to a much wider circle of people, and recommend much less popular tracks. And the main plus, we also get a vector representation of the tracks, which is very convenient to work with, with which you can quickly search for similar tracks.
However, this does not solve all our problems. we have only slightly pushed the bar for the number of tracks that we can recommend. If we build a graph of the number of users who listened to the performers, sort the performers according to their popularity, we will see that millions of users listen to the top performers on our service. If we look at the 10 thousandth position of these artists, there will be only thousands of users. If we even look at the 50,000th artist, there will be only a hundred users. It is clear that his tracks will have only dozens of users who have listened to it, which actually makes it impossible to recommend them, since the SVD vector for such tracks will be extremely unstable and will not work.
How can we try to solve this? What do we want?
We want to take some rare, new track about which we know nothing, for example, a rare track from Israel, and we want to get some kind of vector representation for it that would be very similar to our SVD vector, which is very convenient to work with. and make recommendations.
The only thing that we did not consider is the audio of this track itself. Thanks to the audio, we could recommend the tracks. As if to us, using audio tracks, to receive vector SVD. First of all, we want to do a little transformation.
What is, in fact, audio? You can imagine a graph of stress. In any case, this is a one-dimensional set of numbers, with which it is rather inconvenient to work, it is very large and long, it represents little sense in itself. But we can check his spectrum, make Fourier transforms on it, very briefly, to see how similar it is to a particular type of sinusoid. How he looks like some of the sinusoids. And see how many sine waves in this graph, and do the same for each of the frequencies.
If we do this for the entire track as a whole, of course, we will get some information, but very little, it will speak very little, because, for example, transitions between parts of the track are very important for music, whereas in the spectrum we will to have an indirect view on the change of very large frequencies, which should be related to seconds, minutes, and this is rather inconvenient and poorly representable in the form of a spectrum.
Therefore, we go further and cut the track into small pieces. In each piece we do this transformation. As a result, we get such a picture, I drew it in three-dimensional form, so that it was more visible that we unwrapped the frequencies on the plane, and the energy, which was at that frequency at that time, in height. And got the so-called spectrogram.
How would we use this spectrogram to get the vector SVD? The answer nowadays is quite banal: let's take a neural network and train it to predict the SVD vector.
So we did. What have we chosen as training? Those tracks SVD, the vector of which we know for sure. We specially selected popular tracks, the feedback of which was large enough so that the SVD vector was already completely quiet, and we could clearly calculate it. And - they trained the neural network to predict these vectors.
What we got in the end? A network that can take any track already and predict its SVD vector. Got a very simple solution that works very well.
I want to show an example of a pair of tracks that we pulled out. One of these tracks is quite popular, and its SVD vector could be recognized quite accurately, and the second one is very unpopular. I want to suggest to guess which of these tracks is less popular and which one is more popular.
First track:
Second track:
Answer
The first track is more popular. If you look at the number of listeners who knew about this track and were able to find it themselves, without the help of recommendations, the first track could be found by more than 1000 users, and the second - only 10. And how we applied our technology, we could not even try to recommend this track, because there was nothing to cling to for recommendations. We could only offer it to these 10 users.
The first track is more popular. If you look at the number of listeners who knew about this track and were able to find it themselves, without the help of recommendations, the first track could be found by more than 1000 users, and the second - only 10. And how we applied our technology, we could not even try to recommend this track, because there was nothing to cling to for recommendations. We could only offer it to these 10 users.
When we applied it in production, we received a lot of great reviews. One of the playlists, Déjà Vu, where we have to embed tracks that the user did not listen to, organize for the user of discovery, improved significantly after we were able to apply this technology.
Of course, we applied this when entering new countries and also received many positive reviews. They noted that playlists are well personalized. In addition, the editors in Israel were quite surprised that the Russian service in Israel recommends not Russian performers in large quantities, but local and international music.
About the numbers that we managed to achieve. Most importantly, we wanted to achieve the number of new products for users in the audio stream, so that it becomes more diverse. , . , : . . . 1,5% . , . , - , , . , , .
: . , , , . . Thanks for attention.
Source: https://habr.com/ru/post/441586/
All Articles