Bash scripts, part 7: sed and word processing
Bash scripts: start
Bash scripts, part 2: loops
Bash scripts, part 3: command line options and keys
Bash scripts, part 4: input and output
Bash Scripts, Part 5: Signals, Background Tasks, Script Management
Bash scripts, part 6: functions and library development
Bash scripts, part 7: sed and word processing
Bash scripts, part 8: awk data processing language
Bash scripts, part 9: regular expressions
Bash scripts, part 10: practical examples
Bash scripts, part 11: expect and automate interactive utilities
Last time we talked about functions in bash scripts, in particular, how to call them from the command line. Our topic today is a very useful tool for processing string data - a Linux utility called sed. It is often used to work with texts that look like log files, configuration files, and other files.

If you, in bash-scripts, somehow process the data, you will not interfere with the sed and gawk tools. Here we will focus on sed and on working with texts, as this is a very important step in our journey through the vast expanses of bash script development.

')
Now we will analyze the basics of working with sed, as well as consider more than three dozen examples of using this tool.
Sed basics
The sed utility is called a stream text editor. In interactive text editors, like nano, they work with texts using the keyboard, editing files, adding, deleting, or changing texts. Sed allows you to edit data streams based on the developer-defined rule sets. Here is the scheme of calling this command:
$ sed options file By default, sed applies the rules specified when invoked, expressed as a set of commands, to
STDIN . This allows data to be transmitted directly to sed.For example:
$ echo "This is a test" | sed 's/test/another test/' That's what happens when you run this command.

A simple example of calling sed
In this case, sed replaces the word “test” in the line passed for processing with the words “another test”. For the design of the rules for processing text enclosed in quotes, use forward slashes. In our case, a command of the form
s/pattern1/pattern2/ . The letter "s" is an abbreviation of the word "substitute", that is - we have a replacement team. Sed, executing this command, will scan the transferred text and replace the fragments found in it (about which pattern1 , pattern2 talk below), corresponding to pattern1 , with pattern2 .The above is a primitive example of using sed, which is needed to get you up to speed. In fact, sed can be used in much more complex word processing scenarios, for example, for working with files.
Below is a file containing a fragment of text, and the results of its processing with such a command:
$ sed 's/test/another test' ./myfile 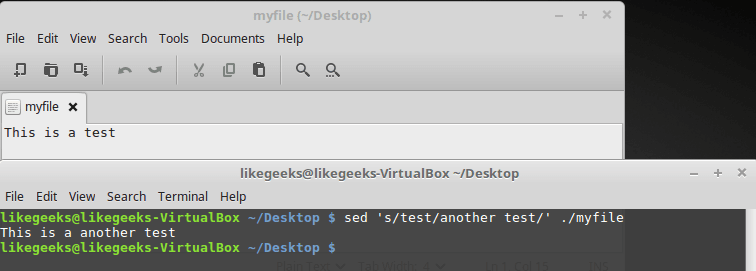
Text file and its processing results
This is the same approach that we used above, but now sed processes the text stored in the file. At the same time, if the file is large enough, you can see that sed processes the data in chunks and displays what is processed on the screen, without waiting for the entire file to be processed.
Sed does not change the data in the file being processed. The editor reads the file, processes the read, and sends what came out in
STDOUT . In order to make sure that the source file has not changed, it is enough to open it after it has been transferred to sed. If necessary, the sed output can be redirected to a file, it is possible to overwrite the old file. If you are familiar with one of the previous materials in this series, where it comes to redirecting input and output streams, you may well be able to do this.Executing command sets when calling sed
To perform multiple actions on data, use the
-e switch when invoking sed. For example, here's how to organize the replacement of two pieces of text: $ sed -e 's/This/That/; s/test/another test/' ./myfile 
Using the -e switch when calling sed
Both commands are applied to each line of text from a file. They should be separated by a semicolon, while there should be no space between the end of the command and the semicolon.
To enter several text processing templates when you call sed, you can, after entering the first single quote, press Enter, and then enter each rule from a new line, without forgetting about the closing quote:
$ sed -e ' > s/This/That/ > s/test/another test/' ./myfile That's what happens after the command presented in this form will be executed.

Another way to work with sed
Reading commands from a file
If there are many sed commands with which you need to process the text, it is usually best to pre-write them to a file. To specify a sed file containing commands, use the
-f :Here are the contents of the
mycommands file: s/This/That/ s/test/another test/ Call sed, passing the editor a file with commands and a file for processing:
$ sed -f mycommands myfile The result of calling such a command is similar to that obtained in the previous examples.

Using the command file when calling sed
Replacement team flags
Take a close look at the following example.
$ sed 's/test/another test/' myfile This is what the file contains and what will be obtained after it is processed by sed.

Source file and its processing results
The replace command normally processes a file consisting of several lines, but only the first occurrences of the required text fragment in each line are replaced. In order to replace all occurrences of a pattern, you need to use the appropriate flag.
The scheme of the replacement command when using flags looks like this:
s/pattern/replacement/flags The execution of this command can be modified in several ways.
- When transmitting the number, the sequence number of the occurrence of the pattern in the string is taken into account.
- The
gflag indicates that you need to process all occurrences of the pattern that are in the string. - The
pflag indicates that the contents of the source string should be displayed. - A
w fileflag tells the command to write text processing results to a file.
Consider using the first variant of the replacement command, indicating the position of the replaced occurrence of the desired fragment:
$ sed 's/test/another test/2' myfile 
Calling a replacement command indicating the position of the fragment being replaced
Here we indicated the number 2 as the replacement flag. This led to the fact that only the second occurrence of the search pattern in each line was replaced. Now let's test the global replacement flag -
g : $ sed 's/test/another test/g' myfile As can be seen from the output, this command replaced all occurrences of the pattern in the text.

Global replacement
The replace command
p flag allows you to output lines that match, and the -n specified when you call sed suppresses normal output: $ sed -n 's/test/another test/p' myfile As a result, when you run sed in such a configuration, only lines (in our case, one line) are displayed on the screen in which the specified text fragment is found.

Using the replace command flag p
We use the
w flag, which allows you to save the text processing results to a file: $ sed 's/test/another test/w output' myfile 
Saving text processing results to a file
It is clearly seen that during the work of the command, the data is output to STDOUT , while the processed lines are written to the file whose name is specified after
w .Delimiter characters
Imagine replacing
/bin/bash with /bin/csh in the /etc/passwd . The task is not so difficult: $ sed 's/\/bin\/bash/\/bin\/csh/' /etc/passwd However, this does not look very good. The thing is that since the forward slashes are used as separator characters, the same characters in the transmitted sed lines have to be escaped. As a result, the readability of the command suffers.
Fortunately, sed allows us to set the delimiter characters ourselves for use in the replace command. The separator is the first character that will be encountered after
s : $ sed 's!/bin/bash!/bin/csh!' /etc/passwd In this case, an exclamation point is used as a separator, as a result, the code is easier to read and it looks much tidier than before.
Select text fragments for processing
So far, we have called sed to process the entire data stream passed to the editor. In some cases, with the help of sed, it is necessary to process only some part of the text — some specific line or group of lines. To achieve this goal, you can use two approaches:
- Set a limit on the number of lines to be processed.
- Specify the filter corresponding to the line to be processed.
Consider the first approach. There are two possible options. The first, discussed below, provides for the indication of the number of one line to be processed:
$ sed '2s/test/another test/' myfile 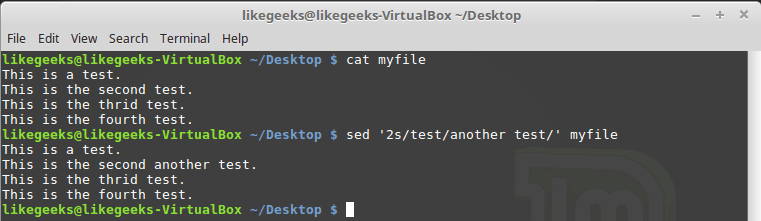
Processing only one line whose number is set when you call sed
The second option is a range of lines:
$ sed '2,3s/test/another test/' myfile 
Row range processing
In addition, you can call the replace command so that the file is processed starting from a certain line to the end:
$ sed '2,$s/test/another test/' myfile 
File processing starting from the second line to the end
In order to process only the rows corresponding to the specified filter using the replace command, the command must be called as follows:
$ sed '/likegeeks/s/bash/csh/' /etc/passwd By analogy with what was considered above, the pattern is passed before the command name
s .
Processing strings matching the filter
Here we used a very simple filter. In order to fully reveal the possibilities of this approach, you can use regular expressions. We will talk about them in one of the following materials in this series.
Delete rows
The sed utility is not only suitable for replacing some character strings in strings with others. With its help, namely, using the
d command, you can delete lines from the text stream.The command call looks like this:
$ sed '3d' myfile We want the third line to be removed from the text. Please note that this is not a file. The file will remain unchanged, the deletion will only affect the output that will form sed.
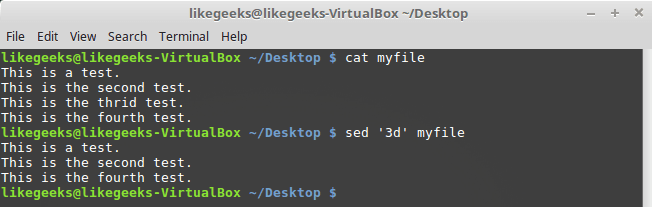
Delete third row
If the
d command does not specify the line number to be deleted, all the lines in the stream will be deleted.Here's how to apply the
d command to a range of lines: $ sed '2,3d' myfile 
Delete row range
And here is how to delete lines starting from the given one - and to the end of the file:
$ sed '3,$d' myfile 
Delete lines to end of file
Lines can also be deleted by pattern:
$ sed '/test/d' myfile 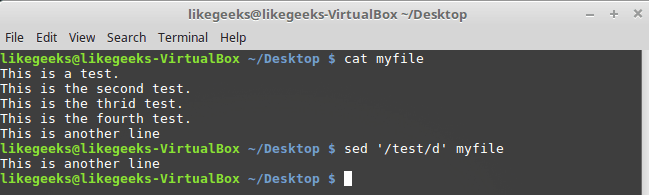
Delete rows by pattern
When you call
d you can specify a couple of patterns - the lines will be deleted in which the pattern will be found, and the lines that are between them: $ sed '/second/,/fourth/d' myfile 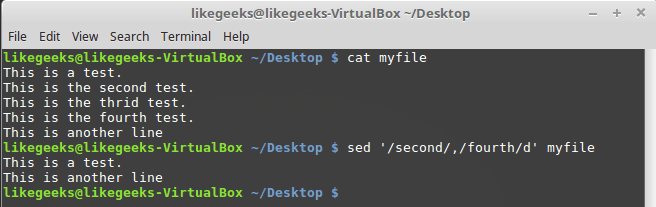
Delete a range of rows using templates
Insert text to stream
With sed, you can insert data into a text stream using the
i and a commands:- The
icommand adds a new line before the specified one. - The
acommand adds a new line after the specified one.
Consider an example of using the
i command: $ echo "Another test" | sed 'i\First test ' 
Command i
Now take a look at the
a command: $ echo "Another test" | sed 'a\First test ' 
Command a
As you can see, these commands add text before or after the data from the stream. What if you need to add a line somewhere in the middle?
Here we will be helped by the indication of the number of the reference line in the stream, or pattern. Note that addressing strings as a range does not work here. Call the
i command, specifying the line number before which you need to insert a new line: $ sed '2i\This is the inserted line.' myfile 
The i command with the reference line number
Do the same with the
a command: $ sed '2a\This is the appended line.' myfile 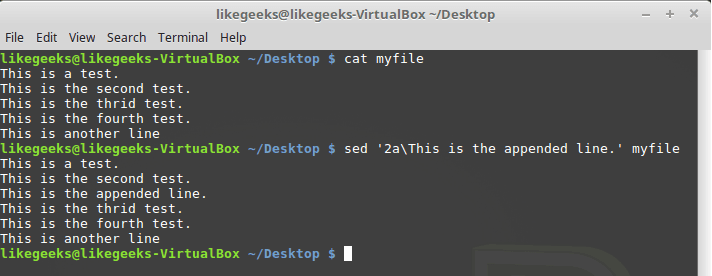
Command a with reference line number
Notice the difference between the
i and a commands. The first inserts a new line to the specified, the second - after.Replacing strings
The
c command allows you to change the contents of a whole line of text in a data stream. When calling it, you need to specify the line number, instead of which new data should be added to the stream: $ sed '3c\This is a modified line.' myfile 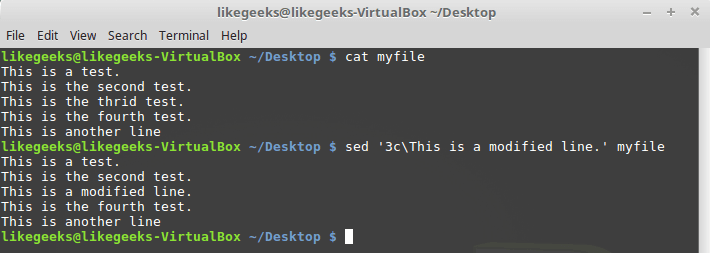
Replacing the entire string
If you use a template in the form of a plain text or a regular expression, all the lines matching the pattern will be replaced:
$ sed '/This is/c This is a changed line of text.' myfile 
Replacing strings by pattern
Character replacement
The
y command works with individual characters, replacing them in accordance with the data passed to it when it is called: $ sed 'y/123/567/' myfile 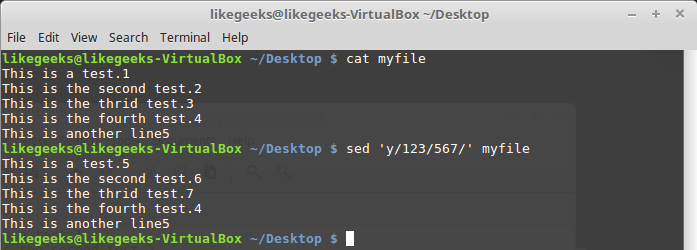
Character replacement
Using this command, you need to take into account that it applies to the entire text flow, you cannot limit it to specific occurrences of characters.
Display line numbers
If you call sed using the
= command, the utility displays line numbers in the data stream: $ sed '=' myfile 
Display line numbers
The stream editor output line numbers in front of their contents.
If you pass a pattern to this command and use the sed
-n key, only line numbers matching the pattern will be output: $ sed -n '/test/=' myfile 
Display line numbers matching the pattern
Reading data to insert from file
Above, we looked at techniques for inserting data into a stream, indicating what needs to be inserted, right when you call sed. As a data source, you can use the file. To do this, use the
r command, which allows you to insert data from the specified file into the stream. When you call it, you can specify the line number after which you want to insert the contents of the file, or a template.Consider an example:
$ sed '3r newfile' myfile 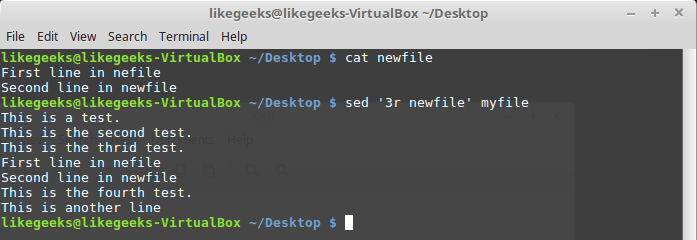
Insert file into stream
Here the contents of the file
newfile were inserted after the third line of the file myfile .Here's what happens if you apply a pattern when invoking the
r command: $ sed '/test/r newfile' myfile 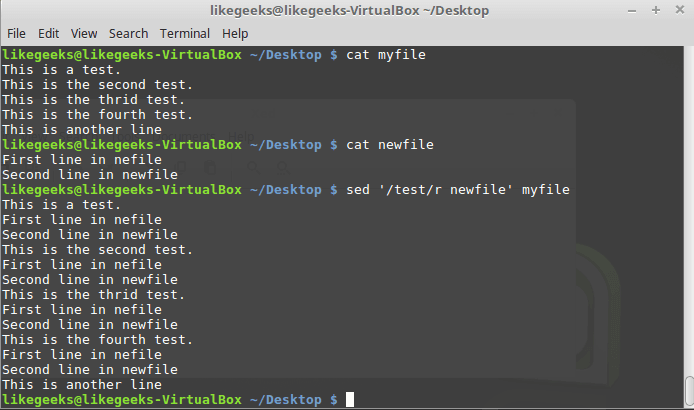
Using a template when calling the r command
The contents of the file will be inserted after each line corresponding to the pattern.
Example
Imagine such a task. There is a file in which there is a certain sequence of characters, in itself meaningless, which must be replaced with data taken from another file. Namely, let it be the file
newfile , in which the sequence of characters DATA plays the role of a newfile . Data that needs to be substituted for DATA is stored in the data file.This task can be solved by using the
r and d commands of the stream sed editor: $ Sed '/DATA>/ { r newfile d}' myfile 
Replacing the placeholder with real data
As you can see, instead of the placeholder,
DATA sed added two lines from the data file to the output stream.Results
Today we covered the basics of working with the sed streaming editor. In fact, sed is a huge topic. Its study can be compared with the study of a new programming language, but, having understood the basics, you can master sed at any level you need. As a result, your ability to process texts with its help will be limited only by your imagination.
That's all for today. Next time, let's talk about the awk data processing language.
Dear readers! Do you use sed in your daily work? If so, please share your experience.
Source: https://habr.com/ru/post/327530/
All Articles