What is a service mesh and why do I need it [for a cloud microservice application]?
Preface from the translator : This week was marked by the release of Linkerd 1.0 , which is an excellent reason to tell not only about this product, but also about the very category of such software - the service mesh (literally translated as “grid for services”). Moreover, the authors Linkerd just published the relevant article.
tl; dr: Service mesh is a dedicated infrastructure layer to provide secure, fast, and reliable interoperability between services. If you are creating an application to run in the cloud (i.e. cloud native) , you need a service mesh.
Over the past year, service mesh has become a critical component in the cloud stack. Companies with high traffic, such as PayPal, Lyft, Ticketmaster and Credit Karma, have already added a service mesh to their applications in production, and in January, Linkerd , the Open Source implementation of service mesh for cloud applications, became the official project of the Cloud Native Computing Foundation ( containerd and rkt were recently transferred to the same fund , and he is also known at least from Kubernetes and Prometheus - approx. transl.) . But what is a service mesh? And why was he suddenly needed?
')
In this article, I will give a definition of a service mesh and trace its origin through changes in the architecture of applications over the past decade. I will separate the service mesh from related, but different concepts: API gateway, edge proxy, corporate service bus. Finally, I will describe where the service mesh is needed, and what to expect from the adaptation of this concept in the cloud native world.
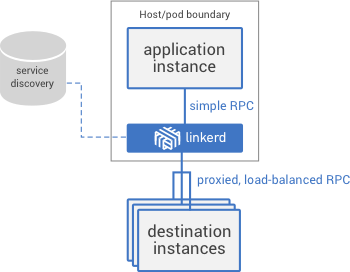
Service mesh is a dedicated infrastructure layer for interoperability between services. He is responsible for the reliable delivery of requests through the complex topology of services that make up a modern application created for work in the cloud. In practice, a service mesh is usually implemented as an array of lightweight network proxies that are deployed along with the application code, without the application having to know about it. (But we will see that this idea has different variations.)
The concept of service mesh as a separate layer is associated with the growth of applications created specifically for cloud environments. In such a cloud model, a single application can consist of hundreds of services, each service can have thousands of instances, and each instance can have constantly changing states depending on the dynamic planning performed by an orchestration tool like Kubernetes . In this world, the interaction of services is not just a very complex process, but also a ubiquitous, fundamental part of the behavior of the executable environment. Managing it is very important for maintaining performance and reliability.
Yes, service mesh is a network model that is at the level of abstraction above TCP / IP. It is understood that the underlying L3 / L4 network is represented and capable of transmitting bytes from point to point. (It also implies that this network, like all other aspects of the environment, is not reliable; the service mesh must handle network failures.)
In some ways, the service mesh is similar to TCP / IP. As the TCP stack abstracts from the mechanics of reliable transfer of bytes between end network points, so the service mesh abstracts from the mechanics of sending requests between services. Like TCP, the service mesh does not attach importance to the actual load and how it is encoded. The application has a high-level task (“send something from A to B”), and the work of the service mesh, as in the case of TCP, is to solve this problem by processing any problems along the way.
Unlike TCP, the service mesh has a significant goal in addition to “just getting something to work” - to provide a unified entry point for the entire application, ensuring visibility and control of its executable environment. The direct goal of a service mesh is to bring interaction between services from the area of the invisible, intended infrastructure, offering it the role of a full-fledged participant in the ecosystem , where everything is monitored, managed, controlled.
Reliable request transfer in a cloud infrastructure application can be very complex. And a service mesh like Linkerd deals with this complexity with the help of a set of efficient technicians: protection from network problems, load balancing taking into account delays, service discovery (according to the pattern of consistency in the final analysis ), retries and deadlines. All of these opportunities must work together, and the interactions between them and the environment in which they operate can be quite complex.
For example, when a request is made in a service through Linkerd, a very simplified sequence of events looks like this:
And this is only a simplified version: Linkerd can also initiate and terminate TLS, perform protocol updates, dynamically switch traffic, and switch between data centers.

It is important to note that these capabilities are designed to ensure sustainability at both the endpoint level and the application level as a whole. Distributed systems of large scales, regardless of their architecture, have one defining characteristic: there are many opportunities for small, local falls to become catastrophic for the entire system. Therefore, the service mesh should be designed to provide protection against such problems, reducing the load and quickly falling when the underlying systems reach their limits.
Service mesh is, of course, not providing new functionality, but rather a shift in where this functionality is placed. Web applications have always been forced to drag the burden of interaction between services. The origin of the service mesh model can be traced in the evolution of these applications over the past 15 years.
Imagine a typical medium-sized web application architecture in the 2000s: these are 3 levels. In such a model, application logic, content upload logic, and storage logic are separate layers. The interaction between these levels is complex, but limited in scale - there are only two transit areas. There is no “grid” (i.e., mesh) - only the interaction of logic between transit sections, carried out in the code of each layer.
When this architectural approach reached a very large scale, it began to break down. Companies like Google, Netflix and Twitter are faced with the need to maintain large traffic, the implementation of which became the predecessor of the cloud (cloud native) approach: the application layer was broken into many services (sometimes called microservices), and the levels became topology. In these systems, a generic layer for interaction quickly became a necessity, but usually took the form of a “fat client” library: Finagle from Twitter, Hystrix from Netflix, Stubby from Google.
In many ways, these libraries (Finagle, Stubby, Hystrix) became the first “grids for services”. Let them be sharpened to work in their specific environment and required the use of specific languages and frameworks, however, they were already a dedicated infrastructure for managing the interaction between services and (in the case of the Finagle and Open Source libraries of Finagle and Hystrix) were used not only in the companies that developed them .
Followed by a rapid movement towards the modern applications created to run in the clouds. The cloud native model combines a microservice approach from many small services with two additional factors:
These three components allow applications to naturally adapt to scaling under load and to handle the presence of always partial failures in a cloudy environment. But with hundreds of services and thousands of instances, and even a layer of orchestration to plan the launch of instances, the path of a single query that follows the service topology can be incredibly complicated, and since containers have simplified the ability to create services in any different languages, the library approach has ceased to be practical.
The combination of complexity and critical importance led to the need for a dedicated layer for interaction between services, separated from the application code and able to cope with the very dynamic nature of the underlying environment. This layer is the service mesh.
While there is a rapid growth in the adaptation of the service mesh in the cloud ecosystem, an extensive and exciting roadmap [the further development of this concept and its implementations - approx. transl.] still to be opened. Requirements for computing without servers (for example, Amazon Lambda) fit perfectly into the service mesh model by naming and linking [components], which forms a natural extension of its use in the cloud ecosystem. The roles of service identity and access policies are still very young in cloud environments, and here the service mesh is well suited to become a fundamental component of such a need. Finally, the service mesh, like TCP / IP before, will continue its penetration into the underlying infrastructure. As Linkerd evolved from systems like Finagle, it will continue its evolution and the current implementation of the service mesh as a separate proxy in user space that can be added to the cloud stack.
Service mesh is a critical component of the cloud native stack. Linkerd, appearing just over 1 year ago, is part of the Cloud Native Computing Foundation and has gained a growing community of contributors and users. Its users are diverse: from startups like Monzo, destroying the UK banking industry [this is a fully digital bank offering API developers access to financial data - approx. trans.] , to large scale Internet companies such as PayPal, Ticketmaster and Credit Karma, as well as companies with a business history of hundreds of years like Houghton Mifflin Harcourt.
The open source community of Linkerd users and contributors demonstrate daily the value of the service mesh model. We are committed to creating a great product and the continued growth of our community.

PS The author of the article is William Morgan, one of the founders of Linkerd in 2015, the founder and CEO of Buoyant Inc (the developer company that transferred Linkerd to CNCF).
UPDATED (02.20.2018): Read also in our blog the review of the new Buoyant product - “ Conduit - Kubernetes lightweight service mesh ”.
tl; dr: Service mesh is a dedicated infrastructure layer to provide secure, fast, and reliable interoperability between services. If you are creating an application to run in the cloud (i.e. cloud native) , you need a service mesh.
Over the past year, service mesh has become a critical component in the cloud stack. Companies with high traffic, such as PayPal, Lyft, Ticketmaster and Credit Karma, have already added a service mesh to their applications in production, and in January, Linkerd , the Open Source implementation of service mesh for cloud applications, became the official project of the Cloud Native Computing Foundation ( containerd and rkt were recently transferred to the same fund , and he is also known at least from Kubernetes and Prometheus - approx. transl.) . But what is a service mesh? And why was he suddenly needed?
')
In this article, I will give a definition of a service mesh and trace its origin through changes in the architecture of applications over the past decade. I will separate the service mesh from related, but different concepts: API gateway, edge proxy, corporate service bus. Finally, I will describe where the service mesh is needed, and what to expect from the adaptation of this concept in the cloud native world.
What is a service mesh?
Service mesh is a dedicated infrastructure layer for interoperability between services. He is responsible for the reliable delivery of requests through the complex topology of services that make up a modern application created for work in the cloud. In practice, a service mesh is usually implemented as an array of lightweight network proxies that are deployed along with the application code, without the application having to know about it. (But we will see that this idea has different variations.)
The concept of service mesh as a separate layer is associated with the growth of applications created specifically for cloud environments. In such a cloud model, a single application can consist of hundreds of services, each service can have thousands of instances, and each instance can have constantly changing states depending on the dynamic planning performed by an orchestration tool like Kubernetes . In this world, the interaction of services is not just a very complex process, but also a ubiquitous, fundamental part of the behavior of the executable environment. Managing it is very important for maintaining performance and reliability.
Is service mesh a network model?
Yes, service mesh is a network model that is at the level of abstraction above TCP / IP. It is understood that the underlying L3 / L4 network is represented and capable of transmitting bytes from point to point. (It also implies that this network, like all other aspects of the environment, is not reliable; the service mesh must handle network failures.)
In some ways, the service mesh is similar to TCP / IP. As the TCP stack abstracts from the mechanics of reliable transfer of bytes between end network points, so the service mesh abstracts from the mechanics of sending requests between services. Like TCP, the service mesh does not attach importance to the actual load and how it is encoded. The application has a high-level task (“send something from A to B”), and the work of the service mesh, as in the case of TCP, is to solve this problem by processing any problems along the way.
Unlike TCP, the service mesh has a significant goal in addition to “just getting something to work” - to provide a unified entry point for the entire application, ensuring visibility and control of its executable environment. The direct goal of a service mesh is to bring interaction between services from the area of the invisible, intended infrastructure, offering it the role of a full-fledged participant in the ecosystem , where everything is monitored, managed, controlled.
What does service mesh do?
Reliable request transfer in a cloud infrastructure application can be very complex. And a service mesh like Linkerd deals with this complexity with the help of a set of efficient technicians: protection from network problems, load balancing taking into account delays, service discovery (according to the pattern of consistency in the final analysis ), retries and deadlines. All of these opportunities must work together, and the interactions between them and the environment in which they operate can be quite complex.
For example, when a request is made in a service through Linkerd, a very simplified sequence of events looks like this:
- Linkerd applies dynamic routing rules, specifying which service the request is for. Should the request be passed to the service in production or staging? A service in a local data center or in the cloud? The latest version of the service that has been tested, or an older version tested in production? All of these routing rules are configured dynamically, can be applied globally or for selected traffic slices.
- After finding the desired recipient, Linkerd requests the appropriate pool of instances from the discovery service of the corresponding endpoint (there may be several). If this information is at variance with what Linkerd sees in practice, he decides which source of information to trust.
- Linkerd selects the instance that is likely to return a quick response based on a number of factors (including the delay recorded for recent requests).
- Linkerd tries to send a request to the instance, recording the result of the operation (delay and type of response).
- If the instance has fallen, is not responding, or cannot process the request, Linkerd tries this request on another instance (only if it knows that the request is idempotent ).
- If the instance repeatedly returns errors, Linkerd removes it from the load balancing pool and will periodically check it further (the instance may experience a short-term failure).
- If the deadline for the request is reached, Linkerd proactively returns the request error, rather than adding a load with retrying its execution.
- Linkerd takes into account every aspect of the above described behavior in the form of metrics and distributed tracking — all of this data is sent to a centralized metrics system.
And this is only a simplified version: Linkerd can also initiate and terminate TLS, perform protocol updates, dynamically switch traffic, and switch between data centers.
It is important to note that these capabilities are designed to ensure sustainability at both the endpoint level and the application level as a whole. Distributed systems of large scales, regardless of their architecture, have one defining characteristic: there are many opportunities for small, local falls to become catastrophic for the entire system. Therefore, the service mesh should be designed to provide protection against such problems, reducing the load and quickly falling when the underlying systems reach their limits.
Why is service mesh needed?
Service mesh is, of course, not providing new functionality, but rather a shift in where this functionality is placed. Web applications have always been forced to drag the burden of interaction between services. The origin of the service mesh model can be traced in the evolution of these applications over the past 15 years.
Imagine a typical medium-sized web application architecture in the 2000s: these are 3 levels. In such a model, application logic, content upload logic, and storage logic are separate layers. The interaction between these levels is complex, but limited in scale - there are only two transit areas. There is no “grid” (i.e., mesh) - only the interaction of logic between transit sections, carried out in the code of each layer.
When this architectural approach reached a very large scale, it began to break down. Companies like Google, Netflix and Twitter are faced with the need to maintain large traffic, the implementation of which became the predecessor of the cloud (cloud native) approach: the application layer was broken into many services (sometimes called microservices), and the levels became topology. In these systems, a generic layer for interaction quickly became a necessity, but usually took the form of a “fat client” library: Finagle from Twitter, Hystrix from Netflix, Stubby from Google.
In many ways, these libraries (Finagle, Stubby, Hystrix) became the first “grids for services”. Let them be sharpened to work in their specific environment and required the use of specific languages and frameworks, however, they were already a dedicated infrastructure for managing the interaction between services and (in the case of the Finagle and Open Source libraries of Finagle and Hystrix) were used not only in the companies that developed them .
Followed by a rapid movement towards the modern applications created to run in the clouds. The cloud native model combines a microservice approach from many small services with two additional factors:
- containers (for example, Docker) that provide resource isolation and dependency management;
- An orchestration layer (for example, Kubernetes) that abstracts from hardware and offers a single pool.
These three components allow applications to naturally adapt to scaling under load and to handle the presence of always partial failures in a cloudy environment. But with hundreds of services and thousands of instances, and even a layer of orchestration to plan the launch of instances, the path of a single query that follows the service topology can be incredibly complicated, and since containers have simplified the ability to create services in any different languages, the library approach has ceased to be practical.
The combination of complexity and critical importance led to the need for a dedicated layer for interaction between services, separated from the application code and able to cope with the very dynamic nature of the underlying environment. This layer is the service mesh.
Future service mesh
While there is a rapid growth in the adaptation of the service mesh in the cloud ecosystem, an extensive and exciting roadmap [the further development of this concept and its implementations - approx. transl.] still to be opened. Requirements for computing without servers (for example, Amazon Lambda) fit perfectly into the service mesh model by naming and linking [components], which forms a natural extension of its use in the cloud ecosystem. The roles of service identity and access policies are still very young in cloud environments, and here the service mesh is well suited to become a fundamental component of such a need. Finally, the service mesh, like TCP / IP before, will continue its penetration into the underlying infrastructure. As Linkerd evolved from systems like Finagle, it will continue its evolution and the current implementation of the service mesh as a separate proxy in user space that can be added to the cloud stack.
Conclusion
Service mesh is a critical component of the cloud native stack. Linkerd, appearing just over 1 year ago, is part of the Cloud Native Computing Foundation and has gained a growing community of contributors and users. Its users are diverse: from startups like Monzo, destroying the UK banking industry [this is a fully digital bank offering API developers access to financial data - approx. trans.] , to large scale Internet companies such as PayPal, Ticketmaster and Credit Karma, as well as companies with a business history of hundreds of years like Houghton Mifflin Harcourt.
The open source community of Linkerd users and contributors demonstrate daily the value of the service mesh model. We are committed to creating a great product and the continued growth of our community.
PS The author of the article is William Morgan, one of the founders of Linkerd in 2015, the founder and CEO of Buoyant Inc (the developer company that transferred Linkerd to CNCF).
UPDATED (02.20.2018): Read also in our blog the review of the new Buoyant product - “ Conduit - Kubernetes lightweight service mesh ”.
Source: https://habr.com/ru/post/327536/
All Articles