As I made the fastest resize of images. Part 2, SIMD
This is a continuation of a series of articles on how I worked on optimization and got the fastest resize on modern x86 processors. In each article, I tell a part of the story, and I hope to push someone else to optimize my or someone else's code. In the previous series:
→ Part 0
→ Part 1, general optimizations
Last time, we received an average acceleration of 2.5 times without changing the approach. This time I will show how to apply the SIMD approach and get acceleration another 3.5 times. Of course, the use of SIMD for graphics processing is not a know-how, you can even say that SIMD was invented for this. But in practice, very few developers use it even in image processing tasks. For example, the rather well-known and popular libraries ImageMagick and LibGD are written without using SIMD. This is partly due to the fact that the SIMD approach is objectively more complicated and not cross-platform, and partly because there is little information on it. Quite easy to find the basics, but few detailed materials and analysis of real problems. From this on Stack Overflow there are a lot of questions literally about every little thing: how to load data, how to unpack, pack. It is evident that everyone has to fill the cones on their own.
What is SIMD
Feel free to skip this section if you are already familiar with the basics. SIMD means singe instruction, multiple data (one command, multiple data). This approach allows you to combine several identical operations into one. The data set on which the operation is performed is called a vector.
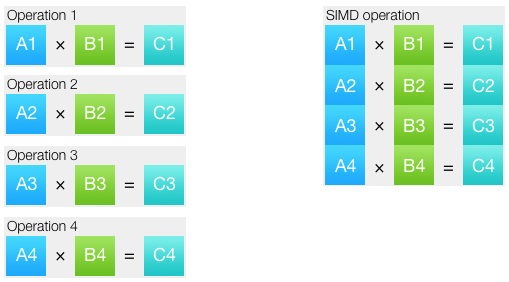
In most cases, on modern processors, SIMD instructions are executed in as many cycles as their scalar counterparts. Those. theoretically, when switching to SIMD, you can expect acceleration of 2, 4, 8, 16, and even 32 times, depending on the data types used and the sets of commands. In practice, goes differently. First, even in vectorized code, part of the code remains scalar. Secondly, often for vector operations data need to be prepared: unpack and pack. As a rule, packing and unpacking data is the most difficult thing when writing a SIMD code. Thirdly, SIMD instructions are not an exact copy of the usual ones: for some operations there are specific instructions that solve the problem well, but for other tasks there are no necessary instructions. For example, to find the minimum and maximum values, there are separate SIMD instructions that work without conditional jumps. But the integer vector division in x86 processors is simply not there.
Vector registers fit more values. How much depends on the type of data and the size of the register. 128-bit SSE registers. If, for example, we work with 32-bit integers, then four values fit into one SSE register. The following data types are generally available:
- 8-bit integers (with or without a sign)
- 16 bit integers (with or without a sign)
- 32-bit integers (with or without a sign)
- 64 bit integers (with or without a sign)
- Single-precision floating point numbers, 32 bits
- Double precision floating point numbers, 64 bits
All vector registers are the same and do not know what type of data they are in. Interpretation depends only on the instruction that works with the register. Accordingly, most instructions have variations for working with data of different types. Instructions can receive data of one type, and issue another. If you are familiar with assembler, this is somewhat reminiscent of how ordinary registers work: you can write something to the 32-bit eax register, and then work with its 16-bit part of ax .
Choosing the right command expansion
The first SIMD instructions appeared in the Intel Pentium MMX processor. Actually MMX - this is the name of the expansion commands. This kit was so important that Intel rendered it in the name of the processor. With the help of MMX, I once wrote for a long time simple algorithms like mixing two images or supersampling. I wrote on Delphi, but in order to use MMX, I had to go down a level and make inserts in assembly language.
Since then, I have not watched too much the development of processor teams and related development tools. Therefore, when I recently took up SIMD, I was pleasantly surprised. No, the compiler is still not able to automatically apply SIMD instructions in more or less complex cases. And even if he is capable, he usually gets worse than self-written SIMD code. But on the other hand, for the use of SIMD, it is no longer necessary to write in assembly language, everything is done by special functions - intrinsics.
Most often, each intrinsic corresponds to one specific processor instruction. Those. The written code turns out very effective and close to iron. But you also use the familiar and relatively safe C syntax for writing code. You, as usual, include the header file, in which intrinsiki functions are defined, as usual you declare variables using special data types, and as you usually call functions. In short, write the usual code. A slight inconvenience is that you cannot use mathematical operations with SIMD data types; intrinsics should be used for all calculations. Roughly speaking, you cannot write ss0 + ss1 , you can only add_float(ss0, ss1) (the name of the function is invented).
SIMD extensions are many. Basically, the presence of a newer expansion in the processor means the presence of all the predecessors. In the chronology of the appearance of the expansion are in the following order:
MMX, SSE, SSE2, SSE3, SSSE3, SSE4.1, SSE4.2, AVX, AVX2, AVX-512
As you can see, the list is impressive. Not every machine has every extension. Find a live x86 processor without MMX can only be in the museum. SSE2 is a mandatory extension for 64-bit processors, i.e. these days, too, are almost everywhere. Support for SSE4.2 can be found in any processor, starting with the Nehalem architecture, i.e. since 2008. But AVX2 has only non-budget Intel processors, starting with the Haswell core, i.e. since 2013, while AMD appeared in Ryzen processors released in 2017. AVX-512 is currently only available in Intel Xeon and Xeon Phi server processors.
From the choice of instructions, depends on the performance and complexity of writing code, as well as support for processors. Sometimes developers make several implementations of their code for different instruction sets. I chose two: SSE4.2 and AVX2. I reasoned like this: SSE4.2 is the basic set that everyone who should be worried about performance and should not suffer, implementing everything, for example, on SSE2, should be. And AVX2 for those who are not lazy to change the iron at least once in 3 years. Whatever you choose for your implementation, over time your choice will only become more accurate, because the number of processors on the market with the selected instruction set will only increase.
SSE4 implementation
Let's finally go back to the code. In order to use SSE4.2 in C, you need to include as many as three header files:
#include <emmintrin.h> #include <mmintrin.h> #include <smmintrin.h> In addition, you need to specify the compiler flag -msse4 . If we are talking about building the Python module (like ours), then we can add this flag directly from the command line, so as not to complicate the assembly now:
$ CC="ccache cc -msse4" python ./setup.py develop The most comprehensive reference for intrinsics can be found at the Intel Intrinsics Guide . There is a good search and filtering, in the description of intrinsics are indicated the corresponding instructions, pseudo-code of instructions and even the execution time in cycles on Intel processors of the latest generations. As a reference book, this is a unique thing. But the format of the directory does not allow to make an overall picture of what should happen.
Only identical operations on different data can be vectorized. In our case, the same actions are performed on different image channels:
for (xx = 0; xx < imOut->xsize; xx++) { ss0 = 0.5; ss1 = 0.5; ss2 = 0.5; for (y = ymin; y < ymax; y++) { ss0 = ss0 + (UINT8) imIn->image[y][xx*4+0] * k[y-ymin]; ss1 = ss1 + (UINT8) imIn->image[y][xx*4+1] * k[y-ymin]; ss2 = ss2 + (UINT8) imIn->image[y][xx*4+2] * k[y-ymin]; } imOut->image[yy][xx*4+0] = clip8(ss0); imOut->image[yy][xx*4+1] = clip8(ss1); imOut->image[yy][xx*4+2] = clip8(ss2); } A similar code is for vertical and horizontal passage. For convenience, we will take both into separate functions and will use SIMD only within the framework of two functions with the following signatures:
void ImagingResampleHorizontalConvolution8u( UINT32 *lineOut, UINT32 *lineIn, int xsize, int *xbounds, float *kk, int kmax ); void ImagingResampleVerticalConvolution8u( UINT32 *lineOut, Imaging imIn, int ymin, int ymax, float *k ); If you remember, in the previous part I made three special cases for two, three and four channels in the image. It was necessary to get rid of the internal cycle through the channels and at the same time not to perform unnecessary calculations for channels that are not in the image. In the SIMD version, we will not divide implementations by channels: all calculations will always be made on four channels. Each pixel will be represented by four 32-bit floating point numbers and will occupy exactly one SSE register. Yes, for three-channel images, four operations will be performed idly, and for two-channel images - half. But it's easier to close your eyes to this than to try to fill the SSE registers with useful data as much as possible.
Take another look at the code above. At the very beginning, the batteries are assigned a constant value of 0.5, which is necessary for rounding the result. To load a single float value into the entire register, use the _mm_set1_* functions.
__m128 sss = _mm_set1_ps(0.5); Usually the last part of the name of the function means the type of data with which it works. In our case, this is _ps , which means packed single.
Further, if we want to work with a pixel as a vector of floating-point numbers, we need to somehow convert the pixel into this representation. There are no instructions in SSE that convert 8-bit values directly to single-precision numbers. There is _mm_cvtepi32_ps , which converts 32-bit integers into numbers with single precision, but before using it, you need to unpack 8-bit numbers into 32-bit ones. For this, the _mm_cvtepu8_epi32 function _mm_cvtepu8_epi32 . She needs to transfer the address to 128-bit values in memory.
__m128i pix_epi32 = _mm_cvtepu8_epi32(*(__m128i *) &imIn->image32[y][xx]); __m128 pix_ps = _mm_cvtepi32_ps(pix_epi32); Notice how much in SIMD code you have to do explicitly when loading values. In scalar code there is nothing of this, the compiler itself understands that since we multiply an 8-bit integer by a float, the first one also needs to be converted to float.
The coefficient for all channels of the same pixel is the same, so _mm_set1_ps useful _mm_set1_ps .
__m128 mmk = _mm_set1_ps(k[y - ymin]); It remains to multiply the coefficients on the channels and add up with the battery:
__m128 mul = _mm_mul_ps(pix_ps, mmk); sss = _mm_add_ps(sss, mul); Now in the sss battery there is the value of the pixel channels, which truth may go beyond the range [0, 255], which means that you need to somehow limit these values. Remember the clip8 feature from the previous article? It had two conditional transitions. In the case of SIMD, we are not able to use conditional transitions depending on the data, because the processor must execute the same command for all data. But in fact, this is even better, because there are functions _mm_min_epi32 and _mm_max_epi32 . Therefore, we translate the values into signed 32-bit integers, and then we cut them off within [0, 255].
__m128i mmmax = _mm_set1_epi32(255); __m128i mmmin = _mm_set1_epi32(0); __m128i ssi = _mm_cvtps_epi32(sss); ssi = _mm_max_epi32(mmmin, _mm_min_epi32(mmmax, ssi)); Unfortunately, there is no instruction to reverse _mm_cvtepu8_epi32 , so I didn’t think of anything better than shifting the needed bytes to the very beginning and then converting the SSE register into a general-purpose register using _mm_cvtsi128_si32 .
__m128i shiftmask = _mm_set_epi8(-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,12,8,4,0); lineOut[xx] = _mm_cvtsi128_si32(_mm_shuffle_epi8(ssi, shiftmask)); Notice that in the shiftmask mask shiftmask low bytes go to the right. For a horizontal pass, everything is exactly the same; only the order of loading pixels changes: the adjacent pixels are loaded from the row, not from the adjacent rows.
Everything is ready, it's time to start the test and find out the result.
Scale 2560×1600 RGB image to 320x200 bil 0,01151 s 355.87 Mpx/s 161.4 % to 320x200 bic 0,02005 s 204.27 Mpx/s 158.7 % to 320x200 lzs 0,03421 s 119.73 Mpx/s 137.2 % to 2048x1280 bil 0,04450 s 92.05 Mpx/s 215.0 % to 2048x1280 bic 0,05951 s 68.83 Mpx/s 198.3 % to 2048x1280 lzs 0,07804 s 52.49 Mpx/s 189.6 % to 5478x3424 bil 0,18615 s 22.00 Mpx/s 215.5 % to 5478x3424 bic 0,24039 s 17.04 Mpx/s 210.5 % to 5478x3424 lzs 0,30674 s 13.35 Mpx/s 196.2 % Result for commit 8d0412b .
A gain of two and a half to three times! Let me remind you that I am testing on a three-channel RGB image, so the acceleration 3 times in this case can be considered a reference.
Correct packing
The previous version was almost 1 in 1 copied from a scalar code. Moreover, the functions that appeared in the latest versions of SSE were used for packing and unpacking: _mm_cvtepu8_epi32 , _mm_max/min_epi32 , _mm_shuffle_epi8 . Obviously, people somehow coped with these tasks and with earlier versions of SSE. And indeed, there is a whole set of functions for packing / unpacking data, _mm_pack* and _mm_unpack* . And if the unpacking here does not help much ( _mm_cvtepu8_epi32 better suited for our purposes), then the packing can be greatly simplified. Simplify so that no constants are needed to shift and trim values (we are talking about mmmax , mmmin and shiftmask ).
The point is that the _mm_packs _mm_packs* packing functions are performed with saturation, as indicated by the letter s in the name, for example _mm_packs_epi32 . Saturation means that if during conversion the value of a variable goes beyond the limits of a new type, then it remains extreme for this type. For example, if we convert from a 16-bit integer with a sign to an 8-bit unsigned, then the value 257 is converted to 255, and -3 to 0. It turns out that the packing functions simultaneously shift the values and do not allow to go beyond the limits of the range.
__m128i ssi = _mm_cvtps_epi32(sss); ssi = _mm_packs_epi32(ssi, ssi); ssi = _mm_packus_epi16(ssi, ssi); lineOut[xx] = _mm_cvtsi128_si32(ssi); This optimization does not give me acceleration, but it looks beautiful and does not require additional constants. Watch the b17cdc9 commit .
AVX registers
If the dog wore pants, would she do it this way or that?
And if registers contained twice as much data? When I found out how AVX works, I immediately remembered this picture. When first considering AVX, instructions seem strange and illogical. This is not just “like SSE, only 2 times more,” there is some kind of incomprehensible logic in them. See for yourself the same mixing instructions that we already used. Here is the SSE version pseudocode:
FOR j := 0 to 15 i := j*8 IF b[i+7] == 1 dst[i+7:i] := 0 ELSE index[3:0] := b[i+3:i] dst[i+7:i] := a[index*8+7:index*8] FI ENDFOR It would be logical to assume that the AVX simply needs to increase the counter from 15 to 31. But no, the pseudo-code of the AVX version is much wiser:
FOR j := 0 to 15 i := j*8 IF b[i+7] == 1 dst[i+7:i] := 0 ELSE index[3:0] := b[i+3:i] dst[i+7:i] := a[index*8+7:index*8] FI IF b[128+i+7] == 1 dst[128+i+7:128+i] := 0 ELSE index[3:0] := b[128+i+3:128+i] dst[128+i+7:128+i] := a[128+index*8+7:128+index*8] FI ENDFOR AVX is not twice as large as SSE, it is two SSE! That is, AVX registers should be looked at as a couple of vectors. And these vectors in most teams do not interact with each other. Look at the pseudo-code of the AVX-team again, it clearly shows that the first block only works with the lower 128 bits, and the second only with the high 128 bits. And you can not mix so that in the older were lower bytes, or vice versa. Moreover, for this instruction, the separation is not too strict: a register that tells how to shift can shift the upper and lower parts in different ways. And it often happens that the arguments of operations in both parts are the same. For example, _mm256_blend_epi16 pseudocode:
FOR j := 0 to 15 i := j*16 IF imm8[j%8] dst[i+15:i] := b[i+15:i] ELSE dst[i+15:i] := a[i+15:i] FI ENDFOR dst[MAX:256] := 0 Note that j is iterated to 15, and the mask is taken from byte modulo eight: imm8[j%8] . Those. the top and bottom of the register will always have the same mask. There is still a lot of trouble unpacking and packing, it also occurs independently in the upper and lower parts.
PACK_SATURATED(src[127:0]) { dst[15:0] := Saturate_Int32_To_UnsignedInt16 (src[31:0]) dst[31:16] := Saturate_Int32_To_UnsignedInt16 (src[63:32]) dst[47:32] := Saturate_Int32_To_UnsignedInt16 (src[95:64]) dst[63:48] := Saturate_Int32_To_UnsignedInt16 (src[127:96]) RETURN dst[63:0] } dst[63:0] := PACK_SATURATED(a[127:0]) dst[127:64] := PACK_SATURATED(b[127:0]) dst[191:128] := PACK_SATURATED(a[255:128]) dst[255:192] := PACK_SATURATED(b[255:128]) dst[MAX:256] := 0 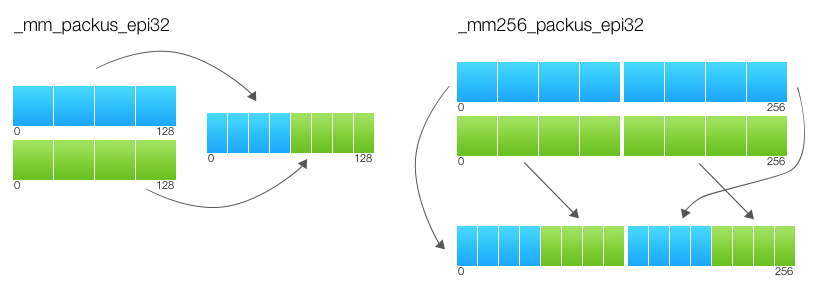
The lower bits of the result are calculated only on the basis of the lower bits of the input parameters. And the top only on the basis of the top. I have not seen in any source mention of this rule explicitly, but its understanding greatly simplifies porting the SSE code to AVX.
AVX commands
There is something that distinguishes the AVX teams themselves from SSE. Remember the problem with data dependency, discussed at the end of the first part? She was counted in AVX. Of course, it is no longer possible to correct the behavior of scalar instructions, but it is possible to prevent the same error during the transition from SSE to AVX. In the pseudocode of each AVX instruction, there is a line at the end:
dst[MAX:256] := 0 This means that AVX determines the behavior of existing commands with registers of future generations (512-bit and more). But that is not all. For encoding AVX commands, the VEX opcode system is used. AVX includes the ability to encode even SSE instructions in VEX. SSE instructions encoded in this manner also receive guarantees that the high bits are reset. You may have heard that there is a penalty of about a hundred bars for using AVX commands after SSE or vice versa. The good news is that this penalty does not apply to SSE teams encoded in VEX. And if you use intrinsics, with the -mavx flag -mavx compiler will generate instructions in a new format. The bad news is that if the code is compiled with -mavx and contains SSE commands, but does not contain any AVX commands, it will still be encoded in VEX and will not work on processors without AVX. Those. It will not work within the framework of a single assembly module to use SSE instructions in the old format and AVX instructions:
if (is_avx_available()) { resample_avx(); } else { resample_sse(); } Because with the -mavx flag -mavx code from the resample_sse() function resample_sse() not run on the processor without AVX, and without this flag, the code from the resample_avx() function resample_avx() not even compile.
AVX2, vertical pass
Until now, the transfer to SIMD was quite simple, because exactly one pixel is represented in one SSE4 register, represented as four floating point numbers. But with AVX2 we have to process 8 floating-point values at once, that is, two pixels. But which pixels to take in one register? Here I again want to insert a picture with a dog that wears pants. Let me remind you what the frame looks like, for example, of horizontal convolution:
for (xx = 0; xx < xsize; xx++) { xmin = xbounds[xx * 2 + 0]; xmax = xbounds[xx * 2 + 1]; for (x = xmin; x < xmax; x++) { __m128i pix = lineIn[x]; __m128 mmk = k[x - xmin]; // } } You can, for example, take the neighboring pixels in the line: lineIn[x] and lineIn[x + 1] , this is the most obvious option. But then for these pixels it is necessary to prepare different coefficients ( k[x - xmin] and k[x - xmin + 1] ). And the distance from xmax to xmin may turn out to be odd, and in order to calculate the last pixel, you will need to combine SSE and AVX-code.
You can take pixels in adjacent lines: lineIn1[x] and lineIn2[x] . But then it will be necessary to load and unload pixels somehow separately, which is not very convenient.
In fact, any method will have some advantages and disadvantages. Frankly, translating a horizontal pass to the AVX2 is not very convenient. Another thing is vertical! Look at him:
for (xx = 0; xx < imIn->xsize; xx++) { for (y = ymin; y < ymax; y++) { __m128i pix = image32[y][xx]; __m128 mmk = k[y - ymin]; // } } We can take the adjacent pixels in the image32[y][xx] and image32[y][xx + 1] and they will have the same factor. After the internal cycle is completed in the battery, there will be a result for two neighboring pixels; it is also easy to pack it. In short, the code can be rewritten simply by changing all the prefixes __m128 to __m256 , and _mm_ to _mm256_ . The only thing that really differs is the use of the _mm256_castsi256_si128 and _mm_storel_epi64 at the end. The first is noop, just type casting. And the second saves the 64-bit value from the register to memory.
Scale 2560×1600 RGB image to 320x200 bil 0.01162 s 352.37 Mpx/s -0,9 % to 320x200 bic 0.02085 s 196.41 Mpx/s -3,8 % to 320x200 lzs 0.03247 s 126.16 Mpx/s 5,4 % to 2048x1280 bil 0.03992 s 102.61 Mpx/s 11,5 % to 2048x1280 bic 0.05086 s 80.53 Mpx/s 17,0 % to 2048x1280 lzs 0.06563 s 62.41 Mpx/s 18,9 % to 5478x3424 bil 0.15232 s 26.89 Mpx/s 22,2 % to 5478x3424 bic 0.19810 s 20.68 Mpx/s 21,3 % to 5478x3424 lzs 0.23601 s 17.36 Mpx/s 30,0 % Result for commit 86fe8a2 .
We got a small performance loss for the first time. This is not the measurement error, because The result is fairly stable. Later I will explain why this happened. In the meantime, it can be seen that there is a gain mainly with an increase and not a strong decrease in the image. As it is not difficult to guess, this is because the vertical passage is made after the horizontal and therefore has a greater impact with a larger size of the final image. In general, the picture is quite positive.
AVX2, horizontal pass
For a horizontal passage, it is nevertheless more convenient to take two adjacent pixels in a row. Then for them it will be necessary to prepare different factors:
__m256 mmk = _mm256_set1_ps(k[x - xmin]); mmk = _mm256_insertf128_ps(mmk, _mm_set1_ps(k[x - xmin + 1]), 1); Well, at the end the result in the upper part of the 256-bit register will need to be added with the result in the bottom:
__m128 sss = _mm_add_ps( _mm256_castps256_ps128(sss256), _mm256_extractf128_ps(sss256, 1)); Scale 2560×1600 RGB image to 320x200 bil 0,00918 s 446.18 Mpx/s 26,6 % to 320x200 bic 0,01490 s 274.90 Mpx/s 39,9 % to 320x200 lzs 0,02287 s 179.08 Mpx/s 42,0 % to 2048x1280 bil 0,04186 s 97.85 Mpx/s -4,6 % to 2048x1280 bic 0,05029 s 81.44 Mpx/s 1,1 % to 2048x1280 lzs 0,06178 s 66.30 Mpx/s 6,2 % to 5478x3424 bil 0,16219 s 25.25 Mpx/s -6,1 % to 5478x3424 bic 0,19996 s 20.48 Mpx/s -0,9 % to 5478x3424 lzs 0,23377 s 17.52 Mpx/s 1,0 % Result for commit fd82859 .
Here we again see for some sizes a small loss relative to the previous version. But from both optimizations in total, we received an increase of 6 to 50 percent. On average, the AVX2 version is 25% faster than the SSE4 version.
Is it a lot or a little? . , 100% , 50% . , , .
, . , . Intel Core i5-4258U. , , .
, : . i5-4258U 2.4 2.9 . — , . — , . , . , , , . Intel Power Gadget . , SSE4- 2.9 . AVX2-, 2.75 . AVX2-, 2.6 . Those. , AVX2-, . AVX2- , - . AVX2 . ? , AVX2 .
, Xeon E5-2680 v2 ( Haswell, ) — AVX2- , , .
')
Source: https://habr.com/ru/post/326900/
All Articles