Experience implementing Tarantool in the service Calltouch

In the modern world of information technology, everyone, both large and small companies, has a large number of different APIs. And fault tolerance, despite many best practices, most often does not allow to guarantee 100% ability to correctly process customer requests, as well as recover from a failure, and continue processing requests lost due to a failure. This problem occurs even with large players on the Internet, not to mention not very large companies.
I work at Calltouch , and our main goal is to achieve fault tolerance of services and to be able to manage the data and requests that customers made to the API service. We need the ability to quickly restore service after a failure and process requests to the service that has problems. Start processing from the moment of failure. All this will allow to get closer to the state when it is almost impossible to lose customer requests on our side.
Analyzing the solutions offered in the market, we discovered for ourselves excellent performance and almost unlimited possibilities for data management and processing - with very few requirements for technical and financial resources.
Prehistory
In Calltouch, there is an API service that receives client requests with data to build reports in the web interface. These data are very important: they are used in marketing, and their loss can lead to unforeseen service work. Like everyone else, sometimes after laying out or adding new features, the service has problems, for some time it can be denied. Therefore, we need the ability to very quickly take and process those requests with data that were not delivered to the API service at the time of failure. Balancing with backup alone is not enough for several reasons:
- The amount of memory required for the service may require new equipment.
- The cost of equipment is now high.
- From an error with the killer request, no one is insured.
A fairly simple task (storing requests and quick access to them) generates high costs for the budget. In this regard, we decided to conduct a study on how now you can save all incoming requests with very fast access to them.
Study
There were several options for storing incoming data.
First option
Save queries with data using nginx logs and add them to some place. If problems arise, the API service will access the data that has been saved somewhere, and then do the necessary processing.
Second option
Make duplicate HTTP requests in several places. Plus, write an additional service that will add the data somewhere.
Configuring a web server to save data through the logs for further processing has its drawbacks. This solution is not very cheap, and the speed of access to the data will be extremely slow. You will need additional services to work with log files, aggregation and data storage. Plus, it will require a large amount of financial costs - for the introduction of new services, training of operating personnel, and the likely purchase of new equipment. And most importantly, if there was no such solution before, then you will have to find time for implementation. For these reasons, we almost immediately abandoned the first option and began to explore opportunities to implement the second option.
Implementation
We chose between nginx , goreplay and lwan .
The first lwan was dropped, because goreplay is able to immediately everything we need. It remains only to choose nginx with @post_action or goreplay. Goreplay was the benchmark for this scheme, but we decided to stop and think about the queries: where and how to store them better.
One could not particularly think about storage until a certain moment. We needed an inverse relationship between the already processed and not yet processed data. In the API, for which we make duplication of requests, IDs were not provided in requests from the client side. And this situation arose: it took the opportunity to insert additional data into the incoming request. This would allow to get feedback between the processed and unprocessed data, because all the data will get into the base, and not just the unprocessed. Then somehow you need to deal with all incoming data.
To get rid of request IDs, we decided to add a header with a UUID on the web server side and proxify such requests to the API - so that the API service modifies / deletes those requests that we duplicate in the database after processing. At this point, we also give up goreplay in favor of nginx, since nginx supports many modules, including the ability to write to various databases. This will simplify the data processing scheme and reduce the number of auxiliary services in solving this technical problem. You do not have to spend time learning additional languages and modifying goreplay to meet the requirements.
The simplest option would be to take a module for nginx, which can write all the contents of incoming requests to any database. Additional code and programming in configs would not be very desirable. The module for Tarantool turned out to be the most flexible and suitable for us; they can proxy all the data in Tarantool without any additional actions.
As an example, we present the simplest configuration and a small Lua script for Tarantool, in which all the bodies of incoming requests will be logged. The interaction of services is shown in the diagram below.
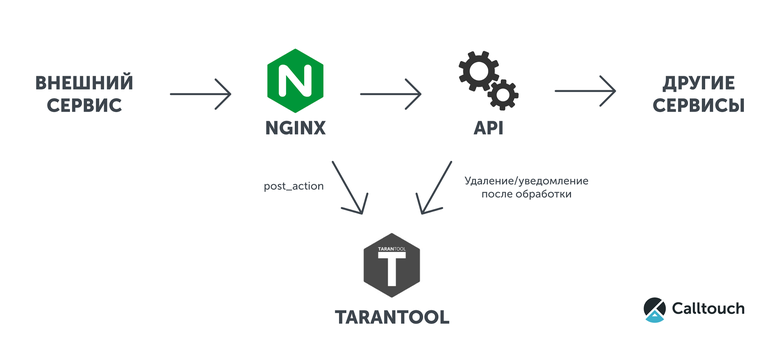
For this we need a nginx with a set of modules and Tarantool.
Additional modules to nginx:
An example of an upstream configuration in nginx for working with Tarantool:
upstream tnt { server 127.0.0.1:3301 max_fails=1 fail_timeout=1s; keepalive 10; } Configuration of proxying data in Tarantool using post_action:
location @send_to_tnt { tnt_method http_handler; tnt_http_rest_methods all; tnt_pass_http_request on pass_body parse_args pass_headers_out; tnt_pass tnt; } location / { uuid4 $req_uuid; proxy_set_header x-request-uuid $req_uuid; add_header x-request-uuid $req_uuid always; proxy_pass http://127.0.0.1:8080/; post_action @send_to_tnt; } An example of a procedure in Tarantool that accepts input from nginx:
box.cfg { log_level = 5; listen = 3301; } log = require('log') box.once('grant', function() box.schema.user.grant('guest', 'read,write,execute', 'universe') box.schema.create_space('example') end) function http_handler(req) local headers = req.headers local body = req.body if not body then log.error('no data') return false end if not headers['x-request-uuid'] then log.error('header x-request-uuid not found') return false end local s, e = pcall(box.space.example.insert, box.space.example, {headers['x-request-uuid'], body}) if not s then log.error('can not insert error:\n%s', e) return false end return true end The solution is the small size of the Lua code and the rather simple nginx configuration. The part with the API here does not make sense to take into account, it is necessary to do it in any implementation variant. You can easily extend this master-master scheme with replication in Tarantool and load balance across multiple nodes using nginx or twemproxy.
Since post_action sends data to Tarantool a few milliseconds later than the request arrives at the API and is processed, there is one nuance in the schema. If the API works as fast as Calltouch, then you will have to make several requests to delete or time out before the request in Tarantool. We chose several requests instead of timeouts, so that our services worked without delay, as quickly as before.
Conclusion
In conclusion, you can add the fact that just nginx and the nginx_upstream_module module together with Tarantool allow you to achieve incredible flexibility and simplicity in working with http requests, high speed data access without disrupting the operation of basic services, and significant changes when implementing into existing infrastructure. The scope of tasks - from creating complex statistics to the usual save queries. Not to mention that you can use it as a regular web service and implement an API based on this module for nginx and Tarantool.
As a development for the future in Calltouch, I would like to mention the possibility of creating an interface in which you can almost instantly gain access to various data using some filters. Use real queries on tests instead of synthetic load. Debug applications in the event of problems, both to improve quality and to eliminate errors. If it is possible to have such high availability of data and flexibility in work, it is possible to increase the number of services and their quality by a negligible amount of expenses for implementing Tarantool in various products.
')
Source: https://habr.com/ru/post/326902/
All Articles