Concurrent programming with CUDA. Part 2: GPU hardware and parallel communication patterns
Content
Part 1: Introduction.
Part 2: GPU hardware and parallel communication patterns.
Part 3: GPU fundamental algorithms: convolution (reduce), scan (scan) and histogram (histogram).
Part 4: Fundamental GPU algorithms: compaction (compact), segmented scan (segmented scan), sorting. Practical application of some algorithms.
Part 5: Optimization of GPU programs.
Part 6: Examples of parallelization of sequential algorithms.
Part 7: Additional Parallel Programming Topics, Dynamic Concurrency.
Parallel communication patterns

What is parallel computing? Nothing else but a multitude of flows that solve a specific task cooperatively . The key word here is “cooperative” - to achieve cooperation, it is necessary to apply certain communication mechanisms between the streams. When using CUDA, communication takes place through memory: streams can read input data, change output data, or exchange “intermediate” results.
Depending on the way in which the threads communicate through memory, different patterns of parallel communication are distinguished.
In the previous section, the task of converting a color image to shades of gray was considered as a simple example of using CUDA. For this, the intensity of each pixel of the output image in shades of gray was calculated by the formula I = A * pix.R + B * pix.G + C * pix.B , where A, B, C are constants, pix is the corresponding pixel of the original image. Graphically, this process looks like this:

If we abstract from the very method of calculating the output value, we get the first parallel communication pattern - map : the same function is performed on each input data element, with index i , and the result is stored in the output data array under the same index i . The map template is very effective on the GPU, and moreover, it is simply expressed in the framework of CUDA - just run one thread per input element (as was done in the previous part for the task of converting an image). However, only a small part of the tasks can be solved using only this template.
If, however, several input elements are used to calculate the output value with the index i , then this pattern is called the gather , and it can look like this:

Or so:
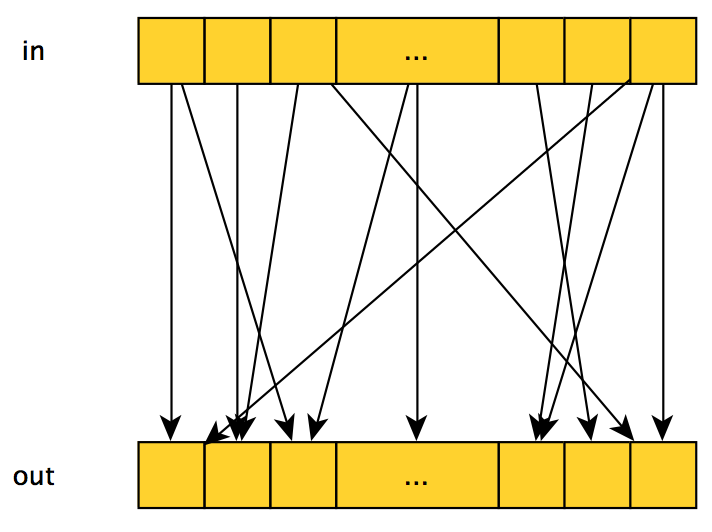
The effectiveness of the implementation of this pattern on CUDA depends on what kind of input values are used when calculating the output and their number - it is best when a small number of consecutive elements are used.
The reverse pattern, scatter - each input element affects several (or one) output elements, graphically looks like the gather , but the meaning changes: now we are “repelling” not from the output elements, for which we calculate their value, but from the input, which affect the values of certain output elements. Quite often, the same problem can be solved within the framework of both the gather pattern and the scatter . For example, if we want to average 3 neighboring input elements and write them into the output array, then we can:
- run along the stream to each output element, where each stream will average the values of 3 neighboring input elements - gather ;
- or run downstream to each input element, where each stream will add 1/3 of the value of its input element to the value of the corresponding output element - scatter .
As you most likely guessed, when using the scatter approach, a synchronization problem arises, since several streams may attempt to modify the same output element at the same time.
It is also worth highlighting the subspecies of the gather - stencil pattern: in this pattern, a restriction is imposed on the input elements that are involved in the calculation of the output element - namely, it can only be neighboring elements. In the case of 2D / 3D images, various types of this pattern can be used, for example, a two-dimensional von Neumann stencil:

or two-dimensional Moore stencil:
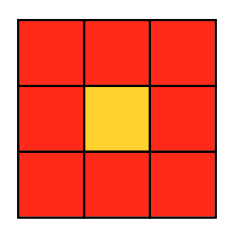
In connection with this limitation, the stencil pattern is usually quite effectively implemented within CUDA: it is enough to run one thread per output element, and the flow will read the input elements it needs. With this organization of computation, efficiency is ensured by two factors:
- All data needed for one stream is grouped in memory (in the case of a one-dimensional array, a solid “piece” of memory, in the 2D case, several pieces of memory that are at the same distance from each other).
- The value of some input element is read several times from neighboring streams (the specific number of readings depends on the selected mask) - it becomes possible to "reuse" the data provided to us by CUDA - this will be discussed later in the article.
GPU hardware
Consider the high-level structure of the GPU hardware:
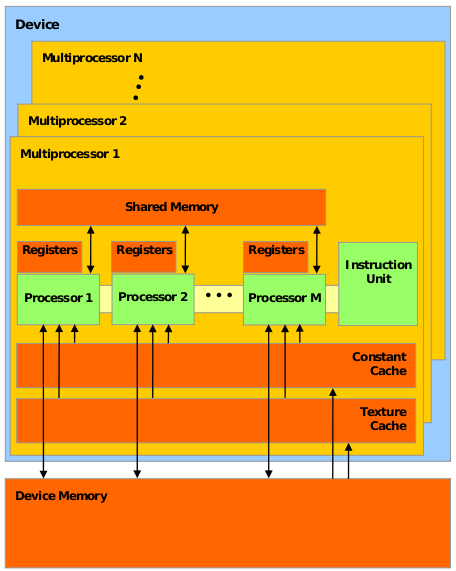
- A CUDA-compatible GPU consists of several (usually dozens) streaming multiprocessors (streaming multiprocessors), followed by SM .
- Each SM , in turn, consists of several dozen simple / streaming processors (SP) (regular / stream processors), or to put it more precisely, CUDA cores ( CUDA cores ). These guys are more like the usual CPU - they have their own registers, cache, etc. Each SM also has its own shared memory (shared memory) —a kind of additional cache that is accessible to all SPs, and can be used both as a cache for frequently used data and for “communication” between threads of a single CUDA block.
- The GPU also has its own memory, called device memory , which is common to all CUDA streams - the cudaMalloc and cudaMemcpy functions work with it
(it is also the size used by schoolchildren and GPU manufacturers tocomparewith its size).
Compliance with CUDA model and GPU hardware. CUDA Warranties
According to the CUDA model, the programmer divides the task into blocks, and blocks into threads. How does the mapping of these software entities with the above described GPU hardware blocks performed?
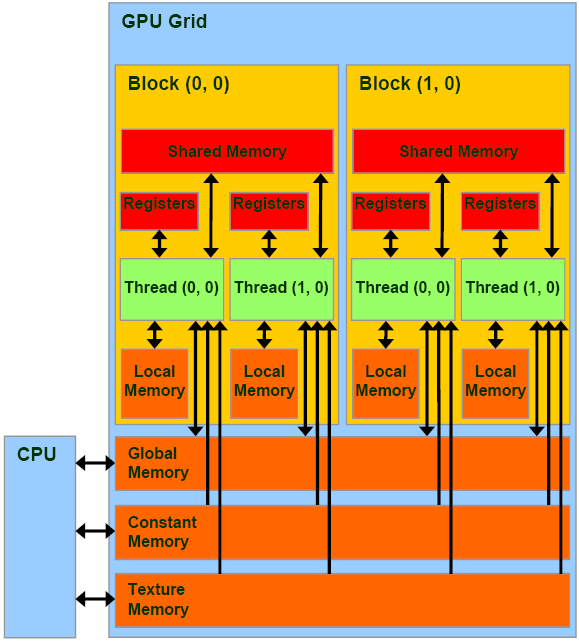
- Each block will be completely executed on the SM allocated to it.
- The distribution of blocks on the SM is engaged in the GPU, not the programmer.
- All streams of block X will be divided into groups, called warps (usually say so - warps), and executed on the SM . The size of these groups depends on the GPU model, for example, for models with the Fermi microarchitecture, it is equal to 32. All threads from the same warp are executed at the same time, occupying a certain part of the SM resources. And they either perform the same instruction (but on different data), or idle.
For all these reasons, CUDA provides the following guarantees:
- All threads in a particular block will be executed on any one SM .
- All threads of a specific kernel will be executed before the next kernel starts.
CUDA does not guarantee that:
- Any block X will be executed before / after / simultaneously with some block Y.
- Some block X will be executed on some particular SM Z.
Synchronization
So, let's list the main synchronization mechanisms provided by CUDA:
- A barrier is a point in the code of the kernel, upon reaching which a thread can “pass” further only if all the threads from its block have reached this point. Once again: the barrier allows you to synchronize only the threads of one block , and not all the threads in principle! The restriction is quite natural, because the number of blocks set by the programmer can significantly exceed the number of available SMs .
- Atomic operations are similar to atomic operations of the CPU, the full list of available operations can be found here .
- __threadfence is not exactly a synchronization primitive: when this instruction is reached, a thread can continue execution only after all its memory manipulations become visible to other threads - in effect, it forces the thread to flush the cache.
Basic principles for the effective use of CUDA
- The principle of increasing the ratio (useful time) / (time of memory operations) - was discussed in the previous article. The fraction value can be increased in two ways - to increase the numerator, to reduce the denominator: that is, you need to either do more work, or spend less time on memory operations. In addition to the obvious solution - to reduce the number of memory accesses as far as possible, the following principles of efficient work with memory are used:
- Moving frequently used data to faster memory: local stream memory > shared block memory >> shared device memory >> host memory. Thus, if several streams in the same block use the same data, it is most likely that it makes sense to move them to the common memory of the block.
- Sequential memory access: since the streams in the blocks are actually running in warp groups, provided that the streams in the same warp work with data located in memory sequentially, CUDA can read one large chunk of memory as one instruction. Otherwise, if the streams in the warp will access the data scattered in the memory, the number of memory accesses will increase.
- Reducing divergence of flows: a feature of the work of CUDA is that the threads in the same warp always either execute the same instruction or idle. Thus, if in the kernel code there is code of the form
if (threadIdx.x % 2 == 0) { ... } ...
, then half of the warp threads (those with an odd index) will wait for the other half to execute the code inside the if-a. Therefore, you should avoid such situations.
Writing a second program on CUDA
We proceed to practice. As an example illustrating the theory presented, we will write a program that performs Gaussian image blurring. The principle of operation is the following: the value of the R, G, B channels of a pixel in the output blurred image is calculated as the weighted sum of the values of the R, G, B channels of all pixels of the original image in a stencil:

The weights are calculated using the 2D Gaussian distribution, but exactly how this is done is not too important for our task.
As you can see from the description of the task, it is quite natural to choose a stencil pattern for the implementation of this algorithm, because each pixel of the output image is calculated from the corresponding neighboring pixels of the original image.
Let's start with the skeleton of the program:
main.cpp
#include <chrono> #include <iostream> #include <cstring> #include <string> #include <opencv2/core/core.hpp> #include <opencv2/highgui/highgui.hpp> #include <opencv2/opencv.hpp> #include <vector_types.h> #include "openMP.hpp" #include "CUDA_wrappers.hpp" #include "common/image_helpers.hpp" void prepareFilter(float **filter, int *filterWidth, float *filterSigma) { static const int blurFilterWidth = 9; static const float blurFilterSigma = 2.; *filter = new float[blurFilterWidth * blurFilterWidth]; *filterWidth = blurFilterWidth; *filterSigma = blurFilterSigma; float filterSum = 0.f; const int halfWidth = blurFilterWidth/2; for (int r = -halfWidth; r <= halfWidth; ++r) { for (int c = -halfWidth; c <= halfWidth; ++c) { float filterValue = expf( -(float)(c * c + r * r) / (2.f * blurFilterSigma * blurFilterSigma)); (*filter)[(r + halfWidth) * blurFilterWidth + c + halfWidth] = filterValue; filterSum += filterValue; } } float normalizationFactor = 1.f / filterSum; for (int r = -halfWidth; r <= halfWidth; ++r) { for (int c = -halfWidth; c <= halfWidth; ++c) { (*filter)[(r + halfWidth) * blurFilterWidth + c + halfWidth] *= normalizationFactor; } } } void freeFilter(float *filter) { delete[] filter; } int main( int argc, char** argv ) { using namespace cv; using namespace std; using namespace std::chrono; if( argc != 2) { cout <<" Usage: blur_image imagefile" << endl; return -1; } Mat image, blurredImage, referenceBlurredImage; uchar4 *imageArray, *blurredImageArray; prepareImagePointers(argv[1], image, &imageArray, blurredImage, &blurredImageArray, CV_8UC4); int numRows = image.rows, numCols = image.cols; float *filter, filterSigma; int filterWidth; prepareFilter(&filter, &filterWidth, &filterSigma); cv::Size filterSize(filterWidth, filterWidth); auto start = system_clock::now(); cv::GaussianBlur(image, referenceBlurredImage, filterSize, filterSigma, filterSigma, BORDER_REPLICATE); auto duration = duration_cast<milliseconds>(system_clock::now() - start); cout<<"OpenCV time (ms):" << duration.count() << endl; start = system_clock::now(); BlurImageOpenMP(imageArray, blurredImageArray, numRows, numCols, filter, filterWidth); duration = duration_cast<milliseconds>(system_clock::now() - start); cout<<"OpenMP time (ms):" << duration.count() << endl; cout<<"OpenMP similarity:" << getEuclidianSimilarity(referenceBlurredImage, blurredImage) << endl; for (int i=0; i<4; ++i) { memset(blurredImageArray, 0, sizeof(uchar4)*numRows*numCols); start = system_clock::now(); BlurImageCUDA(imageArray, blurredImageArray, numRows, numCols, filter, filterWidth); duration = duration_cast<milliseconds>(system_clock::now() - start); cout<<"CUDA time full (ms):" << duration.count() << endl; cout<<"CUDA similarity:" << getEuclidianSimilarity(referenceBlurredImage, blurredImage) << endl; } freeFilter(filter); return 0; } The points:
- We read the image file, prepare pointers to the original image and the resulting blurred image. The prepareImagePointers function remains the same; if necessary, you can view its source code on bitbucket.
- Prepare a Gaussian filter - that is, a set of our scales. We also remember the used filter parameters in order to transfer them to OpenCV and get a sample of the blurred image to verify the correctness of our algorithms.
- Call the Gauss blur function from OpenCV, save the resulting sample, measure the time spent.
- Call the Gauss blur function written using OpenMP, measure the time spent, check the result obtained with the sample. The image similarity calculation function of getEuclidianSimilarity is as follows:getEuclidianSimilarity
double getEuclidianSimilarity(const cv::Mat& a, const cv::Mat& b) { double errorL2 = cv::norm(a, b, cv::NORM_L2); double similarity = errorL2 / (double) (a.rows * a.cols); return similarity; }
In fact, it finds the average sum of squares of differences in the values of all channels of all pixels of two images. - Call the CUDA-version of the blur according to Gauss 4 times, each time measuring the time spent and checking the obtained result with the sample. Why call 4 times? The fact is that with the very first call, some time will be spent on initialization - therefore, it is better to run several times and measure the time spent on subsequent calls.
OpenMP implementation of the algorithm:
openMP.hpp
#include <stdio.h> #include <omp.h> #include <vector_types.h> #include <vector_functions.h> void BlurImageOpenMP(const uchar4 * const imageArray, uchar4 * const blurredImageArray, const long numRows, const long numCols, const float * const filter, const size_t filterWidth) { using namespace std; const long halfWidth = filterWidth/2; #pragma omp parallel for collapse(2) for (long row = 0; row < numRows; ++row) { for (long col = 0; col < numCols; ++col) { float resR=0.0f, resG=0.0f, resB=0.0f; for (long filterRow = -halfWidth; filterRow <= halfWidth; ++filterRow) { for (long filterCol = -halfWidth; filterCol <= halfWidth; ++filterCol) { //Find the global image position for this filter position //clamp to boundary of the image const long imageRow = min(max(row + filterRow, static_cast<long>(0)), numRows - 1); const long imageCol = min(max(col + filterCol, static_cast<long>(0)), numCols - 1); const uchar4 imagePixel = imageArray[imageRow*numCols+imageCol]; const float filterValue = filter[(filterRow+halfWidth)*filterWidth+filterCol+halfWidth]; resR += imagePixel.x*filterValue; resG += imagePixel.y*filterValue; resB += imagePixel.z*filterValue; } } blurredImageArray[row*numCols+col] = make_uchar4(resR, resG, resB, 255); } } } For all 3 channels of each pixel of the original image, we consider the described weighted sum, write the result to the corresponding position of the output image.
CUDA option:
CUDA.cu
#include <iostream> #include <cuda.h> #include "CUDA_wrappers.hpp" #include "common/CUDA_common.hpp" __global__ void gaussian_blur(const uchar4* const d_image, uchar4* const d_blurredImage, const int numRows, const int numCols, const float * const d_filter, const int filterWidth) { const int row = blockIdx.y*blockDim.y+threadIdx.y; const int col = blockIdx.x*blockDim.x+threadIdx.x; if (col >= numCols || row >= numRows) return; const int halfWidth = filterWidth/2; extern __shared__ float shared_filter[]; if (threadIdx.y < filterWidth && threadIdx.x < filterWidth) { const int filterOff = threadIdx.y*filterWidth+threadIdx.x; shared_filter[filterOff] = d_filter[filterOff]; } __syncthreads(); float resR=0.0f, resG=0.0f, resB=0.0f; for (int filterRow = -halfWidth; filterRow <= halfWidth; ++filterRow) { for (int filterCol = -halfWidth; filterCol <= halfWidth; ++filterCol) { //Find the global image position for this filter position //clamp to boundary of the image const int imageRow = min(max(row + filterRow, 0), numRows - 1); const int imageCol = min(max(col + filterCol, 0), numCols - 1); const uchar4 imagePixel = d_image[imageRow*numCols+imageCol]; const float filterValue = shared_filter[(filterRow+halfWidth)*filterWidth+filterCol+halfWidth]; resR += imagePixel.x * filterValue; resG += imagePixel.y * filterValue; resB += imagePixel.z * filterValue; } } d_blurredImage[row*numCols+col] = make_uchar4(resR, resG, resB, 255); } void BlurImageCUDA(const uchar4 * const h_image, uchar4 * const h_blurredImage, const size_t numRows, const size_t numCols, const float * const h_filter, const size_t filterWidth) { uchar4 *d_image, *d_blurredImage; cudaSetDevice(0); checkCudaErrors(cudaGetLastError()); const size_t numPixels = numRows * numCols; const size_t imageSize = sizeof(uchar4) * numPixels; //allocate memory on the device for both input and output checkCudaErrors(cudaMalloc(&d_image, imageSize)); checkCudaErrors(cudaMalloc(&d_blurredImage, imageSize)); //copy input array to the GPU checkCudaErrors(cudaMemcpy(d_image, h_image, imageSize, cudaMemcpyHostToDevice)); float *d_filter; const size_t filterSize = sizeof(float) * filterWidth * filterWidth; checkCudaErrors(cudaMalloc(&d_filter, filterSize)); checkCudaErrors(cudaMemcpy(d_filter, h_filter, filterSize, cudaMemcpyHostToDevice)); dim3 blockSize; dim3 gridSize; int threadNum; cudaEvent_t start, stop; cudaEventCreate(&start); cudaEventCreate(&stop); threadNum = 32; blockSize = dim3(threadNum, threadNum, 1); gridSize = dim3(numCols/threadNum+1, numRows/threadNum+1, 1); cudaEventRecord(start); gaussian_blur<<<gridSize, blockSize, filterSize>>>(d_image, d_blurredImage, numRows, numCols, d_filter, filterWidth); cudaEventRecord(stop); cudaEventSynchronize(stop); cudaDeviceSynchronize(); checkCudaErrors(cudaGetLastError()); float milliseconds = 0; cudaEventElapsedTime(&milliseconds, start, stop); std::cout << "CUDA time kernel (ms): " << milliseconds << std::endl; checkCudaErrors(cudaMemcpy(h_blurredImage, d_blurredImage, sizeof(uchar4) * numPixels, cudaMemcpyDeviceToHost)); checkCudaErrors(cudaFree(d_filter)); checkCudaErrors(cudaFree(d_image)); checkCudaErrors(cudaFree(d_blurredImage)); } - Allocate memory on the device for the original image, output image, filter. Copy the relevant data from the host memory to the allocated device memory.
- Call the core. Pay attention to the new, 3rd parameter when you call the kernel: <<< gridSize, blockSize, filterSize >>> - it sets the size of the total memory that is needed for each block. In this task, it was possible to realize the use of shared memory in two ways: either move the filter data to the common memory of the block, or move the “piece” of the image that only this block needs, since it is these data that are needed by several threads of the block at once. However, the second option is somewhat more complicated - you need to take into account that the piece of the input image that is needed for each block is slightly larger than the block itself - because we perform the gather operation, which means each stream calculates the values of one pixel of the output image using several neighboring pixels of the original image:

Therefore, I stopped at the first option, which means that each block needs exactly sizeof (float) * filterWidth * filterWidth memory to store all filter values. Moving the filter weights from the device’s memory to the block’s common memory is as follows:Hidden textextern __shared__ float shared_filter[]; if (threadIdx.y < filterWidth && threadIdx.x < filterWidth) { const int filterOff = threadIdx.y*filterWidth+threadIdx.x; shared_filter[filterOff] = d_filter[filterOff]; } __syncthreads();
Here __shared__ in the declaration of the filter weights array says that this data should be placed in the shared memory of the block; extern means that the size of the allocated memory will be set at the location of the kernel call; __syncthreads is a barrier that guarantees that all filter weights will be transferred to the common memory of the block before any of the threads of this block continues its execution. Further, all readings of the filter weights are made from the total memory of the block. - Copy the output image from the device memory to the host memory, freeing the allocated memory.
Compile, run (input image size - 557x313):
OpenCV time (ms):2 OpenMP time (ms):11 OpenMP similarity:0.00287131 CUDA time kernel (ms): 2.93245 CUDA time full (ms):32 CUDA similarity:0.00287131 CUDA time kernel (ms): 2.93402 CUDA time full (ms):4 CUDA similarity:0.00287131 CUDA time kernel (ms): 2.93267 CUDA time full (ms):4 CUDA similarity:0.00287131 CUDA time kernel (ms): 2.93312 CUDA time full (ms):4 CUDA similarity:0.00287131 As you can see, if you do not take into account the very first launch of the CUDA version, we received almost 3-fold time gain in comparison with the OpenMP option, although we did not catch up with the OpenCV option - which, by the way, uses OpenCL .
Configuration of the machine on which the tests were conducted:
Hidden text
Processor: Intel® Core (TM) i7-3615QM CPU @ 2.30GHz.
GPU: NVIDIA GeForce GT 650M, 1024 MB, 900 MHz.
RAM: DD3,2x4GB, 1600 MHz.
OS: OS X 10.9.5.
Compiler: g ++ (GCC) 4.9.2 20141029.
CUDA compiler: Cuda compilation tools, release 6.0, V6.0.1.
Supported OpenMP Version: OpenMP 4.0.
GPU: NVIDIA GeForce GT 650M, 1024 MB, 900 MHz.
RAM: DD3,2x4GB, 1600 MHz.
OS: OS X 10.9.5.
Compiler: g ++ (GCC) 4.9.2 20141029.
CUDA compiler: Cuda compilation tools, release 6.0, V6.0.1.
Supported OpenMP Version: OpenMP 4.0.
Today, everything, in the next part, will look at some of the fundamental algorithms of the GPU.
All source code is available on bitbucket .
')
Source: https://habr.com/ru/post/245523/
All Articles