Pure architecture in a go app. Part 3
From the translator: this article was written by Manuel Kiessling in September 2012, as the implementation of Uncle Bob ’s article on pure architecture with consideration for Go-specificity.
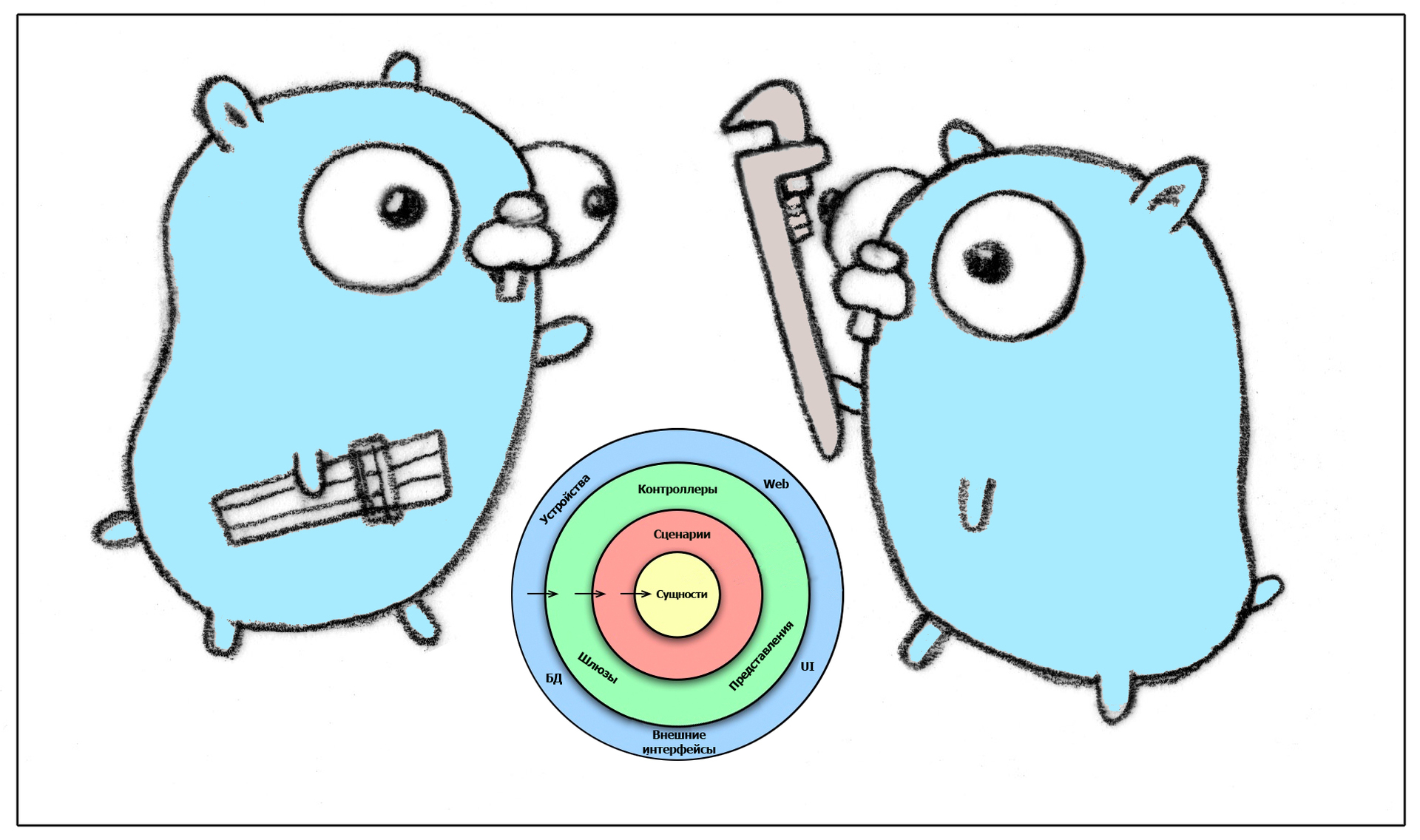
This is the third article in a series on the implementation of Pure Architecture in Go. [ Part 1 ] [ Part 2 ]
At the moment, everything that should have been said about business and Scenarios is said. Let's now look at the interface layer. While the code for the inner layers is logically located together, the interface code consists of several parts that exist separately, so we will divide the code into several files. Let's start with the web service:
')
We are not going to implement all web services here, since they all look more or less the same. In a real application, for example, we would also implement adding goods to an order, admin access to an order, etc.
The most significant thing in this code is that this code doesn’t really do anything. Interfaces, if done correctly, are quite simple, simply because their main task is simply to deliver data between layers. This is just seen in the code above. It simply essentially hides the HTTP call from the Scripting layer and passes the data from the request to it.
It should be noted once again that code injection is used here to handle dependencies. Order processing in production would be through real usecases.OrderInteractor, but in the case of testing this object is easy to clean, which allows you to test the web service in isolation, which primarily means that unit tests will test the behavior of the web service handlers.
Also, once again, I emphasize that in this code there are not many things that should be in the production code, such as authorization, validation of input parameters, sessions, cookies, etc. All this is intentionally omitted to simplify the code.
Nevertheless, it is worth saying a few words about the sessions and cookies. First of all, it should be noted that sessions and cookies are entities of different conceptual levels. A cookie is a low-level mechanism that essentially works with HTTP headers. While sessions are in some way an abstraction, allowing to work within the context of different requests in the context of a single user, which is realized, for example, through cookies.
Users, however, are an abstraction of an even higher level: “the person who interacts with the application” and this is done, including through sessions. And finally, there is a client, an entity that works in business terms, through a user who ... well, you get the idea.
I recommend doing this division by levels of abstraction explicitly and immediately, thus avoiding problems in the future. As an example of such a situation, the need to translate the session mechanism from the use of cookies to client SSL certificates. With proper abstraction, you need to add only the library for working with certificates on the infrastructure layer and the interface code for working with them in the Interfaces layer. And these changes are not affected by users or customers.
Also on the interface layer is the code that creates HTML responses based on the data that comes from the Scripting layer. In a real application, this will most likely be done with the help of a certain template engine located in the Infrastructure layer.
Let's move on to the last block, storage. We already have a working Domain layer code, we have implemented a Scripting layer responsible for data delivery and we have implemented an interface that allows users to access our application via the web. Now we have to implement the save data to disk.
This is done by implementing abstract repositories, the interfaces of which we saw on the Domain and Scripting layer. This is done on the Interfaces layer because it is the interface between the database (low-level storage implementation) and high-level business entities.
Some implementations of repositories can be isolated in dependencies on the Interfaces layer and below, for example, when implementing caching of memory objects or when implementing mocks for unit testing. However, most implementations of repositories must interact with external persistent storage mechanisms (DB), most likely through some libraries, and here we must once again make sure that we do not violate the Dependencies Rule, since libraries must be located in the Infrastructure layer.
This does not mean that the repository is isolated from the database! The repository perfectly represents what it sends to the database, but it does so in some kind of high-level representation. Get data from this table, put the data in that table. Low-level operations or “physical” such as establishing a connection to a database, taking a slave for reading or a master for writing, processing timeouts and the like are infrastructure issues.
In other words, our Storage should use some high-level interface that would hide all these low-level things.
Let's create this interface:
This is of course a very limited interface, but it allows you to perform all the necessary operations: reading, inserting, updating, and deleting records in the database.
In the Infrastructure layer, we implement some binding code that allows you to work with the database through the sqlite3 library and implements the operation of this interface. but first let's finish the Repository implementation:
I already hear from you: this is a terrible code! :) A lot of duplication, no error handling and a few other smelly things. But the meaning of this article is neither in the explanation of the style of the code, nor in the implementation of design patterns - this is all about the application's ARCHITECTURE, so the code is written in such a way that it can be easier to explain and read this article. This code is very simplified - its main and only task: to be simple and clear.
Pay attention to dbHandlers map [string] DbHandler in each repository - here each repository can use another repository without using Dependency Injection - if any of the repositories use some other implementation of dbHandlers, then the other repositories should not think about who and what uses . A sort of implementation of DI for the poor.
Let's analyze one of the most interesting methods - DbUserRepo.FindById (). This is a good example to show that in our architecture, Interfaces are all about converting data from one layer to another. FindById reads records from the database and creates objects for them at the level of Scripts and Domain. I deliberately made the representation of the User.IsAdmin attribute more complicated than necessary, storing it in the database as a varchar type field with “yes” and “no” values. At the Scenarios level, this is of course represented as a boolean value. On this discontinuity of representations between layers, we illustrate the overcoming of boundaries between data layers with different representations.
The User entity has the attribute Customer - this is essentially a reference to the Domain. The User repository simply uses the Customer repository to obtain the necessary data.
It is easy to imagine how such an architecture can help us when our application grows. By following the Rule of Dependencies, we will be able to rework the implementation of data storage without processing entities and layers. For example, we could decide that object data in the database can be stored in several tables, but the separation of data for storage and assembly for transferring objects to the application will be hidden in the repository and will not affect the other layers.
This is the third article in a series on the implementation of Pure Architecture in Go. [ Part 1 ] [ Part 2 ]
At the moment, everything that should have been said about business and Scenarios is said. Let's now look at the interface layer. While the code for the inner layers is logically located together, the interface code consists of several parts that exist separately, so we will divide the code into several files. Let's start with the web service:
')
// $GOPATH/src/interfaces/webservice.go package interfaces import ( "fmt" "io" "net/http" "strconv" "usecases" ) type OrderInteractor interface { Items(userId, orderId int) ([]usecases.Item, error) Add(userId, orderId, itemId int) error } type WebserviceHandler struct { OrderInteractor OrderInteractor } func (handler WebserviceHandler) ShowOrder(res http.ResponseWriter, req *http.Request) { userId, _ := strconv.Atoi(req.FormValue("userId")) orderId, _ := strconv.Atoi(req.FormValue("orderId")) items, _ := handler.OrderInteractor.Items(userId, orderId) for _, item := range items { io.WriteString(res, fmt.Sprintf("item id: %d\n", item.Id)) io.WriteString(res, fmt.Sprintf("item name: %v\n", item.Name)) io.WriteString(res, fmt.Sprintf("item value: %f\n", item.Value)) } } We are not going to implement all web services here, since they all look more or less the same. In a real application, for example, we would also implement adding goods to an order, admin access to an order, etc.
The most significant thing in this code is that this code doesn’t really do anything. Interfaces, if done correctly, are quite simple, simply because their main task is simply to deliver data between layers. This is just seen in the code above. It simply essentially hides the HTTP call from the Scripting layer and passes the data from the request to it.
It should be noted once again that code injection is used here to handle dependencies. Order processing in production would be through real usecases.OrderInteractor, but in the case of testing this object is easy to clean, which allows you to test the web service in isolation, which primarily means that unit tests will test the behavior of the web service handlers.
Also, once again, I emphasize that in this code there are not many things that should be in the production code, such as authorization, validation of input parameters, sessions, cookies, etc. All this is intentionally omitted to simplify the code.
Nevertheless, it is worth saying a few words about the sessions and cookies. First of all, it should be noted that sessions and cookies are entities of different conceptual levels. A cookie is a low-level mechanism that essentially works with HTTP headers. While sessions are in some way an abstraction, allowing to work within the context of different requests in the context of a single user, which is realized, for example, through cookies.
Users, however, are an abstraction of an even higher level: “the person who interacts with the application” and this is done, including through sessions. And finally, there is a client, an entity that works in business terms, through a user who ... well, you get the idea.
I recommend doing this division by levels of abstraction explicitly and immediately, thus avoiding problems in the future. As an example of such a situation, the need to translate the session mechanism from the use of cookies to client SSL certificates. With proper abstraction, you need to add only the library for working with certificates on the infrastructure layer and the interface code for working with them in the Interfaces layer. And these changes are not affected by users or customers.
Also on the interface layer is the code that creates HTML responses based on the data that comes from the Scripting layer. In a real application, this will most likely be done with the help of a certain template engine located in the Infrastructure layer.
Let's move on to the last block, storage. We already have a working Domain layer code, we have implemented a Scripting layer responsible for data delivery and we have implemented an interface that allows users to access our application via the web. Now we have to implement the save data to disk.
This is done by implementing abstract repositories, the interfaces of which we saw on the Domain and Scripting layer. This is done on the Interfaces layer because it is the interface between the database (low-level storage implementation) and high-level business entities.
Some implementations of repositories can be isolated in dependencies on the Interfaces layer and below, for example, when implementing caching of memory objects or when implementing mocks for unit testing. However, most implementations of repositories must interact with external persistent storage mechanisms (DB), most likely through some libraries, and here we must once again make sure that we do not violate the Dependencies Rule, since libraries must be located in the Infrastructure layer.
This does not mean that the repository is isolated from the database! The repository perfectly represents what it sends to the database, but it does so in some kind of high-level representation. Get data from this table, put the data in that table. Low-level operations or “physical” such as establishing a connection to a database, taking a slave for reading or a master for writing, processing timeouts and the like are infrastructure issues.
In other words, our Storage should use some high-level interface that would hide all these low-level things.
Let's create this interface:
type DbHandler interface { Execute(statement string) Query(statement string) Row } type Row interface { Scan(dest ...interface{}) Next() bool } This is of course a very limited interface, but it allows you to perform all the necessary operations: reading, inserting, updating, and deleting records in the database.
In the Infrastructure layer, we implement some binding code that allows you to work with the database through the sqlite3 library and implements the operation of this interface. but first let's finish the Repository implementation:
// $GOPATH/src/interfaces/repositories.go package interfaces import ( "domain" "fmt" "usecases" ) type DbHandler interface { Execute(statement string) Query(statement string) Row } type Row interface { Scan(dest ...interface{}) Next() bool } type DbRepo struct { dbHandlers map[string]DbHandler dbHandler DbHandler } type DbUserRepo DbRepo type DbCustomerRepo DbRepo type DbOrderRepo DbRepo type DbItemRepo DbRepo func NewDbUserRepo(dbHandlers map[string]DbHandler) *DbUserRepo { dbUserRepo := new(DbUserRepo) dbUserRepo.dbHandlers = dbHandlers dbUserRepo.dbHandler = dbHandlers["DbUserRepo"] return dbUserRepo } func (repo *DbUserRepo) Store(user usecases.User) { isAdmin := "no" if user.IsAdmin { isAdmin = "yes" } repo.dbHandler.Execute(fmt.Sprintf(`INSERT INTO users (id, customer_id, is_admin) VALUES ('%d', '%d', '%v')`, user.Id, user.Customer.Id, isAdmin)) customerRepo := NewDbCustomerRepo(repo.dbHandlers) customerRepo.Store(user.Customer) } func (repo *DbUserRepo) FindById(id int) usecases.User { row := repo.dbHandler.Query(fmt.Sprintf(`SELECT is_admin, customer_id FROM users WHERE id = '%d' LIMIT 1`, id)) var isAdmin string var customerId int row.Next() row.Scan(&isAdmin, &customerId) customerRepo := NewDbCustomerRepo(repo.dbHandlers) u := usecases.User{Id: id, Customer: customerRepo.FindById(customerId)} u.IsAdmin = false if isAdmin == "yes" { u.IsAdmin = true } return u } func NewDbCustomerRepo(dbHandlers map[string]DbHandler) *DbCustomerRepo { dbCustomerRepo := new(DbCustomerRepo) dbCustomerRepo.dbHandlers = dbHandlers dbCustomerRepo.dbHandler = dbHandlers["DbCustomerRepo"] return dbCustomerRepo } func (repo *DbCustomerRepo) Store(customer domain.Customer) { repo.dbHandler.Execute(fmt.Sprintf(`INSERT INTO customers (id, name) VALUES ('%d', '%v')`, customer.Id, customer.Name)) } func (repo *DbCustomerRepo) FindById(id int) domain.Customer { row := repo.dbHandler.Query(fmt.Sprintf(`SELECT name FROM customers WHERE id = '%d' LIMIT 1`, id)) var name string row.Next() row.Scan(&name) return domain.Customer{Id: id, Name: name} } func NewDbOrderRepo(dbHandlers map[string]DbHandler) *DbOrderRepo { dbOrderRepo := new(DbOrderRepo) dbOrderRepo.dbHandlers = dbHandlers dbOrderRepo.dbHandler = dbHandlers["DbOrderRepo"] return dbOrderRepo } func (repo *DbOrderRepo) Store(order domain.Order) { repo.dbHandler.Execute(fmt.Sprintf(`INSERT INTO orders (id, customer_id) VALUES ('%d', '%v')`, order.Id, order.Customer.Id)) for _, item := range order.Items { repo.dbHandler.Execute(fmt.Sprintf(`INSERT INTO items2orders (item_id, order_id) VALUES ('%d', '%d')`, item.Id, order.Id)) } } func (repo *DbOrderRepo) FindById(id int) domain.Order { row := repo.dbHandler.Query(fmt.Sprintf(`SELECT customer_id FROM orders WHERE id = '%d' LIMIT 1`, id)) var customerId int row.Next() row.Scan(&customerId) customerRepo := NewDbCustomerRepo(repo.dbHandlers) order := domain.Order{Id: id, Customer: customerRepo.FindById(customerId)} var itemId int itemRepo := NewDbItemRepo(repo.dbHandlers) row = repo.dbHandler.Query(fmt.Sprintf(`SELECT item_id FROM items2orders WHERE order_id = '%d'`, order.Id)) for row.Next() { row.Scan(&itemId) order.Add(itemRepo.FindById(itemId)) } return order } func NewDbItemRepo(dbHandlers map[string]DbHandler) *DbItemRepo { dbItemRepo := new(DbItemRepo) dbItemRepo.dbHandlers = dbHandlers dbItemRepo.dbHandler = dbHandlers["DbItemRepo"] return dbItemRepo } func (repo *DbItemRepo) Store(item domain.Item) { available := "no" if item.Available { available = "yes" } repo.dbHandler.Execute(fmt.Sprintf(`INSERT INTO items (id, name, value, available) VALUES ('%d', '%v', '%f', '%v')`, item.Id, item.Name, item.Value, available)) } func (repo *DbItemRepo) FindById(id int) domain.Item { row := repo.dbHandler.Query(fmt.Sprintf(`SELECT name, value, available FROM items WHERE id = '%d' LIMIT 1`, id)) var name string var value float64 var available string row.Next() row.Scan(&name, &value, &available) item := domain.Item{Id: id, Name: name, Value: value} item.Available = false if available == "yes" { item.Available = true } return item } I already hear from you: this is a terrible code! :) A lot of duplication, no error handling and a few other smelly things. But the meaning of this article is neither in the explanation of the style of the code, nor in the implementation of design patterns - this is all about the application's ARCHITECTURE, so the code is written in such a way that it can be easier to explain and read this article. This code is very simplified - its main and only task: to be simple and clear.
Pay attention to dbHandlers map [string] DbHandler in each repository - here each repository can use another repository without using Dependency Injection - if any of the repositories use some other implementation of dbHandlers, then the other repositories should not think about who and what uses . A sort of implementation of DI for the poor.
Let's analyze one of the most interesting methods - DbUserRepo.FindById (). This is a good example to show that in our architecture, Interfaces are all about converting data from one layer to another. FindById reads records from the database and creates objects for them at the level of Scripts and Domain. I deliberately made the representation of the User.IsAdmin attribute more complicated than necessary, storing it in the database as a varchar type field with “yes” and “no” values. At the Scenarios level, this is of course represented as a boolean value. On this discontinuity of representations between layers, we illustrate the overcoming of boundaries between data layers with different representations.
The User entity has the attribute Customer - this is essentially a reference to the Domain. The User repository simply uses the Customer repository to obtain the necessary data.
It is easy to imagine how such an architecture can help us when our application grows. By following the Rule of Dependencies, we will be able to rework the implementation of data storage without processing entities and layers. For example, we could decide that object data in the database can be stored in several tables, but the separation of data for storage and assembly for transferring objects to the application will be hidden in the repository and will not affect the other layers.
Source: https://habr.com/ru/post/271157/
All Articles