Intervals in C ++, part 3: we represent incrementors (Iterable)
In previous posts I described the problems I encountered when creating a library for working with intervals. Now I will describe to you my solution: improvements to the concept of intervals, which allow you to create intervals with delimiters and infinite intervals that fit perfectly into the hierarchy of the standard library without loss of performance.
At the end of the previous post, I summarized the shortcomings of the existing intervals:
The first problem is especially difficult, so let's start with it.
To begin with, let's strictly define the concept of an interval. In the C ++ standard, this word is used everywhere, but it is not defined anywhere. It can be understood that an interval is something from which begin and end can be extracted, a couple of iterators that are designed so that end can be reached by starting from begin. In terms of my proposal, this concept can be formalized as follows:
')
There are also improvements to the Range interval concept called InputRange, ForwardRange, etc. In fact, they simply require more from their iterators. The entire hierarchy is shown below.
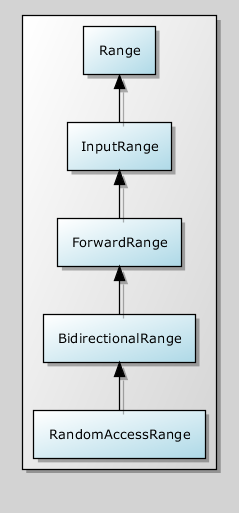
These concepts are the basis for the Boost.Range library (http://www.boost.org/libs/range)
If you remember, to implement intervals both with a limiter and infinite, in the form of a pair of iterators, the end iterator must be a signal one. And such an iterator is more of a concept than the physical position of an element in a sequence. You can think of it as an element with the “last + 1” position — the only difference is that you don’t know where its position is until you reach it. Since the type of signal iterator is the same as that of a normal one, a check at the program execution stage is required to determine if this iterator is a signal iterator. This leads to slow comparison of iterators and inconvenient implementations of methods.
What are iterators for? We increase them, dereference and compare, right? And what can be done with the signal iterator? Not really a lot of things. His position does not change, it cannot be dereferenced, because his position is always “last + 1”. But it can be compared with an iterator. It turns out that the signal iterator is a weak iterator.
The problem with intervals is that we are trying to turn a signal iterator into a regular one. But he is not. So let's not do it - let them be a different type .
The concept of Range requires that begin and end be of the same type. If you can make them different, it will already be a weaker concept - the concept of Iterable. Incrementors are like iterators, only begin and end have different types. Concept:
Naturally, the Range concept is part of the Iterable concept. It simply refines it by adding a constraint on the equality of the begin and end types.
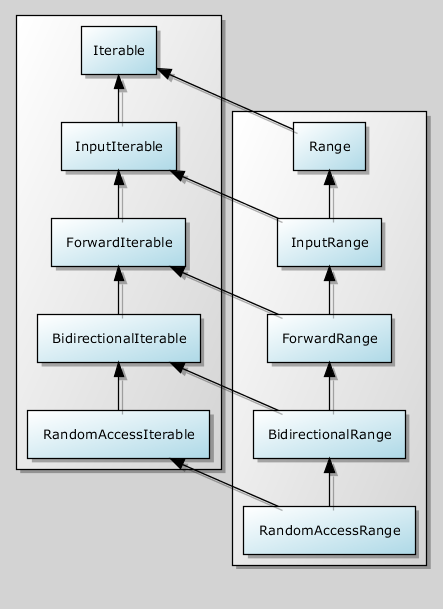
This is the hierarchy, if we consider intervals, incrementors and iterators, but it is not necessary to define them exactly in the program as well. Notice that “intervalness” —that is, the similarity of the begin and end types is orthogonal to the strength of the begin iterator. When we need to include a RandomAccessRange simulation in the code, we can say it requires a RandomAccessIterable && Range and just change the whole concept.
The difference between, for example, BidirectionalIterable and ForwardIterable in the concept modeled by the iterator begin from Iterator.
But wait, because the STL algorithms will not work with incrementors, because they want begin and end to have the same type. And there is. Therefore, I have gone through the entire STL to check what can be rewritten. For example, std :: find
Now std :: find uses Ranges. But note that the algorithm does not attempt to change the position of the end iterator. The search algorithm can be easily changed so that it works with Iterables instead of Ranges:
That's all - the change is so small that it is difficult to even notice.
So which C ++ 98 algorithms can be adapted to work with Iterables instead of Ranges? It turns out almost everything. It is easier to list those that are not amenable. It:
The remaining fifty require a purely mechanical change in the code. Having defined the concept of Iterable as it is defined in the Range, we give any algorithm that works with Iterable to work with Ranges in the same way. This is useful and important - there is too much code written for iterators to do for them some kind of incompatible abstraction.
And what will we get? Let's return to our C-lines. I described the c_string_range class and found that enumerating characters generates bad code. We start again, only using range_facade, to build Iterable instead of Range.
The code is much simpler than the old one. All work is done by range_facade. The iterator and signal iterator are implemented as primitives. To test it, I generated optimized machine code for the following functions, one of which uses the old c_string_range class, and the other the new c_string_iterable:
Even without knowing the assembler, you can understand the difference.
The incrementor code is much cooler. And it is almost identical with the assembler obtained from the naked iterator C.
But what does the comparison of two objects of different types for equivalence mean?
A little for the uninitiated: N3351 determines in which cases comparisons of different types are permissible. It is not enough that the syntax "x == y" is valid and gives a boolean value. If x and y have different types, then these types must be EqualityComparable by themselves, and they must have a general type to which they can be converted, and it must also be EqualityComparable. Suppose we compare char and short. This is possible because they are EqualityComparable, and they can be converted to an int, which is also EqualityComparable.
Iterators can be compared, and signal iterators are compared in a trivial way. The difficulty is to find a common type for them. In general, each iterator and signal has a common type that can be created like this: suppose the existence of a new type of iterator I, which is a type-sum, and contains either an iterator or a signal iterator. When they are compared, it behaves semantically as if both of them were first converted into two objects of type I, let's call them lhs and rhs, and then compare them with the following label:
This label resembles the one that turned out when analyzing the behavior of the comparison operator c_string_range :: iterator . This is not by accident - it was a special case of this more general scheme. It confirms the intuitive conclusion that you can already notice by looking at my two classes, c_string_range and c_string_iterable. One is a pair of iterators, the other is a pair of iterators / signalers, but their work patterns are similar. We feel that it is possible to build an equivalent Range from any Iterable, if we donate a small bit of speed. And now we have found confirmation of this.
The ability to compare iterators and signal iterators directly allows us to use the C ++ type system to optimize a large category of iterations, removing the ramifications in the parity comparison operator.
The idea of giving different types of begin and end is not new, and it was not me who invented it. I learned about it from Dave Abrahams many years ago. Recently, a similar idea was filed by Dietmar Kuehl on the Ranges mailing list, and in response to his letter, Sean Parent expressed the following objection:
If I understood him correctly, he talks about the existence of three parallel concepts of intervals: IteratorRange, CountedRange and SentinelRange. And these hierarchies do not need to try to link together. The copying algorithm should contain three different implementations, one for each concept. Then you have to triple the order of 50 algorithms - and this is too much repetition in the code.
Worse, some algorithms are based on refined concepts. For example, in libc ++, the rotate algorithm chooses one of three implementations, depending on whether you pass it direct, bidirectional, or random access iterators. And to enable three different implementations of Iterator, Counted and SentinelRanges would require 9 rotate algorithms! With all due respect, this is insane.
At the beginning of the post I gave a list of problems associated with intervals with paired iterators. I showed a new concept, Iterable, which deals with performance issues, and raised the issue of the complexity of implementing intervals. So far I have not described how this concept works at infinite intervals, as we will discuss in the fourth, final post.
All code can be found in the github repository.
I would like to thank Andrew Sutton for helping with Concpets Lite syntax and for explaining the requirements of the EqualityComparable concept for different types and general improvement and formalization of many ideas. Articles have become much better thanks to his great contribution.
Other articles of the cycle
Intervals in C ++, part 1: Intervals with limiters
Intervals in C ++, part 2: Infinite intervals
Intervals in C ++, part 4: to infinity and beyond
At the end of the previous post, I summarized the shortcomings of the existing intervals:
- spacing with limiters and infinite spans generates bad code
- they have to model weaker concepts than they could
- You can easily transfer an infinite interval to an algorithm that does not digest it.
- they are difficult to use
- intervals that can be infinite or very large can cause an overflow in difference_type
The first problem is especially difficult, so let's start with it.
Spacing concept
To begin with, let's strictly define the concept of an interval. In the C ++ standard, this word is used everywhere, but it is not defined anywhere. It can be understood that an interval is something from which begin and end can be extracted, a couple of iterators that are designed so that end can be reached by starting from begin. In terms of my proposal, this concept can be formalized as follows:
')
using std::begin; using std::end; template<typename T> using Iterator_type = decltype(begin(std::declval<T>())); template<typename T> concept bool Range = requires(T range) { { begin(range) } -> Iterator_type<T>; { end(range) } -> Iterator_type<T>; requires Iterator<Iterator_type<T>>; }; There are also improvements to the Range interval concept called InputRange, ForwardRange, etc. In fact, they simply require more from their iterators. The entire hierarchy is shown below.
These concepts are the basis for the Boost.Range library (http://www.boost.org/libs/range)
Problem 1: Bad Code Generation
If you remember, to implement intervals both with a limiter and infinite, in the form of a pair of iterators, the end iterator must be a signal one. And such an iterator is more of a concept than the physical position of an element in a sequence. You can think of it as an element with the “last + 1” position — the only difference is that you don’t know where its position is until you reach it. Since the type of signal iterator is the same as that of a normal one, a check at the program execution stage is required to determine if this iterator is a signal iterator. This leads to slow comparison of iterators and inconvenient implementations of methods.
Incremental concept
What are iterators for? We increase them, dereference and compare, right? And what can be done with the signal iterator? Not really a lot of things. His position does not change, it cannot be dereferenced, because his position is always “last + 1”. But it can be compared with an iterator. It turns out that the signal iterator is a weak iterator.
The problem with intervals is that we are trying to turn a signal iterator into a regular one. But he is not. So let's not do it - let them be a different type .
The concept of Range requires that begin and end be of the same type. If you can make them different, it will already be a weaker concept - the concept of Iterable. Incrementors are like iterators, only begin and end have different types. Concept:
template<typename T> using Sentinel_type = decltype(end(std::declval<T>())); template<typename T> concept bool Iterable = requires(T range) { { begin(range) } -> Iterator_type<T>; { end(range) } -> Sentinel_type<T>; requires Iterator<Iterator_type<T>>; requires EqualityComparable< Iterator_type<T>, Sentinel_type<T>>; }; template<typename T> concept bool Range = Iteratable<T> && Same<Iterator_type<T>, Sentinel_type<T>>; Naturally, the Range concept is part of the Iterable concept. It simply refines it by adding a constraint on the equality of the begin and end types.
This is the hierarchy, if we consider intervals, incrementors and iterators, but it is not necessary to define them exactly in the program as well. Notice that “intervalness” —that is, the similarity of the begin and end types is orthogonal to the strength of the begin iterator. When we need to include a RandomAccessRange simulation in the code, we can say it requires a RandomAccessIterable && Range and just change the whole concept.
The difference between, for example, BidirectionalIterable and ForwardIterable in the concept modeled by the iterator begin from Iterator.
Iterable and STL algorithms
But wait, because the STL algorithms will not work with incrementors, because they want begin and end to have the same type. And there is. Therefore, I have gone through the entire STL to check what can be rewritten. For example, std :: find
template<class InputIterator, class Value> InputIterator find(InputIterator first, InputIterator last, Value const & value) { for (; first != last; ++first) if (*first == value) break; return first; } Now std :: find uses Ranges. But note that the algorithm does not attempt to change the position of the end iterator. The search algorithm can be easily changed so that it works with Iterables instead of Ranges:
template<class InputIterator, class Sentinel, class Value> InputIterator find(InputIterator first, Sentinel last, Value const & value) { for (; first != last; ++first) if (*first == value) break; return first; } That's all - the change is so small that it is difficult to even notice.
So which C ++ 98 algorithms can be adapted to work with Iterables instead of Ranges? It turns out almost everything. It is easier to list those that are not amenable. It:
- copy_backward
- algorithms for working with sets and pyramids (push_heap, pop_heap, make_heap, sort_heap)
- inplace_merge
- nth_element
- partial_sort and partial_sort_copy
- next_permutation and prev_permutation
- random_shuffle
- reverse and reverse_copy
- sort and stable_sort
- stable_partition
The remaining fifty require a purely mechanical change in the code. Having defined the concept of Iterable as it is defined in the Range, we give any algorithm that works with Iterable to work with Ranges in the same way. This is useful and important - there is too much code written for iterators to do for them some kind of incompatible abstraction.
Perf Proof
And what will we get? Let's return to our C-lines. I described the c_string_range class and found that enumerating characters generates bad code. We start again, only using range_facade, to build Iterable instead of Range.
using namespace ranges; struct c_string_iterable : range_facade<c_string_iterable> { private: friend range_core_access; char const *sz_; char const & current() const { return *sz_; } void next() { ++sz_; } bool done() const { return *sz_ == 0; } bool equal(c_string_iterable const &that) const { return sz_ == that.sz_; } public: c_string_iterable(char const *sz) : sz_(sz) {} }; The code is much simpler than the old one. All work is done by range_facade. The iterator and signal iterator are implemented as primitives. To test it, I generated optimized machine code for the following functions, one of which uses the old c_string_range class, and the other the new c_string_iterable:
// Range-based int range_strlen( c_string_range::iterator begin, c_string_range::iterator end) { int i = 0; for(; begin != end; ++begin) ++i; return i; } // Iterable-based int iterable_strlen( range_iterator_t<c_string_iterable> begin, range_sentinel_t<c_string_iterable> end) { int i = 0; for(; begin != end; ++begin) ++i; return i; } Even without knowing the assembler, you can understand the difference.
| |
The incrementor code is much cooler. And it is almost identical with the assembler obtained from the naked iterator C.
Iterators, signal iterators, and parity
But what does the comparison of two objects of different types for equivalence mean?
A little for the uninitiated: N3351 determines in which cases comparisons of different types are permissible. It is not enough that the syntax "x == y" is valid and gives a boolean value. If x and y have different types, then these types must be EqualityComparable by themselves, and they must have a general type to which they can be converted, and it must also be EqualityComparable. Suppose we compare char and short. This is possible because they are EqualityComparable, and they can be converted to an int, which is also EqualityComparable.
Iterators can be compared, and signal iterators are compared in a trivial way. The difficulty is to find a common type for them. In general, each iterator and signal has a common type that can be created like this: suppose the existence of a new type of iterator I, which is a type-sum, and contains either an iterator or a signal iterator. When they are compared, it behaves semantically as if both of them were first converted into two objects of type I, let's call them lhs and rhs, and then compare them with the following label:
| lhs signal iterator? | rhs signal iterator? | lhs == rhs? |
| true | true | true |
| true | false | done (rhs.iter) |
| false | true | done (lhs.iter) |
| false | false | lhs.iter == rhs.iter |
This label resembles the one that turned out when analyzing the behavior of the comparison operator c_string_range :: iterator . This is not by accident - it was a special case of this more general scheme. It confirms the intuitive conclusion that you can already notice by looking at my two classes, c_string_range and c_string_iterable. One is a pair of iterators, the other is a pair of iterators / signalers, but their work patterns are similar. We feel that it is possible to build an equivalent Range from any Iterable, if we donate a small bit of speed. And now we have found confirmation of this.
The ability to compare iterators and signal iterators directly allows us to use the C ++ type system to optimize a large category of iterations, removing the ramifications in the parity comparison operator.
Objections
The idea of giving different types of begin and end is not new, and it was not me who invented it. I learned about it from Dave Abrahams many years ago. Recently, a similar idea was filed by Dietmar Kuehl on the Ranges mailing list, and in response to his letter, Sean Parent expressed the following objection:
I think we assign too much to iterators. Algorithms that work with termination based on checking a signal iterator or based on counting are different entities. See copy_n () and copy_sentinel ()
stlab.adobe.com/copy_8hpp.html
Regarding the intervals - I'm sure that you can build it with:
- iterator pairs
- iterator and quantity
- iterator and signal
And in this case, copy (r, out) can produce the desired algorithm.
If I understood him correctly, he talks about the existence of three parallel concepts of intervals: IteratorRange, CountedRange and SentinelRange. And these hierarchies do not need to try to link together. The copying algorithm should contain three different implementations, one for each concept. Then you have to triple the order of 50 algorithms - and this is too much repetition in the code.
Worse, some algorithms are based on refined concepts. For example, in libc ++, the rotate algorithm chooses one of three implementations, depending on whether you pass it direct, bidirectional, or random access iterators. And to enable three different implementations of Iterator, Counted and SentinelRanges would require 9 rotate algorithms! With all due respect, this is insane.
Total
At the beginning of the post I gave a list of problems associated with intervals with paired iterators. I showed a new concept, Iterable, which deals with performance issues, and raised the issue of the complexity of implementing intervals. So far I have not described how this concept works at infinite intervals, as we will discuss in the fourth, final post.
All code can be found in the github repository.
Thanks
I would like to thank Andrew Sutton for helping with Concpets Lite syntax and for explaining the requirements of the EqualityComparable concept for different types and general improvement and formalization of many ideas. Articles have become much better thanks to his great contribution.
Other articles of the cycle
Intervals in C ++, part 1: Intervals with limiters
Intervals in C ++, part 2: Infinite intervals
Intervals in C ++, part 4: to infinity and beyond
Source: https://habr.com/ru/post/264975/
All Articles