Code generation at runtime or “Writing your JIT compiler”
Modern compilers are very good at optimizing code. They remove the conditional jumps that are never executed, calculate constant expressions, get rid of senseless arithmetic operations (multiplication by 1, addition with 0). They operate on data known at the time of compilation.
At the time of execution of information about the processed data is much more. Based on it, you can perform additional optimizations and speed up the program.
The algorithm optimized for a particular case always works faster than the universal one (at least, not more slowly).
What if for each set of input data to generate the optimal algorithm for processing this data?
Obviously, some of the execution time will be spent on optimization, but if the optimized code is executed frequently, the costs will be repaid with interest.
How technically to do this? Quite simply, the program includes a mini-compiler that generates the necessary code. The idea is not new, the technology is called “compile time” or JIT compilation. The key role of JIT compilation plays in virtual machines and interpreters of programming languages. Frequently used parts of the code (or bytecode) are converted to machine instructions, which can greatly improve performance.
Java, Python, C #, JavaScript, Flash ActionScript - an incomplete (completely incomplete) list of languages in which it is used. I propose to solve a specific problem using this technology and see what happens.
Task
The task is to take the implementation of the interpreter of mathematical expressions. At the entrance we have a string like
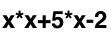
and the number is the value of x. The output should get a number - the value of the expression at this value of x. For simplicity, we will process only four operators - '+', '-', '*', '/'.
')
At this stage, it is not yet clear how to compile this expression at all, because the string is not the most convenient way to work. For analysis and computation, a parse tree is better suited, in our case, a binary tree.
For the original expression, it will look like this:
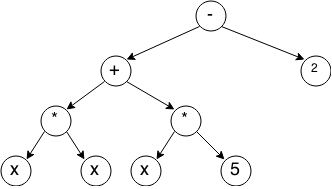
Each node in the tree is an operator, its children are operands. In the leaves of the tree are constants and variables.
The simplest algorithm for constructing such a tree is recursive descent - at each stage we find the operator with the lowest priority, divide the expression into two parts - before this operator and after, and recursively call the construction operation for these parts. Step-by-step illustration of the algorithm:
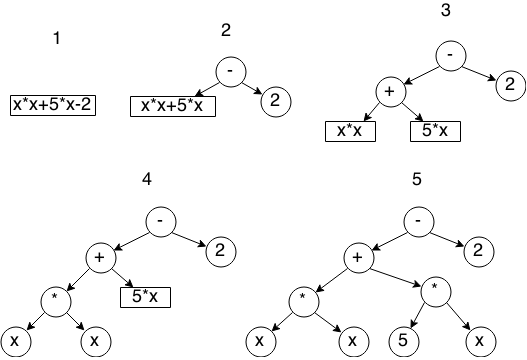
I will not give here the implementation of the algorithm for a simple reason - it is quite large, and the article is not about that.
A tree consists of nodes, each of which will be represented by a TreeNode structure
typedef struct TreeNode TreeNode ;
struct TreeNode
{
TreeNodeType type ; // node type
TreeNode * left ; // link to the left child
TreeNode * right ; // link for the right child
float value ; // value (for constant node)
} ;
Here are all possible node types:
typedef enum
{
OperatorPlus , // Operator Plus
OperatorMinus , // Operator minus
OperatorMul , // Operator multiply
OperatorDiv , // Operator split
OperandConst , // Operand is a constant
OperandVar , // Operand is a variable
OperandNegVar , // Operand is a variable taken with a minus (for processing a unary minus)
} TreeNodeType ;
The value of the expression for a given x is calculated very simply - with the help of a depth traversal.
This is also implemented using recursion.
float calcTreeFromRoot ( TreeNode * root , float x )
{
if ( root -> type == OperandVar )
return x ;
if ( root -> type == OperandNegVar )
return - x ;
if ( root -> type == OperandConst )
return root -> value ;
switch ( root -> type )
{
case OperatorPlus :
return calcTreeFromRoot ( root -> left , x ) + calcTreeFromRoot ( root -> right , x ) ;
case OperatorMinus :
return calcTreeFromRoot ( root -> left , x ) - calcTreeFromRoot ( root -> right , x ) ;
case OperatorMul :
return calcTreeFromRoot ( root -> left , x ) * calcTreeFromRoot ( root -> right , x ) ;
case OperatorDiv :
return calcTreeFromRoot ( root -> left , x ) / calcTreeFromRoot ( root -> right , x ) ;
}
}
What is the current situation?
- Tree is generated for the expression
- If it is necessary to calculate the value of the expression, the recursive function calcTreeFromRoot is called.
What would the code look like if we knew the expression at the assembly stage?
float calcExpression ( float x )
{
return x * x + 5 * x - 2 ;
}
Calculating the value of an expression in this case comes down to calling one very simple function — many times faster than recursively traversing the tree.
Compile time!
I want to note that I will generate code for the x86 platform focusing on architecture processors similar to IA32. In addition, I will take a float size of 4 bytes, an int size of 4 bytes.
Theory
So, our task is to get the usual C function, which can be called if necessary.
To begin with, let's define its prototype:
typedef float _cdecl ( * Func ) ( float ) ;
Now the Func data type is a pointer to a function that returns a value of type float and takes one argument, also of type float.
_cdecl indicates that the C-declaration calling convention is used.
This is the standard calling convention for the C language:
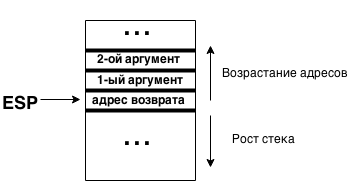
- arguments are passed through the stack from right to left (when called on the top of the stack, the first argument should appear)
- integer values are returned via the EAX register
- floating point values are returned through the st0 register
- for the safety of the registers eax, edx, ecx is responsible for the calling function
- the rest of the registers must be restored by the called function
The function call looks like this:
push ebp // Save the stack frame pointer
push arg3 // Put the arguments on the stack in order from right to left (the first argument is at the end)
push arg2
push arg1
call func // self call
add esp , 0xC // Restore the pointer to the stack (3 arguments of 4 bytes just take 0xC bytes)
pop ebp // Restore the stack frame pointer
Stack status at the time of call:
How do we generate the code that evaluates the expression? Time to remember that there is such a thing as a stack calculator. How does he work? At the entrance serves numbers and operators. The algorithm is elementary:
- We met a constant or variable - put it on the stack
- The operator was met - 2 operands were removed from the stack, the operation was performed, the result was put on the stack
But it is necessary to feed the stack calculator in a certain way - it works with the expressions presented in the reverse Polish notation. Its peculiarity lies in the fact that the operands are written first, then the operator. Thus, our original expression will appear as follows:

The program for the stack calculator corresponding to the expression:
push x
push x
mul
push 5
push x
mul
add
push 2
sub
Much like a program in assembler, is not it?
It turns out that it is enough to translate the expression into reverse Polish notation and create code following the elementary rules.
Translation is very simple to perform - we already have a parse tree built, we just need to perform a depth crawl, and when we exit the vertex, generate the corresponding action - we get a sequence of commands in the order we need.
Pseudocode of this action:
static void generateCodeR ( TreeNode * root , ByteArray * code )
{
if ( root -> left & amp ; & amp ; root -> right )
{
generateCodeR ( root -> right , code ) ; // Must be generated first
generateCodeR ( root -> left , code ) ; // code to calculate child elements
}
// Generate code for parent element
if ( root -> type == OperandVar )
{
code + = "push x" ; // Put the value of the argument (variable) on the stack
}
else if ( root -> type == OperandNegVar )
{
code + = "push -x" ; // Put the value of the argument on the stack with a change of sign
}
else if ( root -> type == OperandConst )
{
code + = "push" + root -> value ; // Put a constant in the stack
}
else
{
code + = "pop" ; // Remove from the stack
code + = "pop" ; // two values
switch ( root -> type )
{
case OperatorPlus :
code + = "add" ; // perform addition
break ;
case OperatorMinus :
code + = "sub" ; // Perform Subtraction
break ;
case OperatorMul :
code + = "mul" ; // Perform Multiplication
break ;
case OperatorDiv :
code + = "div" ; // Perform Division
break ;
}
code + = "push result" // Save the result of a mathematical operation on the stack
}
}
Implementation
First, let's define the stack: everything is simple with it - the esp register contains a pointer to the vertex. To put something there, just run the command
push { value }
or subtract the number 4 from ESP and write the desired value at the received address
sub esp , 4
mov [ esp ] , { value }
Removing from the stack is performed by the pop command or by adding the number 4 to esp.
I used to mention a calling convention. Thanks to him, we can know exactly where the only function argument will be. At the esp address (at the top), the return address will be located, and at the esp address, 4 will be the argument value. Since the call to it will occur relatively often, you can put it in the eax register:
mov eax , [ esp - 4 ] ;
Now, a little about working with floating point numbers. We will use the x87 FPU instruction set.
An FPU has 8 registers that form a stack. Each of them holds 80 bits. Appeal to the top of this stack is through the register st0. Accordingly, the register st1 addresses the next highest value in this stack, st2 is the next and so on up to st7.
FPU stack:

To load the value on top, use the fld command. The operand of this command can only be the value stored in memory.
fld [ esp ] // Load the value stored at the address contained in esp into st0
Commands for performing arithmetic operations are very simple: fadd, fsub, fmul, fdiv. They can have many different combinations of arguments, but we will use them only this way:
fadd dword ptr [ esp ]
fsub dword ptr [ esp ]
fmul dword ptr [ esp ]
fdiv dword ptr [ esp ]
In all these cases, the value from [esp] is loaded, the necessary operation is performed, the result is stored in st0.
Removing the value from the stack is also simple:
fstp [ esp ] // Delete the value from the top of the FPU stack and save it to the memory location at the address lying in esp
Recall that in the expression there can be a variable x with a unary minus. To process it, you need to change the sign. For this, the FCHS command comes in handy - it inverts the bit of the register character st0
For each of these commands, we define the function that generates the necessary opcodes:
void genPUSH_imm32 ( ByteArray * code , int32_t * pValue ) ;
void genADD_ESP_4 ( ByteArray * code ) ;
void genMOV_EAX_PTR_ESP_4 ( ByteArray * code ) ;
void genFSTP ( ByteArray * code , void * dstAddress ) ;
void genFLD_DWORD_PTR_ESP ( ByteArray * code ) ;
void genFADD_DWORD_PTR_ESP ( ByteArray * code ) ;
void genFSUB_DWORD_PTR_ESP ( ByteArray * code ) ;
void genFMUL_DWORD_PTR_ESP ( ByteArray * code ) ;
void genFCHS ( ByteArray * code ) ;
In order for the code-calculator to work normally and return the value, add the corresponding instructions before it and after it. The whole generateCode wrapper function collects this whole thing:
void generateCode ( Tree * tree , ByteArray * resultCode )
{
ByteArray * code = resultCode ;
genMOV_EAX_ESP_4 ( code ) ; // Put the value of the argument in eax
generateCodeR ( tree -> root , code ) ; // Generate a code calculator
genFLD_DWORD_PTR_ESP ( code ) ;
genADD_ESP_4 ( code ) ; // Remove the extra double word from the stack
genRET ( code ) ; // Exit the function
}
The final form of the function of generating code that calculates the value of the expression:
void generateCodeR ( TreeNode * root , ByteArray * resultCode )
{
ByteArray * code = resultCode ;
if ( root -> left & amp ; & amp ; root -> right )
{
generateCodeR ( root -> right , code ) ;
generateCodeR ( root -> left , code ) ;
}
if ( root -> type == OperandVar )
{
genPUSH_EAX ( code ) ; // In eax, the function argument is
}
else if ( root -> type == OperandNegVar )
{
genPUSH_EAX ( code ) ; // load the stack
genFLD_DWORD_PTR_ESP ( code ) ; // Change
genFCHS ( code ) ; //sign
genFSTP_DWORD_PTR_ESP ( code ) ; // return to the stack
}
else if ( root -> type == OperandConst )
{
genPUSH_imm32 ( code , ( int32_t * ) & amp ; root -> value ) ;
}
else
{
genFLD_DWORD_PTR_ESP ( code ) ; // Load the left operand in the FPU ..
genADD_ESP_4 ( code ) ; // ... and remove it from the stack
switch ( root -> type )
{
case OperatorPlus :
genFADD_DWORD_PTR_ESP ( code ) ; // Perform addition (the result is saved in st0)
break ;
case OperatorMinus :
genFSUB_DWORD_PTR_ESP ( code ) ; // Perform subtraction (the result is saved in st0)
break ;
case OperatorMul :
genFMUL_DWORD_PTR_ESP ( code ) ; // Perform multiplication (the result is saved in st0)
break ;
case OperatorDiv :
genFDIV_DWORD_PTR_ESP ( code ) ; // Perform division (the result is saved in st0)
break ;
}
genFSTP_DWORD_PTR_ESP ( code ) ; // Save the result to the stack (st0 - & gt; [esp])
}
}
By the way, about the buffer for storing code. For these purposes, I created the ByteArray container type:
typedef struct
{
int size ; // Size of allocated memory
int dataSize ; // Actual size of stored data
char * data ; // Pointer to the data
} ByteArray ;
ByteArray * byteArrayCreate ( int initialSize ) ;
void byteArrayFree ( ByteArray * array ) ;
void byteArrayAppendData ( ByteArray * array , const char * data , int dataSize ) ;
It allows you to add data to the end and not to think about the allocation of memory - a kind of dynamic array.
If you generate code using generateCode () and transfer control to it, the program is likely to crash. The reason is simple - the lack of permission to perform. I write under Windows, so the WinAPI function VirtualProtect will help me here, allowing me to set permissions for a memory region (or rather, for memory pages).
In MSD, it is described as:
BOOL WINAPI VirtualProtect (
_In_ LPVOID lpAddress , // Address of the beginning of the region in memory
_In_ SIZE_T dwSize , // Size of region in memory
_In_ DWORD flNewProtect , // New access parameters for pages in the region
_Out_ PDWORD lpflOldProtect // Pointer to a variable, where to save the old access parameters
) ;
It is used in the main compiler function:
CompiledFunc compileTree ( Tree * tree )
{
CompiledFunc result ;
DWORD oldP ;
ByteArray * code ;
code = byteArrayCreate ( 2 ) ; // Initial container size - 2 bytes
generateCode ( tree , code ) ; // Generate code
VirtualProtect ( code -> data , code -> dataSize , PAGE_EXECUTE_READWRITE , & oldP ) ; // We give the right to perform
result. code = code ;
result. run = ( Func ) result. code -> data ;
return result ;
}
CompiledFunc is a structure for conveniently storing code and a function pointer:
typedef struct
{
ByteArray * code ; // Container with code
Func run ; // function pointer
} CompiledFunc ;
The compiler is written and it is very easy to use:
Tree * tree ;
CompiledFunc f ;
float result ;
tree = buildTreeForExpression ( "x + 5" ) ;
f = compileTree ( tree ) ;
result = f. run ( 5 ) ; // result = 10
It remains only to test for speed.
Testing
When testing, I will compare the running time of the compiled code and the recursive calculation algorithm based on the tree. We will measure the time using the clock () function from the standard library. To calculate the time of the code section, it is enough to save the result of its call before and after the part being profiled. If you find the difference of these values divided by the constant CLOCKS_PER_SEC, you can get the time of the code in seconds. Of course, this is not a very accurate method of measurement, but I didn’t need it more precisely.
In order to avoid the strong influence of errors, we will measure the time of multiple function calls.
Code for testing:
double measureTimeJIT ( Tree * tree , int iters )
{
int i ;
double result ;
clock_t start , end ;
CompiledFunc f ;
start = clock ( ) ;
f = compileTree ( tree ) ;
for ( i = 0 ; i & lt ; iters ; i ++ )
{
f. run ( ( float ) ( i % 1000 ) ) ;
}
end = clock ( ) ;
result = ( end - start ) / ( double ) CLOCKS_PER_SEC ;
compiledFuncFree ( f ) ;
return result ;
}
double measureTimeNormal ( Tree * tree , int iters )
{
int i ;
clock_t start , end ;
double result ;
start = clock ( ) ;
for ( i = 0 ; i & lt ; iters ; i ++ )
{
calcTree ( tree , ( float ) ( i % 1000 ) ) ;
}
end = clock ( ) ;
result = ( end - start ) / ( double ) CLOCKS_PER_SEC ;
return result ;
}
The code of the tester itself can be viewed in the repository. All he does is consistently increasing the size of the input data in a controlled range, calls the above testing functions and writes the results to a file.
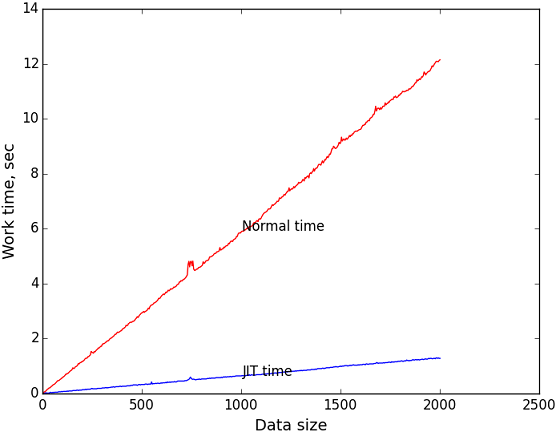
According to this data, I plotted the execution time versus the size of the input data (expression length). As the number of iterations to measure, I took 1 million. Just. The length of the string consistently increased from 0 to 2000.
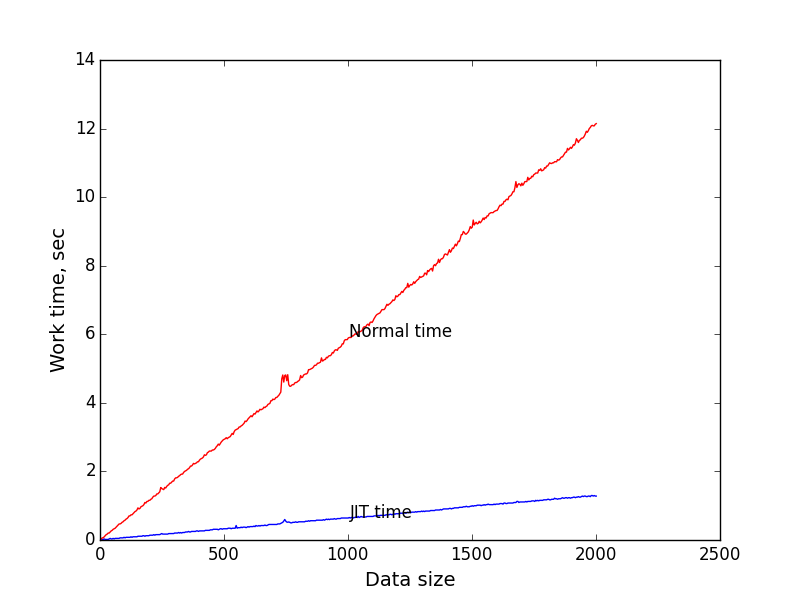
The blue graph is the dependence of the execution time of the compiled code on the size of the task.
The red graph is the dependence of the execution time of the recursive algorithm on the size of the task.
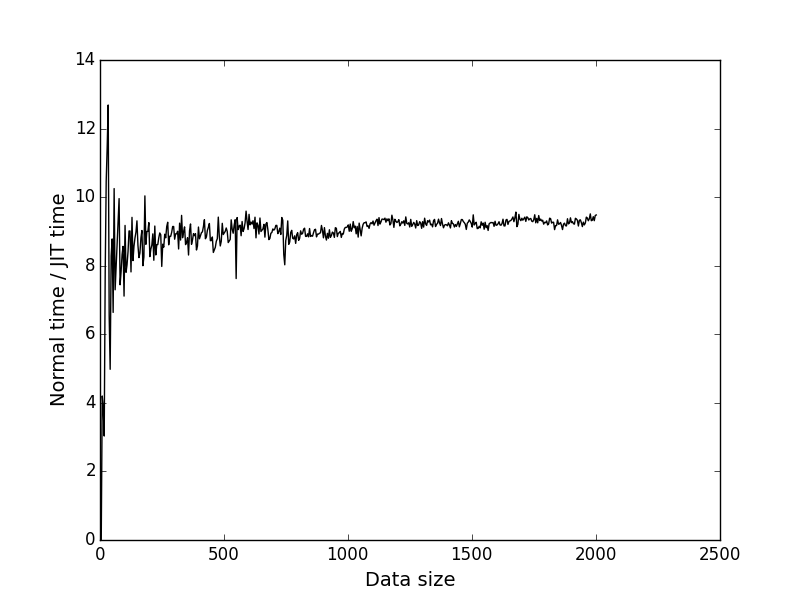
The black graph is the ratio of the y coordinates of the corresponding points of the first and second graphs. Shows how many times the JIT is faster depending on the size of the task.
It can be seen that when the size of the input data = 2000, JIT wins about 9.4 times. I think this is very good.
Why is it faster with JIT?
Compiled code is absolutely linear - no conditional transition. Due to this, during the execution time there is not a single reset of the processor pipeline, which is a very beneficial effect on performance.
What could be done better?
The biggest problem of our compiler is that it does not use all the features of FPU. In FPU 8 registers, we use at most two. If we were able to transfer part of our stack to the FPU stack, I am sure that the computation speed would greatly increase (of course, this should be tested).
Another drawback - the compiler is very stupid. It does not calculate constant expressions, it does not avoid unnecessary calculations. It is very easy to make an expression so that it spends maximum resources. If you add an elementary expression simplifier, the compiler will become close to ideal.
The problem of the implementation itself can be considered the impossibility of a simple transfer to another platform (specific commands are used in the code generation function) and the operating system (VirtualProtect, though). A completely obvious and fairly simple solution would be to abstract the platform and OS dependent parts and put their implementations into separate modules.
Thanks for reading, really looking forward to comments and advice.
Repository: bitbucket.org/Informhunter/jithabr
The article was inspired by the book “Perfect Code”, namely, its chapter “Dynamic Code Generation for Image Processing”.
Source: https://habr.com/ru/post/254831/
All Articles