Pure solution architecture, tests without mocks and how I came to this
Hello dear readers! In this article I want to talk about the architecture of my project, which I refactored 4 times at its start, because I was not satisfied with the result. I'll tell you about the disadvantages of popular approaches and show mine.
Just want to say that this is my first article, I am not saying what to do as I am - right. I just want to show what I did, tell you how I got to the final result and the most important thing is to get the opinions of others.
I worked in several campaigns and saw a bunch of things I’d do differently.
For example, I often see an N-Layered architecture, there is a layer of working with data (DA), there is a layer with business logic (BL) that works using DA and maybe some other services, and there is also a view layer \ API in which accepted request, processed using BL. It seems to be convenient, but looking at the code I see this situation:
- [DA] draws \ writes \ changes data, even if a complex query is OK
- [BL] 80% calls 1 method and rolls the result higher - Why this empty layer?
- [View] 80% Calls 1 BL method pushes the result higher - Why this empty layer?
In addition, it is fashionable to wrap in the interfaces in order to then lock and test - wow, just wow!
- Why mock?
- Well, to cut out side effects for the duration of the tests.
- That is, we will test without side effects, and in prod with them?
...
This is a grounded thing that I didn’t like in this architecture, so as to solve a problem of the type: "Display a list of user likes" is a big process, but in fact there is 1 query to the database and possibly mapping.
1) [DA] Add request to DA
2) [BL] Forward the answer DA
3) [View] Forward result BA, can promappit
Do not forget about the fact that all these methods still need to be added to the interface, we are writing a project in order to get wet, and not to solve it.
Elsewhere I saw an API implementation with a CQRS approach.
The solution did not look bad, 1 folder - 1 feature. The developer doing the feature is sitting in his folder and almost always can forget about the effect of his code on other features, but there were so many files that it was just a nightmare. Query / response models, validators, helpers, logic itself. The search in the studio practically refused to work, extensions were made to search for the necessary things in the code.
There is a lot more to be said, but I have highlighted the main reasons that made me give up on it.
And finally to my project
As I said, I refactored my project several times, at that moment I had a “programmer’s depression”, I was just not happy with my code, and refactored it, again and again, I finally started to watch a video about the architecture of the application to see how do others. I stumbled upon Anton Moldovan's reports about DDD and functional programming, and thought: "Here it is, I need F #!".
Having spent a couple of days on F #, I realized that, in principle, I will do the same in C # and not worse. In the video showed:
- Here is the C # code, it's shit
- Here is F # cool, less wrote - super.
But the joke is that the solution on F # was implemented differently, and against it showed a poor implementation in C #. The main principle was that BL is not a thing that causes DA services and does all the work, and this is a pure function .
Of course, F # is good, I liked some features, but like C # it is just a tool that can be used in different ways.
And I went back to C # and started creating.
I created such projects in the solution:
- API
- Core
- Services
- Tests
I also used C # 8 features, especially the nullable refence type, I will show its use.
Briefly about the tasks of the layers that I gave them.
API
1) Receive requests, query models + validation, restrictions

2) Calling functions from Core and Services
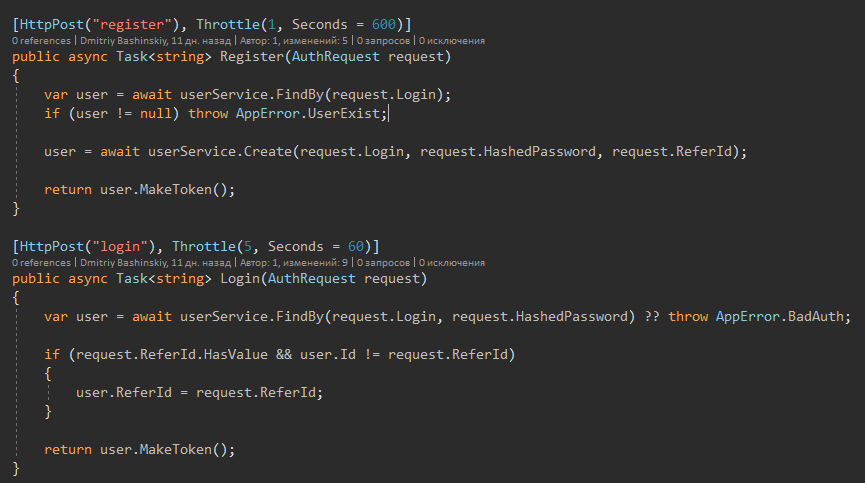
Here we see a simple, readable code, I think everyone will understand what is written here.
There is a clear pattern
1) Get the data
2) Edit, change, etc. - It is this part that needs to be tested.
3) Save.
3) Mapping, if needed
4) Error handling (logging + human response)
In this class all possible application errors are collected, to which exception handler responds.
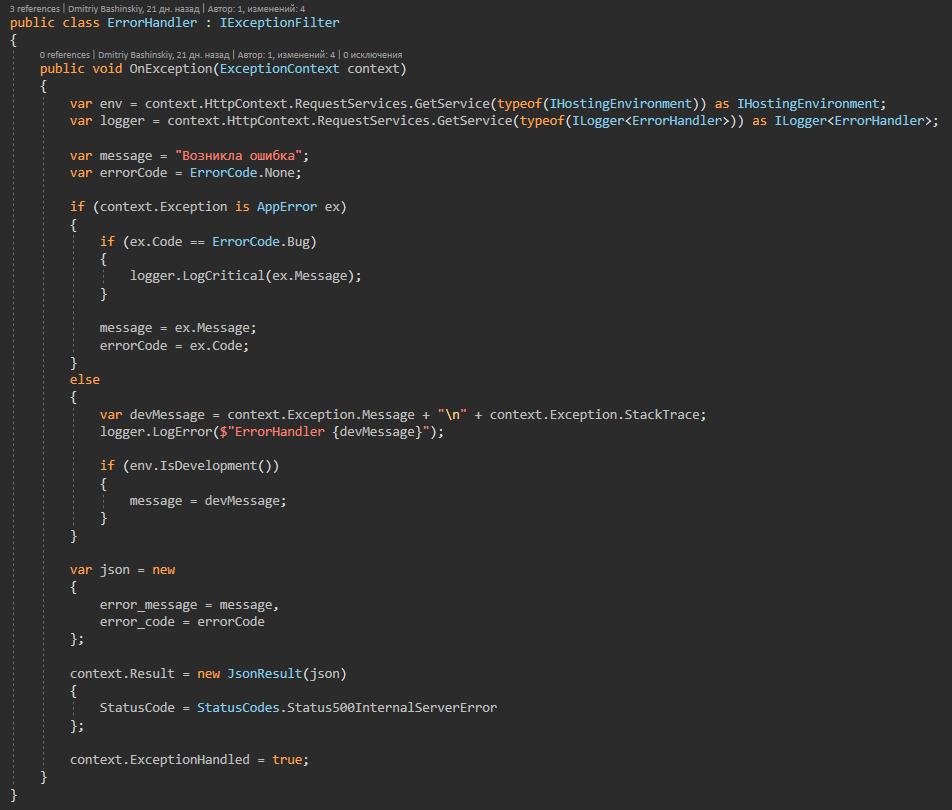
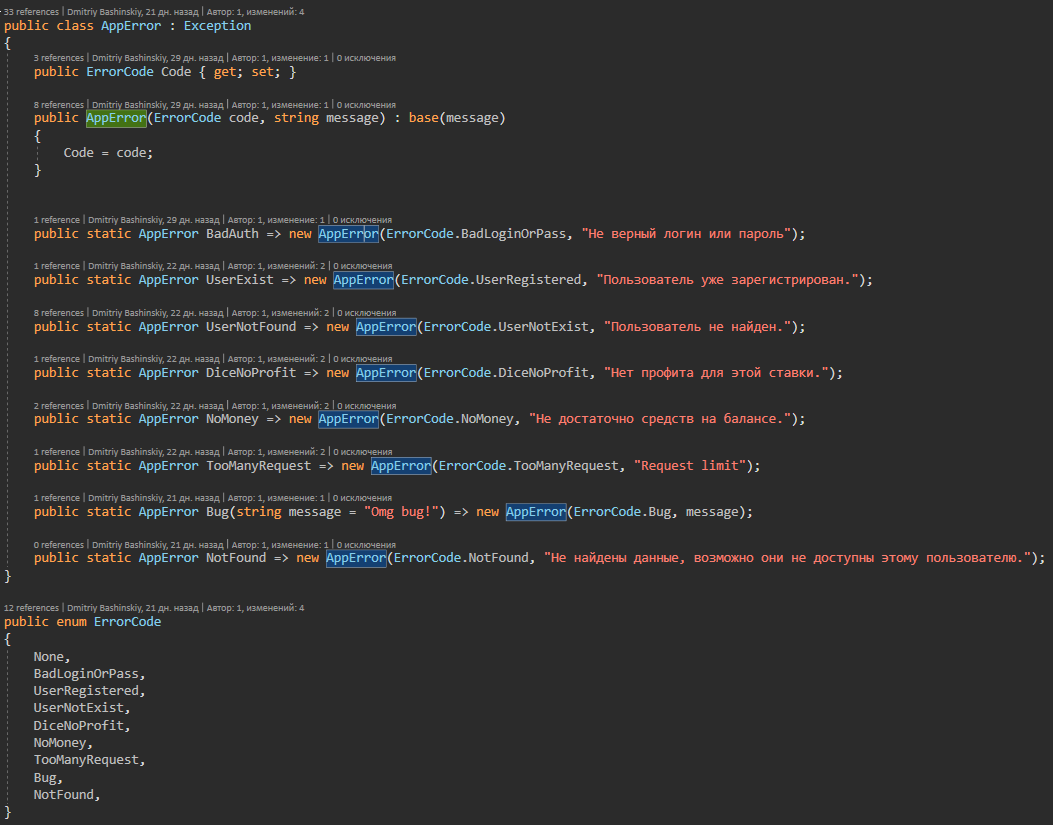
It turns out that the application either works, or gives a specific error, and not processed errors are either a side effect or a bug, the log of such errors flies right away to my telegrams in a chat with a bot.
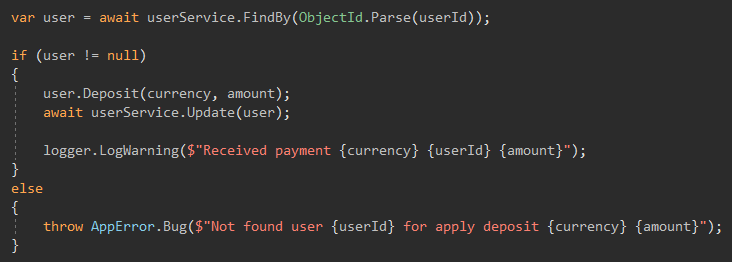
I have AppError.Bug this error for not clear case.
I have a CallBack from another service, it will have a userId in my system, and if I don’t find a user with this ID, it means either something happened to the user or it’s not clear at all, such an error flies to me like CRITICAL, in theory shouldn’t arise, but if it does, it requires my intervention.
Core, the most interesting
I always kept in mind that BL is just functions that, with the same input, give the same result. The complexity of the code in this layer was at the level of laboratory work, not large functions that clearly and without error do their work. And it was important that there were no side effects inside the functions; all that the function needs is a parameter to it.
If the functions need a user's balance, then WE will reach the balance, and transfer it to the function, but DO NOT shove the users' service in BL.
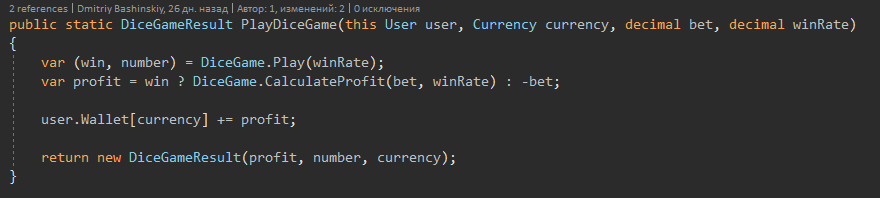
1) Basic entity actions

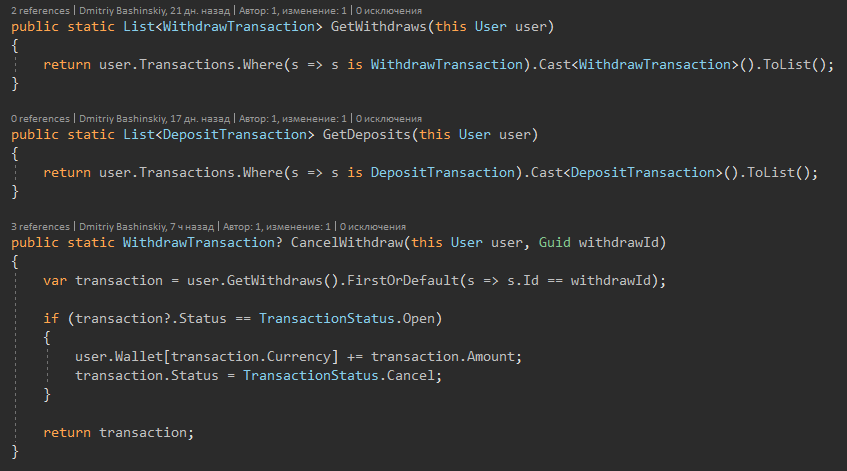
I rendered methods as extension methods so that the class does not bloat, and the functional can be grouped by features.
Another important topic is the good construction of entity models.
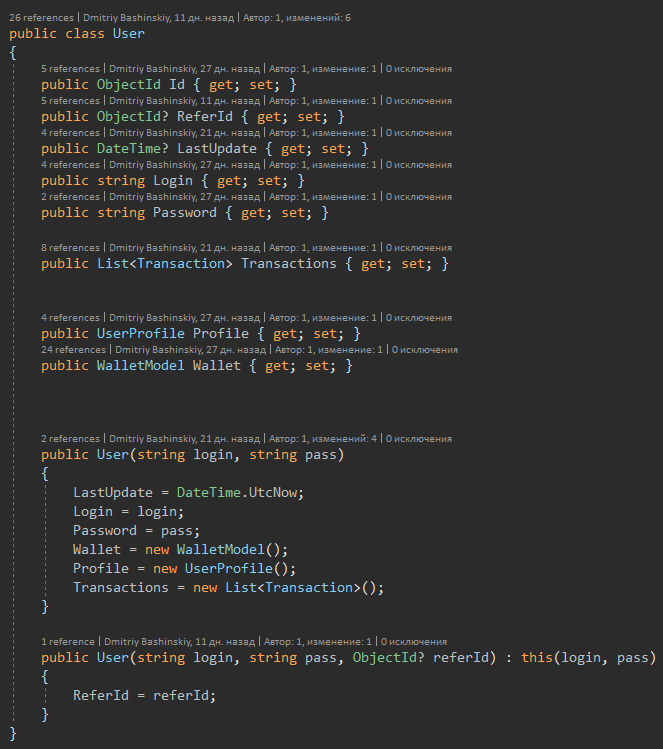
Here for example, I have a user, the user has balances in several currencies. One of the typical solutions that I took without hesitation is the essence of "Balance" and simply shove an array of balances into the user. But what is not convenient brought such a decision?
1) Adding / removing currency. This task immediately means for us not only writing new code, but also migration, filling / deleting all existing users and this is the simplest option. God forbid, to add a new currency would have to make a button for the user, which he will press and initiate the creation of a new wallet for some business process. As a result, it was only necessary to expand the enum for the new currency, and wrote another feature for creating purses by button, another task was thrown to the front.
2) In the code, the constants FirstOrDefault (s => s.Currency == currency) and check for null
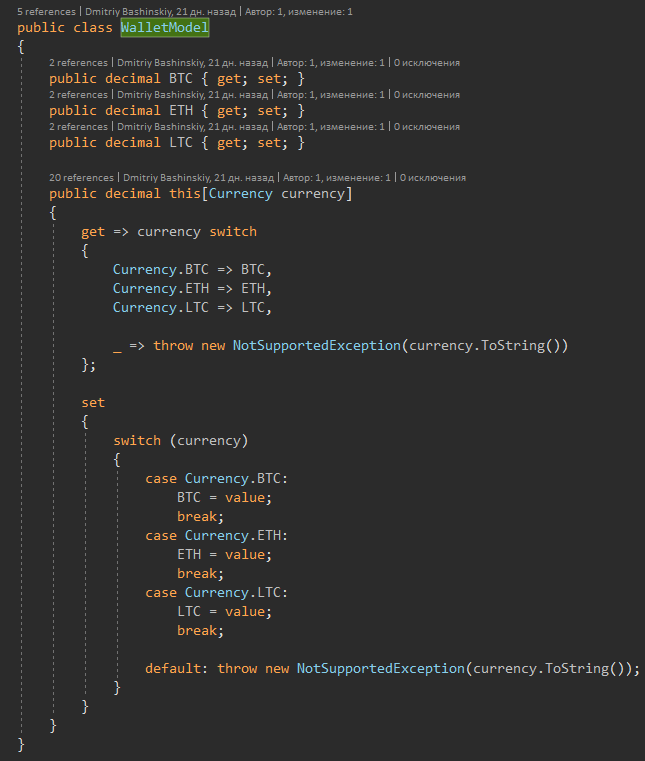
With the model itself, I guarantee myself that the balance will be no null, and by creating an operator indexer I simplified myself the code in all places of interaction with the balance.
Services
This layer provides me with convenient tools for working with various services.
In my project I use MongoDB and for convenient work with it, I wrapped collections in such a repository.
Repository itself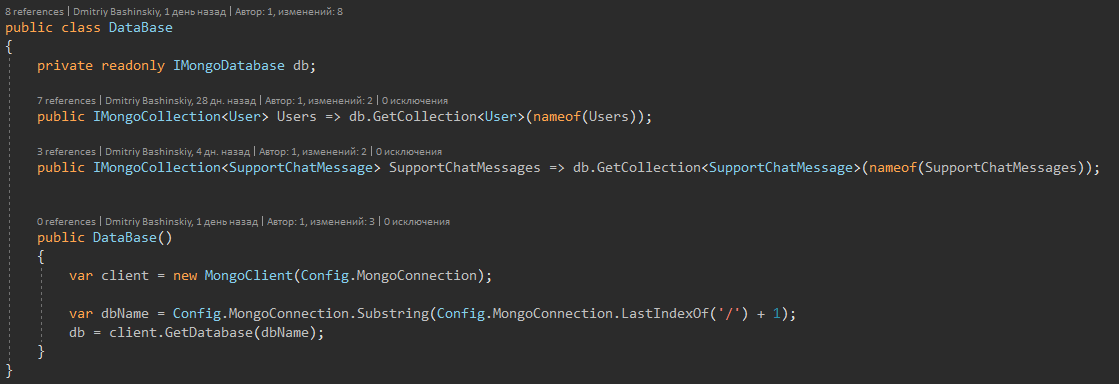
Monga blocks the document at the time of working with it, respectively, it will help us with solving problems in the competition of requests. And in the monge there are methods for finding an entity + an action on it, for example: "Find a user with id and add 10 to his current balance"
And now about the C # 8 feature.
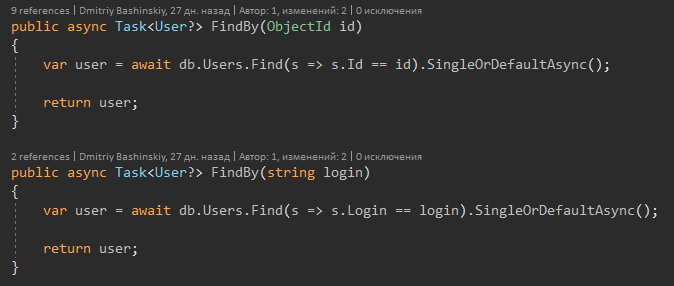
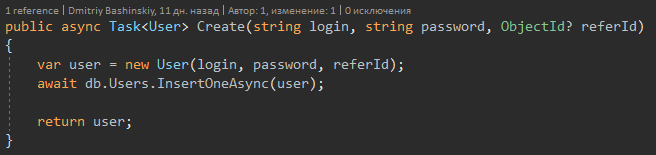
The method signature tells me that User can come back, and maybe Null, respectively, when I see User? I immediately get a compiler warning, and I check for null.
When the method returns User, I work with it confidently.
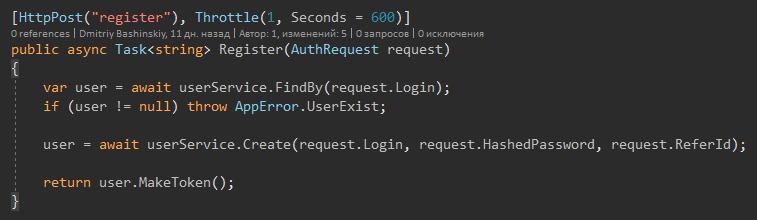
I also want to draw attention to the fact that there is no try catch because there can be exceptions only from "weird situations" and incorrect data that should not come here because there is validation. There is also no try catch in the API layer, there is only one global exception handler.
There is only one method that throws an Exception. This is the Update method.
It provides protection against data loss in multi-threaded mode.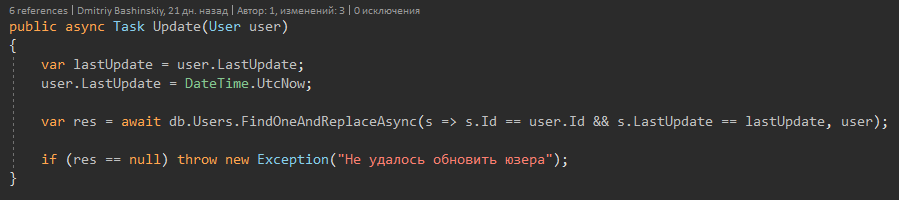
Why did not use the methods of Mongi, about which he spoke above?
There are places where I don’t know for sure if I can work with the user at all, maybe he simply doesn’t have money for this action, because in the beginning I get the user to check it, then I mutate and save it.
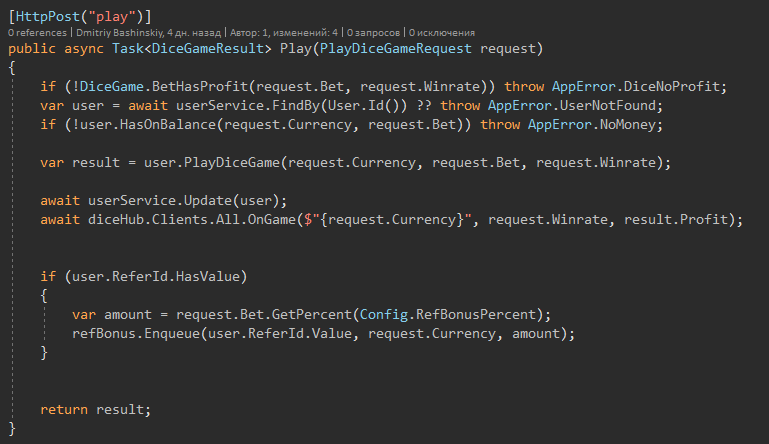
In theory, my application will change the user's balance more often than once per second, since these will be fast games.
But the user model itself, it is clearly visible here that the referral is not mandatory for the user, and you can work with everything else without thinking about null.
Finally Tests
As I said, you only need to test the logic, and the logic of our function, without side effects.
Therefore, we can run our tests very quickly and with different parameters.
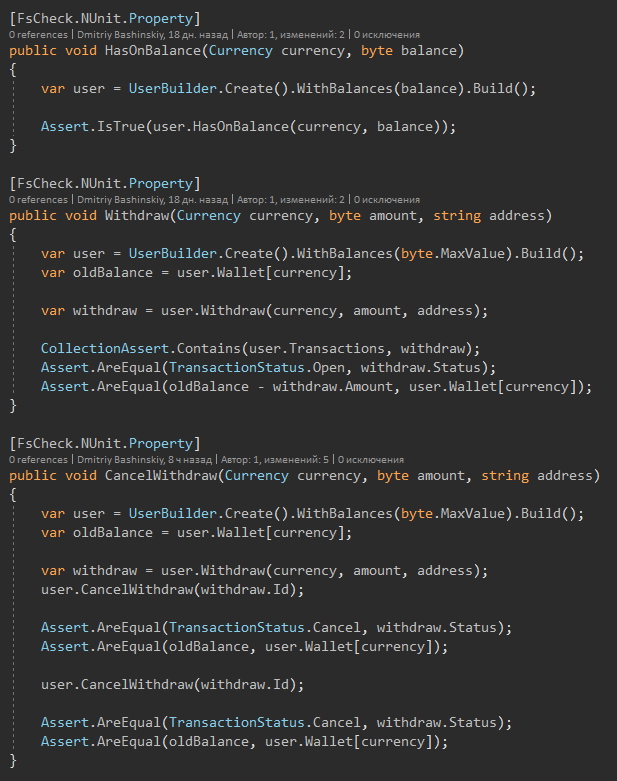
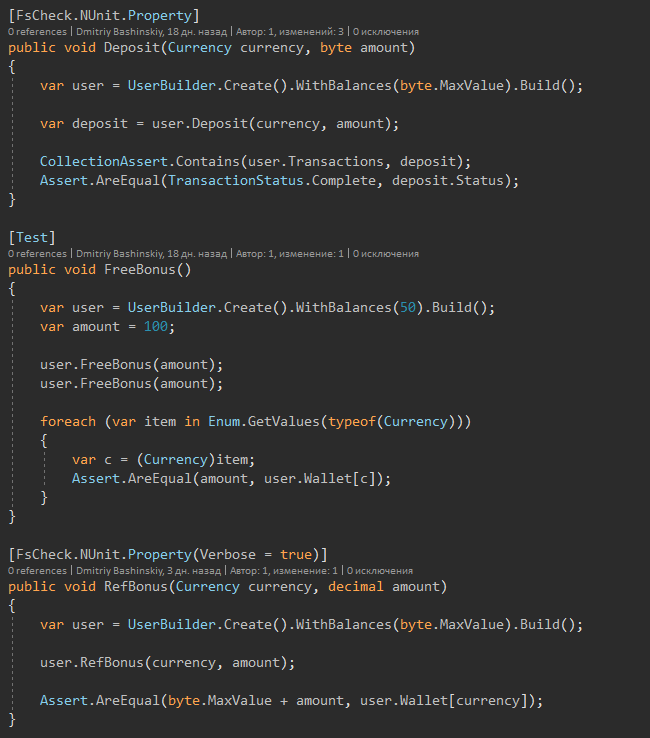
I downloaded the FSCheck nuget which generates randomly incoming data and allows me to carry out many different cases.
I just need to create different users, feed them to the test and check the changes.
To create such users there is a builder, so far small, but it is easy to expand.

And here are the tests themselves
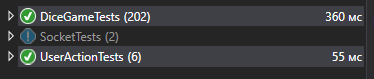
After some changes, I run tests, after 1-2 seconds I see that everything is in order.
Also in the plans to write E2E tests in order to check the entire API from the outside and be sure that it works as it should, from the request to the answer.
Chips
Each my request is doped, when a bug occurs, I find the requestId and I can easily reproduce the bug by repeating the request, because my API has no state, and each request depends only on the request parameters.
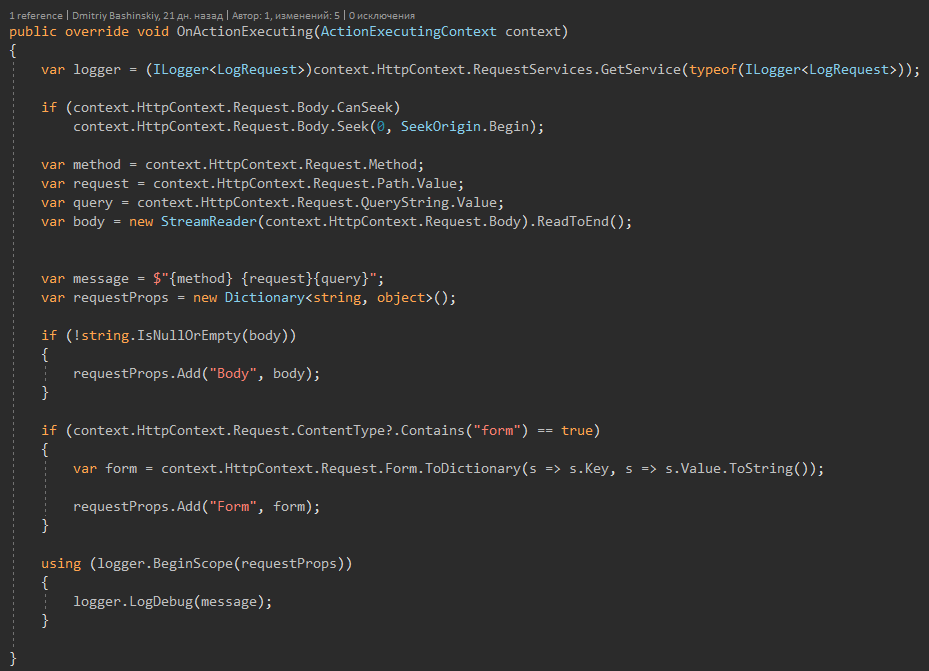
Summarize.
We really wrote a solution, not a framework in which a bunch of unnecessary abstractions, as well as mocks. We did error handling in one place and those should occur very rarely. We separated the BL and side effects, now the BL is just local logic that can be reused. We did not write unnecessary functions that simply forward the call to other functions. I will actively read the comments and add to the article, thank you!
')
Source: https://habr.com/ru/post/459394/
All Articles