Distributed data structures (part 2, how it's done)
In the previous article - part 1, overview - I talked about why we need distributed data structures (hereinafter referred to as RSD) and discussed several options offered by the distributed Apache Ignite cache.
Today I want to talk about the details of the implementation of specific RSD, as well as to conduct a small educational program for distributed caches.
So:

Let's start with the fact that, at least in the case of Apache Ignite , RSDs are not implemented from scratch, but are a superstructure over a distributed cache.
Distributed cache is a data storage system in which information is stored on more than one server , but it provides access to the entire volume of data at once.
The main advantage of this kind of systems is the ability to cram in nevpihuemoe store huge amounts of data without splitting them into pieces, limited by the volumes of specific drives or even entire servers.
Most often, such systems allow you to dynamically increase storage by adding new servers to the distributed storage system.
In order to be able to change the cluster topology (add and delete servers), as well as balance data, the principle of partitioning data is used .
When creating a distributed cache, you specify the number of partitions into which the data will be divided, for example, 1024. When adding data, the partition responsible for storing them is selected, for example, by key hash. Each partition can be stored on one or several servers, depending on the cache configuration. For each specific topology (set of servers), the server where the partition will be stored is calculated using a predetermined algorithm.
For example, when starting the cache, we indicate that:
- Partitions will be 4 [A, B, C, D]
- each partition will be stored on two servers (i.e., each will have one backup)
We will launch four data nodes [JVM 1-4] (responsible for data storage) and one client node [Client JVM] (responsible only for providing data access).
Each of the four data nodes can be used as a client node (that is, to provide access to all data). For example, JVM 1 was able to get data on partitions A, C, D, although, locally, it only has A (Primary) and D (Backup).
Any data node of a distributed cache for a particular partition can be Primary or Backup, or it may not contain a partition at all.
Primary node differs from Backup in that it processes requests within the partition and, if necessary, replicates the results to the Backup node.
In case of failure of the Primary node, one of the Backup nodes becomes Primary.
If the Primary node fails, in the absence of the Backup node, the partition is considered lost.
Some distributed caches provide the ability to locally cache data located on other nodes. For example, the Client JVM cached part B locally and will not request additional data until it changes.
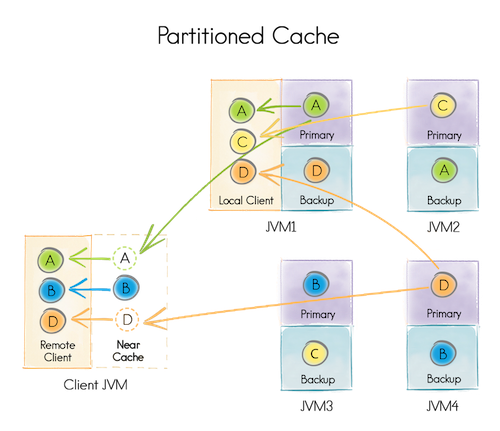
Distributed caches are divided into Partitioned and Replicated.
The difference is that the Partitioned cache stores one (or one + N backups) partition partition within the cluster, and Replicated stores one instance of the partition on each data node.

Partitioned cache makes sense to use for data storage, whose volumes exceed the capabilities of individual servers, and Replicated - for storing the same data “everywhere”.
A good example for understanding is the Employee - Organization bundle. There are a lot of employees and they change quite often, so it’s better to keep them in the partitioned cache. There are few organizations and they rarely change, so it makes sense to store them in the Replicated cache, reading from it is much faster.
So, we will pass to implementation details.
I want to once again indicate that we are talking about implementation within the Apache Ignite source code , the implementation may differ in other distributed caches.
To ensure the work of the RSD, two caches are used: one Replicated and one Partitioned.
Replicated cache - in this case, it is the system cache, ( ignite-sys-cache ) responsible, among other things, for storing information about the RSDs registered in the system.
Partitioned-cache ( ignite-atomics-sys-cache ) stores the data necessary for the operation of the RSD, and their state.
So, most of the RSD is created as follows:
- The transaction starts.
- In the
ignite-sys-cache, using theDATA_STRUCTURES_KEYkey,Map<_, DataStructureInfo>is taken (it is created if necessary), and a new item is added to it with a description, for example,IgniteAtomicReference. - In the
ignite-atomics-sys-cache, by the key from the previously addedDataStructureInfo, an element is added that is responsible for the state of the RSD. - The transaction commits.
The first request to create the RSD creates a new instance, and subsequent requests receive the previously created one.
IgniteAtomicReference and IgniteAtomicLong ( brief introductory )
The third initialization step for both types is to add an object of type GridCacheAtomicReferenceValue or GridCacheAtomicLongValue to ignite-atomics-sys-cache .
Both classes contain one single val field.
Accordingly, any change in the IgniteAtomicReference :
// , . ref.compareAndSet(expVal, newVal); ... is launching an EntryProcessor with the following process method code:
EntryProcessor is a function that allows you to atomically perform complex operations on objects in the cache.
The process method accepts MutableEntry (object in the cache) and can change its value.
EntryProcessor, in fact, is an alternative to a transaction with a single key (sometimes even implemented as a transaction).
As a result, it is guaranteed that only one EntryProcessor will be executed on a single object in the cache per time.
Boolean process(MutableEntry<GridCacheInternalKey, GridCacheAtomicReferenceValue<T>> e, Object... args) { GridCacheAtomicReferenceValue<T> val = e.getValue(); T curVal = val.get(); // expVal newVal — // ref.compareAndSet(expVal, newVal); if (F.eq(expVal, curVal)) { e.setValue(new GridCacheAtomicReferenceValue<T>(newVal)); return true; } return false; } IgniteAtomicLong is a defacto extension of the IgniteAtomicReference , therefore its compareAndSet method compareAndSet implemented in the same way.
The incrementAndGet method does not check for the expected value, but simply adds one.
Long process(MutableEntry<GridCacheInternalKey, GridCacheAtomicLongValue> e, Object... args) { GridCacheAtomicLongValue val = e.getValue(); long newVal = val.get() + 1; e.setValue(new GridCacheAtomicLongValue(newVal)); return newVal; } IgniteAtomicSequence ( brief introductory )
When creating each instance of IgniteAtomicSequence ...
// IgniteAtomicSequence. final IgniteAtomicSequence seq = ignite.atomicSequence("seqName", 0, true); ... it is allocated a pool of identifiers.
// try (GridNearTxLocal tx = CU.txStartInternal(ctx, seqView, PESSIMISTIC, REPEATABLE_READ)) { GridCacheAtomicSequenceValue seqVal = cast(dsView.get(key), GridCacheAtomicSequenceValue.class); // locCntr = seqVal.get(); // upBound = locCntr + off; seqVal.set(upBound + 1); // GridCacheAtomicSequenceValue dsView.put(key, seqVal); // tx.commit(); Accordingly, the challenge ...
seq.incrementAndGet(); ... simply increments the local counter to reach the upper boundary of the value pool.
When the boundary is reached, a new pool of identifiers is IgniteAtomicSequence , in the same way as when creating a new instance of the IgniteAtomicSequence .
IgniteCountDownLatch ( brief introductory )
Decrement counter:
latch.countDown(); ... is implemented as follows:
// try (GridNearTxLocal tx = CU.txStartInternal(ctx, latchView, PESSIMISTIC, REPEATABLE_READ)) { GridCacheCountDownLatchValue latchVal = latchView.get(key); int retVal; if (val > 0) { // retVal = latchVal.get() - val; if (retVal < 0) retVal = 0; } else retVal = 0; latchVal.set(retVal); // latchView.put(key, latchVal); // tx.commit(); return retVal; } Waiting for decrementing counter to 0 ...
latch.await(); ... is implemented through the Continuous Queries mechanism, that is, each time the GridCacheCountDownLatchValue changes in the cache, all instances of IgniteCountDownLatch notified of these changes.
Each instance of IgniteCountDownLatch has a local:
/** Internal latch (transient). */ private CountDownLatch internalLatch; Each notification decrements internalLatch to the current value. Therefore, latch.await() is implemented very simply:
if (internalLatch.getCount() > 0) internalLatch.await(); IgniteSemaphore ( short introductory )
Getting permission...
semaphore.acquire(); ... proceeds as follows:
// for (;;) { int expVal = getState(); int newVal = expVal - acquires; try (GridNearTxLocal tx = CU.txStartInternal(ctx, semView, PESSIMISTIC, REPEATABLE_READ)) { GridCacheSemaphoreState val = semView.get(key); boolean retVal = val.getCount() == expVal; if (retVal) { // . // - node, // . { UUID nodeID = ctx.localNodeId(); Map<UUID, Integer> map = val.getWaiters(); int waitingCnt = expVal - newVal; if (map.containsKey(nodeID)) waitingCnt += map.get(nodeID); map.put(nodeID, waitingCnt); val.setWaiters(map); } // val.setCount(newVal); semView.put(key, val); tx.commit(); } return retVal; } } Return Permission ...
semaphore.release(); ... occurs in a similar way, except that the new value is greater than the current one.
int newVal = cur + releases; IgniteQueue ( short introductory )
Unlike other RSDs, IgniteQueue does not use ignite-atomics-sys-cache . The used cache is described using the colCfg parameter.
// IgniteQueue. IgniteQueue<String> queue = ignite.queue("queueName", 0, colCfg); Depending on the specified Atomicity Mode (TRANSACTIONAL, ATOMIC), you can get different versions of IgniteQueue .
queue = new GridCacheQueueProxy(cctx, cctx.atomic() ? new GridAtomicCacheQueueImpl<>(name, hdr, cctx) : new GridTransactionalCacheQueueImpl<>(name, hdr, cctx)); In both cases, the state of IgniteQueue controlled by:
class GridCacheQueueHeader{ private long head; private long tail; private int cap; ... AddProcessor used to add an item ...
Long process(MutableEntry<GridCacheQueueHeaderKey, GridCacheQueueHeader> e, Object... args) { GridCacheQueueHeader hdr = e.getValue(); boolean rmvd = queueRemoved(hdr, id); if (rmvd || !spaceAvailable(hdr, size)) return rmvd ? QUEUE_REMOVED_IDX : null; GridCacheQueueHeader newHdr = new GridCacheQueueHeader(hdr.id(), hdr.capacity(), hdr.collocated(), hdr.head(), hdr.tail() + size, // hdr.removedIndexes()); e.setValue(newHdr); return hdr.tail(); } ... which, in essence, simply moves the pointer to the tail of the queue.
Thereafter...
// , // hdr.tail() QueueItemKey key = itemKey(idx); ... a new item is added to the queue:
cache.getAndPut(key, item); Deleting an element is similar, but the pointer does not change to tail , but to head ...
GridCacheQueueHeader newHdr = new GridCacheQueueHeader(hdr.id(), hdr.capacity(), hdr.collocated(), hdr.head() + 1, // hdr.tail(), null); ... and the item is deleted.
Long idx = transformHeader(new PollProcessor(id)); QueueItemKey key = itemKey(idx); T data = (T)cache.getAndRemove(key); The difference between GridAtomicCacheQueueImpl and GridTransactionalCacheQueueImpl is that:
When adding an element,
GridAtomicCacheQueueImplfirst atomically incrementshdr.tail(), and then adds an element to the cache using the resulting index.GridTransactionalCacheQueueImpldoes both actions in the same transaction.
As a result, GridAtomicCacheQueueImpl works faster, but there may be a problem of data consistency: if the information about the size of the queue and the data itself are not stored at the same time, then they may not be deducted at the same time.
It is quite possible that the inside of the poll method shows that the queue contains new elements, but there are no elements themselves yet. This is extremely rare, but still possible.
This problem is solved by waiting for the value.
long stop = U.currentTimeMillis() + RETRY_TIMEOUT; while (U.currentTimeMillis() < stop) { data = (T)cache.getAndRemove(key); if (data != null) return data; } There were real cases when there was not enough five-second timeout, which led to data loss in the queue.
Instead of conclusion
Once again, I would like to point out that distributed cache is, in fact, ConcurrentHashMap within many cluster-integrated computers.
Distributed cache can be used to implement many important, complex, but reliable systems.
A special case of implementation are distributed data structures, but in general they are used for storing and processing huge amounts of data in real time, with the possibility of increasing the volume or speed of processing by simply adding new nodes.
')
Source: https://habr.com/ru/post/328368/
All Articles