Why Apache Ignite is a good microservice platform

Note Translator. The article may be of interest to architects and developers who are planning to build a solution based on microservices, or who are looking for ways to optimize the current solution, especially if the work comes with large amounts of data. The translation is made on the basis of part 1 and part 2 of the cycle of articles on microservices on Apache Ignite. General familiarity with the Java ecosystem is assumed (Apache Ignite also works with .NET, C ++, and with REST and with other languages, but the examples in the article will appeal to Java), it is recommended that you have a basic knowledge of Spring.
Today microservice architecture is one of the most popular approaches, on the basis of which many companies build their solutions. One of the key advantages of this approach is that it involves splitting the solution into a set of weakly related components — microservices — each of which can have its own life and release cycles, development team, etc. These components always have at least one data exchange mechanism, through which microservices interact with each other. Moreover, they can be created using different languages and technologies that are most appropriate for a specific module of the system.
')
If you use solutions based on microservice architecture where there is a high load and you need to work with actively growing data arrays, most likely, you have encountered or will encounter problems of classical approaches:
- disk databases do not cope with increasing volumes of information that must be stored and processed; databases become a bottleneck in which your decision rests;
- The high availability requirements that were once the “cherry on the cake” are now the necessary minimum for a product that wants to compete successfully in the market.
The purpose of this article is to explain how you can solve these problems in your product using Apache Ignite (or GridGain In-Memory Data Fabric) to build a fault tolerant and scalable solution in the microservice paradigm.
Analysis of solutions based on Apache Ignite
Let's look at a typical microservice solution architecture that uses Apache Ignite, shown in the figure below.
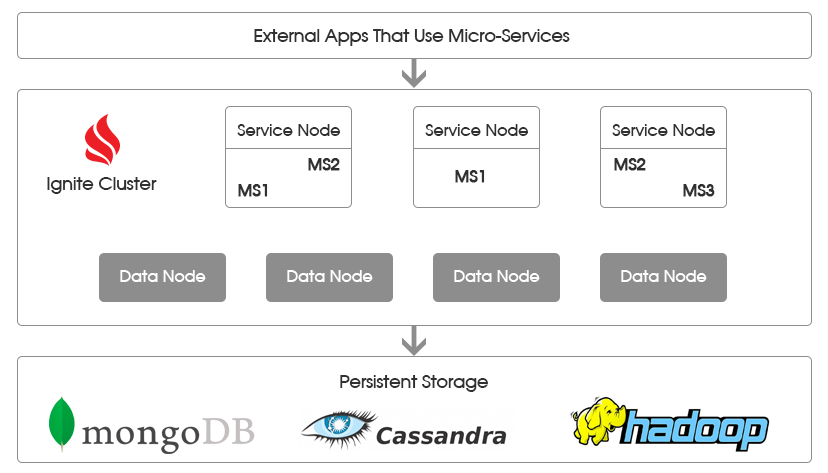
Apache Ignite Cluster Layer
Apache Ignite cluster is used to achieve 2 goals.
First, it is the main data repository in which they are contained in RAM. Since the data is in memory, microservice does not need indirectly through the DBMS to perform many expensive disk accesses, which significantly improves the overall system performance.
" Data nodes " ( data nodes ) - a special group in the cluster, which is responsible for storing data. These are the “server” Apache Ignite nodes that store data patches and allow execution of data retrieval and calculation requests on these sites. There is no need to deploy data and computation classes: Apache Ignite relies on its own cross-platform binary format, and also has mechanisms for exchanging classes with logic between cluster nodes (peer class loading).
Apache Ignite binary format is used to serialize objects and support the dynamic exchange of classes between nodes. The possibility of such an exchange of logic within the cluster allows you to flexibly manage computations by loading the necessary code on demand from a separate layer of service nodes containing business logic.
Secondly, the cluster manages the life cycle of microservices and provides all the necessary APIs for interaction between them and the data nodes.
For this solution, based on the Apache Ignite cluster, use Service nodes (service nodes). These are the nodes where the microservice code is deployed containing the necessary business logic. A separate node may contain one or more microservice, depending on the particular solution.
Each microservice implements the Service interface, and also is registered in the Apache Ignite node, after which the internal cluster mechanisms allow for fault tolerance and provide a convenient mechanism for calling microservice from other parts of the cluster. Apache Ignite takes care of deploying one or more copies of microservice on the service nodes. Cluster internal mechanics also provide load balancing and fault tolerance.
In the above figure, microservices are labeled MS <N> (MS1, MS2, etc.). Due to the separation of logic between service nodes and data nodes, there is no need to restart the entire cluster, if the MS1 microservice needs to be updated. All you need to do is update the MS1 classes on the service nodes where it is deployed. Further, it will be necessary to restart only a certain subset of nodes, minimizing the potential impact on the system.
All nodes (services and data) are interconnected in a single cluster, which allows MS1, deployed on one node to interact with any other microservice, deployed on another (or the same) node, and also to receive or send data and calculations to any nodes data.
Data storage layer
This layer is optional and can be used in scenarios where:
- there is no sense or it is impossible to keep all data in memory;
- you must be able to recover data from a copy on disk in case the entire cluster falls or you need to restart it.
To use the persistent data storage layer, you need to specify for Apache Ignite the implementation of the CacheStore interface. Among the default implementations, you can find various relational DBMSs, as well as MongoDB, Cassandra, etc.
External application interaction layer
This is the “clients” layer of your microservices, various execution branches are initiated from this layer by calling one or more microservices.
This layer can communicate with your microservices using protocols specific to that microservice. At the same time, within the framework of this architectural solution, microservices will communicate with each other using Apache Ignite mechanisms.
This architecture provides the possibility of horizontal scaling, allows you to store data in memory and ensures high availability of microservices.
Implementation example
The following is a possible implementation of the first layer of the Apache Ignite cluster. The code that will work with, you can look at: https://github.com/dmagda/MicroServicesExample .
In particular, it will be shown how you can:
- configure and run data nodes;
- implement services using the Apache Ignite Service Grid API;
- configure and run service nodes;
- create an application (in its simplest form) that connects to the cluster and initiates the execution of the service.
Data nodes
As it was written above, the data node is the Apache Ignite server node, which contains part of the data and allows you to perform queries and calculations initiated by the business logic of the application. Data nodes are decoupled from business logic and encapsulate only the data storage and processing mechanisms in themselves, accepting specific requests for them from outside.
Let's look at the creation of such nodes by example. To do this, you will need to download the GitHub project that was mentioned earlier.
Locate the data-node-config.xml file in the project. This file is used to launch new data nodes. In it you can see the definition of caches that should be deployed on the cluster, as well as other settings specific to data nodes. Consider the main ones.
Note translator. Apache Ignite XML configuration uses Spring to build a tree of objects. If the reader is not familiar with the Spring configuration, the necessary information can be obtained, for example, from official documentation (English) or from any training materials . Naturally, it is possible to create IgniteConfiguration directly, and also, since Spring mechanisms are used, configuration creation based on annotations or Groovy dialect.
First, in this configuration, for each cache, a filter is set, which determines which Apache Ignite nodes will contain information. This filter will be applied every time the topology changes, when nodes join or leave the cluster. The filter implementation must be deployed on the classpath of all cluster nodes, including nodes that are not data nodes, and be available on the classpath.
<bean class="org.apache.ignite.configuration.CacheConfiguration"> ... <property name="nodeFilter"> <bean class="common.filters.DataNodeFilter"/> </property> </bean> Secondly, the filter class is implemented, which we defined above. In this example, one of the simplest approaches is used, when the criterion of whether the node will be responsible for storing data is the attribute of the “data.node” node. If this attribute is set and is true, the node will be considered a data node and will contain caches on the network. Otherwise, the node will be ignored when distributing data across the cluster.
public boolean apply(ClusterNode node) { Boolean dataNode = node.attribute("data.node"); return dataNode != null && dataNode; } Third, the configuration defines the value of the “data.node” parameter for each node that will use this configuration at startup.
<property name="userAttributes"> <map key-type="java.lang.String" value-type="java.lang.Boolean"> <entry key="data.node" value="true"/> </map> </property> Try using the DataNodeStartup class to start a data node, or use ignite.sh or ignite.bat scripts, passing them the configuration specified in data-node-config.xml as an argument. In the latter case, do not forget to pre-compile the JAR file that will contain the classes from java / app / common, and put this JAR file on the classpath of each data node.
Service nodes
In terms of configuration, the service nodes are not much different from the data nodes from the previous section. Similarly, it is necessary to determine the criterion according to which a subset of Apache Ignite nodes will be allocated, but this subset will no longer be responsible for storing data, but for the operation of microservices.
First, you need to define microservice using the Apache Ignite Service Grid API . The article will look at the MaintenanceService example attached to the repository on GitHub.
The service interface looks like this:
public interface MaintenanceService extends Service { public Date scheduleVehicleMaintenance(int vehicleId); public List<Maintenance> getMaintenanceRecords(int vehicleId); } The service allows you to plan machine maintenance, as well as receive a list of assigned services. The implementation, in addition to business logic, contains a definition of Service Grid-specific methods, such as init (...), execute (...) and cancel (...).
There are several ways to publish this microservice on a subset of the cluster. One of them, which will be used in the example, is to define the configuration file maintenance-service-node-config.xml, and start the service nodes with this configuration file and the necessary classes on the classpath. In this case, the configuration will be as follows.
For a start, a filter is defined that allows the service nodes to be distinguished from the rest.
<bean class="org.apache.ignite.services.ServiceConfiguration"> <property name="nodeFilter"> <bean class="common.filters.MaintenanceServiceFilter"/> </property> </bean> The implementation of the filter is as follows:
public boolean apply(ClusterNode node) { Boolean dataNode = node.attribute("maintenance.service.node"); return dataNode != null && dataNode; } In this implementation, the criterion is that the node has the attribute “maintenance.service.node” set to true.
Finally, nodes will receive this attribute due to the following configuration portion maintenance-service-node-config.xml :
<property name="userAttributes"> <map key-type="java.lang.String" value-type="java.lang.Boolean"> <entry key="maintenance.service.node" value="true"/> </map> </property> Note translator. The very fact of placing the service is specified by the code below from the configuration. The serviceConfiguration lists the services that can theoretically be deployed on this node.
The name property of the service is responsible for the unique name within the cluster, by which, for example, the service can be accessed through a service proxy, the service property refers to the class that implements the service logic, and the totalCount and maxPerNodeCount properties denote the total number of instances that must be maintained and the maximum number of instances on a particular node, respectively. In this case, the cluster singleton is configured: within the non-segmented cluster there will always be only 1 instance of the service.
<property name="serviceConfiguration"> <list> <!-- MaintenanceService. --> <bean class="org.apache.ignite.services.ServiceConfiguration"> <!-- --> <property name="name" value="MaintenanceService"/> <!-- , --> <property name="service"> <bean class="services.maintenance.MaintenanceServiceImpl"/> </property> <!-- --> <property name="totalCount" value="1"/> <!-- , --> <property name="maxPerNodeCount" value="1"/> … </bean> </list> </property> Try running multiple instances of service nodes using MaintenanceServiceNodeStartup or by passing maintenance-service-node-config.xml to ignite.sh or ignite.bat, first we put all the necessary classes from java / app / common and java / services / maintenance to the classpath of each of the nodes .
In the repository on GitHub you can also find an example of the VehicleService service. You can start instances of this service using the VehicleServiceNodeStartup class, or by transferring the vehicle-service-node-config.xml file to ignite.sh or ignite.bat, having previously placed all the necessary classes on the classpath.
Sample application
Once we have the data nodes configured and ready to start, as well as the service nodes with the MaintenanceService and VehicleService services, we can launch our first application that will use the distributed microservice infrastructure.
To do this, run the TestAppStartup file from the GitHub repository. The application will join the cluster, fill the caches with data and perform operations on the deployed microservices.
The code for performing operations on the service is as follows:
MaintenanceService maintenanceService = ignite.services().serviceProxy( MaintenanceService.SERVICE_NAME, MaintenanceService.class, false); int vehicleId = rand.nextInt(maxVehicles); Date date = maintenanceService.scheduleVehicleMaintenance(vehicleId); As you can see, the application works with services using a service proxy. The beauty of this approach is that the node playing the role of a client does not have to have service implementation classes deployed locally on the classpath — only interface classes are enough — and it does not need to have the service started locally: the proxy will provide transparent interaction with the remote implementation.
Conclusion
In this article, the architecture was considered, which implies the use of microservices on top of Apache Ignite, and an example application that implements this architecture was considered. The following articles will discuss how to associate a cluster with a persistent data storage layer, as well as how to isolate the interaction layer with external applications.
Source: https://habr.com/ru/post/327380/
All Articles