GraphQL - API in a new way
What is the GraphQL query language? What are the benefits of this technology and what problems will developers face when using it? How to effectively use GraphQL? About all this under the cut.

The article is based on the introductory level report by Vladimir Tsukur ( volodymyrtsukur ) from the Joker 2017 conference.
My name is Vladimir, I lead the development of one of the departments in the company WIX. More than hundreds of millions of WIX users create websites of the most diverse directions - from business cards and shops to complex web applications where you can write code and arbitrary logic. As a living example of a project on WIX, I would like to show you a successful website-shop unicornadoptions.com , which offers the opportunity to purchase a kit for taming a unicorn - the perfect gift for a child.
')

A visitor to this site can choose the set he liked for taming a unicorn, say, pink, then see what exactly is included in this set: a toy, a certificate, an icon. Next, the buyer has the opportunity to add the product to the cart, view its contents and place an order. This is a simple example of a store site, and we have many such sites, hundreds of thousands. All of them are built on the same platform, with a single backend, with a set of clients that we support, using the API for this. About API also the speech will go further.
Let's imagine what a general-purpose API (that is, one API for all stores on top of the platform) we could create to provide the functionality of the stores. Concentrate until purely on the receipt of data.
For the product page on such a site, the product name, its price, pictures, description, additional information and much more should be returned. In a complete solution for stores on WIX, there are more than two dozen such data fields. The standard solution for such a task on top of the HTTP API is to describe the

Let's now look at the product catalog page. This page will require a collection resource / products . Here are just in displaying a collection of products on the catalog page, not all product data is needed, but only the price, the name and the main image. For example, the description, additional information, background images, etc. do not interest us.

Suppose, for simplicity, we decide to use the same product data model for the
And now let's look at the "payload" of the response from the server for a collection of products. Here is what the client actually uses among more than two dozen fields:
Obviously, if I want to keep the product model simple by returning the same data, I end up with an over-fetching problem, getting in some cases more data than I need. In this case, this manifested itself on the product catalog page, but in general, any UI screens that are somehow related to the product will potentially require only a portion (not all) of data from it.
Let's now look at the cart page. In the basket, besides the products themselves, there is also their quantity (in this basket), the price, as well as the total cost of the entire order:

If we continue the simple HTTP API modeling approach, then the basket can be presented through the / carts /: id resource, whose view refers to the resources of the products added to this basket:
Now, for example, in order to draw a basket with three products on the frontend, you need to make four requests: one to load the basket itself, and three requests to download product data (name, price and SKU item number).
The second problem we have is under-fetching. The division of responsibility between the basket and product resources has led to the need to make additional requests. There are obviously a number of shortcomings: due to the greater number of requests, we plant the battery of the mobile phone faster and get the full answer more slowly. And the scalability of our solution also raises questions.
Of course, this solution is not suitable for production. One way to get rid of the problem is to add projection support for the basket. One of such projections could, in addition to the data of the basket itself, return data on products. Moreover, this projection will be very specific, because it is on the cart page that you need an inventory number (SKU) of the product. Nowhere else has SKU been needed.
Such a “fitting” of resources to a specific UI usually does not end there, and we begin to generate other projections: brief information on the basket, basket projection for the mobile web, and after that - the projection for unicorns.

(In general, in the WIX designer, as a user, you can configure which product data you want to display on the product page and what data to show in the basket)
And here we face difficulties: we are gardening the garden and looking for difficult solutions. There are few standard solutions from the API point of view for such a task, and they usually depend heavily on the framework or library for describing HTTP resources.
What's more important, now it becomes harder to work, because when the requirements on the client side change, the backend must constantly “catch up” and satisfy them.
As the “cherry on the cake,” let's consider another important problem. In the case of a simple HTTP API, the server developer has no idea what kind of data is used by the client. Is the price used? Description? One or all images?
Accordingly, several questions arise. How to work with deprecated / obsolete data? How to find out which data is really not used anymore? How is it relatively safe to remove data from an answer without breaking most clients? There is no answer to these questions with the usual HTTP API. Contrary to the fact that we are optimistic and the API seems to be simple, the situation does not look so hot. This spectrum of problems with the API came not only from WIX. They had to deal with a large number of companies. And now it's interesting to look at a potential solution.
In 2012, in the process of developing a mobile application, Facebook faced a similar problem. Engineers wanted to achieve the minimum number of mobile applications to the server, while at each step receiving only the necessary data and nothing but them. The result of their efforts was GraphQL, presented in 2015 at the React Conf conference. GraphQL is a query description language, as well as the execution environment for these queries.

Consider a typical approach to working with GraphQL-servers.
The data scheme in GraphQL defines the types and relationships between them and does this in a strictly typed manner. For example, imagine a simple model of a social network. User
Of course, in order for the graph to be useful, we also need the so-called “entry points”. For example, such an entry point could be getting a user by name.
Let's see what the essence of the GraphQL query language is. Let us translate this question into this language: “For a user with the name Vanya Unicorn, I want to know the names of his friends, as well as the name and population of the city in which Vanya lives” :
And here comes the answer from the GraphQL server:
Notice how the request form is “in tune” with the response form. There is a feeling that this query language was created for JSON. With strict typing. And all this is done in one HTTP POST request - no need to make multiple calls to the server.
Let's see how it looks in practice. Open the standard console for the GraphQL server, which is called Graph i QL (“graph”). For a request for a basket, I will execute the following request: “I want to receive a basket by identifier 1, all positions of this basket and product information are interested. Of the information, the name, price, inventory number and images (and only the first) are important. I am also interested in the quantity of these products, their price and the total cost of the basket . ”
After successful execution of the request, we will receive exactly what was asked:
Today GraphQL server can be done in almost any language. The most complete version of the GraphQL server is GraphQL.js for the Node platform. In the Java community, the reference implementation is GraphQL Java .
Let's take a look at how to create a GraphQL server using a specific life example.
Consider a simplified version of an online store based on a microservice architecture with two components:
Both services are implemented on top of the classic Spring Boot and already contain all the basic logic.
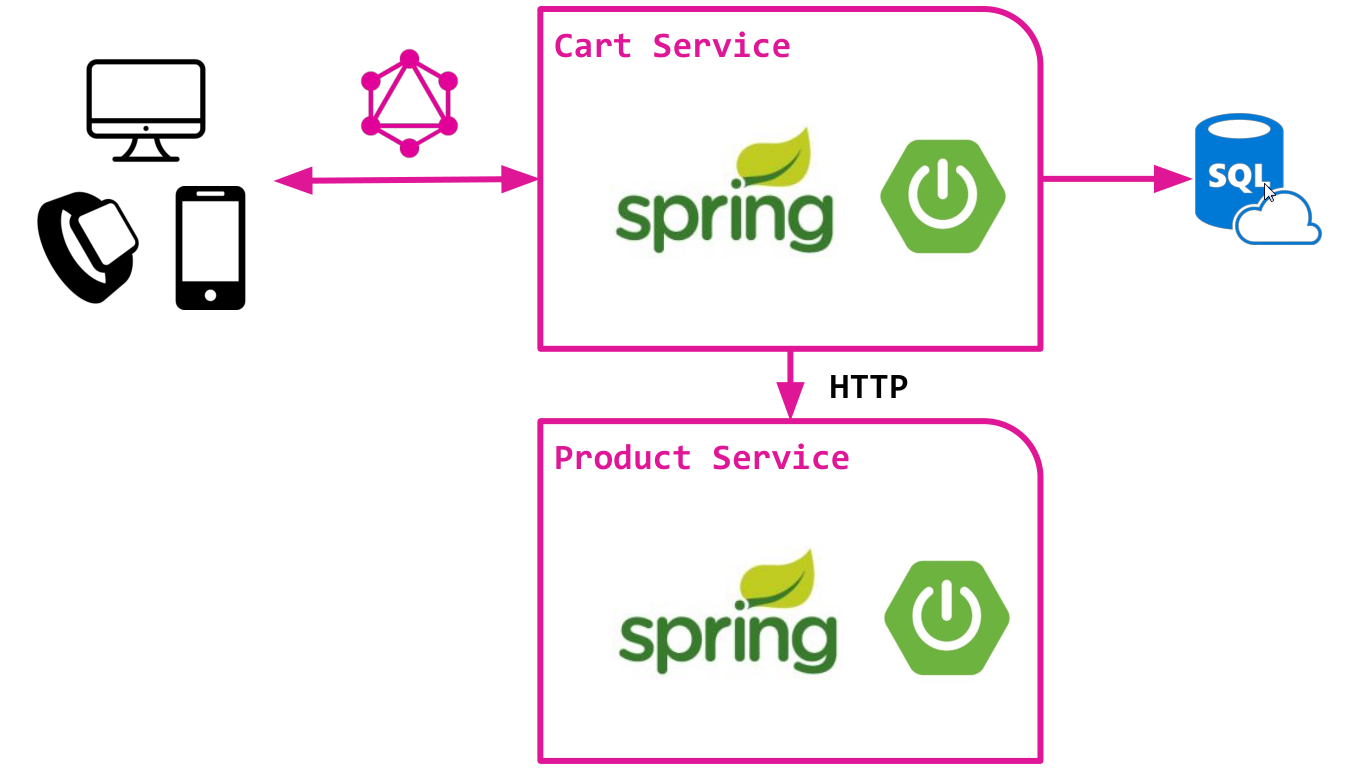
We intend to create GraphQL API over the Cart service. This API is designed to provide access to the cart data and products added to it.
We will be helped by the GraphQL reference implementation for the Java ecosystem, which we mentioned earlier - GraphQL Java.
Add some dependencies to
In addition to the previously mentioned
The next important step is to define the GraphQL service schema, our graph. The nodes of this graph are described using types , and edges using fields . An empty graph definition looks like this:
In this scheme, as you remember, there are “entry points” or top-level requests. They are defined via the query field in the schema. Let's name our type for entry points EntryPoints :
We define in it a basket search by identifier as the first entry point:
It's time to determine the type of
In addition to the standard
It remains to look at the definition of the type
Everything is simple here - all fields are scalar types and are required.
This scheme was not chosen randomly. The Cart service already defines the Cart
So, the basket (
We need to clarify exactly how the "
These changes are enough for us to get a working application. After restarting the Cart service in the GraphiQL console, the following query will start successfully:
So we got the first result, and that's great. But now our API is too primitive. For example, for the time being it is not possible to request useful data on a product, such as its name, price, article number, pictures, and so on. Instead, there is only a
Add the required field to the
With the scheme figured out. Now is the time to describe how the selection for the
We have a choice:
The second way is more preferable, because in this case the model of describing the internal subject area (
The GraphQLResolver marker interface will help in achieving this goal. By implementing it, you can determine (or redefine) exactly how to get field values for type
The name of the method
These changes should be enough to implement a more interesting sample that includes the real connection between the basket and the products that have been added to it.
After restarting the application, you can try a new query in the Graph i QL console.
And here is the result of the query:

Although the

It's time to show the Document Explorer, part of the Graph i QL console, which builds on the basis of the GraphQL schema and shows information on all the specific types. Here’s what the Document Explorer looks like for the

But back to the example. In order to achieve the same functionality as in the very first demo, there is still not enough overlap on the number of returned images. After all, for a basket, for example, you need only one image for each product:
To do this, change the schema and add a new parameter for the images field to the Product type:
And in the application code we will use it again
Again, I note that the name of the method is not accidental: it coincides with the name of the field
If the client does not specify anything as a value for
We compile the project and wait for the server to restart. Restarting the scheme in the console and executing the query, we see that the full query really works.
Agree, all this is very cool. In a short time, we not only learned what GraphQL is, but also transferred a simple microservice system to support such an API. And it didn’t matter to us where the data came from: both the SQL and the HTTP API were well placed under the same roof.
You might have noticed that during the development process there was some inconvenience, namely the need to constantly keep the GraphQL scheme and code in sync. Type changes always had to be done in two places. In many cases it is more convenient to use the code-first approach. Its essence is that the scheme for GraphQL is automatically generated based on the code. In this case, you do not need to support the scheme separately. Now I will show how it looks.
Only the basic features of GraphQL Java are no longer enough; we will also need the GraphQL SPQR library. The good news is that GraphQL SPQR is an add-on to GraphQL Java, and not an alternative implementation of the Java Graphical SQL Server.
Add the desired dependency in
Here is the code that implements the same functionality based on GraphQL SPQR for the basket:
And for the product:
The @GraphQLQuery annotation is used to mark field loader methods. The annotation
It is time to look at b on lshih detail how the implementation of the whole request "under the hood". We quickly created the GraphQL API, but does it work efficiently?
Consider the following example:

Receiving a basket

When it comes to downloading data by products, then there will be exactly as many requests for a Product-service as in this basket of products. If there are three different products in the basket, then we will receive three requests to the HTTP API of the product service, and if there are ten of them, then the same service will have to answer ten such requests.

Here is what the communication between the Cart-Service and the Product-Service in Charles Proxy looks like:

Accordingly, we return to the classic N + 1 problem. Exactly the one from which they tried so hard to leave at the very beginning of the report. Undoubtedly, we have progress, because there is exactly one request between the end customer and our system. But inside the server ecosystem, performance clearly needs improvement.
I want to solve this problem by getting all the necessary products in one request. Fortunately, the Product-service already supports this feature through a parameter
Let's see how you can modify the code of the selection method for the product field . Previous version:
Replace with more effective:
We did exactly three things:
These changes are enough to solve our N + 1 problem. In the Charles Proxy application window, you can now see one request for a Product-service, which returns three products at once:

We solved the main problem, but you can make the selection even faster! Now the Product-service returns all the data, regardless of what the end customer needs. We could improve the query and return only the requested fields. For example, if the end customer did not request images, why do we need to transfer them to the Cart-service at all?
It's great that the HTTP API of the Product Service already supports this feature through the include parameter for the same collection resource:
For the loader method, add a parameter of type Set with annotation
Now our sample is real effective, it is devoid of the N + 1 problem and only involves the necessary data:

Imagine working with a user graph within a classic social network such as Facebook. If such a system provides the GraphQL API, then nothing prevents the client from sending a request of the following nature:
At the 5-6 nesting level, the full execution of such a query will lead to a sample of all users in the world. The server certainly will not cope with such a task in one sitting and most likely will simply simply “fall”.
There are a number of measures that should be taken in order to protect against such situations:
For example, consider the following query:
Obviously, the depth of such a request - 4, because the longest path within it
If we assume that the weight of each field is 1, then taking into account 7 fields in the query, its complexity is also 7.
In GraphQL Java, the imposition of checks is achieved by specifying additional instrumentation when creating an object
Instrumentation
Instrumentation
Here is an example of a depth test, when it clearly exceeds the specified value:

By the way, the instrumentation mechanism is not limited to the imposition of restrictions. It can be used for other purposes, such as logging or tracing.
We looked at the GraphQL “protection” measures. However, there are a number of techniques that should be noted regardless of the type of API:
So far, we have considered a purely data sample. But GraphQL allows you to organically organize not only data retrieval, but also their change. There is a mechanism for this
For example, adding a product to the basket can be organized through this mutation:
This is similar to the definition of a field, because the mutation also has parameters and a return value.
The implementation of a mutation in the server code using GraphQL SPQR is as follows:
Of course, the main part of the useful work is done inside
In the GraphQL console, you can now perform a query-mutation to add a specific product to our basket in the amount of 2:
Since the mutation has a return value, it can request fields using the same rules as we did for ordinary samples.
Several WIX development teams actively use GraphQL along with Scala and the Sangria library, the main implementation of GraphQL in this language.
One of the useful techniques we use on WIX is support for GraphQL queries when rendering HTML. We do this in order to generate JSON directly into the page code. Here is an example of filling the HTML template:
But what happens at the output:
Such a bundle of HTML-renderer and GraphQL-server allows us to reuse our API to the maximum and not to create an additional layer of controllers. More than this, this technique often turns out to be advantageous in terms of performance, because after loading a page, the JavaScript application does not need to go after the first necessary data again to the backend - they are already on the page.
Today GraphQL uses a large number of companies, including such giants as GitHub, Yelp, Facebook and many others. And if you decide to join them, you should know not only the merits of GraphQL, but also its disadvantages, and there are a lot of them:
It is also worth remembering that if you did not manage to develop the HTTP API well, then, most likely, it will not be possible to develop the GraphQL API as well. What is most important in the development of any API? Separate the internal domain model from the external API model. Build an API based on usage scenarios, not the internal device of the application. Open only the necessary minimum of information, and not everything. Choose the correct names. Describe the graph correctly. There is a resource graph in the HTTP API, and a field graph in the GraphQL API. In both cases, this graph needs to be done qualitatively.
There are alternatives in the HTTP API world, and it is not necessary to always use GraphQL when it comes to the need for complex samples. For example, there is an OData standard that supports partial and expansion samples, like GraphQL, and works on top of HTTP. There is a JSON API standard that works with JSON and supports the capabilities of hypermedia and complex samples. There is also LinkRest, more about which you can learn from https://youtu.be/EsldBtrb1Qc"> the report of Andrus Adamchik on Joker 2017.
For those who want to try GraphQL, I strongly advise reading the comparison articles from engineers who are deeply versed in REST and GraphQL from practical and philosophical points of view:
GraphQL has one interesting advantage over standard APIs. In GraphQL, both synchronous and asynchronous usage scenarios can sit under the same roof.
We considered with you receiving data through
Imagine that a client wants to receive asynchronously notifications about adding a product to the basket. Through the GraphQL API, this can be done based on this scheme:
The customer can subscribe through the following request:
Now, each time a product is added to cart 1, the server will send a message to the subscribed client via WebSocket with the requested cart data. Again, by continuing the GraphQL policy, only the data that the customer requested when signing up will come:
The client can now redraw the basket, without necessarily redrawing the entire page.
This is convenient because both the synchronous API (HTTP) and the asynchronous API (WebSocket) can be described via GraphQL.
Another example of using asynchronous communication is the defer mechanism . The basic idea is that the client chooses what data he wants to receive immediately (synchronously), and those that he is ready to receive later (asynchronously). For example, for such a query:
The server first returns the author and a message for each story:
After that, the server, having received data on the comments, will asynchronously deliver them to the client via WebSocket, specifying in the path for which particular history the comments are now ready:
The code that was used in the preparation of this report can be found on GitHub .
The article is based on the introductory level report by Vladimir Tsukur ( volodymyrtsukur ) from the Joker 2017 conference.
My name is Vladimir, I lead the development of one of the departments in the company WIX. More than hundreds of millions of WIX users create websites of the most diverse directions - from business cards and shops to complex web applications where you can write code and arbitrary logic. As a living example of a project on WIX, I would like to show you a successful website-shop unicornadoptions.com , which offers the opportunity to purchase a kit for taming a unicorn - the perfect gift for a child.
')
A visitor to this site can choose the set he liked for taming a unicorn, say, pink, then see what exactly is included in this set: a toy, a certificate, an icon. Next, the buyer has the opportunity to add the product to the cart, view its contents and place an order. This is a simple example of a store site, and we have many such sites, hundreds of thousands. All of them are built on the same platform, with a single backend, with a set of clients that we support, using the API for this. About API also the speech will go further.
Simple API and its problems
Let's imagine what a general-purpose API (that is, one API for all stores on top of the platform) we could create to provide the functionality of the stores. Concentrate until purely on the receipt of data.
For the product page on such a site, the product name, its price, pictures, description, additional information and much more should be returned. In a complete solution for stores on WIX, there are more than two dozen such data fields. The standard solution for such a task on top of the HTTP API is to describe the
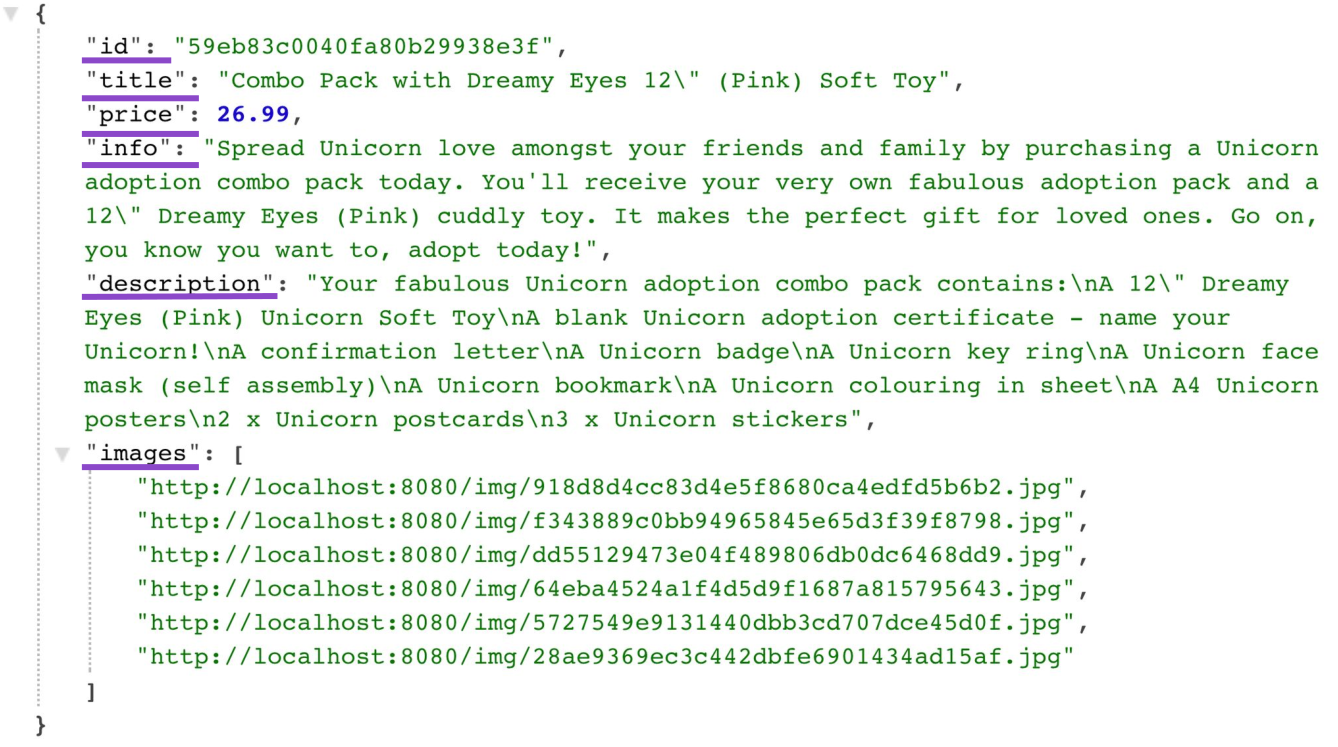
/products/:id resource, which on a GET request returns product data. The following is an example of the response data: { "id": "59eb83c0040fa80b29938e3f", "title": "Combo Pack with Dreamy Eyes 12\" (Pink) Soft Toy", "price": 26.99, "description": "Spread Unicorn love amongst your friends and family by purchasing a Unicorn adoption combo pack today. You'll receive your very own fabulous adoption pack and a 12\" Dreamy Eyes (Pink) cuddly toy. It makes the perfect gift for loved ones. Go on, you know you want to, adopt today!", "sku":"010", "images": [ "http://localhost:8080/img/918d8d4cc83d4e5f8680ca4edfd5b6b2.jpg", "http://localhost:8080/img/f343889c0bb94965845e65d3f39f8798.jpg", "http://localhost:8080/img/dd55129473e04f489806db0dc6468dd9.jpg", "http://localhost:8080/img/64eba4524a1f4d5d9f1687a815795643.jpg", "http://localhost:8080/img/5727549e9131440dbb3cd707dce45d0f.jpg", "http://localhost:8080/img/28ae9369ec3c442dbfe6901434ad15af.jpg" ] } Let's now look at the product catalog page. This page will require a collection resource / products . Here are just in displaying a collection of products on the catalog page, not all product data is needed, but only the price, the name and the main image. For example, the description, additional information, background images, etc. do not interest us.
Suppose, for simplicity, we decide to use the same product data model for the
/products and /products/:id resources. In the case of a collection of such products there will potentially be several. The response scheme can be represented as follows: GET /products [ { title price images description info ... } ] And now let's look at the "payload" of the response from the server for a collection of products. Here is what the client actually uses among more than two dozen fields:
{
"id": "59eb83c0040fa80b29938e3f",
"title": "Combo Pack with Dreamy Eyes 12\" (Pink) Soft Toy",
"price": 26.99,
"info": "Spread Unicorn love amongst your friends and family by purchasing a Unicorn adoption combo pack today. You'll receive your very own fabulous adoption pack and a 12\" Dreamy Eyes (Pink) cuddly toy. It makes the perfect gift for loved ones. Go on, you know you want to, adopt todayl",
" description": "Your fabulous Unicorn adoption combo pack contains:\nA 12\" Dreamy Eyes (Pink) Unicorn Soft Toy\nA blank Unicorn adoption certificate — name your Unicorn!\nA confirmation letter\nA Unicorn badge\nA Unicorn key ring\nA Unicorn face mask (self assembly)\nA Unicorn bookmark\nA Unicorn colouring in sheet\nA A4 Unicorn posters\n2 x Unicorn postcards\n3 x Unicorn stickers",
"images": [
"http://localhost:8080/img/918d8d4cc83d4e5f8680ca4edfd5b6b2.jpg",
"http://localhost:8080/img/f343889c0bb94965845e65d3f39f8798.jpg",
"http://localhost:8080/img/dd55129473604f489806db0dC6468dd9.jpg",
"http://localhost:8080/img/64eba4524a1f4d5d9f1687a815795643.jpg",
"http://localhost:8080/img/5727549e9l3l440dbb3cd707dce45d0f.jpg",
"http://localhost:8080/img/28ae9369ec3c442dbfe6901434ad15af.jpg"
],
...
}Obviously, if I want to keep the product model simple by returning the same data, I end up with an over-fetching problem, getting in some cases more data than I need. In this case, this manifested itself on the product catalog page, but in general, any UI screens that are somehow related to the product will potentially require only a portion (not all) of data from it.
Let's now look at the cart page. In the basket, besides the products themselves, there is also their quantity (in this basket), the price, as well as the total cost of the entire order:
If we continue the simple HTTP API modeling approach, then the basket can be presented through the / carts /: id resource, whose view refers to the resources of the products added to this basket:
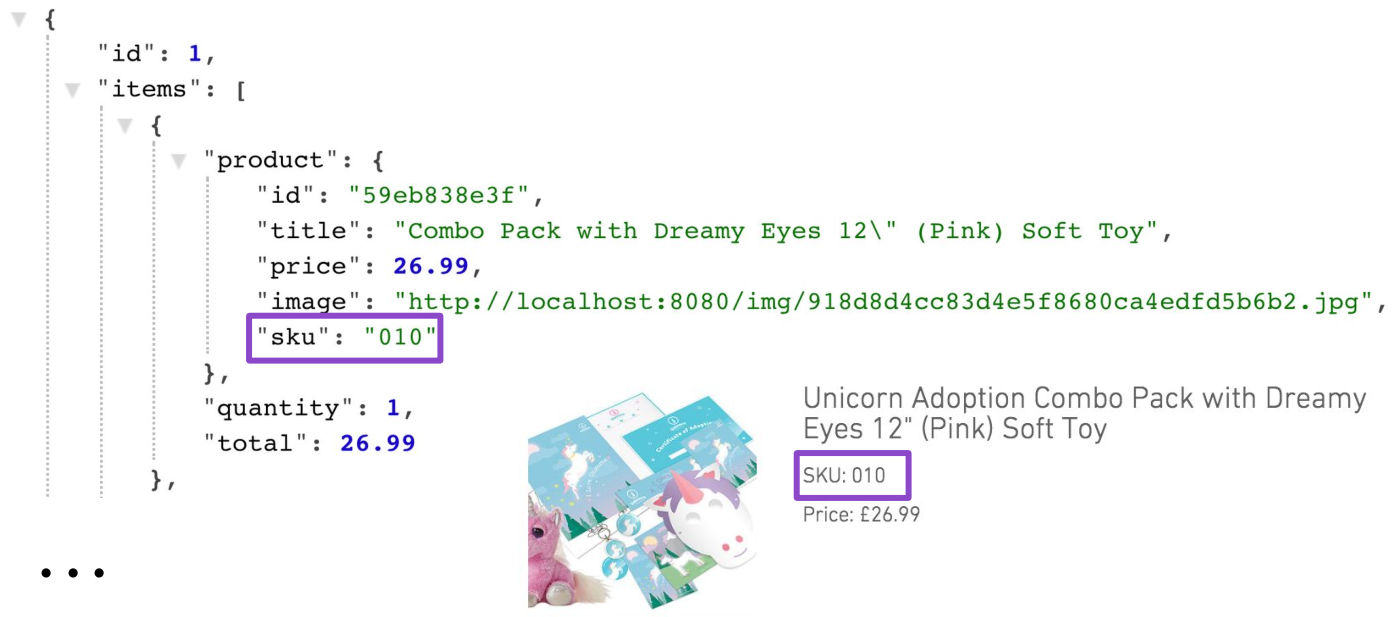
{ "id": 1, "items": [ { "product": "/products/59eb83c0040fa80b29938e3f", "quantity": 1, "total": 26.99 }, { "product": "/products/59eb83c0040fa80b29938e40", "quantity": 2, "total": 25.98 }, { "product": "/products/59eb88bd040fa8125aa9c400", "quantity": 1, "total": 26.99 } ], "subTotal": 79.96 } Now, for example, in order to draw a basket with three products on the frontend, you need to make four requests: one to load the basket itself, and three requests to download product data (name, price and SKU item number).
The second problem we have is under-fetching. The division of responsibility between the basket and product resources has led to the need to make additional requests. There are obviously a number of shortcomings: due to the greater number of requests, we plant the battery of the mobile phone faster and get the full answer more slowly. And the scalability of our solution also raises questions.
Of course, this solution is not suitable for production. One way to get rid of the problem is to add projection support for the basket. One of such projections could, in addition to the data of the basket itself, return data on products. Moreover, this projection will be very specific, because it is on the cart page that you need an inventory number (SKU) of the product. Nowhere else has SKU been needed.
GET /carts/1?projection=with-products Such a “fitting” of resources to a specific UI usually does not end there, and we begin to generate other projections: brief information on the basket, basket projection for the mobile web, and after that - the projection for unicorns.
(In general, in the WIX designer, as a user, you can configure which product data you want to display on the product page and what data to show in the basket)
And here we face difficulties: we are gardening the garden and looking for difficult solutions. There are few standard solutions from the API point of view for such a task, and they usually depend heavily on the framework or library for describing HTTP resources.
What's more important, now it becomes harder to work, because when the requirements on the client side change, the backend must constantly “catch up” and satisfy them.
As the “cherry on the cake,” let's consider another important problem. In the case of a simple HTTP API, the server developer has no idea what kind of data is used by the client. Is the price used? Description? One or all images?
Accordingly, several questions arise. How to work with deprecated / obsolete data? How to find out which data is really not used anymore? How is it relatively safe to remove data from an answer without breaking most clients? There is no answer to these questions with the usual HTTP API. Contrary to the fact that we are optimistic and the API seems to be simple, the situation does not look so hot. This spectrum of problems with the API came not only from WIX. They had to deal with a large number of companies. And now it's interesting to look at a potential solution.
GraphQL. Start
In 2012, in the process of developing a mobile application, Facebook faced a similar problem. Engineers wanted to achieve the minimum number of mobile applications to the server, while at each step receiving only the necessary data and nothing but them. The result of their efforts was GraphQL, presented in 2015 at the React Conf conference. GraphQL is a query description language, as well as the execution environment for these queries.
Consider a typical approach to working with GraphQL-servers.
We describe the scheme
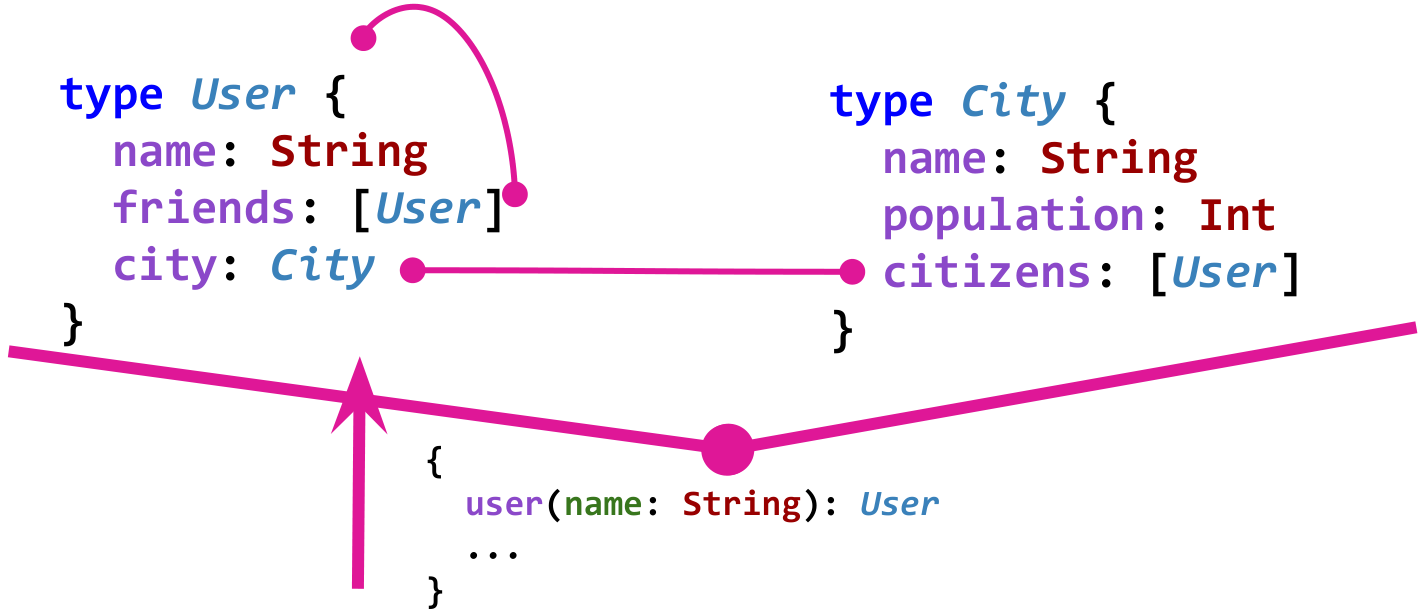
The data scheme in GraphQL defines the types and relationships between them and does this in a strictly typed manner. For example, imagine a simple model of a social network. User
User knows about his friends friends . Users live in the City, and the city knows about its residents through the citizens field. Here is what is graph of such a model in GraphQL:Of course, in order for the graph to be useful, we also need the so-called “entry points”. For example, such an entry point could be getting a user by name.
We are requesting data
Let's see what the essence of the GraphQL query language is. Let us translate this question into this language: “For a user with the name Vanya Unicorn, I want to know the names of his friends, as well as the name and population of the city in which Vanya lives” :
{ user(name: "Vanya Unicorn") { friends { name } city { name population } } } And here comes the answer from the GraphQL server:
{ "data": { "user": { "friends": [ { "name": "Lena" }, { "name": "Stas" } ] "city": { "name": "Kyiv", "population": 2928087 } } } } Notice how the request form is “in tune” with the response form. There is a feeling that this query language was created for JSON. With strict typing. And all this is done in one HTTP POST request - no need to make multiple calls to the server.
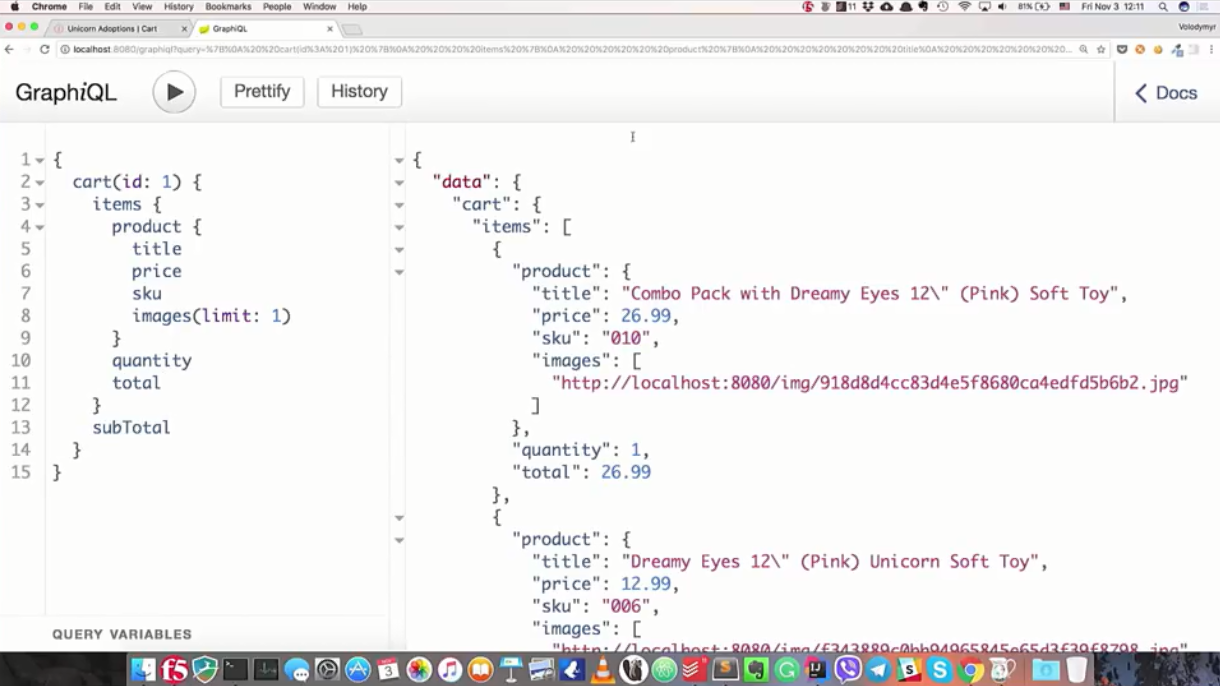
Let's see how it looks in practice. Open the standard console for the GraphQL server, which is called Graph i QL (“graph”). For a request for a basket, I will execute the following request: “I want to receive a basket by identifier 1, all positions of this basket and product information are interested. Of the information, the name, price, inventory number and images (and only the first) are important. I am also interested in the quantity of these products, their price and the total cost of the basket . ”
{ cart(id: 1) { items { product { title price sku images(limit: 1) } quantity total } subTotal } } After successful execution of the request, we will receive exactly what was asked:
Main advantages
- Flexible selection. The client can make a request for your specific requirements.
- Effective sampling. Only the requested data is returned in the response.
- Faster development. Many changes on the client can occur without the need to change anything on the server side. For example, based on our example, you can easily show a different view of the basket for the mobile web.
- Useful analytics. Since the client is obliged to specify the fields explicitly in the request, the server knows exactly which fields are really needed. And this is important information for the deprecation-policy.
- Works on top of any data source and transport. It is important that GraphQL allows you to work on top of any data source and any transport. In this case, HTTP is not a panacea, GraphQL can also work through WebSocket, and we will touch on this point later.
Today GraphQL server can be done in almost any language. The most complete version of the GraphQL server is GraphQL.js for the Node platform. In the Java community, the reference implementation is GraphQL Java .
Create GraphQL API
Let's take a look at how to create a GraphQL server using a specific life example.
Consider a simplified version of an online store based on a microservice architecture with two components:
- Cart-service, providing work with the user basket. Stores data in a relational database and uses SQL to access data. Very simple service, without too much magic :)
- A product-service providing access to the product catalog, from which, in fact, the basket is filled. Provides HTTP API for accessing product data.
Both services are implemented on top of the classic Spring Boot and already contain all the basic logic.
We intend to create GraphQL API over the Cart service. This API is designed to provide access to the cart data and products added to it.
First version
We will be helped by the GraphQL reference implementation for the Java ecosystem, which we mentioned earlier - GraphQL Java.
Add some dependencies to
pom.xml: <dependency> <groupId>com.graphql-java</groupId> <artifactId>graphql-java</artifactId> <version>9.3</version> </dependency> <dependency> <groupId>com.graphql-java</groupId> <artifactId>graphql-java-tools</artifactId> <version>5.2.4</version> </dependency> <dependency> <groupId>com.graphql-java</groupId> <artifactId>graphql-spring-boot-starter</artifactId> <version>5.0.2</version> </dependency> <dependency> <groupId>com.graphql-java</groupId> <artifactId>graphiql-spring-boot-starter</artifactId> <version>5.0.2</version> </dependency> In addition to the previously mentioned
graphql-java we will need the graphql-java-tools, library of graphql-java-tools, as well as the Spring Boot “starters” for GraphQL, which will greatly simplify the first steps to create a GraphQL server:- graphql-spring-boot-starter provides a GraphQL Java quick bind mechanism with Spring Boot;
- graphiql-spring-boot-starter adds the Graphi QL interactive web console to execute GraphQL queries.
The next important step is to define the GraphQL service schema, our graph. The nodes of this graph are described using types , and edges using fields . An empty graph definition looks like this:
schema { } In this scheme, as you remember, there are “entry points” or top-level requests. They are defined via the query field in the schema. Let's name our type for entry points EntryPoints :
schema { query: EntryPoints } We define in it a basket search by identifier as the first entry point:
type EntryPoints { cart(id: Long!): Cart } Cart is nothing more than a field in terms of GraphQL. id is a parameter of this field with scalar type Long . Exclamation mark ! after specifying the type means that the parameter is required.It's time to determine the type of
Cart : type Cart { id: Long! items: [CartItem!]! subTotal: BigDecimal! } In addition to the standard
id , the items items and the sum for all products subTotal are included in the basket. Notice that items are defined as a list, as indicated by square brackets [] . Items in this list are CartItem types. The presence of an exclamation mark after the name of the field type ! indicates that the field is required. This means that the server undertakes to return a non-empty value for this field if it was requested.It remains to look at the definition of the type
CartItem , which includes a link to the product ( productId ), how many times it is added to the cart ( quantity ) and the sum of the product, recalculated to the quantity ( total ): type CartItem { productId: String! quantity: Int! total: BigDecimal! } Everything is simple here - all fields are scalar types and are required.
This scheme was not chosen randomly. The Cart service already defines the Cart
Cart and its CartItem elements with exactly the same names and field types as in the GraphQL scheme. The basket model uses the Lombok library for autogenerating getters / setters, constructors, and other methods. JPA is used for persistence in DB.Cart class: import lombok.Data; import javax.persistence.*; import java.math.BigDecimal; import java.util.ArrayList; import java.util.List; @Entity @Data public class Cart { @Id @GeneratedValue private Long id; @ElementCollection(fetch = FetchType.EAGER) private List<CartItem> items = new ArrayList<>(); public BigDecimal getSubTotal() { return getItems().stream() .map(Item::getTotal) .reduce(BigDecimal.ZERO, BigDecimal::add); } } CartItem class: import lombok.AllArgsConstructor; import lombok.Data; import javax.persistence.Column; import javax.persistence.Embeddable; import java.math.BigDecimal; @Embeddable @Data @AllArgsConstructor public class CartItem { @Column(nullable = false) private String productId; @Column(nullable = false) private int quantity; @Column(nullable = false) private BigDecimal total; } So, the basket (
Cart ) and elements of the basket ( CartItem ) are described both in the GraphQL scheme, in the code, and “compatible” with each other by the set of fields and their types. But this is still not enough for our service to work.We need to clarify exactly how the "
cart(id: Long!): Cart " entry point will work. To do this, create an extremely simple Java configuration for Spring with beans like GraphQLQueryResolver. GraphQLQueryResolver describes the entry points in the schema. We define a method with a name identical to the field at the entry point ( cart ), make it compatible by the type of parameters, and use cartService to find the same basket by identifier: @Bean public GraphQLQueryResolver queryResolver() { return new GraphQLQueryResolver () { public Cart cart(Long id) { return cartService.findCart(id); } } } These changes are enough for us to get a working application. After restarting the Cart service in the GraphiQL console, the following query will start successfully:
{ cart(id: 1) { items { productId quantity total } subTotal } } On a note
- We use the scalar types
LongandStringas unique identifiers for the cart and product. In GraphQL there is a special type for such purposes -ID. Semantically, this is a better choice for this API. Values of typeIDcan be used as a key for caching. - At this stage of development of our application, the internal and external domain model is completely identical. These are the
CartandCartItemand their direct use in GraphQL resolvers. In combat applications, these models are recommended to separate. For GraphQL resolvers, there must be a separate model from the internal domain.
Making API useful
So we got the first result, and that's great. But now our API is too primitive. For example, for the time being it is not possible to request useful data on a product, such as its name, price, article number, pictures, and so on. Instead, there is only a
productId . Let's make the API really useful and add full support for the product concept. Here is what its definition looks like in the schema: type Product { id: String! title: String! price: BigDecimal! description: String sku: String! images: [String!]! } Add the required field to the
CartItem , and mark the outdated productId field: type Item { quantity: Int! product: Product! productId: String! @deprecated(reason: "don't use it!") total: BigDecimal! } With the scheme figured out. Now is the time to describe how the selection for the
product field will work. Previously, we relied on the presence of getters in the Cart and CartItem , which allowed GraphQL Java to automatically bind values. But here it should be recalled that there are no properties of the product in the CartItem class: @Embeddable @Data @AllArgsConstructor public class CartItem { @Column(nullable = false) private String productId; @Column(nullable = false) private int quantity; @Column(nullable = false) private BigDecimal total; } We have a choice:
- add the product property to the CartItem and “teach” it to get product data;
- Determine how to get a product without changing the CartItem class.
The second way is more preferable, because in this case the model of describing the internal subject area (
CartItem class) will not overgrow with the details of the implementation of the Graph i QL API.The GraphQLResolver marker interface will help in achieving this goal. By implementing it, you can determine (or redefine) exactly how to get field values for type
T Here is the corresponding bean in the Spring configuration: @Bean public GraphQLResolver<CartItem> cartItemResolver() { return new GraphQLResolver<CartItem>() { public Product product(CartItem item) { return http.getForObject("http://localhost:9090/products/{id}", Product.class, item.getProductId()); } }; } The name of the method
product not chosen randomly. GraphQL Java searches for data loader methods by field name, and we just needed to define a loader for the product field! An object of type CartItem , passed as a parameter, defines the context in which the product is selected. Next - a matter of technology. With the help of the http client of the RestTemplate type RestTemplate we perform a GET request to the Product-service and convert the result into a Product , which looks like this: @Data public class Product { private String id; private String title; private BigDecimal price; private String description; private String sku; private List<String> images; } These changes should be enough to implement a more interesting sample that includes the real connection between the basket and the products that have been added to it.
After restarting the application, you can try a new query in the Graph i QL console.
{ cart(id: 1) { items { product { title price sku images } quantity total } subTotal } } And here is the result of the query:
Although the
productId was tagged as @deprecated , queries with this field will continue to work. But the Graph i QL console will not offer autocomplete for such fields and will highlight their use in a special way:It's time to show the Document Explorer, part of the Graph i QL console, which builds on the basis of the GraphQL schema and shows information on all the specific types. Here’s what the Document Explorer looks like for the
CartItem type:But back to the example. In order to achieve the same functionality as in the very first demo, there is still not enough overlap on the number of returned images. After all, for a basket, for example, you need only one image for each product:
images(limit: 1) To do this, change the schema and add a new parameter for the images field to the Product type:
type Product { id: ID! title: String! price: BigDecimal! description: String sku: String! images(limit: Int = 0): [String!]! } And in the application code we will use it again
GraphQLResolver, only this time by type Product: @Bean public GraphQLResolver<Product> productResolver() { return new GraphQLResolver<Product>() { public List<String> images(Product product, int limit) { List<String> images = product.getImages(); int normalizedLimit = limit > 0 ? limit : images.size(); return images.subList(0, Math.min(normalizedLimit, images.size())); } }; } Again, I note that the name of the method is not accidental: it coincides with the name of the field
images. The context object Productgives access to the images, and limitis a parameter of the field itself.If the client does not specify anything as a value for
limit, then our service will return all product images. If the client has specified a specific value, then the service will return exactly as much (but not more than they are in the product).We compile the project and wait for the server to restart. Restarting the scheme in the console and executing the query, we see that the full query really works.
{ cart(id: 1) { items { product { title price sku images(limit: 1) } quantity total } subTotal } } Agree, all this is very cool. In a short time, we not only learned what GraphQL is, but also transferred a simple microservice system to support such an API. And it didn’t matter to us where the data came from: both the SQL and the HTTP API were well placed under the same roof.
Code-First and GraphQL SPQR Approach
You might have noticed that during the development process there was some inconvenience, namely the need to constantly keep the GraphQL scheme and code in sync. Type changes always had to be done in two places. In many cases it is more convenient to use the code-first approach. Its essence is that the scheme for GraphQL is automatically generated based on the code. In this case, you do not need to support the scheme separately. Now I will show how it looks.
Only the basic features of GraphQL Java are no longer enough; we will also need the GraphQL SPQR library. The good news is that GraphQL SPQR is an add-on to GraphQL Java, and not an alternative implementation of the Java Graphical SQL Server.
Add the desired dependency in
pom.xml: <dependency> <groupId>io.leangen.graphql</groupId> <artifactId>spqr</artifactId> <version>0.9.8</version> </dependency> Here is the code that implements the same functionality based on GraphQL SPQR for the basket:
@Component public class CartGraph { private final CartService cartService; @Autowired public CartGraph(CartService cartService) { this.cartService = cartService; } @GraphQLQuery(name = "cart") public Cart cart(@GraphQLArgument(name = "id") Long id) { return cartService.findCart(id); } } And for the product:
@Component public class ProductGraph { private final RestTemplate http; @Autowired public ProductGraph(RestTemplate http) { this.http = http; } @GraphQLQuery(name = "product") public Product product(@GraphQLContext CartItem cartItem) { return http.getForObject( "http://localhost:9090/products/{id}", Product.class, cartItem.getProductId() ); } @GraphQLQuery(name = "images") public List<String> images(@GraphQLContext Product product, @GraphQLArgument(name = "limit", defaultValue = "0") int limit) { List<String> images = product.getImages(); int normalizedLimit = limit > 0 ? limit : images.size(); return images.subList(0, Math.min(normalizedLimit, images.size())); } } The @GraphQLQuery annotation is used to mark field loader methods. The annotation
@GraphQLContextspecifies the type of sampling for the field. And the annotation @GraphQLArgumentmarks the argument parameters explicitly. All of this is part of a single mechanism that helps GraphQL SPQR generate a circuit automatically. Now, if you delete the old Java configuration and schema, restart the Cart service using the new features from GraphQL SPQR, then you can make sure that everything works in the same way as before.Solve the problem of N + 1
It is time to look at b on lshih detail how the implementation of the whole request "under the hood". We quickly created the GraphQL API, but does it work efficiently?
Consider the following example:
Receiving a basket
cartoccurs in a single SQL query to the database. Data on itemsand subtotalcome back in the same place, because the elements of the basket loaded with the entire collection of JPA-based strategy eager fetch: @Data public class Cart { @ElementCollection(fetch = FetchType.EAGER) private List<Item> items = new ArrayList<>(); ... } When it comes to downloading data by products, then there will be exactly as many requests for a Product-service as in this basket of products. If there are three different products in the basket, then we will receive three requests to the HTTP API of the product service, and if there are ten of them, then the same service will have to answer ten such requests.
Here is what the communication between the Cart-Service and the Product-Service in Charles Proxy looks like:
Accordingly, we return to the classic N + 1 problem. Exactly the one from which they tried so hard to leave at the very beginning of the report. Undoubtedly, we have progress, because there is exactly one request between the end customer and our system. But inside the server ecosystem, performance clearly needs improvement.
I want to solve this problem by getting all the necessary products in one request. Fortunately, the Product-service already supports this feature through a parameter
idsin the collection resource: GET /products?ids=:id1,:id2,...,:idn Let's see how you can modify the code of the selection method for the product field . Previous version:
@GraphQLQuery(name = "product") public Product product(@GraphQLContext CartItem cartItem) { return http.getForObject( "http://localhost:9090/products/{id}", Product.class, cartItem.getProductId() ); } Replace with more effective:
@GraphQLQuery(name = "product") @Batched public List<Product> products(@GraphQLContext List<Item> items) { String productIds = items.stream() .map(Item::getProductId) .collect(Collectors.joining(",")); return http.getForObject( "http://localhost:9090/products?ids={ids}", Products.class, productIds ).getProducts(); } We did exactly three things:
- marked the loader method with the @Batched annotation , making it clear to GraphQL SPQR that the download should be done by batch;
- changed the return type and the context parameter to the list, because working with batch assumes that several objects are received and returned;
- changed the body of the method by implementing a sample of all the necessary products at once.
These changes are enough to solve our N + 1 problem. In the Charles Proxy application window, you can now see one request for a Product-service, which returns three products at once:
Effective sampling by field
We solved the main problem, but you can make the selection even faster! Now the Product-service returns all the data, regardless of what the end customer needs. We could improve the query and return only the requested fields. For example, if the end customer did not request images, why do we need to transfer them to the Cart-service at all?
It's great that the HTTP API of the Product Service already supports this feature through the include parameter for the same collection resource:
GET /products?ids=...?include=:field1,:field2,...,:fieldN For the loader method, add a parameter of type Set with annotation
@GraphQLEnvironment. GraphQL SPQR understands that the code in this case "asks" a list of field names that are requested for the product, and automatically fills them in: @GraphQLQuery(name = "product") @Batched public List<Product> products(@GraphQLContext List<Item> items, @GraphQLEnvironment Set<String> fields) { String productIds = items.stream() .map(Item::getProductId) .collect(Collectors.joining(",")); return http.getForObject( "http://localhost:9090/products?ids={ids}&include={fields}", Products.class, productIds, String.join(",", fields) ).getProducts(); } Now our sample is real effective, it is devoid of the N + 1 problem and only involves the necessary data:
"Heavy" requests
Imagine working with a user graph within a classic social network such as Facebook. If such a system provides the GraphQL API, then nothing prevents the client from sending a request of the following nature:
{ user(name: "Vova Unicorn") { friends { name friends { name friends { name friends { name ... } } } } } } At the 5-6 nesting level, the full execution of such a query will lead to a sample of all users in the world. The server certainly will not cope with such a task in one sitting and most likely will simply simply “fall”.
There are a number of measures that should be taken in order to protect against such situations:
- Limit the depth of the request. In other words, customers should not be allowed to request data of arbitrary nesting.
- Limit query complexity. By assigning a weight to each field and calculating the sum of the weights of all the fields in the request, you can accept or reject such requests on the server.
For example, consider the following query:
{ cart(id: 1) { items { product { title } quantity } subTotal } } Obviously, the depth of such a request - 4, because the longest path within it
cart -> items -> product -> title.If we assume that the weight of each field is 1, then taking into account 7 fields in the query, its complexity is also 7.
In GraphQL Java, the imposition of checks is achieved by specifying additional instrumentation when creating an object
GraphQL: GraphQL.newGraphQL(schema) .instrumentation(new ChainedInstrumentation(Arrays.asList( new MaxQueryComplexityInstrumentation(20), new MaxQueryDepthInstrumentation(3) ))) .build(); Instrumentation
MaxQueryDepthInstrumentationchecks the depth of the query and does not allow launching too “deep” queries (in this case, with a depth of more than 3).Instrumentation
MaxQueryComplexityInstrumentationbefore the execution of the request counts and checks its complexity. If this number exceeds the specified value (20), then such a request is rejected. You can redefine the weight for each field, because some of them obviously get "heavier" than others. For example, the product field can be assigned complexity 10 through the annotation @GraphQLComplexity,supported in GraphQL SPQR: @GraphQLQuery(name = "product") @GraphQLComplexity("10") public List<Product> products(...) Here is an example of a depth test, when it clearly exceeds the specified value:
By the way, the instrumentation mechanism is not limited to the imposition of restrictions. It can be used for other purposes, such as logging or tracing.
We looked at the GraphQL “protection” measures. However, there are a number of techniques that should be noted regardless of the type of API:
- throttling / rate-limiting - limiting the number of requests per unit of time
- timeouts - time limit for operations with other services, databases, etc .;
- pagination - pagination support.
Change data through mutations
So far, we have considered a purely data sample. But GraphQL allows you to organically organize not only data retrieval, but also their change. There is a mechanism for this
mutation: schema { query: EntryPoints, mutation: Mutations } For example, adding a product to the basket can be organized through this mutation:
type Mutations { addProductToCart(cartId: Long!, productId: String!, count: Int = 1): Cart } This is similar to the definition of a field, because the mutation also has parameters and a return value.
The implementation of a mutation in the server code using GraphQL SPQR is as follows:
@GraphQLMutation(name = "addProductToCart") public Cart addProductToCart( @GraphQLArgument(name = "cartId") Long cartId, @GraphQLArgument(name = "productId") String productId, @GraphQLArgument(name = "quantity", defaultValue = "1") int quantity) { return cartService.addProductToCart(cartId, productId, quantity); } Of course, the main part of the useful work is done inside
cartService. And the task of this interlayer method is to associate it with the API. As in the case of data sampling, thanks to annotations it is @GraphQL*very easy to understand exactly which GraphQL scheme is generated from this method definition.In the GraphQL console, you can now perform a query-mutation to add a specific product to our basket in the amount of 2:
mutation { addProductToCart( cartId: 1, productId: "59eb83c0040fa80b29938e3f", quantity: 2) { items { product { title } quantity total } subTotal } } Since the mutation has a return value, it can request fields using the same rules as we did for ordinary samples.
Several WIX development teams actively use GraphQL along with Scala and the Sangria library, the main implementation of GraphQL in this language.
One of the useful techniques we use on WIX is support for GraphQL queries when rendering HTML. We do this in order to generate JSON directly into the page code. Here is an example of filling the HTML template:
// Pre-rendered <html> <script data-embedded-graphiql> { product(productId: $productId) title description price ... } } </script> </html> But what happens at the output:
// Rendered <html> <script> window.DATA = { product: { title: 'GraphQL Sticker', description: 'High quality sticker', price: '$2' ... } } </script> </html> Such a bundle of HTML-renderer and GraphQL-server allows us to reuse our API to the maximum and not to create an additional layer of controllers. More than this, this technique often turns out to be advantageous in terms of performance, because after loading a page, the JavaScript application does not need to go after the first necessary data again to the backend - they are already on the page.
GraphQL Disadvantages
Today GraphQL uses a large number of companies, including such giants as GitHub, Yelp, Facebook and many others. And if you decide to join them, you should know not only the merits of GraphQL, but also its disadvantages, and there are a lot of them:
- -, GraphQL . GraphQL , HTTP API. Cache-Control Last-Modified HTTP GraphQL API. , proxy gateways (Varnish, Fastly ). , GraphQL , , .
- GraphQL — . , API, , .
- GraphQL . .
- . GraphQL — . JSON XML, , , GraphQL, .
- GraphQL . , HTTP PUT POST -. , . GraphQL . .
- . , -: «delete» «kill», «annihilate» «terminate», . GraphQL API . HTTP DELETE .
- Joker 2016 . GraphQL . API- , , , HATEOAS, , « REST». , , GraphQL .
It is also worth remembering that if you did not manage to develop the HTTP API well, then, most likely, it will not be possible to develop the GraphQL API as well. What is most important in the development of any API? Separate the internal domain model from the external API model. Build an API based on usage scenarios, not the internal device of the application. Open only the necessary minimum of information, and not everything. Choose the correct names. Describe the graph correctly. There is a resource graph in the HTTP API, and a field graph in the GraphQL API. In both cases, this graph needs to be done qualitatively.
There are alternatives in the HTTP API world, and it is not necessary to always use GraphQL when it comes to the need for complex samples. For example, there is an OData standard that supports partial and expansion samples, like GraphQL, and works on top of HTTP. There is a JSON API standard that works with JSON and supports the capabilities of hypermedia and complex samples. There is also LinkRest, more about which you can learn from https://youtu.be/EsldBtrb1Qc"> the report of Andrus Adamchik on Joker 2017.
For those who want to try GraphQL, I strongly advise reading the comparison articles from engineers who are deeply versed in REST and GraphQL from practical and philosophical points of view:
- https://philsturgeon.uk/api/2017/01/24/graphql-vs-rest-overview/
- https://blog.runscope.com/posts/you-might-not-need-graphql
Finally about Subscriptions and defer
GraphQL has one interesting advantage over standard APIs. In GraphQL, both synchronous and asynchronous usage scenarios can sit under the same roof.
We considered with you receiving data through
query, changing the state of the server through mutation, but there is another goodness. For example, the ability to organize subscriptions subscriptions.Imagine that a client wants to receive asynchronously notifications about adding a product to the basket. Through the GraphQL API, this can be done based on this scheme:
schema { query: Queries, mutation: Mutations, subscription: Subscriptions } type Subscriptions { productAdded(cartId: String!): Cart } The customer can subscribe through the following request:
subscription { productAdded(cart: 1) { items { product ... } subTotal } } Now, each time a product is added to cart 1, the server will send a message to the subscribed client via WebSocket with the requested cart data. Again, by continuing the GraphQL policy, only the data that the customer requested when signing up will come:
{ "data": { "productAdded": { "items": [ { "product": …, "subTotal": … }, { "product": …, "subTotal": … }, { "product": …, "subTotal": … }, { "product": …, "subTotal": … } ], "subTotal": 289.33 } } } The client can now redraw the basket, without necessarily redrawing the entire page.
This is convenient because both the synchronous API (HTTP) and the asynchronous API (WebSocket) can be described via GraphQL.
Another example of using asynchronous communication is the defer mechanism . The basic idea is that the client chooses what data he wants to receive immediately (synchronously), and those that he is ready to receive later (asynchronously). For example, for such a query:
query { feedStories { author { name } message comments @defer { author { name } message } } } The server first returns the author and a message for each story:
{ "data": { "feedStories": [ { "author": …, "message": … }, { "author": …, "message": … } ] } } After that, the server, having received data on the comments, will asynchronously deliver them to the client via WebSocket, specifying in the path for which particular history the comments are now ready:
{ "path": [ "feedStories", 0, "comments" ], "data": [ { "author": …, "message": … } ] } Sample source code
The code that was used in the preparation of this report can be found on GitHub .
More recently, we announced the JPoint 2019 , which will be held April 5-6, 2019. More information about what to expect from the conference, you can learn from our habrapost . Until December 1st, Early Bird tickets are still available at the lowest price.
Source: https://habr.com/ru/post/428517/
All Articles