Regular expressions in Python from simple to complex. Details, examples, pictures, exercises
Regular expressions in Python from simple to complex

I decided to give my schoolchildren just the problem for regular expressions to learn. And the tasks need some theory. And I began to look for good texts in Russian. Found tolerable heels, but it's not that. Something is crumpled, something is missing. These texts had not only a fatal flaw. Few pictures, few examples. And there are almost no reasonable tasks. Well, is searching for an IP address really the most common task for regular expressions? So I think not.
About the difference (?: ...) / (...) you will find figs, and without this knowledge in some cases you can only suffer.
Plus in python there are a lot of regular buns. For example,
re.split can add that piece of text that was cut into the list of parts. And in re.sub you can, instead of a template to replace, pass the function. These are real things that are directly needed, but nobody writes about it.So this rather multi-letter material was born with details, subtleties, pictures and tasks.
')
I hope you manage to extract something new and useful from it, even if you are already in trouble with the regulars.
Ps. Schoolchildren pass the problem solving into a testing system, so the tasks are designed in a somewhat formal form.
Content
Regular expressions in Python from simple to complex ;Content ;
Examples of regular expressions ;
Strength and responsibility ;
Documentation and links ;
Basics of syntax ;
Templates corresponding to one character ;
Quantifiers (specifying the number of repetitions) ;
Greed in regulars and the boundaries of the pattern found ;
Intersection of substrings ;
Sandbox experiments ;
Regulars in python ;
An example of using all the basic functions ;
The subtleties of screening in python ('\\\\\\\\ foo') ;
Using additional flags in python ;
Writing and testing regular expressions ;
Tasks - 1 ;
Bracket groups (?: ...) and enumerations | ;
Enumerations (operation "OR") ;
Bracket groups (grouping plus quantifiers) ;
Brackets plus transfers ;
More examples ;
Tasks - 2 ;
Group brackets (...) and match-objects in python ;
Match objects ;
Group brackets (...) ;
Subtleties with brackets and numbering groups. ;
Groups and re.findall ;
Groups and re.split ;
Using groups for replacements ;
Replacement with template processing function in python ;
Links to groups when searching ;
Tasks - 3 ;
Templates that correspond not to a specific text, but positions ;
Simple patterns matching positions ;
Complicated patterns, matching positions ( lookaround and Co) ;
lookaround on the example of the kings and emperors of France ;
Tasks - 4 ;
Post scriptum ;
A regular expression is a string that specifies a search pattern for substrings in the text. One pattern can match many different lines. The term “ Regular expressions ” is a translation of the English phrase “Regular expressions”. The translation does not accurately reflect the meaning, the “ patterned expressions ” would be more correct. A regular expression, or shortly "regular", consists of ordinary characters and special command sequences. For example,
\d specifies any digit, and \d+ - specifies any sequence of one or more digits. Work with regular programs implemented in all modern programming languages. However, there are several "dialects", so the functionality of regular expressions may vary from language to language. In some programming languages it is very convenient to use regulars (for example, in python), in some not so much (for example, in C ++). Regular Expression Examples
| Regular | Its meaning |
|---|---|
simple text | Exactly the text “simple text” |
\d{5} | 5 digit strings\d means any digit{5} - exactly 5 times |
\d\d/\d\d/\d{4} | Dates in DD / MM / YYYY format (and other pieces similar to them, for example, 98/76/5432) |
\b\w{3}\b | Three letter words\b means word boundary(on the one hand the letter, but on the other - not) \w - any letter,{3} - exactly three times |
[-+]?\d+ | Integer, for example, 7, +17, -42, 0013 (leading zeros are possible)[-+]? - either -, or +, or empty\d+ - a sequence of 1 or more digits |
[-+]?(?:\d+(?:\.\d*)?|\.\d+)(?:[eE][-+]?\d+)? | Real number, possibly in exponential notation For example, 0.2, +5.45, -.4, 6e23, -3.17E-14. See picture below. |

Strength and responsibility
Regular expressions, or shortly, regulars is a very powerful tool. But they should be used with intelligence and caution, and only where they really benefit, not harm. First, poorly written regular expressions are slow. Secondly, they are often very difficult to read, especially if the regular was not written by you five minutes ago. Thirdly, very often even a small change in the task (what is required to be found) leads to a significant change in expression. Therefore, it is often said about regulars that this is write only code (code that is only written from scratch, but does not read and does not rule). As well as joking: Some people, when faced with a problem, think, "I know, I will solve it with regular expressions." Now they have two problems. Here is an example of a regular write-only (to check the validity of an e-mail address (do not do this !!!)):
(?:[a-z0-9!#$%&'*+/=?^_`{|}~-]+(?:\.[a-z0-9!#$%&'*+/=?^_`{|}~-]+)*|"(?:[\x01-\x08\x0b\x0c\x0e-\x1f\x21\x23-\x5b\x5d-\x7f]|\\[\x01-\x09\x0b\x0c\x0e-\x7f])*")@(?:(?:[a-z0-9](?:[a-z0-9-]*[a-z0-9])?\.)+[a-z0-9](?:[a-z0-9-]*[a-z0-9])?|\[(?:(?:25[0-5]| 2[0-4][0-9]|[01]?[0-9][0-9]?)\.){3}(?:25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?|[a-z0-9-]*[a-z0-9]:(?:[\x01-\x08\x0b\x0c\x0e-\x1f\x21-\x5a\x53-\x7f]|\\[\x01-\x09\x0b\x0c\x0e-\x7f])+)\]) And here is a more accurate regular checklist for checking the correctness of an email address to the RFC822 standard. If you suddenly check your email, do not do it! If the user enters the address, then let him enter almost anything, if only there was a dog. The most reliable way is to send a letter there and make sure that the user can receive it. Documentation and links
- Original documentation: https://docs.python.org/3/library/re.html ;
- Very detailed and detailed material: https://www.regular-expressions.info/ ;
- Various complex tricks and subtleties with examples: http://www.rexegg.com/ ;
- On-line debugging of regulars https://regex101.com (do not forget to put a tick in Python in the FLAVOR section on the left);
- On-line visualization of regulars https://www.debuggex.com/ (do not forget to choose Python);
- Powerful text editor Sublime text 3 , in which a very convenient search for regulars;
Basic syntax
Any string (in which there are no characters
.^$*+?{}[]\|() ) Is itself a regular expression. Thus, the expression “Haha” will correspond to the string “Haha” and only it. Regular expressions are case-sensitive, so the string “haha” (with a small letter) will no longer match the expression above. Like strings in the Python language, regular expressions have special characters .^$*+?{}[]\|() , Which are control structures in regulars. To write them simply as symbols you need to escape them, for which you need to put a \ in front of them. Just as in python, the expression \n in regular expressions corresponds to the end of the line, and \t - tabulation. Templates matching one character
In all examples below, regular expression matches are highlighted in turquoise with underlining.
| Template | Description | Example | Apply to text |
|---|---|---|---|
. | Any single character except newline \n . | .. | milk , malako , And a little Ihleb |
\d | Any number | \d\d | SU35 , SU11 1, AL SU14 |
\D | Any character except digit | 926\D123 | 926) 123 , 1 926-123 4 |
\s | Any whitespace character (space, tab, end of line, etc.) | \s | boron ode , beard |
\S | Any non-space character | \S123 | X123 , I123,! 123 456, 1 + 123456 |
\w | Any letter (that can be part of a word), as well as numbers and _ | \w\w\w | Year , f_3 , qwe rt |
\W | Any non-letter, non-digit and underscore | \W | catfish! , som? |
[..] | One of the characters in brackets, as well as any character in the ab range | [0-9][0-9A-Fa-f] | 12 , 1F , 4B |
[^..] | Any character other than those listed. | <[^>]> | <1> , <a> , <>> |
\d≈[0-9],\D≈[^0-9],\w≈[0-9a-zA-Z--],\s≈[ \f\n\r\t\v] | The letter “e” is not included in the total range of letters! Generally speaking, everything that is marked as a “digit” is included in \d , and in \w is included as a letter. So much more! | ||
[abc-], [-1] | if you need a minus, you need to specify it last or first | ||
[*[(+\\\]\t] | inside brackets you need to escape only ] and \ | ||
\b | The beginning or end of a word (on the left is empty or non-letter, on the right is a letter and vice versa). Unlike previous matches position, not symbol | \b | shaft , pass, transshipment |
\B | Not the boundary of the word: either the left and the right of the letter, either the left and the right are NOT letters | \B | shaft , shaft, shaft |
\B\B | pass, shaft, Pere shaft |
Quantifiers (specifying the number of repetitions)
| Template | Description | Example | Apply to text |
|---|---|---|---|
{n} | Exactly n repetitions. | \d{4} | 1, 12, 123, 1234 , 12345 |
{m,n} | From m to n repetitions inclusive | \d{2,4} | 1, 12 , 123 , 1234 , 12345 |
{m,} | At least m reps | \d{3,} | 1, 12, 123 , 1234 , 12345 |
{,n} | No more than n repetitions | \d{,2} | 1 , 12 , 12 3 |
? | Zero or one occurrence, synonym {0,1} | ? | shaft , shafts , shaft |
* | Zero or more, synonym {0,} | \d* | SU , SU1 , SU12 , ... |
+ | One or more, synonym {1,} | a\)+ | a) , a)) , a))) , b a) ]) |
*?+???{m,n}?{,n}?{m,}? | Default greedy quantifiers - capture as many characters as possible. Adding ? makes them lazythey capture the minimum possible number of characters | \(.*\)\(.*?\) | (a + b) * (c + d) * (e + f) (a + b) * (c + d) * (e + f) |
Greed in regulars and the boundaries of the pattern found
As stated above, the default quantifiers are greedy . This approach solves a very important problem - the template boundary problem. Let's say the \d+ pattern captures as many digits as possible. Therefore, you can be sure that before the pattern found there is not a figure, and after that there is no figure. However, if there are non-greedy parts in the pattern (for example, explicit text), then the substring can be found unsuccessfully. For example, if we want to find “words” starting with , followed by numbers, with the regular \d* , then we will find the wrong patterns:
PA SU13 SU12 TO SU6 END IT IS SUCCESSFUL.
In cases where this is important, the condition on the border of the template must be added to the regular schedule. How this can be done will be further.
Intersection of substrings
Normally, regulars allow you to find only non-overlapping patterns. Together with the word boundary problem, this makes their use in some cases more difficult. For example, if we decide to search for e-mail addresses using the irregular regular \w+@\w+ (or even better, [\w'._+-]+@[\w'._+-]+ ), then in unsuccessful case we find this:
foo @ boo @ goo @ moo @ roo @ zoo
That is, on the one hand, it is not an e-mail, but on the other hand, it is not all the substrings of the form
-- , since boo @ goo and moo @ roo are missing.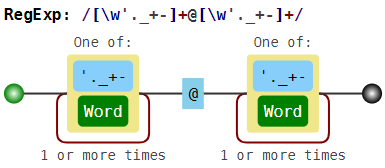
Sandbox Experiments
If you first come across regular expressions, it’s best to try the sandbox first. See how simple patterns and quantifiers work. Solve the following problems for this text (you may have to return to the part after the following theory):
- Find all natural numbers (possibly surrounded by letters);
- Find all the “words” written in caps (i.e., strictly capitalized), possibly inside real words (aaa BBB vvv);
- Find the words that have the Russian letter, and sometime the number behind it;
- Find all words beginning with a Russian or Latin capital letter (
\b- word boundary); - Find words that begin with a vowel (
\b- word boundary) ;; - Find all natural numbers that are not inside or on the boundary of the word;
- Find the lines that have a
*(.- this is definitely not the end of the line!); - Find the lines that have an opening and sometime then closing brackets;
- Highlight in one fell swoop the entire piece of the table of contents (at the end of the example, along with the tags);
- Highlight in one fell swoop only the text part of the table of contents, without tags;
- Find empty lines;
Regulars in python
Functions for working with regulars live in the re module. Main functions:
| Function | Its meaning |
|---|---|
re.search(pattern, string) | Find the first line in the string that matches the pattern ; |
re.fullmatch(pattern, string) | Check if the string is suitable for the pattern ; |
re.split(pattern, string, maxsplit=0) | Analog str.split() , only the division occurs by substrings that match the pattern ; |
re.findall(pattern, string) | Find all non-intersecting patterns in the string ; |
re.finditer(pattern, string) | Iterator to all non-intersecting patterns pattern in string ( match objects are issued); |
re.sub(pattern, repl, string, count=0) | Replace all non-intersecting patterns in the string with repl ; |
An example of using all the basic functions
import re match = re.search(r'\d\d\D\d\d', r' 123-12-12') print(match[0] if match else 'Not found') # -> 23-12 match = re.search(r'\d\d\D\d\d', r' 1231212') print(match[0] if match else 'Not found') # -> Not found match = re.fullmatch(r'\d\d\D\d\d', r'12-12') print('YES' if match else 'NO') # -> YES match = re.fullmatch(r'\d\d\D\d\d', r'. 12-12') print('YES' if match else 'NO') # -> NO print(re.split(r'\W+', ', , ??!')) # -> ['', '', '', '', '', ''] print(re.findall(r'\d\d\.\d\d\.\d{4}', r' 19.01.2018, 01.09.2017')) # -> ['19.01.2018', '01.09.2017'] for m in re.finditer(r'\d\d\.\d\d\.\d{4}', r' 19.01.2018, 01.09.2017'): print('', m[0], ' ', m.start()) # -> 19.01.2018 20 # -> 01.09.2017 45 print(re.sub(r'\d\d\.\d\d\.\d{4}', r'DD.MM.YYYY', r' 19.01.2018, 01.09.2017')) # -> DD.MM.YYYY, DD.MM.YYYY The subtleties of screening in python ( '\\\\\\\\foo' )
Since the \ character in Python lines must also be escaped, as a result, constructs of the form '\\\\par' may appear in the templates. The first slash means that the character following it must be left "as is". The third also. As a result, from the point of view of python, '\\\\' means just two slashes \\ . Now from the point of view of the regular expression engine, the first slash escapes the second. Thus, as a template for the regular '\\\\par' means simply the text \par . In order to avoid such a pile of slashes, before the opening quote you need to put the symbol r , which will tell the python "do not consider \ as a shielding character (except when the opening quotation is shielded)". Accordingly, it will be possible to write r'\\par' .
Using additional flags in python
Each of the functions listed above can be given an additional parameter
flags , which somewhat changes the mode of operation of the regularizers. As a value, you need to pass the sum of the selected constants, here they are:| Constant | Its meaning |
|---|---|
re.ASCII | By default, \w , \W , \b , \B , \d , \D , \s , \S correspondall unicode characters with appropriate quality. For example, \d not only Arabic numbers match,but these are: ٠١٢٣٤٥٦٧٨٩. re.ASCII speeds up workif all matches are inside ASCII. |
re.IGNORECASE | Do not distinguish between uppercase and lowercase letters. Slower, but sometimes convenient |
re.MULTILINE | Special characters ^ and $ matchthe beginning and end of each line |
re.DOTALL | By default, the \n end of line character does not fit the dot.With this flag, a dot is generally any character. |
import re print(re.findall(r'\d+', '12 + ٦٧')) # -> ['12', '٦٧'] print(re.findall(r'\w+', 'Hello, !')) # -> ['Hello', ''] print(re.findall(r'\d+', '12 + ٦٧', flags=re.ASCII)) # -> ['12'] print(re.findall(r'\w+', 'Hello, !', flags=re.ASCII)) # -> ['Hello'] print(re.findall(r'[]+', ' ')) # -> ['', ''] print(re.findall(r'[]+', ' ', flags=re.IGNORECASE)) # -> ['', '', '', ''] text = r""" 1 2 """ print(re.findall(r'.', text)) # -> [] print(re.findall(r'.', text, flags=re.DOTALL)) # -> ['\n'] print(re.findall(r'\w+', text, flags=re.MULTILINE)) # -> ['1', '2'] print(re.findall(r'^\w+', text, flags=re.MULTILINE)) # -> ['2'] Writing and Testing Regular Expressions
For writing and testing regular expressions, it is convenient to use the https://regex101.com service (do not forget to put the Python checkbox in the FLAVOR section on the left) or the Sublime text text editor 3 .
Tasks - 1
In Russia, several types of registration marks are used.
The common thing in them is that they consist of numbers and letters. Moreover, only 12 Cyrillic letters are used, having graphic analogs in the Latin alphabet - A, B, E, K, M, H, O, P, C, T, U and X.
In private cars, numbers are a letter, three numbers, two letters, then two or three numbers with a region code. A taxi has two letters, three digits, then two or three digits with a region code. There are also other species , but they will not be needed in this task.
You will need to determine whether the sequence of letters is the correct number of these two types, and if so, which one.
At the input are given the lines that claim to be a number. Determine the type of room. The letters in the numbers are capitalized Russians. Small and English for simplicity can be ignored.
| Input | Conclusion |
|---|---|
C227NA777 KU22777 T22B7477 M227K19U9 C227NA777 | Private Taxi Fail Fail Fail |
At the input is given the text, count how many words in it.
Ps. The problem is solved in one line. No tricky techs, not mentioned above, are required.
| Input | Conclusion |
|---|---|
He is a gray-brown-crimson radish !! >>>: -> And not a cat. www.kot.ru | 9 |
The valid e-mail address format is governed by RFC 5322.
In short, the e-mail consists of a single @ ( at-symbol or dog ), text to the dog ( Local part ) and text after the dog ( Domain part ). In general, any address may be in the address (in short, you can read about it in Wikipedia ). Quite strange things can be a valid address, for example:"very.(),:;<>[]\".VERY.\"very@\\ \"very\".unusual"@[IPv6:2001:db8::1]"()<>[]:,;@\\\"!#$%&'-/=?^_`{}| ~.a"@(comment)exa-mple
But the majority of postal services do not allow such hell and orgy. And we will not :)
We will consider only addresses whose name consists of no more than 64 Latin letters, numbers and symbols '._+- , and the domain consists of no more than 255 Latin letters, numbers and symbols .- . Neither Local-part, nor Domain part can begin or end on .+- , and there can be no more than one point in a row in the address.
By the way, it is useful to know that the part of the name after the + symbol is ignored, so you can use the synonyms of your address (for example, shshkv+spam@179.ru and shshkv+vk@179.ru ) in order to simplify your mail sorting. (True, not all sites allow the use of "+", alas)
At the entrance is given the text. It is necessary to display all e-mail addresses that are found in it. In general, the task is quite complicated, so we will have 3 limitations:
two points inside the address do not occur;
two dogs inside the address do not occur;
We believe that e-mail can be part of the “word”, that is, in boo@ya_ru we see the address boo@ya , and in foo№boo@ya.ru we see boo@ya.ru .
Ps. It is not necessary to do all checks only by regulars. Regular expressions are simply a tool that makes some of the tasks easy. No need to make them back difficult :)
| Input | Conclusion |
|---|---|
Ivan Ivanovich! Need a response to a letter from ivanoff@ivan-chai.ru. Do not forget to put in a copy serge'o-lupin@mail.ru- this is important. | ivanoff@ivan-chai.ru serge'o-lupin@mail.ru |
NO: foo. @ Ya.ru, foo @ .ya.ru PARTLY: boo @ ya_ru, -boo@ya.ru-, foo№boo@ya.ru | boo @ ya boo@ya.ru boo@ya.ru |
Bracket groups (?:...) and enumerations |
Enumerations (OR operation)
To check whether a string satisfies at least one of the patterns, you can use the analogue of the or operator, which is written using the symbol | . , A|B , A B . , |[]|| .
( )
. , MAC- , - : . , 01:23:45:67:89:ab . [0-9a-fA-F] , :[0-9a-fA-F]{2}[:-][0-9a-fA-F]{2}[:-][0-9a-fA-F]{2}[:-][0-9a-fA-F]{2}[:-][0-9a-fA-F]{2}[:-][0-9a-fA-F]{2}
, .(?:...) . ?: , , . . , REGEXP — , (?:REGEXP) — . , (?:REGEXP) , , . , MAC-, :[0-9a-fA-F]{2}(?:[:-][0-9a-fA-F]{2}){5}
(?:...) , . , (?:|) (?:|) « », « », « », « », | | | .
| Template | |
|---|---|
(?:\w\w\d\d)+ | 29 , 15 4. 2915 4 86 . |
(?:\w+\d+)+ | 29 , 154 . 2915486 . |
(?:\+7|8)(?:-\d{2,3}){4} | +7-926-123-12-12 , 8-926-123-12-12 |
(?:[][]+)+ | — , , ! . |
\b(?:[][]+)+\b | — , , ! . |
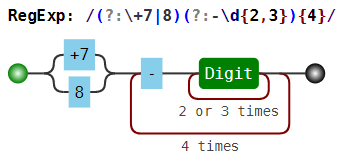
— 2
, .(TBD) . — HH:MM:SS HH:MM , HH — 00 23, MM SS — 00 59.
| Input | Conclusion |
|---|---|
! 09:00 , 09:00:01 . Ps. 25:50 ! | ! (TBD) , (TBD) . Ps. 25:50 ! |
Pascal requires that real constants have either a decimal point, or an exponent (starting with the letter e or E, and officially called a scale factor), or both, in addition to the usual collection of decimal digits. If a decimal point is included it must have at least one decimal digit on each side of it. As expected, a sign (+ or -) may precede the entire number, or the exponent, or both. Exponents may not include fractional digits. Blanks may precede or follow the real constant, but they may not be embedded within it. Note that the Pascal syntax rules for real constants make no assumptions about the range of real values, and neither does this problem. Your task in this problem is to identify legal Pascal real constants.
| Input | Conclusion |
|---|---|
1.2
one.
1.0e-55
e-12
6.5E
1e-12
+4.1234567890E-99999
7.6e+12.5
99
| 1.2 is legal. 1. is illegal. 1.0e-55 is legal. e-12 is illegal. 6.5E is illegal. 1e-12 is legal. +4.1234567890E-99999 is legal. 7.6e+12.5 is illegal. 99 is illegal. |
(...) match -
Match-
re.search , re.fullmatch , None , re.finditer . , match -. . , .
| Description | Example | |
|---|---|---|
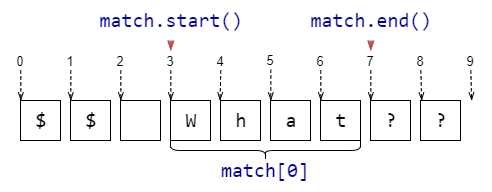
match[0] ,match.group() | , | match = re.search(r'\w+', r'$$ What??')match[0] # -> 'What' |
match.start() | , | match = re.search(r'\w+', r'$$ What??')match.start() # -> 3 |
match.end() | , | match = re.search(r'\w+', r'$$ What??')match.end() # -> 7 |
(...)
(...) ?: , . match-, re.search , re.fullmatch re.finditer , , . , (...) , . .
import re pattern = r'\s*([--]+)(\d+)\s*' string = r'--- 45 ---' match = re.search(pattern, string) print(f' >{match[0]}< {match.start(0)} {match.end(0)}') print(f' >{match[1]}< {match.start(1)} {match.end(1)}') print(f' >{match[2]}< {match.start(2)} {match.end(2)}') ### # -> > 45 < 3 16 # -> >< 6 11 # -> >45< 11 13 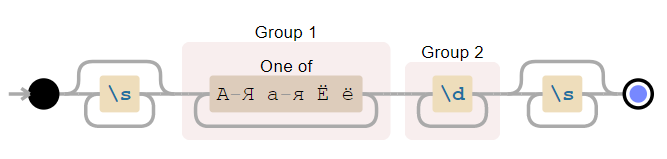
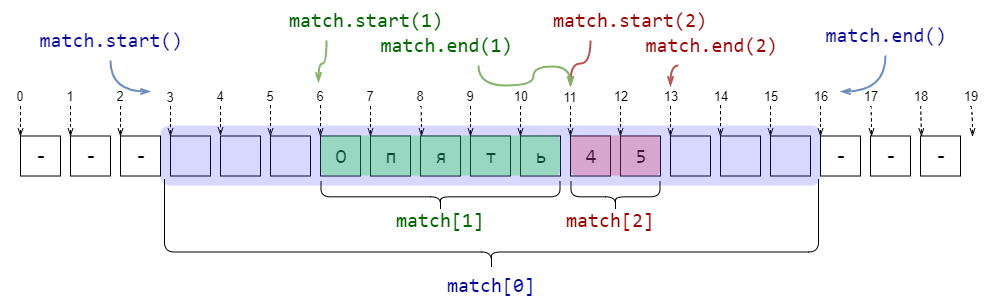
.
( ), match- . , '\s*([--])+(\d)+\s*' , :
# -> > 45 < 3 16 # -> >< 10 11 # -> >5< 12 13
. .
import re pattern = r'((\d)(\d))((\d)(\d))' string = r'123456789' match = re.search(pattern, string) print(f' >{match[0]}< {match.start(0)} {match.end(0)}') for i in range(1, 7): print(f' №{i} >{match[i]}< {match.start(i)} {match.end(i)}') ### # -> >1234< 0 4 # -> №1 >12< 0 2 # -> №2 >1< 0 1 # -> №3 >2< 1 2 # -> №4 >34< 2 4 # -> №5 >3< 2 3 # -> №6 >4< 3 4 re.findall
, , . , (?:...) .
import re print(re.findall(r'([az]+)(\d*)', r'foo3, im12, go, 24buz42')) # -> [('foo', '3'), ('im', '12'), ('go', ''), ('buz', '42')] re.split
, re.split str.split . , .
import re print(re.split(r'(\s*)([+*/-])(\s*)', r'12 + 13*15 - 6')) # -> ['12', ' ', '+', ' ', '13', '', '*', '', '15', ' ', '-', ' ', '6'] ! , , ! import re print(re.split(r'\s*([+*/-])\s*', r'12 + 13*15 - 6')) # -> ['12', '+', '13', '*', '15', '-', '6']
( re.sub , , ) : \1, \2, \3, ... . , // .., :
import re text = "We arrive on 03/25/2018. So you are welcome after 04/01/2018." print(re.sub(r'(\d\d)/(\d\d)/(\d{4})', r'\2.\1.\3', text)) # -> We arrive on 25.03.2018. So you are welcome after 01.04.2018.
9, \g<12> .
: re.sub , match- , . , . , «» , «»:
import re def repl(m): return '>censored(' + str(len(m[0])) + ')<' text = " : , , ." print(re.sub(r'\b[xX]\w*', repl, text)) # -> >censored(7)< : >censored(3)<, >censored(7)<, >censored(15)<. \1, \2, \3, ... \g<12> . , xml html.
, xml html ! . . , html , . « html, », . html , :) html . html xml : html xml , , .
import re text = "SPAM <foo>Here we can <boo>find</boo> something interesting</foo> SPAM" print(re.search(r'<(\w+?)>.*?</\1>', text)[0]) # -> <foo>Here we can <boo>find</boo> something interesting</foo> text = "SPAM <foo>Here we can <foo>find</foo> OH, NO MATCH HERE!</foo> SPAM" print(re.search(r'<(\w+?)>.*?</\1>', text)[0]) # -> <foo>Here we can <foo>find</foo> — 3
. , .
, ( ) . .
| Input | Conclusion |
|---|---|
12 410.37 . | 1728 68921000.50653 . |
— , (. , , , ), ( , « », : — «--»).
. . .
.
| Input | Conclusion |
|---|---|
,
|
— , XIV .
17 , . — — 5, 7 5 . , , .
, , . / . , 5/7/5 , «!». 3, « . 3 .» « . i s, j.», i — , .
, , , .
| Input | Conclusion |
|---|---|
| . / . / ... | ! |
| . 3 . | |
| ! / / -. | . 1 5, 6. |
| / … / ! | . 2 7, 8. |
| , , / , , / , ! | . 1 5, 6. |
| … / / . | ! |
, ,
, . , , «» .
,
, . ( ) .
| Template | Description | Example | |
|---|---|---|---|
^ | ,flag=re.MULTILINE | ^ | |
$ | ,flag=re.MULTILINE | !$ | |
\A | |||
\Z | |||
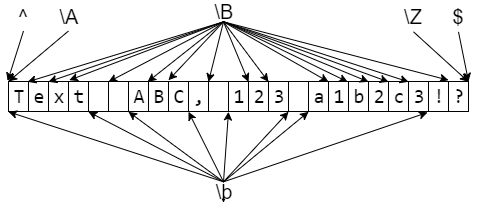
\b | ( -, ) | \b | , , |
\B | : , , , | \B | , , |
\B\B | , , |
, ( lookaround Co)
, , ,
match-.
| Template | Description | Example | |
|---|---|---|---|
(?=...) | lookahead assertion , , ... | Isaac (?=Asimov) | Isaac Asimov, Isaac other |
(?!...) | negative lookahead assertion , , ... | Isaac (?!Asimov) | Isaac Asimov, Isaac other |
(?<=...) | positive lookbehind assertion , , ... , abc a|b — , a* a{2,3} — . | (?<=abc)def | abc def , bcdef |
(?<!...) | negative lookbehind assertion , , ... | (?<!abc)def | abcdef, bc def |
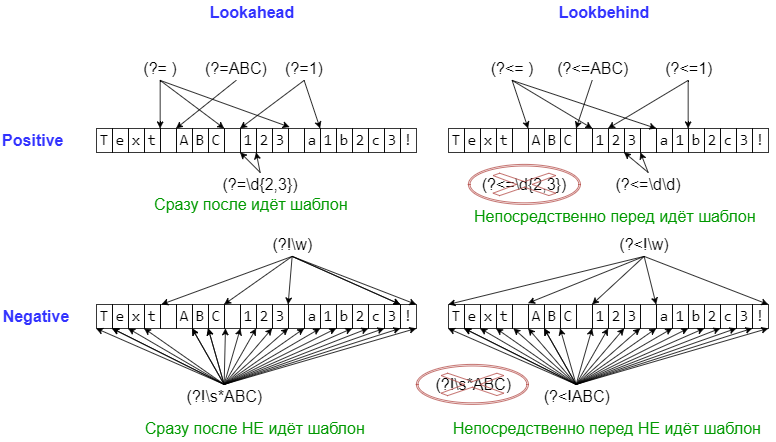
lookaround
(?=VI) — , VI
IV, IX, V, VI, VII, VIII,
IX, VI, VII, VIII, X, ..., XVIII,
I, II, III, IV, V, VI
(?!VI) — , VIIV, IX, V, VI, VII, VIII,
IX, VI, VII, VIII, X, ..., XVIII,
I, II, III, IV, V, VI
(?<=)VI — «»,IV, IX, V, VI, VII, VIII,
IX, VI , VI I, VI II, X, ..., XVIII,
I, II, III, IV, V, VI
(?<!)VI — «»,IV, IX, V, VI , VI I, VI II,
IX, VI, VII, VIII, X, ..., X VI II,
I, II, III, IV, V, VI
| Template | Comment | |
|---|---|---|
(?<!\d)\d(?!\d) | , - | Text ABC 123 A 1 B 2 C 3 ! |
(?<=#START#).*?(?=#END#) | #START# #END# | text from #START# till #END# |
\d+(?=_(?!_)) | , | 12 _34__56 |
^(?:(?!boo).)*?$ | , boo ( , boo) | a foo and boo and zoo and others |
^(?:(?!boo)(?!foo).)*?$ | , boo, foo | a foo and boo and zoo and others |

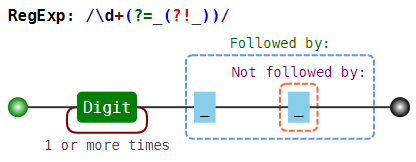
— 4
, «».
, , , (under_score). , « ».
, , , .
, , — , .
| Input | Conclusion |
|---|---|
MyVar17 = OtherVar + YetAnother2Var TheAnswerToLifeTheUniverseAndEverything = 42 | my_var17 = other_var + yet_another2_var the_answer_to_life_the_universe_and_everything = 42 |
— .
. (, , ).
| Input | Conclusion |
|---|---|
| — . , ? . | — . , ? . |
, _ ( \w ).
. , «», 5 , «».
| Input | Conclusion |
|---|---|
, ! | , |
, .
.
| Input | Conclusion |
|---|---|
12 123 1234 12354 123456 1234567 | 12 123 1,234 12,354 123,456 1,234,567 |
, :
- ;
.;!?;- ;
- ( « . . )».
, .
. .
| Input | Conclusion |
|---|---|
... ! ? , ! And this . | ...
!
?
, !
.
|
- , , 10 . - +7 , - 7 8 , . - , - , - ( ). - , - , - . — . , … !
, . +7 123 456-78-90 . - , Fail! .
| Input | Conclusion |
|---|---|
+7 123 456-78-90 | +7 123 456-78-90 |
8(123)456-78-90 | +7 123 456-78-90 |
7(123) 456-78-90 | +7 123 456-78-90 |
1234567890 | +7 123 456-78-90 |
123456789 | Fail! |
+9 123 456-78-90 | Fail! |
+7 123 456+78=90 | Fail! |
+7(123 45678-90 | +7 123 456-78-90 |
8(123 456-78-90 | Fail! |
.
!
. e-mail , . e-mail , e-mail' , - '._+- , .
| Input | Conclusion |
|---|---|
!
ivanoff@ivan-chai.ru.
serge'o-lupin@mail.ru- . | ivanoff@ivan-chai.ru serge'o-lupin@mail.ru |
NO: foo.@ya.ru, foo@.ya.ru, foo@foo@foo NO: +foo@ya.ru, foo@ya-ru NO: foo@ya_ru, -foo@ya.ru-, foo@ya.ru+ NO: foo..foo@ya.ru YES: (boo1@ya.ru), boo2@ya.ru!, boo3@ya.ru | boo1@ya.ru boo2@ya.ru boo3@ya.ru |
Post scriptum
Ps. , . , .
PSS. html -html . , , , ? :)
Source: https://habr.com/ru/post/349860/
All Articles