Natasha - a library for extracting structured information from texts in Russian
There is a standard task of extracting named entities from text ( NER ). At the input, text, output structured, normalized objects, for example, with names, addresses, dates:

The task is old and well studied, for English there are a lot of commercial and open solutions: Spacy , Stanford NER , OpenNLP , NLTK , MITIE , Google Natural Language API , ParallelDots , Aylien , Rosette , TextRazor . There are also good solutions for the Russian, but they are mostly closed: DaData , Pullenti , Abbyy Infoextractor , Dictum , Eureka , Promt , RCO , AOT , Ahunter . From the open, I know only Tomita-parser and fresh Deepmipt NER .
')
I do data analysis, word processing is one of the most frequent tasks. In practice, it turns out that, for example, to extract names from the Russian text is not at all easy. There is a ready-made solution in Tomita-parser , but there is inconvenient integration with Python. Recently there was a solution from the guys from iPavlov , but there the names do not lead to normal form. For extracting, for example, addresses (“8, Marta St., 4”, “Leninsky passage, 15”) I don’t know open solutions, there is a pypostal , but to parse the addresses, and not search for them in the text. With non-standard tasks such as extracting references to normative acts (“Art. 11 of the Civil Code of the Russian Federation”, “Clause 1, Art. 6 of the Law No. 122-FZ”), it is not at all clear what to do.
A year ago, Dima Veselov began the project Natasha . Since then, the code has been significantly improved. Natasha has been used in several large projects. Now we are ready to tell Habr users about it.
Now in Natasha there are rules for retrieving names, addresses, dates and amounts of money. There are also rules for names of organizations and geographical objects, but they are not of very high quality.
Using ready-made rules is simple:
In 2016, the factRuEval-2016 competition was held to retrieve named entities. Among the participants were large companies: ABBYY, RCO. In the top solutions, the F1-measure for names was 0.9+. Natasha's result is worse - 0.78 . The problem is mainly with foreign names and complex names, for example: "Haruki Murakami", "... the head of Afghanistan Hamid Karzai", "Ostap Bender meets Kisa Vorobyaninov ...". For texts with Russian names, the quality is ~ 0.95 . You can, for example, extract the names of teachers from school sites, aggregate reviews:
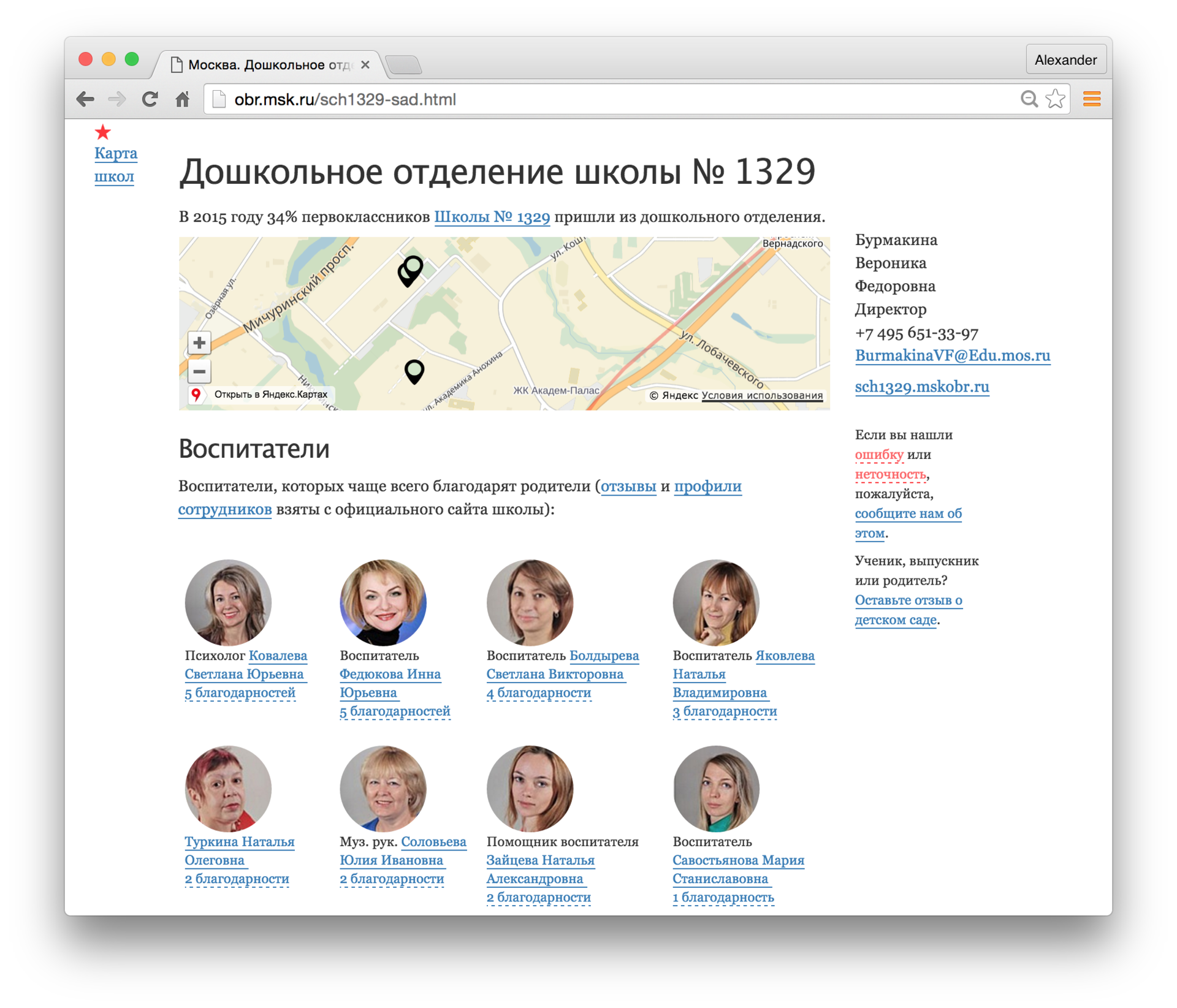
The interface is the same as for names, only
In factRuEval-2016, participants were asked to retrieve names, organizations, and geographical features. Independent test data for assessing the quality of work with addresses, as far as I know, does not exist. For several years of work we have accumulated hundreds of thousands of lines of the form “Address: 443041, Samara, ul. Leninskaya, d.168 ”,“ Address Irkutsk, ul. Baikal, d. 133, office 1 (entrance from the courtyard). ”. To assess the quality, a random sample of 1000 addresses was made, the results were checked manually, ~ 90% of the lines were processed correctly . Problems arise mainly with street names, for example: “ Volzhsk, 2nd Industrial, p. 2 ”,“ 111674, Moscow, Dmitrievskogo, d. 17 ”.
In 2017, in parallel with the history of reconstruction in Moscow, new Land Use and Development Rules (PZZ) were discussed. A survey of the population was conducted. More than 100,000 comments were made publicly available in the form of a huge pdf-file. Nikita Kuznetsov, with the help of Natasha, extracted the mentioned addresses and looked in which districts supported the law, and in which not:
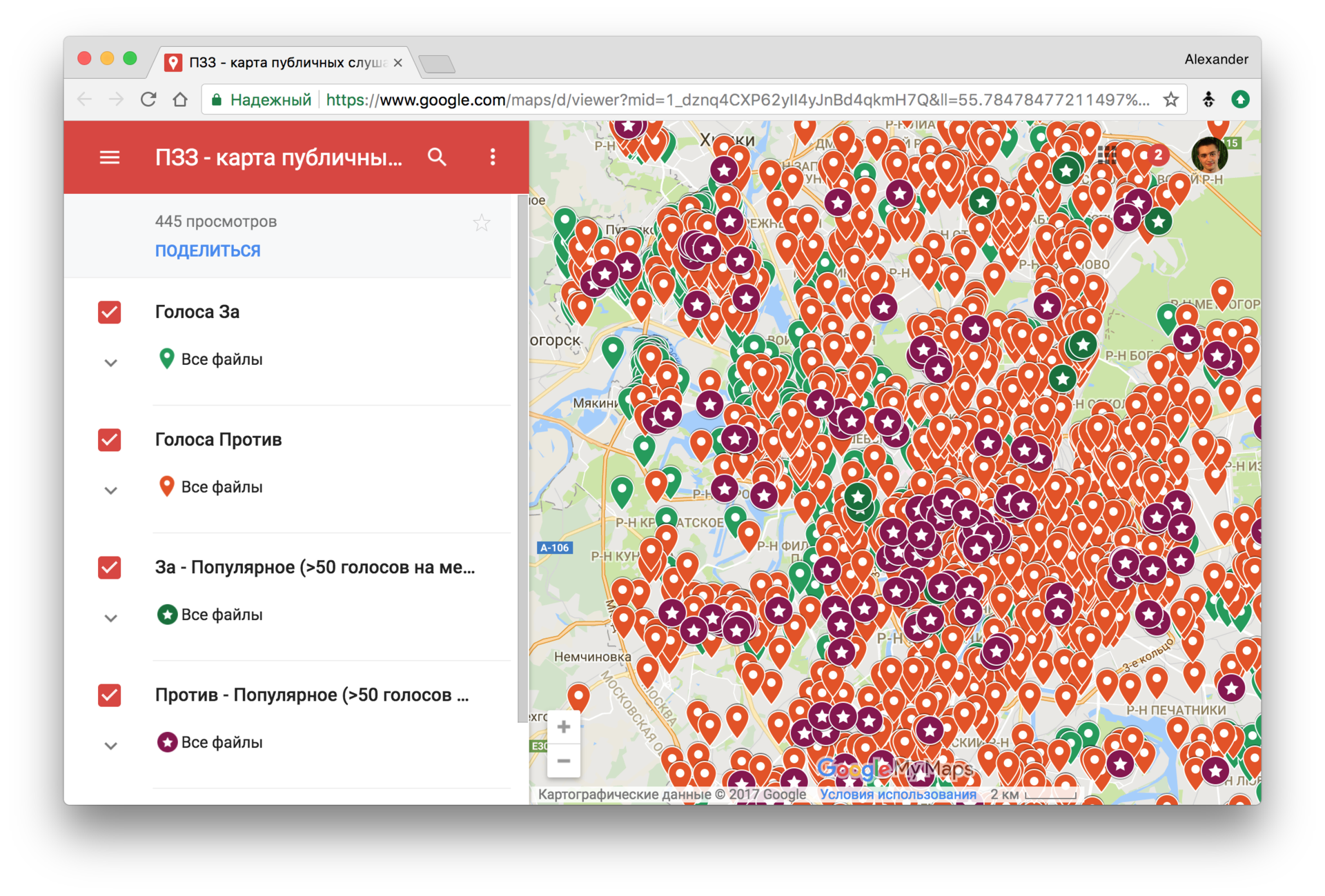
Visually assess the quality of the
There are also rules for dates and money in Natasha. The interface is the same as
Natasha's interface is very simple:
Often you have to go down to a lower level, add ready-made rules and write your own. For this uses Yargy-parser. All the rules in Natasha are written on it. Yargy is a complex and interesting library, in this article we will consider only simple examples of use.
Yargy-parser is an analogue of Yandex Tomita parser for Python. The rules for extracting entities are described using context-free grammars and dictionaries.
Grammar in Yargy are written on a special DSL . So, for example, a simple rule for extracting dates in ISO format (“2018-02-23”, “2015-12-31”) will look like:
While not very impressive, similar functionality can be obtained by the regularity
Finding a substring with a fact is usually not enough. For example, for the text “May 8 by order of President Vladimir Putin”, the parser should return not just “May 8th”, “Vladimir Putin”, but

(R0, R1 - technical vertices, “R” short for “Rule”)
For interpretation, the user “hangs” tagging on the tree nodes using the
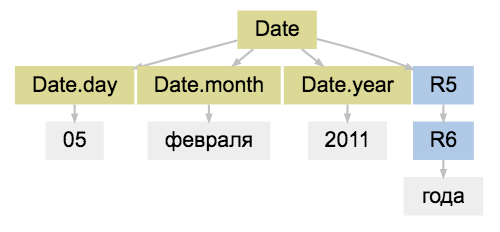
In the example with dates, you need to bring the names of the months, days and years to numbers; for this, the normalization procedure is built into Yargy. Inside
Hurray, we repeated a small piece of the dateparser library functionality . If you need to extract from the text, for example, only dates, then you should choose a ready-made specialized library. The solution will work faster, the quality will be higher. Yargy is needed for voluminous, non-standard tasks.
Consider a simple rule for retrieving names. The Opencorpora dictionary, which uses pymorphy2, is labeled
There are two problems with this solution:
1. The rule marks the name and surname in different cases (“Ivanova Lyosha”, “Petrova Roma”)
2. Female names become male after normalization
To solve these problems in Yargy there is a matching mechanism. Using the
Natasha provides solutions licensed under the MIT license, which were not previously available (or I don’t know about them). For example, previously it was impossible to simply take and extract structured names and addresses from a Russian-language text, but now it is possible. Earlier for Python there wasn’t something like a Tomita parser, now there is.
I will try to summarize the shortcomings:
The address of the project on Gitkhab is simple - github.com/natasha .
Installation -
The documentation for the standard rules package is short, the interface is very simple - natasha.readthedocs.io . The documentation for Yargy is more voluminous and complex - yargy.readthedocs.io . Yargy is an interesting and challenging tool, perhaps existing documentation will not be enough. There is a desire to publish on Habré a series of lessons on Yargy. You can write in the comments, what topics should be covered, for example:
Chat Natasha users - t.me/natural_language_processing . There you can try to ask questions about the library.
Stand to demonstrate the standard rules - natasha.imtqy.com/demo . You can enter your text, see how standard rules work out on it:

The task is old and well studied, for English there are a lot of commercial and open solutions: Spacy , Stanford NER , OpenNLP , NLTK , MITIE , Google Natural Language API , ParallelDots , Aylien , Rosette , TextRazor . There are also good solutions for the Russian, but they are mostly closed: DaData , Pullenti , Abbyy Infoextractor , Dictum , Eureka , Promt , RCO , AOT , Ahunter . From the open, I know only Tomita-parser and fresh Deepmipt NER .
')
I do data analysis, word processing is one of the most frequent tasks. In practice, it turns out that, for example, to extract names from the Russian text is not at all easy. There is a ready-made solution in Tomita-parser , but there is inconvenient integration with Python. Recently there was a solution from the guys from iPavlov , but there the names do not lead to normal form. For extracting, for example, addresses (“8, Marta St., 4”, “Leninsky passage, 15”) I don’t know open solutions, there is a pypostal , but to parse the addresses, and not search for them in the text. With non-standard tasks such as extracting references to normative acts (“Art. 11 of the Civil Code of the Russian Federation”, “Clause 1, Art. 6 of the Law No. 122-FZ”), it is not at all clear what to do.
A year ago, Dima Veselov began the project Natasha . Since then, the code has been significantly improved. Natasha has been used in several large projects. Now we are ready to tell Habr users about it.
Natasha is an analogue of Tomita-parser for Python ( Yargy-parser ) plus a set of ready-made rules for retrieving names, addresses, dates, amounts of money and other entities.The article shows how to use the ready-made rules of Natasha and, most importantly, how to add your own using the Yargy-parser.
Ready rules
Now in Natasha there are rules for retrieving names, addresses, dates and amounts of money. There are also rules for names of organizations and geographical objects, but they are not of very high quality.
Names
Using ready-made rules is simple:
from natasha import NamesExtractor from natasha.markup import show_markup, show_json extractor = NamesExtractor() text = ''' , , : . , . 1"" - , , - , , , ! ! ''' matches = extractor(text) spans = [_.span for _ in matches] facts = [_.fact.as_json for _ in matches] show_markup(text, spans) show_json(facts) >>> , , : [[ ]] [[ ]]. , . 1"" - [[ ]], , - [[ ]], , , ! ! [ { "first": "", "middle": "", "last": "" }, { "first": "", "middle": "", "last": "" }, { "first": "", "middle": "", "last": "" }, { "first": "", "middle": "" } ] In 2016, the factRuEval-2016 competition was held to retrieve named entities. Among the participants were large companies: ABBYY, RCO. In the top solutions, the F1-measure for names was 0.9+. Natasha's result is worse - 0.78 . The problem is mainly with foreign names and complex names, for example: "Haruki Murakami", "... the head of Afghanistan Hamid Karzai", "Ostap Bender meets Kisa Vorobyaninov ...". For texts with Russian names, the quality is ~ 0.95 . You can, for example, extract the names of teachers from school sites, aggregate reviews:
Addresses
The interface is the same as for names, only
NamesExtractor changed to AddressExtractor : from natasha import AddressExtractor from natasha.markup import show_markup, show_json extractor = AddressExtractor() text = ''' №71 2. .51 ( : , ) . 7 881 574-10-02 ,.,. , .8 , 4 ''' matches = extractor(text) spans = [_.span for _ in matches] facts = [_.fact.as_json for _ in matches] show_markup(text, spans) show_json(facts) >>> №71 [[ 2]]. [[ .51]] ( : , ) . 7 881 574-10-02 [[ ,.,. , .8 , 4]] [ { "parts": [ { "name": "", "type": "" }, { "number": "2" } ] }, { "parts": [ { "name": "", "type": "" }, { "number": "51", "type": "" } ] }, { "parts": [ { "name": "", "type": "" }, { "name": "", "type": "" }, { "name": " ", "type": "" }, { "number": "8 ", "type": "" }, { "number": "4", "type": "" } ] } ] In factRuEval-2016, participants were asked to retrieve names, organizations, and geographical features. Independent test data for assessing the quality of work with addresses, as far as I know, does not exist. For several years of work we have accumulated hundreds of thousands of lines of the form “Address: 443041, Samara, ul. Leninskaya, d.168 ”,“ Address Irkutsk, ul. Baikal, d. 133, office 1 (entrance from the courtyard). ”. To assess the quality, a random sample of 1000 addresses was made, the results were checked manually, ~ 90% of the lines were processed correctly . Problems arise mainly with street names, for example: “ Volzhsk, 2nd Industrial, p. 2 ”,“ 111674, Moscow, Dmitrievskogo, d. 17 ”.
In 2017, in parallel with the history of reconstruction in Moscow, new Land Use and Development Rules (PZZ) were discussed. A survey of the population was conducted. More than 100,000 comments were made publicly available in the form of a huge pdf-file. Nikita Kuznetsov, with the help of Natasha, extracted the mentioned addresses and looked in which districts supported the law, and in which not:
Visually assess the quality of the
AddressExtractor on the dataset with comments to the DSS can be in the repository with examples .Other rules
There are also rules for dates and money in Natasha. The interface is the same as
AddressExtractor and NamesExtractor . from natasha import ( NamesExtractor, AddressExtractor, DatesExtractor, MoneyExtractor ) from natasha.markup import show_markup, show_json extractors = [ NamesExtractor(), AddressExtractor(), DatesExtractor(), MoneyExtractor() ] text = ''' 10 1970 , -, . , 5/1 8 000 ( ) 00 ''' spans = [] facts = [] for extractor in extractors: matches = extractor(text) spans.extend(_.span for _ in matches) facts.extend(_.fact.as_json for _ in matches) show_markup(text, spans) show_json(facts) >>> [[ ]] [[10 1970 ]], [[ -, . , 5/1]][[]], 5/1 [[8 000 ( ) 00]] [ { "first": "", "middle": "", "last": "" }, { "last": "" }, { "parts": [ { "name": "-", "type": "" }, { "name": "", "type": "" }, { "number": "5/1", "type": "" } ] }, { "year": 1970, "month": 1, "day": 10 }, { "integer": 8000, "currency": "RUB", "coins": 0 } ] Natasha's interface is very simple:
e = Extractor(); r = e(text); ... e = Extractor(); r = e(text); ... e = Extractor(); r = e(text); ... User is not available any settings. In practice, getting by with ready-made rules is rarely obtained. For example, Natasha will not understand the date "April 21, 2017," because the rules do not include the day number in quotes. The library will not understand the address “Lyubertsy district, village Motyakovo, d. 61/2”, because there is no street name in it.Often you have to go down to a lower level, add ready-made rules and write your own. For this uses Yargy-parser. All the rules in Natasha are written on it. Yargy is a complex and interesting library, in this article we will consider only simple examples of use.
Yargy parser
Yargy-parser is an analogue of Yandex Tomita parser for Python. The rules for extracting entities are described using context-free grammars and dictionaries.
Grammar
Grammar in Yargy are written on a special DSL . So, for example, a simple rule for extracting dates in ISO format (“2018-02-23”, “2015-12-31”) will look like:
from yargy import rule, and_, Parser from yargy.predicates import gte, lte DAY = and_( gte(1), lte(31) ) MONTH = and_( gte(1), lte(12) ) YEAR = and_( gte(1), lte(2018) ) DATE = rule( YEAR, '-', MONTH, '-', DAY ) parser = Parser(DATE) text = ''' 2018-02-23, 2015-12-31; 8 916 364-12-01''' for match in parser.findall(text): print(match.span, [_.value for _ in match.tokens]) >>> [1, 11) ['2018', '-', '02', '-', '23'] >>> [13, 23) ['2015', '-', '12', '-', '31'] >>> [33, 42) ['364', '-', '12', '-', '01'] While not very impressive, similar functionality can be obtained by the regularity
r'\d\d\d\d-\d\d-\d\d' , although it will throw a nonsense like "1234-56-78".Predicates
gte and lte in the example above are predicates. Many ready-made predicates are built into the parser, there is an opportunity to add your own . Pymorphy2 is used to determine the morphology of words. For example, the predicate, gram('NOUN') works on nouns, normalized('') marks all forms of the word "January." Add rules for dates like "January 8, 2014", "June 15, 2001": from yargy import or_ from yargy.predicates import caseless, normalized, dictionary MONTHS = { '', '', '', '', '', '', '', '', '', '', '', '' } MONTH_NAME = dictionary(MONTHS) YEAR_WORDS = or_( rule(caseless(''), '.'), rule(normalized('')) ) DATE = or_( rule( YEAR, '-', MONTH, '-', DAY ), rule( DAY, MONTH_NAME, YEAR, YEAR_WORDS.optional() ) ) parser = Parser(DATE) text = ''' 8 2014 , 15 2001 ., 31 2018''' for match in parser.findall(text): print(match.span, [_.value for _ in match.tokens]) >>> [21, 36) ['15', '', '2001', '', '.'] >>> [1, 19) ['8', '', '2014', ''] >>> [38, 53) ['31', '', '2018'] Interpretation
Finding a substring with a fact is usually not enough. For example, for the text “May 8 by order of President Vladimir Putin”, the parser should return not just “May 8th”, “Vladimir Putin”, but
Date(month=5, day=8) , Name(first='', last='') , Yargy provides an interpretation procedure for this. The result of the parser is the parse tree: match = parser.match('05 2011 ') match.tree.as_dot (R0, R1 - technical vertices, “R” short for “Rule”)
For interpretation, the user “hangs” tagging on the tree nodes using the
.interpretation(...) method: from yargy.interpretation import fact Date = fact( 'Date', ['year', 'month', 'day'] ) DAY = and_( gte(1), lte(31) ).interpretation( Date.day ) MONTH = and_( gte(1), lte(12) ).interpretation( Date.month ) YEAR = and_( gte(1), lte(2018) ).interpretation( Date.year ) MONTH_NAME = dictionary( MONTHS ).interpretation( Date.month ) DATE = or_( rule(YEAR, '-', MONTH, '-', DAY), rule( DAY, MONTH_NAME, YEAR, YEAR_WORDS.optional() ) ).interpretation(Date) match = parser.match('05 2011 ') match.tree.as_dot parser = Parser(DATE) text = '''8 2014 , 2018-12-01''' for match in parser.findall(text): print(match.fact) >>> Date(year='2018', month='12', day='01') >>> Date(year='2014', month='', day='8') Normalization
In the example with dates, you need to bring the names of the months, days and years to numbers; for this, the normalization procedure is built into Yargy. Inside
.interpretation(...) user specifies how to normalize the fields: from datetime import date Date = fact( 'Date', ['year', 'month', 'day'] ) class Date(Date): @property def as_datetime(self): return date(self.year, self.month, self.day) MONTHS = { '': 1, '': 2, '': 3, '': 4, '': 5, '': 6, '': 7, '': 8, '': 9, '': 10, '': 11, '': 12 } DAY = and_( gte(1), lte(31) ).interpretation( Date.day.custom(int) ) MONTH = and_( gte(1), lte(12) ).interpretation( Date.month.custom(int) ) YEAR = and_( gte(1), lte(2018) ).interpretation( Date.year.custom(int) ) MONTH_NAME = dictionary( MONTHS ).interpretation( Date.month.normalized().custom(MONTHS.__getitem__) ) DATE = or_( rule(YEAR, '-', MONTH, '-', DAY), rule( DAY, MONTH_NAME, YEAR, YEAR_WORDS.optional() ) ).interpretation(Date) parser = Parser(DATE) text = '''8 2014 , 2018-12-01''' for match in parser.findall(text): record = match.fact print(record, repr(record.as_datetime)) >>> Date(year=2018, month=12, day=1) datetime.date(2018, 12, 1) >>> Date(year=2014, month=1, day=8) datetime.date(2014, 1, 8) match = parser.match('31 2014 .') match.fact.as_datetime >>> ValueError: day is out of range for month Hurray, we repeated a small piece of the dateparser library functionality . If you need to extract from the text, for example, only dates, then you should choose a ready-made specialized library. The solution will work faster, the quality will be higher. Yargy is needed for voluminous, non-standard tasks.
Matching
Consider a simple rule for retrieving names. The Opencorpora dictionary, which uses pymorphy2, is labeled
Name for names, Surn for names. Let's take the name as a couple of words Name Surn or Surn Name : from yargy.predicates import gram Name = fact( 'Name', ['first', 'last'] ) FIRST = gram('Name').interpretation( Name.first.inflected() ) LAST = gram('Surn').interpretation( Name.last.inflected() ) NAME = or_( rule( FIRST, LAST ), rule( LAST, FIRST ) ).interpretation( Name ) There are two problems with this solution:
1. The rule marks the name and surname in different cases (“Ivanova Lyosha”, “Petrova Roma”)
2. Female names become male after normalization
parser = Parser(NAME) text = ''' ... ... ... ... ''' for match in parser.findall(text): print(match.fact) >>> Name(first='', last='') >>> Name(first='', last='') >>> Name(first='', last='') To solve these problems in Yargy there is a matching mechanism. Using the
.match(...) method, the user specifies restrictions on the rules: from yargy.relations import gnc_relation gnc = gnc_relation() # gender, number case (, ) Name = fact( 'Name', ['first', 'last'] ) FIRST = gram('Name').interpretation( Name.first.inflected() ).match(gnc) LAST = gram('Surn').interpretation( Name.last.inflected() ).match(gnc) NAME = or_( rule( FIRST, LAST ), rule( LAST, FIRST ) ).interpretation( Name ) parser = Parser(NAME) text = ''' ... ... ... ... ''' for match in parser.findall(text): print(match.fact) >>> Name(first='', last='') >>> Name(first='', last='') Advantages and disadvantages
Natasha provides solutions licensed under the MIT license, which were not previously available (or I don’t know about them). For example, previously it was impossible to simply take and extract structured names and addresses from a Russian-language text, but now it is possible. Earlier for Python there wasn’t something like a Tomita parser, now there is.
I will try to summarize the shortcomings:
- Manually compiled rules.
Natasha examines only those phrases for which the rules were drawn up in advance. It may seem unrealistic to write rules, for example, for names in arbitrary text, they are too different. In practice, everything is not so bad:- If you sit for a week, you can still make up rules for 80% of names.
- Usually you need to work not with arbitrary texts, but with texts in a controlled natural language : summary, court decisions, regulations, a section of the site with contacts.
- In the rules for the Yargy-parser, you can use markup obtained by machine learning methods.
- Slow work speed.
Let's start with the fact that Yargy implements the Earley parser algorithm, its complexity isO(n 3 ), wherenis the number of tokens. The code is written on pure Python, with an emphasis on readability, not optimization. In short, the library is slow. For example, on the task of extracting names, Natasha is 10 times slower than Tomita-parser . In practice, you can live with it:- PyPy helps well. There is an acceleration of 10 times, on average, ~ 3-4 times.
- Running in multiple threads on multiple machines. The task is well parallel, the cars for rent are now easily accessible.
- Errors in standard rules.
For example, the quality of extracting names from Natasha is very far from SOTA . In practice, the library does not always show good quality out of the box, you need to refine the rules for yourself.
We hope the community will help improve the accuracy and completeness of the rules. Write bugreports , send pullrequests .
Links
The address of the project on Gitkhab is simple - github.com/natasha .
Installation -
pip install natasha . The library is tested on Python 2.7, 3.3, 3.4, 3.5, 3.6, PyPy and PyPy3.The documentation for the standard rules package is short, the interface is very simple - natasha.readthedocs.io . The documentation for Yargy is more voluminous and complex - yargy.readthedocs.io . Yargy is an interesting and challenging tool, perhaps existing documentation will not be enough. There is a desire to publish on Habré a series of lessons on Yargy. You can write in the comments, what topics should be covered, for example:
- Execution speed, processing large volumes of text;
- Manual rules and machine learning, hybrid solutions;
- Examples of the use of the library in different areas: summary analysis, parsing of product names, chat bots.
Chat Natasha users - t.me/natural_language_processing . There you can try to ask questions about the library.
Stand to demonstrate the standard rules - natasha.imtqy.com/demo . You can enter your text, see how standard rules work out on it:
Source: https://habr.com/ru/post/349864/
All Articles