Arguments for function tree
In this article we will talk about writing good code and the problems that we face. Understandable, declarative, composable, and testable — these terms are used when it comes to writing good code. Solving problems is often called pure functions. But writing web applications is mainly related to side effects and complex asynchronous workflows, concepts that are not inherently clean. The following describes an approach that allows you to cover work with side effects and complex asynchronous flows, while retaining the benefits of pure functions.
Good code writing
Pure functions - the holy grail of writing good code. A pure function is a function that, with the same arguments, always returns the same values and has no visible side effects.
function add(numA, numB) { return numA + numB } A useful feature of pure functions is that they are easy to test.
test.equals(add(2, 2), 4) Composability is also their strength.
test.equals(multiply(add(4, 4), 2), 16) In addition, they are very easy to use declaratively.
const totalPoints = users .map(takePoints) .reduce(sum, 0) But let's take a look at your application. What part of it can really be expressed by pure functions? How often is it about converting values that traditionally perform pure functions? I can assume that most of your code works with side effects. You perform network requests, DOM manipulations, use web-sites, local storage, change the state of the application, and so on. This all describes the development of the application, at least on the Internet.
Side effects
As a rule, we are talking about side effects, in this case:
function getUsers() { return axios.get('/users') .then(response => ({users: response.data})) } The getUsers function points to something "outside itself" - axios . The return value does not always match, as this is the server response. However, we can still use this function declaratively and put it together in many different chains:
doSomething() .then(getUsers) .then(doSomethingElse) But testing will be difficult for us, since axios is out of our control. Rewrite the function so that it axios as an argument:
function getUsers(axios) { return axios.get('/users') .then(response => ({users: response.data})) } Now it is easy to test:
const users = ['userA', 'userB'] const axiosMock = Promise.resolve({data: users}) getUsers(axiosMock).then(result => { assert.deepEqual(result, {users: users}) }) But we will have problems linking the function to different chains, since axios must be explicitly passed to the input.
doSomething() // axios .then(getUsers) // .then(doSomethingElse) Functions that work with side effects are actually problematic.
A popular tip in projects like Elm , Cycle , and implementations in redux (redux-loop) : "slide side effects to the edge of your application." This basically means that the business logic of your application is kept clean. Whenever you need to produce a side effect, you must separate it. The problem with this approach is probably that it does not help improve readability. You cannot express a holistically complex workflow. Your application will have several unrelated cycles that hide the relationship of one side effect, which may cause another side effect, and so on. It does not matter for simple applications, because you rarely deal with more than one additional cycle. But in large applications, in the end, you will encounter a large number of cycles, and it will be difficult to understand how they relate to each other.
Let me explain this in more detail with examples.
Typical application flow
Let's say you have an application. When it gets started, you want to get user data to check if the user is logged in or not. Then you want to get a list of tasks. They are associated with other users. Therefore, based on the received list of tasks, you need to dynamically obtain information about these users too. What are we going to do to describe this workflow in a clear, declarative, composable, and testable form?
Consider a simple implementation using redux :
function loadData() { return (dispatch, getState) => { dispatch({ type: AUTHENTICATING }) axios.get('/user') .then((response) => { if (response.data) { dispatch({ type: AUTHENTICATION_SUCCESS, user: response.data }) dispatch({ type: ASSIGNMENTS_LOADING }) return axios.get('/assignments') .then((response) => { dispatch({ type: ASSIGNMENTS_LOADED_SUCCESS, assignments: response.data }) const missingUsers = response.data.reduce((currentMissingUsers, assignment) => { if (!getState().users[assigment.userId]) { return currentMissingUsers.concat(assignment.userId) } return currentMissingUsers }, []) dispatch({ type: USERS_LOADING, users: users }) return Promise.all( missingUsers.map((userId) => { return axios.get('/users/' + userId) }) ) .then((responses) => { const users = responses.map(response => response.data) dispatch({ type: USERS_LOADED, users: users }) }) }) .catch((error) => { dispatch({ type: ASSIGNMENTS_LOADED_ERROR, error: error.response.data }) }) } else { dispatch({ type: AUTHENTICATION_ERROR }) } }) .catch(() => { dispatch({ type: LOAD_DATA_ERROR }) }) } } Everything is just wrong here. This code is incomprehensible, non-declarative, uncomplicated and not tested. However, there is one advantage. Everything that happens when the loadData function is called is defined as it is executed, orderly and in one file.
If we separate the side effects "to the edge of the application", it will look more like a demonstration of some parts of the stream:
function loadData() { return (dispatch, getState) => { dispatch({ type: AUTHENTICATING_LOAD_DATA }) } } function loadDataAuthenticated() { return (dispatch, getState) { axios.get('/user') .then((response) => { if (response.data) { dispatch({ type: AUTHENTICATION_SUCCESS, user: response.data }) } else { dispatch({ type: AUTHENTICATION_ERROR }) } }) } } function getAssignments() { return (dispatch, getState) { dispatch({ type: ASSIGNMENTS_LOADING }) axios.get('/assignments') .then((response) => { dispatch({ type: ASSIGNMENTS_LOADED_SUCCESS, assignments: response.data }) }) .catch((error) => { dispatch({ type: ASSIGNMENTS_LOADED_ERROR, error: error.response.data }) }) } } Each part reads better than the previous example. And they are easier to link into other chains. However, fragmentation becomes a problem. It is difficult to understand how these parts are related to each other, because you cannot see which functions lead to a call to another function. Moving between files, we have to recreate in our head as sending (dispatch) one action (action) generates a side effect, which causes sending a new action, generating another side effect, which, in turn, again leads to sending a new action.
By bringing side effects to the edge of your application, you really get the benefits. But it also has a negative effect: it becomes harder to talk about flow. About this, of course, it is possible and even necessary to argue. I hope I was able to convey my point of view through the examples and arguments above.
Towards declarativeness
Imagine that we can describe this stream as follows:
[ dispatch(AUTHENTICATING), authenticateUser, { error: [ dispatch(AUTHENTICATED_ERROR) ], success: [ dispatch(AUTHENTICATED_SUCCESS), dispatch(ASSIGNMENTS_LOADING), getAssignments, { error: [ dispatch(ASSIGNMENTS_LOADED_ERROR) ], success: [ dispatch(ASSIGNMENTS_LOADED_SUCCESS), dispatch(MISSING_USERS_LOADING), getMissingUsers, { error: [ dispatch(MISSING_USERS_LOADED_ERROR) ], success: [ dispatch(MISSING_USERS_LOADED_SUCCESS) ] } ] } ] } ] Please note that this is a valid code, which we will now examine in more detail. And also, that we do not use any magic API here, it’s just arrays, objects and functions. But most importantly, we took full advantage of the declarative form of writing code to create a consistent and readable description of a complex application flow.
Function tree
We have just defined (declared) the function tree. As I mentioned, we did not use any special APIs to define it. These are just functions defined in the tree ..., in the function tree. Any of the functions used here, as well as function factories (dispatch) can be reused in any other tree definition. This shows the simplicity of the composition . Not only each function can be in other trees. You can include whole trees in other trees, which makes them particularly interesting in terms of composition.
[ dispatch(AUTHENTICATING), authenticateUser, { error: [ dispatch(AUTHENTICATED_ERROR) ], success: [ dispatch(AUTHENTICATED_SUCCESS), ...getAssignments ] } ] In this example, we created a new tree, getAssignments , which is also an array. We can compose one tree into another using the spread operator.
Let's take a look at how function trees work before moving on to testability . Let's run it!
Execution of the function tree
A compressed example of how to run a function tree is as follows:
import FunctionTree from 'function-tree' const execute = new FunctionTree() function foo() {} execute([ foo ]) The created instance of FunctionTree is a function that allows you to execute trees. In the example above, the function foo will be executed. If we add more functions, they will be executed in order:
function foo() { // } function bar() { // } execute([ foo, bar ]) Asynchrony
function-tree can work with promises (promises). When a function returns a promise, or you define a function as asynchronous, using the async , the execute function will wait until the promise is fulfilled (resolve) or rejected before moving on.
function foo() { return new Promise(resolve => { setTimeout(resolve, 1000) }) } function bar() { // 1 } execute([ foo, bar ]) Often, asynchronous code has more varied results. We examine the context of the function tree in order to understand how these results can be defined declaratively.
Context
All functions performed using function-tree take one argument. context is the only argument with which functions defined in the tree should work. By default, the context has two properties: input and path .
The input property contains the payload (load), transmitted at the start of the tree.
// function foo({input}) { input.foo // "bar" } execute([ foo ], { foo: 'bar' }) When a function wants to transfer a new payload down the tree, it will need to return an object that will be merged with the current payload.
function foo({input}) { input.foo // "bar" return { foo2: 'bar2' } } function bar({input}) { input.foo // "bar" input.foo2 // "bar2" } execute([ foo, bar ], { foo: 'bar' }) It does not matter whether a synchronous function or asynchronous, you just have to return the object or the fulfilled promise with the object.
// function foo() { return { foo: 'bar' } } // function foo() { return new Promise(resolve => { resolve({ foo: 'bar' }) }) } Let us turn to the study of the mechanism for choosing the paths for implementation.
Paths
The result returned from the function can determine the further execution path in the tree. Thanks to static analysis, the path property of the context already knows which paths can be continued. This means that only execution paths that are defined in the tree are available.
function foo({path}) { return path.pathA() } function bar() { // } execute([ foo, { pathA: [ bar ], pathB: [] } ]) You can pass the payload by passing the object to the path method.
function foo({path}) { return path.pathA({foo: 'foo'}) } function bar({input}) { console.log(input.foo) // 'foo' } execute([ foo, { pathA: [ bar ], pathB: [] } ]) What is the good mechanism of the ways? First of all, it is declarative. There are no if or switch expressions. This improves readability.
More importantly, paths do not deal with throwing errors. Often flows are thought of as: "do it or drop everything if an error occurs." But not the case with web applications. There are many reasons why you decide to go down the various execution paths. The solution may be based on the user's role, the server response returned, some state of the application, the value transferred, and so on. The fact is that the function-tree does not catch errors, does not make mistakes, and similar techniques. It simply performs the functions and allows them to return the paths where the execution should diverge.
There are a few small hidden features. For example, you can define a function tree without implementing anything. This means that all possible execution paths are defined in advance. It makes you think about which cases need to be handled. And it greatly reduces the likelihood that you will ignore or forget about scenarios that may occur.
Providers
You cannot build a complex application on input and path alone. Therefore, the function-tree built on the concept of providers . In fact, input and path also providers. The set of function-tree comes with several ready-made ones. And of course you can create them yourself. Suppose you want to use Redux:
import FunctionTree from 'function-tree' import ReduxProvider from 'function-tree/providers/Redux' import store from './store' const execute = new FunctionTree([ ReduxProvider(store) ]) export default execute Now you have access to the dispatch and getState methods in your functions:
function doSomething({dispatch, getState}) { dispatch({ type: SOME_CONSTANT }) getState() // {} } You can add any other tools using ContextProvider :
import FunctionTree from 'function-tree' import ReduxProvider from 'function-tree/providers/Redux' import ContextProvider from 'function-tree/providers/Context' import axios from 'axios' import store from './store' const execute = new FunctionTree([ ReduxProvider(store), ContextProvider({ axios }) ]) export default execute You will most likely want to use DebuggerProvider . In conjunction with the extension for Google Chrome, you can debug your current work. Add a debugger provider to the example above:
import FunctionTree from 'function-tree' import DebuggerProvider from 'function-tree/providers/Debugger' import ReduxProvider from 'function-tree/providers/Redux' import ContextProvider from 'function-tree/providers/Context' import axios from 'axios' import store from './store' const execute = new FunctionTree([ DebuggerProvider(), ReduxProvider(store), ContextProvider({ axios }) ]) export default execute This allows you to see everything that happens when you run these trees in your application. The debugger provider will automatically wrap up and track everything that you put in context:
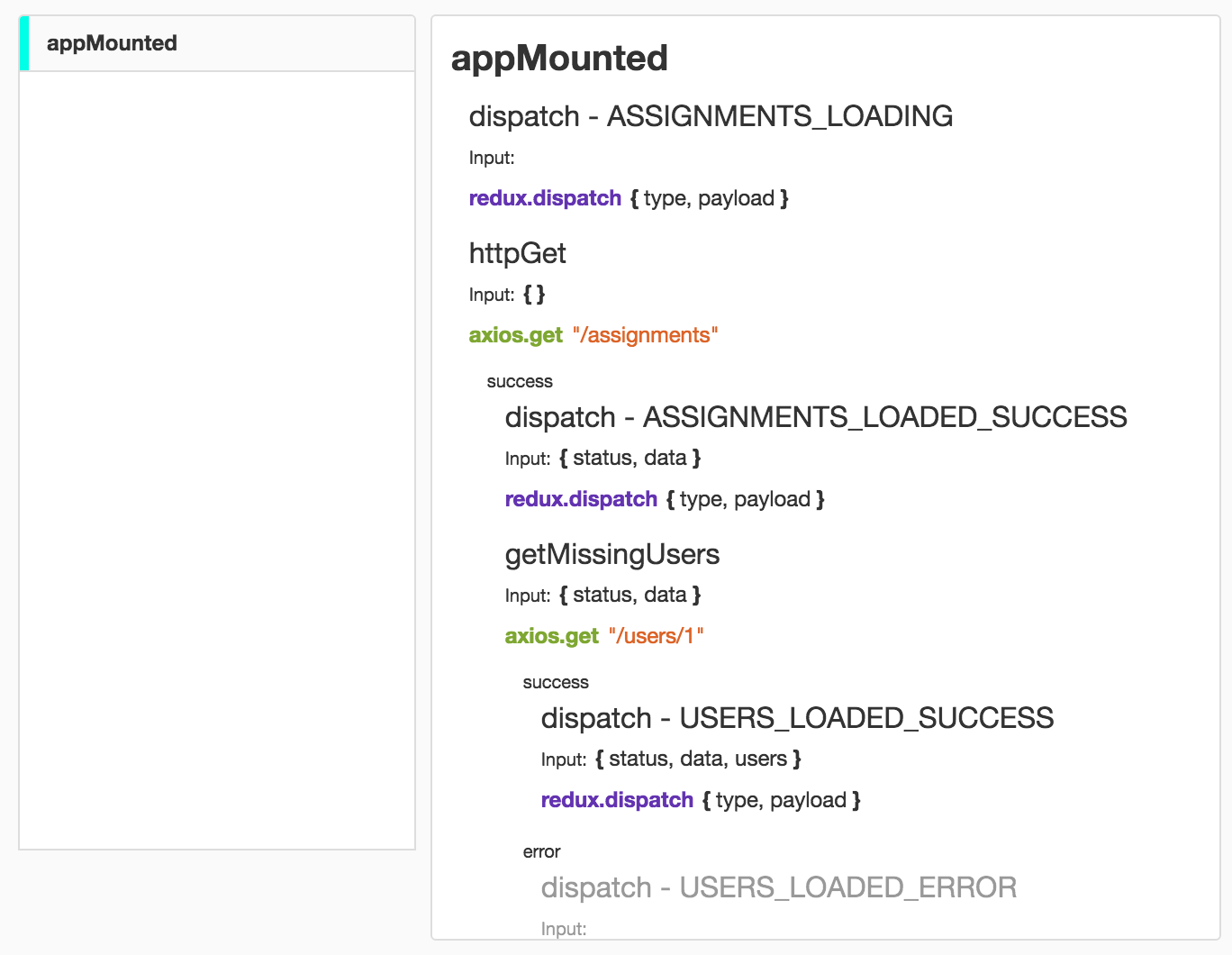
If you decide to use function-tree on the server side, you can connect NodeDebuggerProvider :
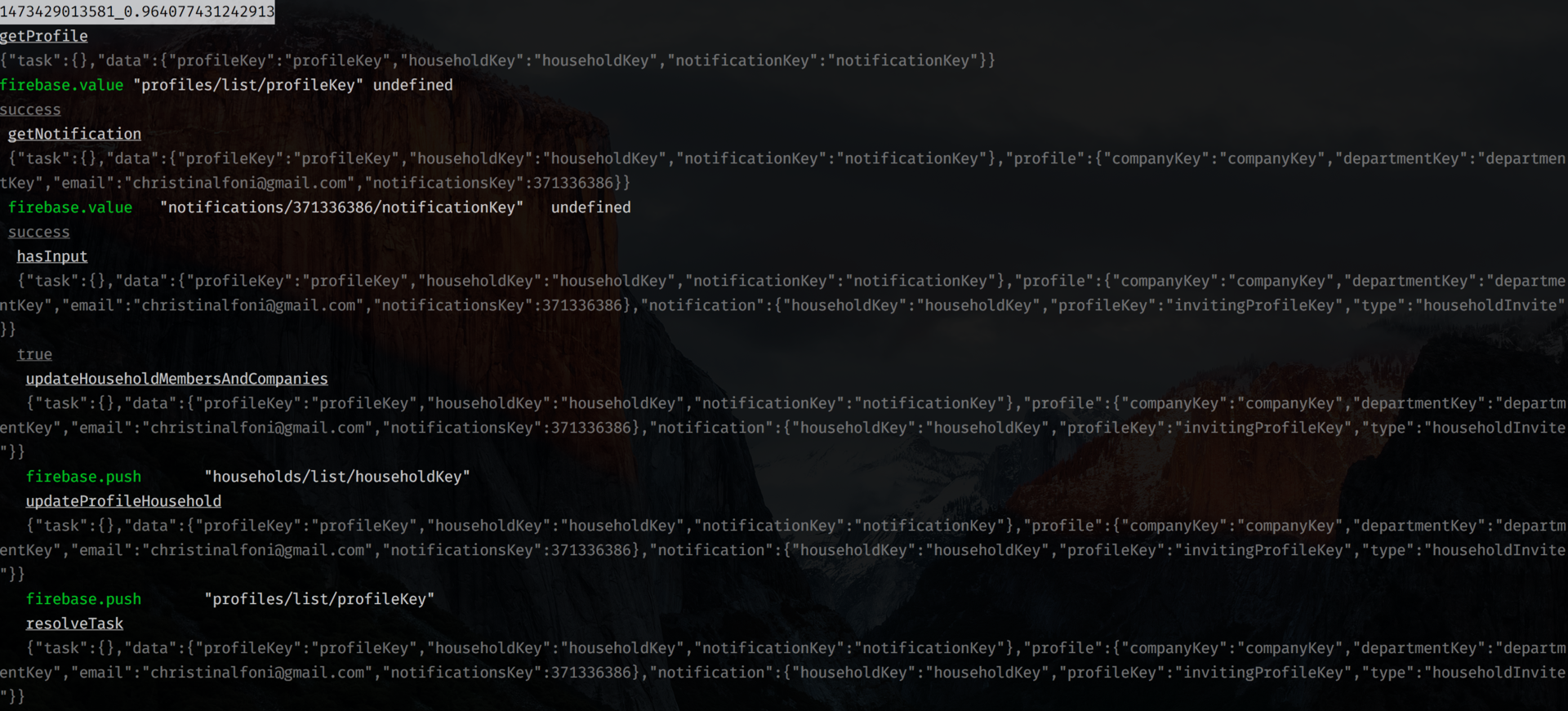
Testability
But, most likely the most important thing is the ability to check the function tree. As it turns out, it is very easy to do. To test individual functions in the tree, simply call them with a specially prepared context. Consider testing the function that creates a side effect:
function setData({window, input}) { window.app.data = input.result } const context = { input: {result: 'foo'}, window: { app: {}} } setData(context) test.deepEqual(context.window, {app: {data: 'foo'}}) Asynchronous Function Testing
Many testing libraries allow you to create stubs for global dependencies. But there is no reason to do this for function-tree , because functions use only what is available through the context argument. For example, the following function, using axios to get data, can be tested as follows:
function getData({axios, path}) { return axios.get('/data') .then(response => path.success({data: response.data})) .catch(error => path.error({error: error.response.data})) } const context = { axios: { get: Promise.resolve({ data: {foo: 'bar'} }) } } getData(context) .then((result) => { test.equal(result.path, 'success') test.deepEqual(result.payload, {data: {foo: 'bar'}}) }) Testing the whole tree
Here it gets even more interesting. We can test the whole tree in the same way as we tested the functions separately.
Let's imagine a simple tree:
[ getData, { success: [ setData ], error: [ setError ] } ] These functions use axios to get data, and then store them in a property of the window object. We will test the tree by creating a new execution function with stubs for passing to context. Then we run the tree and check the changes after the end of execution.
const FunctionTree = require('function-tree') const ContextProvider = require('function-tree/providers/Context') const loadData = require('../src/trees/loadData') const context = { window: {app: {}}, axios: { get: Promise.resolve({data: {foo: 'bar'}}) } } const execute = new FunctionTree([ ContextProvider(context) ]) execute(loadData, () => { test.deepEquals(context.window, {app: {data: 'foo'}}) }) It does not matter which libraries you use. You can easily test function trees while you are placing libraries in the context of a tree.
Factories
Since the tree is functional, you can create factories that will speed up your development. You have already seen the use of the dispatch factory in the Redux example. She was declared as follows:
function dispatchFactory(type) { function dispatchFunction({input, dispatch}) { dispatch({ type, payload: input }) } // `displayName` , // . dispatchFunction.displayName = `dispatch - ${type}` return dispatchFunction } export default dispatchFactory Create factories for your application to avoid creating specific functions for everything. Suppose you decide to use baobab , a single state tree, to store the state of your application.
function setFactory(path, value) { function set({baobab}) { baobab.set(path.split('.'), value) } return set } export default set This factory will allow you to express state changes right in the tree:
[ set('foo', 'bar'), set('admin.isLoading', true) ] You can use factories to build your application's own DSL . Some factories are so generalized that we decided to make them part of the function-tree .
debounce
The debounce factory allows you to keep running for a specified time. If new performances of the same tree are triggered, the existing one will go along the path discarded . If during the specified time there are no new positives, the latter will follow the path accepted . Typically, this approach is used when searching as you type.
import debounce from 'function-tree/factories/debounce' export default [ updateSearchQuery, debounce(500), { accepted: [ getData, { success: [ setData, ], error: [ setError ] } ], discarded: [] } ] What is the difference from Rxjs and promise chains?
Both Rxjs and Promises control the execution control. But none of them has a declarative conditional definition of the ways of execution. You will have to push threads, write if and switch expressions, or throw errors. In the examples above, we were able to separate the execution paths of success and error as declaratively as our functions. This improves readability. But these paths can be absolutely any. For example:
[ withUserRole, { admin: [], superuser: [], user: [] } ] Paths have nothing to do with error handling. function-tree allows you to choose a path at any step of execution, unlike promises and Rxjs, where throwing errors is the only way to stop executing the current path.
Rxjs and promises are based on value conversion. This means that the next function is only available values transmitted as a result of the previous one. This works great when you really need to convert values. But the events in your application are not the case. They work with side effects and go through one or many ways of performing. This is the main difference function-tree .
Where can I apply?
A function tree can help if you create an application that works with side effects in complex asynchronous chains. The advantages of the "forced" splitting of your application logic into "lego" blocks and their testability can be quite weighty reasons. This basically allows you to write more readable and supported code.
The project is available in the repository on Github , and the debugger extension for Google Chrome can be found in the Chrome Web Store . Be sure to look at the sample application in the repository .
The primary source of the function-tree project can be considered cerebral . You can consider the implementation of signals in Cerebral an abstraction with your own representation over function-tree . Currently, Cerebral uses its own implementation, but in Cerebral 2.0, the function-tree will be used as the basis for the signal factory. I thank Alexey Guria for processing and honing the ideas of Cerebral signals, which led to the creation of an independent and common approach.
Tell us what you think about this approach in the comments below. Share if you have links to other patterns and methods for solving the problems discussed in this article. Thanks for reading!
')
Source: https://habr.com/ru/post/309930/
All Articles