Introduction to CQRS + Event Sourcing: Part 1. Basics
The first time I heard about CQRS when I got a new job. In the company where I work to this day, I was immediately told that on the project I’m going to work on, CQRS, Event Sourcing, and MongoDB are used as a database. From all this I heard only about MongoDB. Having tried to penetrate into CQRS, I did not immediately understand all the subtleties of this approach, but for some reason I liked the idea of dividing the model of interaction with data into two - read and write. Perhaps because it somehow echoed the “separation of duties” programming paradigm, perhaps because it was very much in the spirit of DDD.
In general, many people speak of CQRS as a design pattern. In my opinion, it too strongly influences the overall architecture of the application, which would simply be called a “design pattern”, so I prefer to call it a principle or approach. Using CQRS penetrates almost all corners of the application.
I just want to clarify that I only worked with a bunch of CQRS + Event Sourcing, and I never tried CQRS, because it seems to me that without Event Sourcing it loses a lot of benefits. As a CQRS framework, I will use our corporate Paralect.Domain. He is better than others than worse. In any case, I advise you to familiarize yourself with the rest. I will mention here only a few frameworks for .NET. The most popular are NCQRS , Lokad CQRS , SimpleCQRS . You can also look at the Event Store Jonathan Oliver with the support of a huge number of different databases.
')
What is CQRS?
CQRS stands for Command Query Responsibility Segregation (division of responsibility into teams and requests). This is a design pattern I first heard about from Greg Young. It is based on a simple concept that you can use different models for updating and reading information. However, this simple concept leads to serious consequences in the design of information systems. (c) Martin Fowler
Not to say that an exhaustive definition, but now I will try to explain what exactly Fowler had in mind.
To date, there is such a situation that almost everyone works with the data model as a CRUD repository. CQRS offers an alternative approach, but not only affects the data model. If you use CQRS, then this is strongly reflected in the architecture of your application.
Here is how I portrayed the CQRS workflow
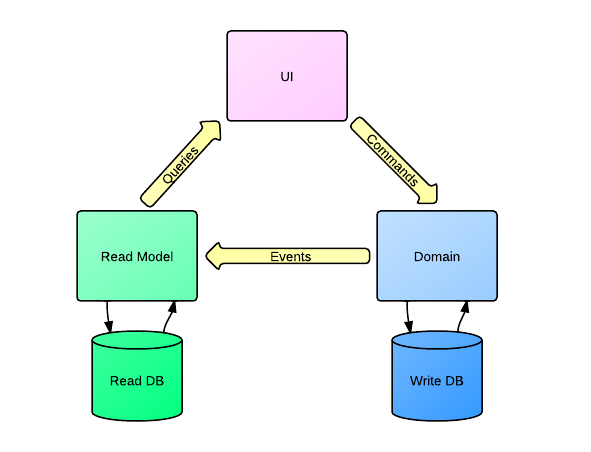
The first thing that catches your eye is that you already have two data models, one for reading (Queries), one for recording (Commands). And it usually means that you also have two databases. And since we use CQRS + Event Sourcing, the write-base (write-model) is the Event Store, something like a log of all user actions (in fact, not all, but only those that are important from the point of view of the business model and affect the construction of the read-base). A read database is generally a denormalized storage of the data you need to display to the user. Why did I say that the read-database is denormalized? Of course, you can use any data structure as a read-model, but I think that when using CQRS + Event Sourcing, you should not bother much about normalizing the read-base, since it can be completely rebuilt at any time. And this is a big plus, especially if you do not want to use relational databases and look towards NoSQL.
Write-base generally represents one collection of events. That is, there is also no point in using a relational database.
The idea of event sourcing is to record every event that changes the state of the application to the database. Thus, it turns out that we do not store the state of our entities, but all the events that relate to them. However, we are used to manipulating the state, it is stored in our database and we can always see it.
In the case of Event Sourcing, we also operate on the state of the entity. But unlike the usual model, we do not store this state, but reproduce it every time we call it.
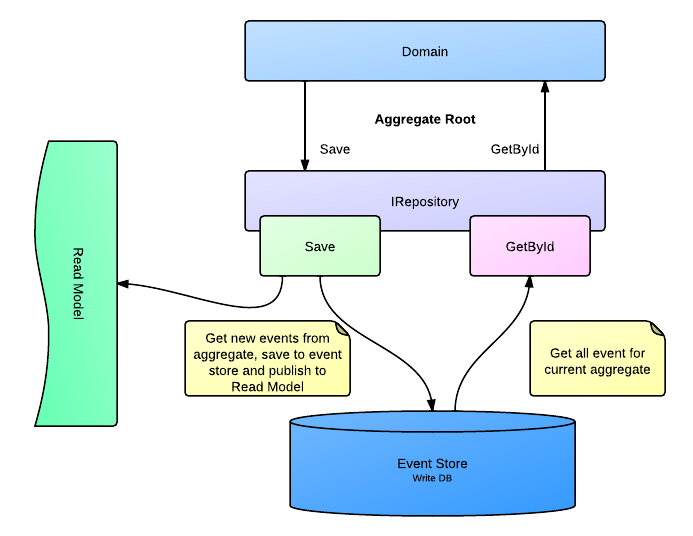
If you look at the code that raises the unit from the base, you may not notice any difference with the traditional approach.
In fact, the repository does not take from the database the ready state of the UserAR aggregate (AR = Aggregate Root), it selects from the database all the events associated with this user, and then reproduces them in order by transferring to the On () method of the aggregate.
For example, the UserAR aggregate class must have the following method in order to restore its ID to the state of the user
From the whole state of the unit, I need only _id user, so I could restore the state of the password, name, etc. However, these fields can be modified by other events, not only User_CreatedEvent, respectively, I will need to process them all. Since all events are reproduced in order, I am sure that I always work with the latest actual state of the aggregate, if I of course wrote On () handlers for all events that change this state.
Let's look at the example of creating a user how CQRS + Event Sourcing works.
The first thing I do is form and send a command. For simplicity, let the user creation command have only the most necessary set of fields and look like this.
Do not be confused by the name of the class of the team, it does not correspond to the generally accepted guidelines, but allows you to immediately understand to which unit it belongs, and what action is performed.
Then I need a handler for this command. The command handler must pass the ID of the desired aggregate; by this ID it will receive the aggregate from the repository. The repository builds an aggregate object as follows: it takes from the database all the events that relate to this aggregate, creates a new empty aggregate object, and in order reproduces the received events at the aggregate object.
But since we have creation teams, there is nothing to lift from the base, which means we create the aggregate ourselves and pass the command metadata to it.
Let's see how the constructor looks like.
The aggregate must also have a constructor without parameters, because when the repository reproduces the state of the aggregate, it must first create an instance path and then send events to the projection methods (the On (User_CreatedEvent created method ) is one of the projection methods).
I will clarify a bit about the projection. Projection is a reproduction of the state of the aggregate, based on events from the Event Store, which relate to this aggregate. In the user example, these are all events for that particular user. And the aggregate all the same events that are saved via the Apply method can be processed during the playback of its state. In our framework, it's enough to write the On method (/ * EventType arg * /), where EventType is the type of event you want to handle.
The Apply method of the aggregate initiates sending events to all handlers. In fact, events will be sent only when the aggregate is saved to the repository, and Apply simply adds them to the internal aggregate list.
Here is the event handler (!) Of creating a user who writes the user’s own database to read.
An event can have multiple handlers. This architecture helps to preserve the integrity of the data, if your data is strongly denormalized. Suppose I need to frequently show the total number of users. But I have too many of them and the count operation for all of them is very expensive for my database. Then I can write another event handler, which will already be related to statistics and each time a user is added, the total user counter will increase by 1. And I will be sure that no one will create a user without updating the counter. If I didn’t use CQRS, and I’d have a regular ORM, I would have to monitor in each place where the user is added and removed so that the counter is updated.
And using Event Sourcing gives me additional steps. Even if I made a mistake in some kind of EventHandler or didn’t handle the event wherever I need it, I can easily fix it by reproducing the read database with the correct business logic.
With creation it is clear. How is the change of the unit and the validation of the team? Consider an example of changing the password.
I will only give the command handler and the ChangePassword () aggregate method, since in other places the difference is generally not large.
I want to note that it is not very desirable for an invalid event to be passed to the Apply () method. Of course, you can process it later in the event handler, but it's better not to save it at all if it doesn't matter to you, as this will only clog up the Event Store.
In the case of a password change, there is no sense at all to save this event, unless of course you are collecting statistics on unsuccessful password changes. And even in this case, you should carefully consider whether you are knocking this event in the write model or it makes sense to write it in some tempo storage. If you assume that the business logic of event validation may change, then save it.
That's all I wanted to tell you in this article. Of course, she does not disclose all aspects and possibilities of CQRS + Event Sourcing, I plan to tell about this in the next articles. The problems that arise when using this approach are also left behind the scenes. And we'll talk about that too.
If you have any questions, ask them in the comments. With joy I will answer them. Also, if there are any suggestions on the following articles - I really want to hear them.
A fully working example on ASP.NET MVC is here .
There is no database there, everything is stored in memory. If desired, simply screw it. There is also a ready-made implementation of the Event Store on MongoDB for storing events out of the box.
To screw it in the Global.asax file, replace the InMemoryTransitionRepository with MongoTransitionRepository.
As a read model, I have a static collection, so that with each restart, the data is destroyed.
I have a few ideas for articles on this topic. Offer more. Say the most interesting.
In general, many people speak of CQRS as a design pattern. In my opinion, it too strongly influences the overall architecture of the application, which would simply be called a “design pattern”, so I prefer to call it a principle or approach. Using CQRS penetrates almost all corners of the application.
I just want to clarify that I only worked with a bunch of CQRS + Event Sourcing, and I never tried CQRS, because it seems to me that without Event Sourcing it loses a lot of benefits. As a CQRS framework, I will use our corporate Paralect.Domain. He is better than others than worse. In any case, I advise you to familiarize yourself with the rest. I will mention here only a few frameworks for .NET. The most popular are NCQRS , Lokad CQRS , SimpleCQRS . You can also look at the Event Store Jonathan Oliver with the support of a huge number of different databases.
')
Let's start with CQRS
What is CQRS?
CQRS stands for Command Query Responsibility Segregation (division of responsibility into teams and requests). This is a design pattern I first heard about from Greg Young. It is based on a simple concept that you can use different models for updating and reading information. However, this simple concept leads to serious consequences in the design of information systems. (c) Martin Fowler
Not to say that an exhaustive definition, but now I will try to explain what exactly Fowler had in mind.
To date, there is such a situation that almost everyone works with the data model as a CRUD repository. CQRS offers an alternative approach, but not only affects the data model. If you use CQRS, then this is strongly reflected in the architecture of your application.
Here is how I portrayed the CQRS workflow
The first thing that catches your eye is that you already have two data models, one for reading (Queries), one for recording (Commands). And it usually means that you also have two databases. And since we use CQRS + Event Sourcing, the write-base (write-model) is the Event Store, something like a log of all user actions (in fact, not all, but only those that are important from the point of view of the business model and affect the construction of the read-base). A read database is generally a denormalized storage of the data you need to display to the user. Why did I say that the read-database is denormalized? Of course, you can use any data structure as a read-model, but I think that when using CQRS + Event Sourcing, you should not bother much about normalizing the read-base, since it can be completely rebuilt at any time. And this is a big plus, especially if you do not want to use relational databases and look towards NoSQL.
Write-base generally represents one collection of events. That is, there is also no point in using a relational database.
Event sourcing
The idea of event sourcing is to record every event that changes the state of the application to the database. Thus, it turns out that we do not store the state of our entities, but all the events that relate to them. However, we are used to manipulating the state, it is stored in our database and we can always see it.
In the case of Event Sourcing, we also operate on the state of the entity. But unlike the usual model, we do not store this state, but reproduce it every time we call it.
If you look at the code that raises the unit from the base, you may not notice any difference with the traditional approach.
var user = Repository.Get<UserAR>(userId); In fact, the repository does not take from the database the ready state of the UserAR aggregate (AR = Aggregate Root), it selects from the database all the events associated with this user, and then reproduces them in order by transferring to the On () method of the aggregate.
For example, the UserAR aggregate class must have the following method in order to restore its ID to the state of the user
protected void On(User_CreatedEvent created) { _id = created.UserId; } From the whole state of the unit, I need only _id user, so I could restore the state of the password, name, etc. However, these fields can be modified by other events, not only User_CreatedEvent, respectively, I will need to process them all. Since all events are reproduced in order, I am sure that I always work with the latest actual state of the aggregate, if I of course wrote On () handlers for all events that change this state.
Let's look at the example of creating a user how CQRS + Event Sourcing works.
Creating and sending a team
The first thing I do is form and send a command. For simplicity, let the user creation command have only the most necessary set of fields and look like this.
public class User_CreateCommand: Command { public string UserId { get; set; } public string Password { get; set; } public string Email { get; set; } } Do not be confused by the name of the class of the team, it does not correspond to the generally accepted guidelines, but allows you to immediately understand to which unit it belongs, and what action is performed.
var command = new User_CreateCommand { UserId = “1”, Password = “password”, Email = “test@test.com”, }; command.Metadata.UserId = command.UserId; _commandService.Send(command); Then I need a handler for this command. The command handler must pass the ID of the desired aggregate; by this ID it will receive the aggregate from the repository. The repository builds an aggregate object as follows: it takes from the database all the events that relate to this aggregate, creates a new empty aggregate object, and in order reproduces the received events at the aggregate object.
But since we have creation teams, there is nothing to lift from the base, which means we create the aggregate ourselves and pass the command metadata to it.
public class User_CreateCommandHandler: CommandHandler<User_CreateCommand> { public override void Handle(User_CreateCommand message) { var ar = new UserAR(message.UserId, message.Email, message.Password, message.Metadata); Repository.Save(ar); } } Let's see how the constructor looks like.
public UserAR(string userId, string email, string password, ICommandMetadata metadata): this() { _id = userId; SetCommandMetadata(metadata); Apply(new User_CreatedEvent { UserId = userId, Password = password, Email = email }); } The aggregate must also have a constructor without parameters, because when the repository reproduces the state of the aggregate, it must first create an instance path and then send events to the projection methods (the On (User_CreatedEvent created method ) is one of the projection methods).
I will clarify a bit about the projection. Projection is a reproduction of the state of the aggregate, based on events from the Event Store, which relate to this aggregate. In the user example, these are all events for that particular user. And the aggregate all the same events that are saved via the Apply method can be processed during the playback of its state. In our framework, it's enough to write the On method (/ * EventType arg * /), where EventType is the type of event you want to handle.
The Apply method of the aggregate initiates sending events to all handlers. In fact, events will be sent only when the aggregate is saved to the repository, and Apply simply adds them to the internal aggregate list.
Here is the event handler (!) Of creating a user who writes the user’s own database to read.
public void Handle(User_CreatedEvent message) { var doc = new UserDocument { Id = message.UserId, Email = message.Email, Password = message.Password }; _users.Save(doc); } An event can have multiple handlers. This architecture helps to preserve the integrity of the data, if your data is strongly denormalized. Suppose I need to frequently show the total number of users. But I have too many of them and the count operation for all of them is very expensive for my database. Then I can write another event handler, which will already be related to statistics and each time a user is added, the total user counter will increase by 1. And I will be sure that no one will create a user without updating the counter. If I didn’t use CQRS, and I’d have a regular ORM, I would have to monitor in each place where the user is added and removed so that the counter is updated.
And using Event Sourcing gives me additional steps. Even if I made a mistake in some kind of EventHandler or didn’t handle the event wherever I need it, I can easily fix it by reproducing the read database with the correct business logic.
With creation it is clear. How is the change of the unit and the validation of the team? Consider an example of changing the password.
I will only give the command handler and the ChangePassword () aggregate method, since in other places the difference is generally not large.
Command handler
public class User_ChangePasswordCommandHandler: IMessageHandler<User_ChangePasswordCommand> { // public void Handle(User_ChangePasswordCommand message) { // var user = _repository.GetById<UserAR>(message.UserId); // user.SetCommandMetadata(message.Metadata); // user.ChangePassword(message.OldPassword, message.NewPassword); // _repository.Save(user); } } Aggregate Root
public class UserAR : BaseAR { //... public void ChangePassword(string oldPassword, string newPassword) { // , if (_password != oldPassword) { throw new AuthenticationException(); } // - Apply(new User_Password_ChangedEvent { UserId = _id, NewPassword = newPassword, OldPassword = oldPassword }); } // protected void On(User_Password_ChangedEvent passwordChanged) { _password = passwordChanged.NewPassword; } // protected void On(User_CreatedEvent created) { _id = created.UserId; _password = created.Password; } } } I want to note that it is not very desirable for an invalid event to be passed to the Apply () method. Of course, you can process it later in the event handler, but it's better not to save it at all if it doesn't matter to you, as this will only clog up the Event Store.
In the case of a password change, there is no sense at all to save this event, unless of course you are collecting statistics on unsuccessful password changes. And even in this case, you should carefully consider whether you are knocking this event in the write model or it makes sense to write it in some tempo storage. If you assume that the business logic of event validation may change, then save it.
That's all I wanted to tell you in this article. Of course, she does not disclose all aspects and possibilities of CQRS + Event Sourcing, I plan to tell about this in the next articles. The problems that arise when using this approach are also left behind the scenes. And we'll talk about that too.
If you have any questions, ask them in the comments. With joy I will answer them. Also, if there are any suggestions on the following articles - I really want to hear them.
Sources
A fully working example on ASP.NET MVC is here .
There is no database there, everything is stored in memory. If desired, simply screw it. There is also a ready-made implementation of the Event Store on MongoDB for storing events out of the box.
To screw it in the Global.asax file, replace the InMemoryTransitionRepository with MongoTransitionRepository.
As a read model, I have a static collection, so that with each restart, the data is destroyed.
What's next?
I have a few ideas for articles on this topic. Offer more. Say the most interesting.
- What are snapshots, why do we need, details and options for implementation.
- Event Store.
- Regeneration database. Opportunities. Problems, performance. Parallelization. Patches.
- Aggregate Root Design
- Application on real projects. One project is outsourced, the second is my startup.
- Features integration of third-party services.
Source: https://habr.com/ru/post/146429/
All Articles