For those who need to analyze C ++ code in an IT startup
The article describes the open and free VivaCore library, which allows parsing and analyzing C / C ++ code. The library can be useful for developers starting their own startups in the field of creating such tools as building code documentation, specific language extensions, counting metrics, and so on.
As part of the blog company Intel, I want to support the creation of "complex" IT startups. It is more interesting for me to hear and discuss such topics. Perhaps, over time, the ISN platform will become exactly the place where the discussion and the emergence of new startups in the field of parallel programming, the creation of their own libraries and other technologies of this kind will begin. And maybe at Habrahabare there will be fewer posts about the achievements of foreign companies and about cuts in ours, and there will be more interesting articles about his own experience, about who does what and how he does it.
Immediately clearly define the place of the library VivaCore . VivaCore library was created on the basis of another open library OpenC ++ , which has not been developed for many years [1]. VivaCore is a set of patches, fixes, crutches, supports and backings, which allowed the OpenC ++ library to parse the source code compiled by Visual C ++ 8.0, 9.0, 10.0. That is, to support specific extensions, as well as new constructions that appeared in C ++ 0x and implemented in Visual C ++ 10.0 [2].
VivaCore is not a full-fledged library. We develop VivaCore as a mechanism on which we create static code analyzers included in PVS-Studio . That is, VivaCore is this part of the PVS-Studio project that we decided to make open in order to enable others to use the improved and expanded version of OpenC ++.
')
VivaCore has a lot of flaws. It is not fully possible to analyze some sample constructs, there is no documentation, it is impossible to work with Unicode code, and so on. If you need full support for parsing and analyzing the C / C ++ language, or you plan to create your own compiler / development environment, the VivaCore library will not suit you. In this case, you should use professional libraries, for example - EDG . The price of a license for such a library ranges from $ 40,000 to $ 250,000 per year. This price is too high for many start-up projects that are not ready for such investments, without confidence in the success of the project. In this case, the VivaCore library can be a good compromise. It is free, and although not ideal, it allows you to work with C / C ++ at a fairly good level. This level will be sufficient for most code tools.
It should be mentioned that it is possible to try to build your project based on GCC source codes or other open systems. These options will also have both strengths and weaknesses. Something will be easier to implement, something more difficult. Legal aspects also make their own adjustments. I just want to talk about the library VivaCore, and research, comparison and choice is provided to the reader.
If you are still interested in the VivaCore library, then this article will allow you to get to know it better and tell you about possible areas of its application. The archive with source code (project for VS2010) is available for download here: http://www.viva64.com/ru/vivacore-library/ . From time to time we update it. I just want to ask in advance not to overwhelm me with various questions about working with VivaCore, if this is related to training. If you have a full-fledged project, then of course I will try to suggest or we can conclude an agreement on the implementation of the required functionality. I want to insure against the influx of students' questions, which occurs 2 times a year, when they are given assignments for coursework / diplomas related to the creation of parsers and the like. :)
Before proceeding, briefly give a definition of some terms.
Preprocessing is a mechanism that looks at the input ".c / .cpp" file, which executes the preprocessor directives in it, which includes the contents of other files specified in #include directives and so on. The result is a file that does not contain preprocessor directives, all macros used are expanded, instead of #include directives the contents of the corresponding files are substituted. The file with the result of preprocessing usually has the suffix ".i". The result of preprocessing is called a translation unit.
Parsing is the process of analyzing the input sequence of characters, with the purpose of parsing the grammatical structure. Usually parsing is divided into two levels: lexical analysis and grammatical analysis.
Lexical analysis is the process of processing the input sequence of characters in order to obtain at the output a sequence of characters called lexemes (or "tokens"). Each lexeme can be conventionally represented as a structure containing the type of the lexeme and, if necessary, the corresponding value. For C ++, the lexemes are “class”, “int”, “-”, “{” and so on.
Grammar analysis (grammatical analysis) is the process of comparing a linear sequence of lexemes (words) of a language with its formal grammar. The result is usually a parse tree or an abstract syntax tree.
An abstract syntax tree (Abstract Syntax Tree - AST) is a finite, labeled, oriented tree, in which internal vertices are associated with operators of a programming language, and leaves with corresponding operands. Thus, the leaves are empty operators and represent only variables and constants. An abstract syntax tree is different from a derivation tree (derivation tree - DT or parse tree - PT) in that there are no nodes for those syntax rules that do not affect the semantics of the program. A classic example of this absence is grouping brackets, since in AST the grouping of operands is explicitly defined by the tree structure.
Metaprogramming is the creation of programs that create other programs as a result of their work, or that change or supplement themselves during execution [3]. In metaprogramming, two main directions can be distinguished: code generation and self-modifying code. Next, we will consider metaprogramming as generation of C / C ++ source code.
Traversing the syntactic tree - traversing all the vertices and leaves of the syntactic tree in order to collect information of various kinds, analysis or modification.
The VivaCore library is an open source project built on the basis of the older library - OpenC ++ (OpenCxx). The VivaCore library is implemented in C ++ and is a project intended for compilation in Visual Studio 2010. However, no specific extension of the Visual C ++ compiler is used and the project after a little adaptation can be assembled with another modern compiler.
The VivaCore library was created and is being developed by the employees of Program Verification Systems LLC. The library of code analysis VivaCore has a certificate of state registration of computer programs N 2008610480.
You can freely and free use the VivaCore library. The only license restriction is the need to indicate that your project was developed on the basis of OpenC ++ libraries and its extension - VivaCore.
First of all, the VivaCore library may be interesting for small companies (start-ups) that create or plan to create tools for working with code. Of course, it’s not possible to list all the valid areas and methods of application, but I’ll still name a number of areas to show VivaCore from different angles. Examples of products related to this class of solutions are indicated in parentheses as explanations. So, with the help of VivaCore it is possible to develop:
The main difference of the VivaCore library from OpenC ++ is that it is a live project and continues to actively increase its functionality. The OpenC ++ library, unfortunately, has not been developed for a long time. The most recent library change dates back to 2004. And the latest change related to the support of new keywords dates back to 2003. This fix is an unsuccessful attempt to add the wchar_t data type, which introduced five errors of a different type.
Let us list the new key functionalities implemented in the VivaCore library in comparison with OpenC ++:
The overall functional structure of the VivaCore library is shown in Figure 1.

Figure 1. The general structure of the VivaCore library.
Consider the functional blocks of the library in the order in which they process the source text of the program received at the input, as shown in Figure 2. Consider what actions each functional block performs, what information it allows to receive and how it can be modified for specific purposes.
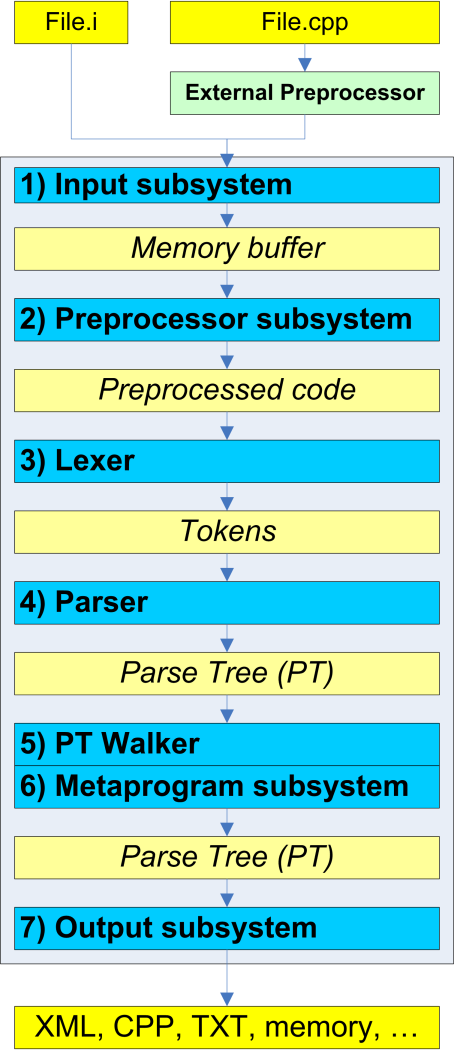
Figure 2 - Sequence of processing code.
The VivaCore library can correctly use only the original C / C ++ code previously processed by the preprocessor. Currently, the Visual C ++ compiler is used to generate preprocessed files in PVS-Studio. After it works, it turns out the processed file with the extension “i”, with which VivaCore works.
In certain cases, you can submit raw C / C ++ files to the input, but in this case, working with VivaCore should be no further than the level of splitting the file into lexemes. This may well be enough for counting metrics or other purposes. But trying to build and analyze the parse tree (PT) is not worth it, since the result is likely to be of little use for processing.
Having preprocessed code, the user can transfer it to the data entry subsystem as a file or a buffer in memory. The purpose of the input subsystem is to arrange the transferred data in the internal structures of the VivaCore library. Also, the input subsystem accepts configuration data that tells what to consider as system and as user libraries.
I would like to emphasize that this subsystem does not perform code preprocessing in its classical sense. As it was said earlier, the preprocessed code should already be submitted to the input of the VivaCore library. The considered subsystem serves for the following tasks:
So we got to those levels of data processing, which are of practical interest for developers. Having parsed the code into lexemes, the user has the ability to count many metrics, to implement a specific syntax highlighting algorithm in various applications.
The VivaCore lexical analyzer parses the program text into a set of Token objects (see the Token.h file), which contain information about the type of the lexeme, its location in the program text and its length. The types of tokens are listed in the tokennames.h file. Examples of types of tokens:
CLASS - the key word of the language "class"
WCHAR is the keyword of the wchar_t language
If necessary, the user can expand the set of tokens. This may be required if the specific syntax of a specific language implementation is supported or when developing its own language extension.
When adding tokens, you need to declare them in the tokennames.h file and add them to the “table” / “tableC” / tableC0xx tables in the Lex.cc. file. The first table is intended for processing C ++ files, and the second for C files, the third for C ++ 0x. The reason for the presence of several tables is related to the fact that the set of lexemes in C, C ++, C ++ 0x is different. For example, the C language lacks the CLASS lexeme, since the word “class” is not a key word in C and may indicate a variable name.
As an experiment, study of VivaCore, or practical purposes, you can get a list of tokens in the form of unstructured text or using the DumpEx function in the following formatted form:
The grammar analyzer is designed to build a derivation tree (DT), which can later be analyzed and transformed. Please note that the grammar analyzer of the VivaCore library does not build an abstract syntax tree (AST), but a parse tree. This allows you to more easily implement support for metaprogram constructions that can be added by the user to C or C ++.
Building a tree in the VivaCore library occurs in the functions of the Parser class. The nodes and leaves of the tree are objects whose classes are inherited from the base classes NonLeaf and Leaf. Figure 3 shows part of the class hierarchy used to represent the tree.

Figure 3. Part of the class hierarchy used to build the parse tree.
As can be seen from the figure, the Ptree class is the base class for all the others and serves to organize a single interface for working with other classes. In the Ptree class, there is a set of pure virtual functions implemented in the descendants. For example, the “virtual bool IsLeaf () const = 0;” function is implemented in the NonLeaf and Leaf classes. Practically, classes implement only this function and are needed to make the class hierarchy more logical and beautiful.
Since working with a tree takes up a significant amount of library, Ptree has a large set of functions for working with tree nodes. For convenience, these functions are analogous to the functions of working with lists in Lisp. Here are some of them: Car, Cdr, Cadr, Cddr, LastNth, Length, Eq.
To get a general idea of the work of the grammar analyzer, as an example, we give the parse tree, which will be built from the following code:
Unfortunately, the entire parse tree will not be able to be depicted; therefore, we will depict it in parts in Figures 4.1-4.4.

Figure 4.1. Color designations of semantic tree nodes.
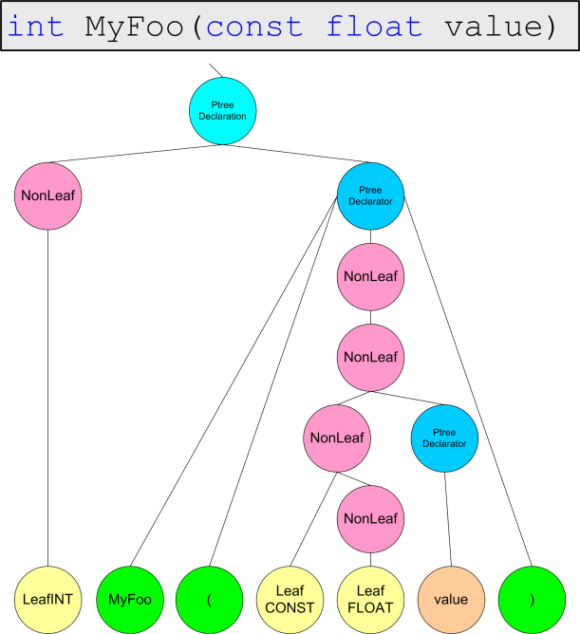
Figure 4.2. Representation of the function header.

Figure 4.3. Representation of the body function.
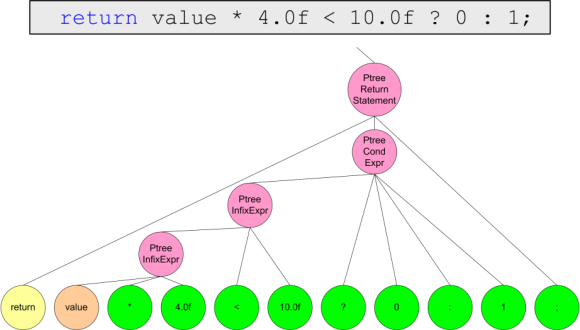
Figure 4.4. Representation of the body function.
Another important component of the analyzer’s work should be mentioned. This is getting information about the types of various objects (functions, variables, and so on), which is done in the Encoding class. Type information is presented in the form of a specially encoded string, the format of which can be found in the Encoding.cc file. There is also a special class TypeInfo in the library, which allows you to retrieve information about types. For example, using functions such as IsFunction, IsPointerType, IsBuiltInType, you can easily identify the type of element being processed.
A description of the approaches to adding new types of nodes or leaves is a non-trivial task and cannot be outlined in this review article. A rational solution would be to select one of the classes, for example, PtreeExprStatement and view all the places in the code where objects of this class are created, work with them, and so on.
The parse tree obtained upon completion can be saved in the file format ".c / .cpp", which, however, makes little sense. This feature will make sense after changing the parse tree, which can occur in the next stages. Having saved the tree now as a program code, we get exactly what we received at the entrance. However, this can be quite useful for testing changes made to the lexer and parser.
Of greater interest is the ability to save the tree for further processing in an arbitrary format implemented by the user. An example would be the following textual representation of the code that was provided earlier:
This format is shown just for example.
For developers of static code analyzers or systems for building documentation on the code, the most interesting step should be the step of traversing the parse tree, performed using the classes Walker, ClassWalker, ClassBodyWalker. Traversing the parse tree can be performed several times, which allows you to create systems that modify the code in several passes, or to carry out an analysis that takes into account already accumulated knowledge during previous tree traversals.
The Walker class serves to bypass the basic constructs of the C / C ++ language.
The ClassWalker class is inherited from the Walker class and adds functionality related to the specifics of the classes present in the C ++ language.
Note. To be honest, in OpenC ++, the functionality of these classes was mixed, and in VivaCore, the Walker and ClassWalker classes merged even more. They can be combined into one, but there is no sense from such work.
When it is necessary to disassemble a class body, objects of the ClassBodyWalker class are temporarily created and used.
If you do not make any changes to the VivaCore library, then a simple walk through all the elements of the tree will occur. In this case, the tree itself will not change.
If the user implements the functionality that will modify the vertices of the tree, the library can rebuild the tree. For example, consider the code that translates unary operations:
Note that if, by translating the expression to the right of a unary operation, the resulting tree is changed, the node of the unary operation will also be changed (re-created). That in turn may lead to restructuring and higher nodes.
For clarity, consider this example in more detail.
The processing of a node that represents a unary operation on a certain expression and has the type PtreeUnaryExpr begins. The first item in the list that is retrieved using the exp-> Car () operation is the unary operation itself. The second element retrieved using PtreeUtil :: Second (exp) is an expression that applies a unary operation.
The expression is translated and the result is placed in the variable right2. If this address is different from the existing one, then this means that the expression has been changed. In this case, a new object of the PtreeUnaryExpr type is created, which will be returned from the TranslateUnary function. Otherwise, nothing changes and the same object is returned as it entered the input.
If the user needs to collect information when traversing the tree, or to modify it, it will most naturally inherit from the ClassWalker and ClassBodyWalker classes.
Let us show the simplest example taken from the Viva64 static analyzer, in which a specialized analysis takes place when passing through the “throw” operator:
First, a standard node translation is performed using ClassWalker :: TranslateThrow (p). Then the necessary analysis is performed. Everything is simple and very elegant.
Speaking about tree traversal, it should also be said about the very important Environment class, which provides information on the types of various objects in different visibility areas.
An example of using the Environment class represented by an env object to get the type of the declTypeInfo object:
There are languages for which metaprogramming is a natural part. An example is the Nemerle language, which can be found in the article “Metaprogramming in Nemerle” [4]. But in the case of C / C ++, everything is more complicated, and in them metaprogramming is implemented in the following two ways:
The OpenC ++ library, on which VivaCore is built, was originally designed specifically for the conversion of C ++ code. The library was a part of a certain system that allows using a specific version of the C ++ language.
Also, on the basis of OpenC ++, the OpenTS execution environment for the T ++ programming language was created at the Institute of Software Systems of the Russian Academy of Sciences. This is the C ++ language, into which additional constructions are introduced for automatic parallelization of code sections. For simplicity, I will call it a kind of analogue of OpenMP technology. This example demonstrates the possibility of using the OpenC ++ library for metaprogramming tasks. Library VivaCore accordingly inherited these features.
By metaprogramming within the VivaCore library, you should understand the possibility of extending the syntax and functionality of the C / C ++ language in order to create your own programming language. A new metalanguage can be implemented as an intermediate link between the preprocessor and the compiler. In general, the operation scheme can be represented as shown in Figure 5.
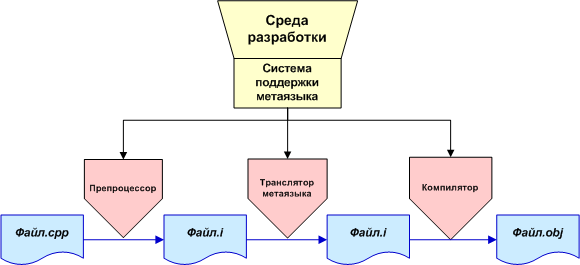
Figure 5. The participation of the meta-language translator in the compilation process.
VivaCore allows you to convert the program as follows. A parse tree is being built. Then the tree nodes are traversed and those nodes that are new language constructs turn into C / C ++ language constructs. New subtrees are built with the necessary functionality. At the same time, the parent nodes begin to point no longer to the nodes with the metalanguage constructions, but to these created subtrees from C / C ++ elements (see also above “Traversing the Parse Tree”).
If necessary, there may be several such passes, which allows you to create some new language constructs from other new language constructs.
After processing, the new tree can be saved as a C / C ++ program text, which will then be compiled using the compiler.
Note. In order not to deceive readers, I will say straight away that unfortunately this is all theoretically. We did not test how many of our edits and improvements to OpenC ++ affected the mechanisms of program transformations. We do not use this mechanism and as a result we do not test. Unfortunately, I am sure that there are errors and shortcomings in it, as a result of which the text of the program at the output will not correspond to the text of the program at the input. I am a practitioner, I do not believe in luck in such matters and I know that mistakes should be there. Therefore, if you start creating a transformation tool, be prepared for this and do not scold us. Better to write, perhaps together we will improve the world (in the sense of the library).
More information on metaprogramming can be found in the available documentation for the OpenC ++ library [5].
It is possible to save the necessary information at any stage of the processing of the source code inside the VivaCore library. In particular, we mentioned that the resulting and modified parse tree can be saved as program text or in any other format. We will not repeat. It is also clear that one can approach the task of collecting the necessary information, for example, by static analysis or counting of metrics, in a variety of ways.
In order to more clearly demonstrate how to use the VivaCore library, we have created a demo project VivaVisualCode, available for download at http://www.viva64.com/ru/vivacore-library/ .
VivaVisualCode graphically displays the constructed parse tree and allows you to view some information on its nodes.
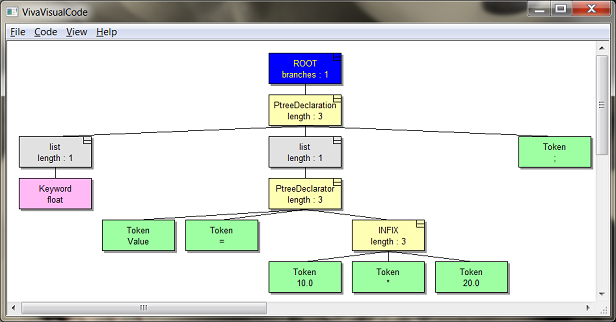
Figure 6. An example of the parse tree constructed by the program VivaVisualCode for the code “float Value = 10.0 * 20.0;”.
I also want to offer readers an article by Yevgeny Zuev " A rare profession " about his experience in compiler development. This article has nothing to do with this post, but it is very interesting, and I recommend it.
Instead of entry. Stop discussing saws, let's create something better
As part of the blog company Intel, I want to support the creation of "complex" IT startups. It is more interesting for me to hear and discuss such topics. Perhaps, over time, the ISN platform will become exactly the place where the discussion and the emergence of new startups in the field of parallel programming, the creation of their own libraries and other technologies of this kind will begin. And maybe at Habrahabare there will be fewer posts about the achievements of foreign companies and about cuts in ours, and there will be more interesting articles about his own experience, about who does what and how he does it.
Place VivaCore in the universe
Immediately clearly define the place of the library VivaCore . VivaCore library was created on the basis of another open library OpenC ++ , which has not been developed for many years [1]. VivaCore is a set of patches, fixes, crutches, supports and backings, which allowed the OpenC ++ library to parse the source code compiled by Visual C ++ 8.0, 9.0, 10.0. That is, to support specific extensions, as well as new constructions that appeared in C ++ 0x and implemented in Visual C ++ 10.0 [2].
VivaCore is not a full-fledged library. We develop VivaCore as a mechanism on which we create static code analyzers included in PVS-Studio . That is, VivaCore is this part of the PVS-Studio project that we decided to make open in order to enable others to use the improved and expanded version of OpenC ++.
')
VivaCore has a lot of flaws. It is not fully possible to analyze some sample constructs, there is no documentation, it is impossible to work with Unicode code, and so on. If you need full support for parsing and analyzing the C / C ++ language, or you plan to create your own compiler / development environment, the VivaCore library will not suit you. In this case, you should use professional libraries, for example - EDG . The price of a license for such a library ranges from $ 40,000 to $ 250,000 per year. This price is too high for many start-up projects that are not ready for such investments, without confidence in the success of the project. In this case, the VivaCore library can be a good compromise. It is free, and although not ideal, it allows you to work with C / C ++ at a fairly good level. This level will be sufficient for most code tools.
It should be mentioned that it is possible to try to build your project based on GCC source codes or other open systems. These options will also have both strengths and weaknesses. Something will be easier to implement, something more difficult. Legal aspects also make their own adjustments. I just want to talk about the library VivaCore, and research, comparison and choice is provided to the reader.
If you are still interested in the VivaCore library, then this article will allow you to get to know it better and tell you about possible areas of its application. The archive with source code (project for VS2010) is available for download here: http://www.viva64.com/ru/vivacore-library/ . From time to time we update it. I just want to ask in advance not to overwhelm me with various questions about working with VivaCore, if this is related to training. If you have a full-fledged project, then of course I will try to suggest or we can conclude an agreement on the implementation of the required functionality. I want to insure against the influx of students' questions, which occurs 2 times a year, when they are given assignments for coursework / diplomas related to the creation of parsers and the like. :)
Basic terms
Before proceeding, briefly give a definition of some terms.
Preprocessing is a mechanism that looks at the input ".c / .cpp" file, which executes the preprocessor directives in it, which includes the contents of other files specified in #include directives and so on. The result is a file that does not contain preprocessor directives, all macros used are expanded, instead of #include directives the contents of the corresponding files are substituted. The file with the result of preprocessing usually has the suffix ".i". The result of preprocessing is called a translation unit.
Parsing is the process of analyzing the input sequence of characters, with the purpose of parsing the grammatical structure. Usually parsing is divided into two levels: lexical analysis and grammatical analysis.
Lexical analysis is the process of processing the input sequence of characters in order to obtain at the output a sequence of characters called lexemes (or "tokens"). Each lexeme can be conventionally represented as a structure containing the type of the lexeme and, if necessary, the corresponding value. For C ++, the lexemes are “class”, “int”, “-”, “{” and so on.
Grammar analysis (grammatical analysis) is the process of comparing a linear sequence of lexemes (words) of a language with its formal grammar. The result is usually a parse tree or an abstract syntax tree.
An abstract syntax tree (Abstract Syntax Tree - AST) is a finite, labeled, oriented tree, in which internal vertices are associated with operators of a programming language, and leaves with corresponding operands. Thus, the leaves are empty operators and represent only variables and constants. An abstract syntax tree is different from a derivation tree (derivation tree - DT or parse tree - PT) in that there are no nodes for those syntax rules that do not affect the semantics of the program. A classic example of this absence is grouping brackets, since in AST the grouping of operands is explicitly defined by the tree structure.
Metaprogramming is the creation of programs that create other programs as a result of their work, or that change or supplement themselves during execution [3]. In metaprogramming, two main directions can be distinguished: code generation and self-modifying code. Next, we will consider metaprogramming as generation of C / C ++ source code.
Traversing the syntactic tree - traversing all the vertices and leaves of the syntactic tree in order to collect information of various kinds, analysis or modification.
What is VivaCore
The VivaCore library is an open source project built on the basis of the older library - OpenC ++ (OpenCxx). The VivaCore library is implemented in C ++ and is a project intended for compilation in Visual Studio 2010. However, no specific extension of the Visual C ++ compiler is used and the project after a little adaptation can be assembled with another modern compiler.
The VivaCore library was created and is being developed by the employees of Program Verification Systems LLC. The library of code analysis VivaCore has a certificate of state registration of computer programs N 2008610480.
You can freely and free use the VivaCore library. The only license restriction is the need to indicate that your project was developed on the basis of OpenC ++ libraries and its extension - VivaCore.
First of all, the VivaCore library may be interesting for small companies (start-ups) that create or plan to create tools for working with code. Of course, it’s not possible to list all the valid areas and methods of application, but I’ll still name a number of areas to show VivaCore from different angles. Examples of products related to this class of solutions are indicated in parentheses as explanations. So, with the help of VivaCore it is possible to develop:
- code refactoring tools (VisualAssist, DevExpress Refactoring, JetBrains Resharper);
- general and specialized static analyzers (Viva64, lint, Gimpel Software PC-Lint, Parasoft C ++ test);
- dynamic code analyzers (Compuware BoundsChecker, AutomatedQA AQTime);
- C / C ++ language extensions, including support for metaprogramming (OpenTS);
- automated code testing (Parasoft C ++ test)
- code transformations, for example, for optimization;
- syntax highlighting (Whole Tomato Software VisualAssist, any modern development environment);
- systems for building documentation on the code (Synopsis, Doxygen);
- tools for monitoring changes in the source code or analyzing the evolution of changes;
- search for duplicate code at the level of grammatical constructions of the language;
- counting metrics (C and C ++ Code Counter - CCCC);
- support for coding standards (Gimpel Software PC-Lint);
- tools that facilitate the migration of code to other software and hardware platforms (Viva64);
- automatic code generation;
- code visualizers, dependency diagram building systems (Source-Navigator, CppDepend);
- code formatting (Ocher SourceStyler).
Difference of VivaCore library from OpenC ++ library
The main difference of the VivaCore library from OpenC ++ is that it is a live project and continues to actively increase its functionality. The OpenC ++ library, unfortunately, has not been developed for a long time. The most recent library change dates back to 2004. And the latest change related to the support of new keywords dates back to 2003. This fix is an unsuccessful attempt to add the wchar_t data type, which introduced five errors of a different type.
Let us list the new key functionalities implemented in the VivaCore library in comparison with OpenC ++:
- Classic C language is supported. A different set of lexemes is used, which makes it possible to name variables with the name “class” or declare a function in the classical C style: PureC_Foo (ptr) char * ptr; {...}.
- Much work has been done to support the specifics of the C ++ language syntax used when developing in the VisualStudio 2005/2008/2010 environment. For example, the library handles the keywords __noop, __if_exists, __ptr32, __pragma, __interface, and so on.
- Some new constructions that are available in the C ++ standard of 1998, but did not manage to get into OpenC ++, are supported. In particular, the call of template functions is supported using the word template: object.template foo <int> () ;.
- The standard of the C ++ 0x language is supported at the level at which it is supported by the Visual C ++ and Intel C ++ compilers.
- Implemented calculation of literal constants.
- The library is adapted and optimized for work on 64-bit systems.
- Fixed a large number of errors and shortcomings. There are a lot of them and there is no impossibility to list them here.
- Supported parsing of OpenMP directives. True, most of the work with them is performed by the VivaMP code, which is absent in VivaCore. But if anything, write - we will help, we will help.
- Implemented coding of long types. Previously, any type was encoded with a special string no longer than 127 characters, which at times was not enough. As a result, on such libraries as boost or loki, the OpenC ++ library “went crazy” and did not work correctly.
General structure of the VivaCore library
The overall functional structure of the VivaCore library is shown in Figure 1.
Figure 1. The general structure of the VivaCore library.
Consider the functional blocks of the library in the order in which they process the source text of the program received at the input, as shown in Figure 2. Consider what actions each functional block performs, what information it allows to receive and how it can be modified for specific purposes.
Figure 2 - Sequence of processing code.
1) Input subsystem
The VivaCore library can correctly use only the original C / C ++ code previously processed by the preprocessor. Currently, the Visual C ++ compiler is used to generate preprocessed files in PVS-Studio. After it works, it turns out the processed file with the extension “i”, with which VivaCore works.
In certain cases, you can submit raw C / C ++ files to the input, but in this case, working with VivaCore should be no further than the level of splitting the file into lexemes. This may well be enough for counting metrics or other purposes. But trying to build and analyze the parse tree (PT) is not worth it, since the result is likely to be of little use for processing.
Having preprocessed code, the user can transfer it to the data entry subsystem as a file or a buffer in memory. The purpose of the input subsystem is to arrange the transferred data in the internal structures of the VivaCore library. Also, the input subsystem accepts configuration data that tells what to consider as system and as user libraries.
2) The code pre-processing subsystem (Preprocessor subsystem)
I would like to emphasize that this subsystem does not perform code preprocessing in its classical sense. As it was said earlier, the preprocessed code should already be submitted to the input of the VivaCore library. The considered subsystem serves for the following tasks:
- Breaking the program text into lines and splitting them into two logical groups. The first group includes the system code (the code of the compiler libraries, and so on). Go to the second user code that is of interest for analysis. As a result, by developing a static analyzer, the user is able to decide whether he will analyze the code of the system libraries or not.
- Specialized modification of the text of the program in memory. An example is the removal from the code of constructions of a specific development environment unrelated to C or C ++ languages. For example, the Viva64 analyzer removes such key constructions as SA_Success or SA_FormatString in the Visual Studio header files for the static analyzer built into Visual Studio (this is Code Analysis for C / C ++).
3) Lexer analyzer (Lexer)
So we got to those levels of data processing, which are of practical interest for developers. Having parsed the code into lexemes, the user has the ability to count many metrics, to implement a specific syntax highlighting algorithm in various applications.
The VivaCore lexical analyzer parses the program text into a set of Token objects (see the Token.h file), which contain information about the type of the lexeme, its location in the program text and its length. The types of tokens are listed in the tokennames.h file. Examples of types of tokens:
CLASS - the key word of the language "class"
WCHAR is the keyword of the wchar_t language
If necessary, the user can expand the set of tokens. This may be required if the specific syntax of a specific language implementation is supported or when developing its own language extension.
When adding tokens, you need to declare them in the tokennames.h file and add them to the “table” / “tableC” / tableC0xx tables in the Lex.cc. file. The first table is intended for processing C ++ files, and the second for C files, the third for C ++ 0x. The reason for the presence of several tables is related to the fact that the set of lexemes in C, C ++, C ++ 0x is different. For example, the C language lacks the CLASS lexeme, since the word “class” is not a key word in C and may indicate a variable name.
As an experiment, study of VivaCore, or practical purposes, you can get a list of tokens in the form of unstructured text or using the DumpEx function in the following formatted form:
258 LC_ID 5
258 lc_id 5
91 [1
262 6 1
93] 1
59; one
303 struct 6
123 {1
282 char 4
42 * 1
258 locale 6 4) Grammar Analyzer (Parser)
The grammar analyzer is designed to build a derivation tree (DT), which can later be analyzed and transformed. Please note that the grammar analyzer of the VivaCore library does not build an abstract syntax tree (AST), but a parse tree. This allows you to more easily implement support for metaprogram constructions that can be added by the user to C or C ++.
Building a tree in the VivaCore library occurs in the functions of the Parser class. The nodes and leaves of the tree are objects whose classes are inherited from the base classes NonLeaf and Leaf. Figure 3 shows part of the class hierarchy used to represent the tree.
Figure 3. Part of the class hierarchy used to build the parse tree.
As can be seen from the figure, the Ptree class is the base class for all the others and serves to organize a single interface for working with other classes. In the Ptree class, there is a set of pure virtual functions implemented in the descendants. For example, the “virtual bool IsLeaf () const = 0;” function is implemented in the NonLeaf and Leaf classes. Practically, classes implement only this function and are needed to make the class hierarchy more logical and beautiful.
Since working with a tree takes up a significant amount of library, Ptree has a large set of functions for working with tree nodes. For convenience, these functions are analogous to the functions of working with lists in Lisp. Here are some of them: Car, Cdr, Cadr, Cddr, LastNth, Length, Eq.
To get a general idea of the work of the grammar analyzer, as an example, we give the parse tree, which will be built from the following code:
int MyFoo (const float value)
{
if (value <1.0)
return sizeof (unsigned long *);
return value * 4.0f <10.0f? 0: 1;
} Unfortunately, the entire parse tree will not be able to be depicted; therefore, we will depict it in parts in Figures 4.1-4.4.
Figure 4.1. Color designations of semantic tree nodes.
Figure 4.2. Representation of the function header.
Figure 4.3. Representation of the body function.
Figure 4.4. Representation of the body function.
Another important component of the analyzer’s work should be mentioned. This is getting information about the types of various objects (functions, variables, and so on), which is done in the Encoding class. Type information is presented in the form of a specially encoded string, the format of which can be found in the Encoding.cc file. There is also a special class TypeInfo in the library, which allows you to retrieve information about types. For example, using functions such as IsFunction, IsPointerType, IsBuiltInType, you can easily identify the type of element being processed.
A description of the approaches to adding new types of nodes or leaves is a non-trivial task and cannot be outlined in this review article. A rational solution would be to select one of the classes, for example, PtreeExprStatement and view all the places in the code where objects of this class are created, work with them, and so on.
The parse tree obtained upon completion can be saved in the file format ".c / .cpp", which, however, makes little sense. This feature will make sense after changing the parse tree, which can occur in the next stages. Having saved the tree now as a program code, we get exactly what we received at the entrance. However, this can be quite useful for testing changes made to the lexer and parser.
Of greater interest is the ability to save the tree for further processing in an arbitrary format implemented by the user. An example would be the following textual representation of the code that was provided earlier:
PtreeDeclaration: [
0
NonLeaf: [
LeafINT: int
]
PtreeDeclarator: [
Leaf: MyFoo
Leaf :(
NonLeaf: [
NonLeaf: [
NonLeaf: [
LeafCONST: const
NonLeaf: [
LeafFLOAT: float
]
]
PtreeDeclarator: [
Leaf: value
]
]
]
Leaf :)
]
[{
NonLeaf: [
PtreeIfStatement: [
LeafReserved: if
Leaf :(
PtreeInfixExpr: [
LeafName: value
Leaf: <
Leaf: 1.0
]
Leaf :)
PtreeReturnStatement: [
LeafReserved: return
PtreeSizeofExpr: [
Leaf: sizeof
Leaf :(
NonLeaf: [
NonLeaf: [
LeafUNSIGNED: unsigned
LeafLONG: long
]
PtreeDeclarator: [
Leaf: *
]
]
Leaf :)
]
Leaf :;
]
]
PtreeReturnStatement: [
LeafReserved: return
PtreeCondExpr: [
PtreeInfixExpr: [
PtreeInfixExpr: [
LeafName: value
Leaf: *
Leaf: 4.0f
]
Leaf: <
Leaf: 10.0f
]
Leaf :?
Leaf: 0
Leaf ::
Leaf: 1
]
Leaf :;
]
]
Leaf:}
}]
] This format is shown just for example.
5) Traversing the parse tree
For developers of static code analyzers or systems for building documentation on the code, the most interesting step should be the step of traversing the parse tree, performed using the classes Walker, ClassWalker, ClassBodyWalker. Traversing the parse tree can be performed several times, which allows you to create systems that modify the code in several passes, or to carry out an analysis that takes into account already accumulated knowledge during previous tree traversals.
The Walker class serves to bypass the basic constructs of the C / C ++ language.
The ClassWalker class is inherited from the Walker class and adds functionality related to the specifics of the classes present in the C ++ language.
Note. To be honest, in OpenC ++, the functionality of these classes was mixed, and in VivaCore, the Walker and ClassWalker classes merged even more. They can be combined into one, but there is no sense from such work.
When it is necessary to disassemble a class body, objects of the ClassBodyWalker class are temporarily created and used.
If you do not make any changes to the VivaCore library, then a simple walk through all the elements of the tree will occur. In this case, the tree itself will not change.
If the user implements the functionality that will modify the vertices of the tree, the library can rebuild the tree. For example, consider the code that translates unary operations:
Ptree * ClassWalker :: TranslateUnary (Ptree * exp)
{
using namespace PtreeUtil;
Ptree * unaryop = exp-> Car ();
Ptree * right = PtreeUtil :: Second (exp);
Ptree * right2 = Translate (right);
if (right == right2)
return exp;
else
return
new (GC_QuickAlloc)
PtreeUnaryExpr (unaryop, PtreeUtil :: List (right2));
} Note that if, by translating the expression to the right of a unary operation, the resulting tree is changed, the node of the unary operation will also be changed (re-created). That in turn may lead to restructuring and higher nodes.
For clarity, consider this example in more detail.
The processing of a node that represents a unary operation on a certain expression and has the type PtreeUnaryExpr begins. The first item in the list that is retrieved using the exp-> Car () operation is the unary operation itself. The second element retrieved using PtreeUtil :: Second (exp) is an expression that applies a unary operation.
The expression is translated and the result is placed in the variable right2. If this address is different from the existing one, then this means that the expression has been changed. In this case, a new object of the PtreeUnaryExpr type is created, which will be returned from the TranslateUnary function. Otherwise, nothing changes and the same object is returned as it entered the input.
If the user needs to collect information when traversing the tree, or to modify it, it will most naturally inherit from the ClassWalker and ClassBodyWalker classes.
Let us show the simplest example taken from the Viva64 static analyzer, in which a specialized analysis takes place when passing through the “throw” operator:
Ptree * VivaWalker :: TranslateThrow (Ptree * p) {
Ptree * result = ClassWalker :: TranslateThrow (p);
Ptree * oprnd = PtreeUtil :: Second (result);
// If oprnd == nullptr, then this is "throw;"
if (oprnd! = nullptr) {
if (! CreateWiseType (oprnd)) {
return result;
}
if (IsErrorActive (115) &&
! ApplyRuleN10 (oprnd-> m_wiseType.m_simpleType))
{
AddError (VivaErrors :: V115 (), p, 115);
}
}
return result;
} First, a standard node translation is performed using ClassWalker :: TranslateThrow (p). Then the necessary analysis is performed. Everything is simple and very elegant.
Speaking about tree traversal, it should also be said about the very important Environment class, which provides information on the types of various objects in different visibility areas.
An example of using the Environment class represented by an env object to get the type of the declTypeInfo object:
TypeInfo declTypeInfo;
if (env-> Lookup (decl, declTypeInfo)) {
...
} 6) Support for metaprogramming
There are languages for which metaprogramming is a natural part. An example is the Nemerle language, which can be found in the article “Metaprogramming in Nemerle” [4]. But in the case of C / C ++, everything is more complicated, and in them metaprogramming is implemented in the following two ways:
- Templates in C ++ and preprocessor in C. This path has many limitations.
- External language tools. The generator language is designed so that automatically or with minimal effort on the part of the programmer to implement the rules of the paradigm or the necessary special functions. In fact, a higher level programming language is being created. The VivaCore library can be used to create such a system.
The OpenC ++ library, on which VivaCore is built, was originally designed specifically for the conversion of C ++ code. The library was a part of a certain system that allows using a specific version of the C ++ language.
Also, on the basis of OpenC ++, the OpenTS execution environment for the T ++ programming language was created at the Institute of Software Systems of the Russian Academy of Sciences. This is the C ++ language, into which additional constructions are introduced for automatic parallelization of code sections. For simplicity, I will call it a kind of analogue of OpenMP technology. This example demonstrates the possibility of using the OpenC ++ library for metaprogramming tasks. Library VivaCore accordingly inherited these features.
By metaprogramming within the VivaCore library, you should understand the possibility of extending the syntax and functionality of the C / C ++ language in order to create your own programming language. A new metalanguage can be implemented as an intermediate link between the preprocessor and the compiler. In general, the operation scheme can be represented as shown in Figure 5.
Figure 5. The participation of the meta-language translator in the compilation process.
VivaCore allows you to convert the program as follows. A parse tree is being built. Then the tree nodes are traversed and those nodes that are new language constructs turn into C / C ++ language constructs. New subtrees are built with the necessary functionality. At the same time, the parent nodes begin to point no longer to the nodes with the metalanguage constructions, but to these created subtrees from C / C ++ elements (see also above “Traversing the Parse Tree”).
If necessary, there may be several such passes, which allows you to create some new language constructs from other new language constructs.
After processing, the new tree can be saved as a C / C ++ program text, which will then be compiled using the compiler.
Note. In order not to deceive readers, I will say straight away that unfortunately this is all theoretically. We did not test how many of our edits and improvements to OpenC ++ affected the mechanisms of program transformations. We do not use this mechanism and as a result we do not test. Unfortunately, I am sure that there are errors and shortcomings in it, as a result of which the text of the program at the output will not correspond to the text of the program at the input. I am a practitioner, I do not believe in luck in such matters and I know that mistakes should be there. Therefore, if you start creating a transformation tool, be prepared for this and do not scold us. Better to write, perhaps together we will improve the world (in the sense of the library).
More information on metaprogramming can be found in the available documentation for the OpenC ++ library [5].
7) Saving results
It is possible to save the necessary information at any stage of the processing of the source code inside the VivaCore library. In particular, we mentioned that the resulting and modified parse tree can be saved as program text or in any other format. We will not repeat. It is also clear that one can approach the task of collecting the necessary information, for example, by static analysis or counting of metrics, in a variety of ways.
Demonstration project VivaVisualCode
In order to more clearly demonstrate how to use the VivaCore library, we have created a demo project VivaVisualCode, available for download at http://www.viva64.com/ru/vivacore-library/ .
VivaVisualCode graphically displays the constructed parse tree and allows you to view some information on its nodes.
Figure 6. An example of the parse tree constructed by the program VivaVisualCode for the code “float Value = 10.0 * 20.0;”.
Instead of conclusion
I also want to offer readers an article by Yevgeny Zuev " A rare profession " about his experience in compiler development. This article has nothing to do with this post, but it is very interesting, and I recommend it.
Bibliographic list
- OpenC ++ library. http://www.viva64.com/go.php?url=16
- Andrey Karpov. Static analysis of C ++ code and the new standard of the C ++ 0x language. http://www.viva64.com/art-2-1-1708094805.html
- Jonathan Bartlet The art of metaprogramming, Part 1: Introduction to metaprogramming. http://www.viva64.com/go.php?url=39
- Kamil Skalski. Metaprogramming in Nemerle. http://www.viva64.com/go.php?url=40
- Grzegorz Jakack. OpenC ++ - A C ++ Metacompiler and Introspection Library. http://www.viva64.com/go.php?url=41
Source: https://habr.com/ru/post/99663/
All Articles