Using Intel AVX: writing the program of tomorrow
Introduction
A new set of SIMD instructions for x86 Intel AVX processors was presented to the public in March 2008. And although the implementation of these instructions in hardware will wait another six months, the AVX specification can already be considered established, and support for the AVX instruction set has been added to new versions of compilers and assemblers. This article discusses practical optimization issues for Intel AVX routines in C / C ++ and assembler languages.
AVX command set
All AVX commands, as well as some other commands, are described in a reference book that can be found on the Intel AVX website . In a sense, the AVX instruction set is an extension of the SSE instruction set, which is already supported by all modern processors. In particular, AVX initially extends 128-bit SSE registers to 256 bits. The new 256-bit registers are denoted as ymm0-ymm15 (for the 32-bit program, only ymm0-ymm7 is available); while the 128-bit SSE registers xmm0-xmm15 refer to the lower 128 bits of the corresponding AVX register.
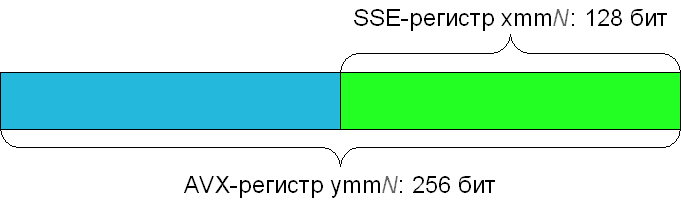
To work effectively with the new 256-bit registers, a myriad of instructions have been added to AVX. However, most of them are only slightly modified versions of the already familiar SSE instructions.
So, each instruction from SSE (as well as SSE2, SSE3, SSSE3, SSE4.1, SSE4.2 and AES-NI) has its analogue in AVX with the prefix v. In addition to the prefix, such AVX instructions differ from their SSE counterparts in that they can have three operands: the first operand indicates where to write the result, and the remaining two tell where to get the data. Three-instruction instructions are good because firstly they get rid of redundant register-copying operations in the code, and secondly they simplify writing good optimizing compilers. SSE2 code
movdqa xmm2, xmm0
punpcklbw xmm0, xmm1
punpckhbw xmm2, xmm1can be rewritten from avx as
vpunpckhbw xmm2, xmm0, xmm1
vpunpcklbw xmm0, xmm0, xmm1 vpunpckhbw xmm2, xmm0, xmm1
vpunpcklbw xmm0, xmm0, xmm1 .At the same time, the commands with the prefix v zero the highest 128 bits of the AVX register into which they write. For example, the instruction vpaddw xmm0, xmm1, xmm2 will zero the upper 128-bit register ymm0.
In addition, some SSE instructions were extended to AVX to work with 256-bit registers. These instructions include all commands working with floating-point numbers (both single and double precision). For example, the following AVX code
vmovapd ymm0, [esi]
vmulpd ymm0, ymm0, [edx]
vmovapd [edi], ymm0processes 4 double at once.
In addition, AVX includes some new instructions.
- vbroadcastss / vbroadcastsd / vbroadcastf128 - filling the entire AVX register with the same loaded value
- vmaskmovps / vmaskmovpd - conditional loading / saving of float / double numbers in AVX register depending on the sign of numbers in another AVX register
- vzeroupper - reset the older 128 bits of all AVX registers
- vzeroall - full resetting of all AVX registers
- vinsertf128 / vextractf128 - insert / receive any 128-bit part of the 256-bit AVX register
- vperm2f128 - swapping the 128-bit parts of the 256-bit AVX register. The permutation parameter is set statically.
- vpermilps / vpermilpd - permutation of float / double numbers inside 128-bit parts of the 256-bit AVX register. The parameters of the permutation are taken from another AVX register.
- vldmxcsr / vstmxcsr - load / save AVX control parameters (where to go without it!)
- xsaveopt - getting hints about which AVX registers contain data. This command is made for OS developers and helps them speed up the context switch.
Using AVX in assembly code
Today AVX is supported by all popular x86 assemblers:
- GAS (GNU Assembler) - from binutils version 2.19.50.0.1, but it is better to use 2.19.51.0.1, which supports the later AVX specification
- MASM - starting from version 10 (included in Visual Studio 2010)
- NASM - starting from version 2.03, but it is better to use the latest version
- YASM - starting with version 0.70, but it is better to use the latest version
Definition of AVX support system
The first thing to do before using AVX is to make sure the system supports it. Unlike different versions of SSE, AVX requires its support not only by the processor, but also by the operating system (after all, it must now save the top 128-bit AVX registers when switching context). Fortunately, the AVX developers have provided a way to learn about the support of this set of instructions by the operating system. The OS saves / restores the AVX context using special XSAVE / XRSTOR instructions, and these commands are configured using the extended control register (extended control register). Today there is only one such register - XCR0, aka XFEATURE_ENABLED_MASK. You can get its value by writing the register number to ecx (for XCR0 it is, of course, 0) and calling the XGETBV command. The 64-bit register value will be stored in the edx pair of registers: eax. The zero bit of the register XFEATURE_ENABLED_MASK means that the XSAVE command saves the state of the FPU registers (however, this bit is always set), the first bit is set to save SSE registers (the lower 128 bits of the AVX register), and the second bit is set to save the high 128 bits of AVX register. So to be sure that the system maintains the state of AVX registers when switching contexts, you need to make sure that bits 1 and 2 are set in the XFEATURE_ENABLED_MASK register. However, this is not all: before calling the XGETBV command, you need to make sure that the OS really uses XSAVE instructions / XRSTOR for context management. This is done by calling the CPUID instruction with the eax = 1 parameter: if the OS has enabled context saving / recovery management with the XSAVE / XRSTOR instructions, then after performing the CPUID, in the 27th bit of the ecx register there will be one. In addition, it would be nice to check that the processor itself supports the AVX instruction set. This is done in the same way: call the CPUID with eax = 1 and make sure that after that in the 28th bit of the ecx register there is one. All of the above can be expressed in the following code (copied, with minor modifications, from the Intel AVX Reference):
; extern "C" int isAvxSupported()
_isAvxSupported:
xor eax, eax
cpuid
cmp eax, 1 ; CPUID eax = 1?
jb not_supported
mov eax, 1
cpuid
and ecx, 018000000h ; , 27 ( XSAVE/XRSTOR)
cmp ecx, 018000000h ; 28 ( AVX )
jne not_supported
xor ecx, ecx ; XFEATURE_ENABLED_MASK/XCR0 0
xgetbv ; XFEATURE_ENABLED_MASK edx:eax
and eax, 110b
cmp eax, 110b ; , AVX
jne not_supported
mov eax, 1
ret
not_supported:
xor eax, eax
ret
Using AVX instructions
Now that you know when to use AVX instructions, it's time to switch to using them. Programming under AVX differs little from programming under other instruction sets, but the following features should be taken into account:
- It is extremely undesirable to mix SSE- and AVX-instructions (including AVX-analogs of SSE-instructions). To move from executing AVX instructions to SSE instructions, the processor stores the top 128 bits of the AVX registers in a special cache, which can take fifty clock cycles. When, after an SSE instruction, the processor returns to the execution of AVX instructions, it will restore the top 128 bits of the AVX registers, which will take another fifty cycles. Therefore, mixing the SSE and AVX instructions will result in a noticeable decrease in performance. If you need some command from the SSE in the AVX-code, use its AVX-analogue with the prefix v.
- Saving the upper part of the AVX registers during the transition to the SSE code can be avoided if you reset the top 128 bits of the AVX registers with the vzeroupper or vzeroall commands. Although these commands nullify all AVX registers, they work very quickly. The pitch rule will use one of these commands before exiting a subroutine using AVX.
- The load / save commands for aligned data vmovaps / vmovapd / vmovdqa require that data be aligned by 16 bytes, even if the command itself loads 32 bytes.
- On Windows x64, the subroutine should not change the xmm6-xmm15 registers. Thus, if you use these registers (or their corresponding registers ymm6-ymm15), you must save them on the stack at the beginning of the subroutine and recover from the stack before exiting the subroutine.
- The Sandy Bridge core will be able to run two 256-bit AVX floating-point commands for each cycle (one multiplication and one addition) due to the expansion of execution units to 256 bits. The Bulldozer core will have two 128-bit universal floating point execution units that allow it to execute one 256-bit AVX command per cycle (multiply, add, or combined multiplied-add and fused multiply-add); you can hope for the same performance as the Sandy Bridge).
Now you know everything to write code using AVX. For example, such:
; extern "C" double _vec4_dot_avx( double a[4], double b[4] )
_vec4_dot_avx:
%ifdef X86
mov eax, [esp + 8 + 0] ; eax = a
mov edx, [esp + 8 + 8] ; edx = b
vmovupd ymm0, [eax] ; ymm0 = *a
vmovupd ymm1, [edx] ; ymm1 = *b
%else
vmovupd ymm0, [rcx] ; ymm0 = *a
vmovupd ymm1, [rdx] ; ymm1 = *b
%endif
vmulpd ymm0, ymm0, ymm1 ; ymm0 = ( a3 * b3, a2 * b2, a1 * b1, a0 * b0 )
vperm2f128 ymm1, ymm0, ymm0, 010000001b ; ymm1 = ( +0.0, +0.0, a3 * b3, a2 * b2 )
vaddpd xmm0, xmm0, xmm1 ; ymm0 = ( +0.0, +0.0, a1 * b1 + a3 * b3, a0 * b0 + a2 * b2 )
vxorpd xmm1, xmm1, xmm1 ; ymm1 = ( +0.0, +0.0, +0.0, +0.0 )
vhaddpd xmm0, xmm0, xmm1 ; ymm0 = ( +0.0, +0.0, +0.0, a0 * b0 + a1 * b1 + a2 * b2 + a3 * b3 )
%ifdef X86 ; 32- st(0)
sub esp, 8
vmovsd [esp], xmm0
vzeroall ; SSE- :
fld qword [esp]
add esp, 8
%else
vzeroupper ; xmm0 , 128
%endif
ret
Testing AVX code
To make sure that the AVX code works, it is better to write Unit tests for it. However, the question arises: how to run these Unit tests if none of the currently sold processor supports AVX? This will help you a special utility from Intel - Software Development Emulator (SDE) . All that SDE can do is launch programs by emulating new instruction sets on the fly. Of course, the performance will be far from that on real hardware, but you can check the correctness of the program in this way. Using SDE is easy: if you have a unit test for AVX code in the avx-unit-test.exe file and need to run it with the “Hello, AVX!” Parameter, then you just need to run SDE with the parameters
sde -- avx-unit-test.exe "Hello, AVX!"When you launch the SDE program, it emulates not only the AVX instructions, but also the XGETBV and CPUID instructions, so if you use the previously proposed method for detecting AVX support, the program running under SDE will decide that AVX is indeed supported. In addition to AVX, SDE (or rather, the JIT pin compiler on which SDE is built) can emulate SSE3, SSSE3, SSE4.1, SSE4.2, SSE4a, AES-NI, XSAVE, POPCNT and PCLMULQDQ instructions, so even a very old processor will not prevent you from developing software for new instruction sets.
AVX code performance evaluation
Some understanding of AVX code performance can be obtained using another utility from Intel - Intel Architecture Code Analyzer (IACA) . IACA allows you to estimate the execution time of the linear code segment (if conditional branching commands are encountered, the IACA considers that the transition does not occur). To use IACA, you must first mark with special markers the code points that you want to analyze. Markers look like this:
; ,
%macro IACA_START 0
mov ebx, 111
db 0x64, 0x67, 0x90
%endmacro
; ,
%macro IACA_END 0
mov ebx, 222
db 0x64, 0x67, 0x90
%endmacroNow you should surround these macros with the code you want to analyze.
IACA_START
vmovups ymm0, [ecx]
vbroadcastss ymm1, [edx]
vmulps ymm0, ymm0, ymm1
vmovups [ecx], ymm0
vzeroupper
IACA_ENDThe object file compiled with these macros needs to be fed to the IACA:
iaca -32 -arch AVX -cp DATA_DEPENDENCY -mark 0 -o avx-sample.txt avx-sample.objParameters for IACA need to be understood as
- -32 - means that the input object file (MS COFF) contains a 32-bit code. For 64-bit code, you need to specify -64 . If the input file IACA is not an object file (.obj), but an executable module (.exe or .dll), then this argument can be omitted.
- -arch AVX - shows IACA that you need to analyze the performance of this code on a future Intel processor with AVX support (i.e. Sandy Bridge). Other possible values: -arch nehalem and -arch westmere .
- -cp DATA_DEPENDENCY asks IACA to show which instructions are on the critical path for the data (that is, which instructions need to be optimized so that the result of this code is calculated faster). Other possible meaning: -cp PERFORMANCE asks IACA to show which instructions plug the processor pipeline.
- -mark 0 tells IACA to analyze all the tagged parts of the code. If you specify -mark n , IACA will only analyze the nth tagged code.
- -o avx-sample specifies the name of the file to which the analysis results will be written. You can omit this parameter, then the results of the analysis will be displayed in the console.
The result of starting IACA is shown below:
Intel(R) Architecture Code Analyzer Version - 1.1.3
Analyzed File - avx-sample.obj
Binary Format - 32Bit
Architecture - Intel(R) AVX
*******************************************************************
Intel(R) Architecture Code Analyzer Mark Number 1
*******************************************************************
Analysis Report
---------------
Total Throughput: 2 Cycles; Throughput Bottleneck: FrontEnd, Port2_ALU, Port2_DATA, Port4
Total number of Uops bound to ports: 6
Data Dependency Latency: 14 Cycles; Performance Latency: 15 Cycles
Port Binding in cycles:
-------------------------------------------------------
| Port | 0 - DV | 1 | 2 - D | 3 - D | 4 | 5 |
-------------------------------------------------------
| Cycles | 1 | 0 | 0 | 2 | 2 | 1 | 1 | 2 | 1 |
-------------------------------------------------------
N - port number, DV - Divider pipe (on port 0), D - Data fetch pipe (on ports 2 and 3)
CP - on a critical Data Dependency Path
N - number of cycles port was bound
X - other ports that can be used by this instructions
F - Macro Fusion with the previous instruction occurred
^ - Micro Fusion happened
* - instruction micro-ops not bound to a port
@ - Intel(R) AVX to Intel(R) SSE code switch, dozens of cycles penalty is expected
! - instruction not supported, was not accounted in Analysis
| Num of | Ports pressure in cycles | |
| Uops | 0 - DV | 1 | 2 - D | 3 - D | 4 | 5 | |
------------------------------------------------------------
| 1 | | | | 1 | 2 | X | X | | | CP | vmovups ymm0, ymmword ptr [ecx]
| 2^ | | | | X | X | 1 | 1 | | 1 | | vbroadcastss ymm1, dword ptr [edx]
| 1 | 1 | | | | | | | | | CP | vmulps ymm0, ymm0, ymm1
| 2^ | | | | 1 | | X | | 2 | | CP | vmovups ymmword ptr [ecx], ymm0
| 0* | | | | | | | | | | | vzeroupper
The most important metrics here are Total Throughput and Data Dependency Latency. If the code you are optimizing is a small subroutine, and the program has a data dependency on its result, then you should try to make Data Dependency Latency as little as possible. As an example, the above listing of the vec4_dot_avx subroutine. If the code being optimized is part of a loop that processes a large array of elements, then your task is to reduce Total Throughput (in general, this metric would be called Reciprocal Throughput, but oh well).
Using AVX in C / C ++ Code
AVX support is implemented in the following popular compilers:
- Microsoft C / C ++ Compiler from version 16 (included in Visual Studio 2010)
- Intel C ++ Compiler from version 11.1
- GCC since version 4.4
To use the 256-bit AVX instructions, the distribution of these compilers includes a new header file immintrin.h with a description of the corresponding intrinsic functions. The inclusion of this header file automatically entails the inclusion of header files of all SSE-intrinsic. As for the 128-bit AVX instructions, for them there are not only separate headers, but also separate intrinsics functions. Instead, they use intrinsic functions for SSEx instructions, and the type of instructions (SSE or AVX) into which calls to these intrinsic functions will be compiled is specified in the compiler settings. This means that mixing SSE and AVX forms of 128-bit instructions in one compiled file will not work, and if you want to have both SSE and AVX versions of functions, then you will have to write them in different compiled files (and compile these files with different parameters ). Compilation options that include compiling SSEx intrinsic functions in AVX instructions are as follows:
- / arch: AVX - for Microsoft C / C ++ Compiler and Intel C ++ Compiler for Windows
- -mavx - for GCC and Intel C ++ Compiler for Linux
- / QxAVX - for Intel C ++ Compiler
- / QaxAVX - for Intel C ++ Compiler
It should be borne in mind that these commands not only change the behavior of SSEx intrinsic functions, but also allow the compiler to generate AVX instructions when compiling normal C / C ++ code (/ QaxAVX tells the Intel compiler to generate two versions of code - with AVX instructions and basic x86 instructions ).
To make it easier to deal with all these intrinsics, Intel made an online reference guide - the Intel Intrinsic Guide, which includes descriptions of all the intrinsic functions supported by Intel processors. For those instructions that are already implemented in the hardware, latency and throughput are also indicated. You can download this reference book from the Intel AVX website (there are versions for Windows, Linux and Mac OS X).
')
Definition of AVX support system
In principle, to recognize the support of the AVX system, you can use the previously assembled code, rewriting it in an inline-assembler, or simply linking the assembled object file. However, if inline assembly is not possible (for example, because of coding guidelines, or because the compiler does not support it, as is the case with Microsoft C / C ++ Compiler for Windows x64), then you are in deep shit. The problem is that the intrinsic functions for the xgetbv instruction do not exist! Thus, the task is divided into two parts: check that the processor supports AVX (this can be done cross-platform) and check that the OS supports AVX (here you have to write your own code for each OS).
You can verify that the processor supports AVX using the same CPUID instruction for which there is an intrinsic-function void __cpuid (int cpuInfo [4], int infoType). The infoType parameter sets the value of the eax register before the CPUID call, and after executing the function, cpuInfo will contain the eax, ebx, ecx, edx registers (in that order). So we get the following code:
int isAvxSupportedByCpu() {
int cpuInfo[4];
__cpuid( cpuInfo, 0 );
if( cpuInfo[0] != 0 ) {
__cpuid( cpuInfo, 1 );
return cpuInfo[3] & 0x10000000; // , 28- ecx
} else {
return 0; //
}
}With support from the OS more difficult. AVX is currently supported by the following OS:
- Windows 7
- Windows Server 2008 R2
- Linux with kernel 2.6.30 and higher
Windows has added the ability to learn about OS support for new instruction sets in the form of the GetEnabledExtendedFeatures function from kernel32.dll. Unfortunately, this function is documented a little less than nothing . But you can still get some information about her. This feature is described in the WinBase.h file from the Platform SDK:
WINBASEAPI
DWORD64
WINAPI
GetEnabledExtendedFeatures(
__in DWORD64 FeatureMask
);The values for the FeatureMask parameter can be found in the WinNT.h header:
//
// Known extended CPU state feature IDs
//
#define XSTATE_LEGACY_FLOATING_POINT 0
#define XSTATE_LEGACY_SSE 1
#define XSTATE_GSSE 2
#define XSTATE_MASK_LEGACY_FLOATING_POINT (1i64 << (XSTATE_LEGACY_FLOATING_POINT))
#define XSTATE_MASK_LEGACY_SSE (1i64 << (XSTATE_LEGACY_SSE))
#define XSTATE_MASK_LEGACY (XSTATE_MASK_LEGACY_FLOATING_POINT | XSTATE_MASK_LEGACY_SSE)
#define XSTATE_MASK_GSSE (1i64 << (XSTATE_GSSE))
#define MAXIMUM_XSTATE_FEATURES 64It is easy to see that the XSTATE_MASK_ * masks correspond to the same bits in the XFEATURE_ENABLED_MASK register.
In addition to this, in the Windows DDK there is a description of the RtlGetEnabledExtendedFeatures function and XSTATE_MASK_XXX constants, like two drops of water similar to GetEnabledExtendedFeatures and XSTATE_MASK_ from WinNT.h. So To determine if Windows supports AVX, you can use the following code:
int isAvxSupportedByWindows() {
const DWORD64 avxFeatureMask = XSTATE_MASK_LEGACY_SSE | XSTATE_MASK_GSSE;
return GetEnabledExtendedFeatures( avxFeatureMask ) == avxFeatureMask;
}If your program should work not only in Windows 7 and Windows 2008 R2, then the GetEnabledExtendedFeatures function needs to be loaded dynamically from kernel32.dll, since Other versions of Windows do not have this feature.
In Linux, as far as I know, there is no separate function to learn about OS support from AVX. But you can take advantage of the fact that AVX support was added to 2.6.30 kernel. Then it remains only to verify that the kernel version is not less than this value. You can check the kernel version using the uname function.
Using AVX instructions
Writing AVX code using intrinsic functions will not cause you any difficulty if you have ever used MMX or SSE using intrinsic. The only thing that needs to be taken care of is to call the _mm256_zeroupper () function at the end of the subroutine (as you might guess, this intrinsic-function generates a vzeroupper instruction). For example, the above assembler subroutine vec4_dot_avx can be rewritten in intrinsic like this:
double vec4_dot_avx( double a[4], double b[4] ) {
// mmA = a
const __m256d mmA = _mm256_loadu_pd( a );
// mmB = b
const __m256d mmB = _mm256_loadu_pd( b );
// mmAB = ( a3 * b3, a2 * b2, a1 * b1, a0 * b0 )
const __m256d mmAB = _mm256_mul_pd( mmA, mmB );
// mmABHigh = ( +0.0, +0.0, a3 * b3, a2 * b2 )
const __m256d mmABHigh = _mm256_permute2f128_pd( mmAB, mmAB, 0x81 );
// mmSubSum = ( +0.0, +0.0, a1 * b1 + a3 * b3, a0 * b0 + a2 * b2 )
const __m128d mmSubSum = _mm_add_pd(
_mm256_castpd256_pd128( mmAB ),
_mm256_castpd256_pd128( mmABHigh )
);
// mmSum = ( +0.0, +0.0, +0.0, a0 * b0 + a1 * b1 + a2 * b2 + a3 * b3 )
const __m128d mmSum = _mm_hadd_pd( mmSubSum, _mm_setzero_pd() );
const double result = _mm_cvtsd_f64( mmSum );
_mm256_zeroupper();
return result;
}Testing AVX code
If you use the AVX instruction set via intrinsic-functions, then, in addition to running this code under the SDE emulator, you have another opportunity - to use a special header file that emulates 256-bit AVX intrinsic-functions via the SSE1.2 intrinsic-functions . In this case, you will have an executable file that can be run on Nehalem and Westmere processors, which, of course, is faster than an emulator. However, keep in mind that this method does not succeed in detecting errors generated by the AVX code by the compiler (and they may well be).
AVX code performance evaluation
Using IACA to analyze the performance of AVX code created by a C / C ++ compiler from intrinsic functions is almost the same as analyzing assembler code. In the IACA distribution you can find the header file iacaMarks.h, which describes the macros markers IACA_START and IACA_END. They need to mark the analyzed code sections. In the code of the subroutine, the IACA_END token must appear before the return statement, otherwise the compiler will "optimize" by throwing out the marker code. The IACA_START / IACA_END macros use an inline-assembler that is not supported by Microsoft C / C ++ Compiler for Windows x64, so if you need to use special macros for it - IACA_VC64_START and IACA_VC64_END.
Conclusion
This article has demonstrated how to develop programs using the AVX instruction set. I hope that this knowledge will help you to please your users with programs that use the capabilities of a computer for one hundred percent!
Exercise
The code for the vec4_dot_avx subroutine is not optimal in terms of performance. . Data Dependency Latency?
Source: https://habr.com/ru/post/99367/
All Articles