Collection of examples of 64-bit errors in real programs - part 2
<< Read the first part of the article
Address arithmetic is a way to calculate the address of an object using pointer arithmetic, as well as the use of pointers in comparison operations. Address arithmetic is also called pointer arithmetic (pointer arithmetic).
')
A large percentage of 64-bit errors are associated with address arithmetic. Often errors occur in those expressions where pointers and 32-bit variables are used together.
Consider the first of the errors of this type:
The reason why in the Win32 program A + B == A - (-B) is shown in Figure 14.

Figure 14 - Win32: A + B == A - (-B)
The reason why in Win64 program A + B! = A - (-B) is shown in Figure 15.

Figure 15 - Win64: A + B! = A - (-B)
The error will be eliminated if you use the appropriate memsize-type . In this case, the ptrdfiff_t type is used:
Consider another version of the error associated with the use of signed and unsigned types. This time the error will not lead to an incorrect comparison, but immediately to the fall of the application.
The expression "x * y" has the value 0xFFFFFFFB and is of type unsigned. The code compiled in the 32-bit version is efficient, since adding a pointer to 0xFFFFFFFB is equivalent to decreasing it by 5. In a 64-bit pointer, after adding 0xFFFFFFFB, it will start pointing far beyond the p1 array (see Figure 16).

Figure 16 - Going beyond the array
The fix is to use memsize types and work carefully with signed and unsigned types:
The code is taken from a real program of mathematical modeling, in which an important resource is the amount of RAM, and the ability to use more than 4 GB of memory on a 64-bit architecture significantly increases computational capabilities. In programs of this class, one-dimensional arrays are often used to save memory, working with them as with three-dimensional arrays. To do this, there are functions similar to GetCell that provide access to the necessary elements.
The code above works correctly with pointers if the value of the expression "x + y * Width + z * Width * Height" does not exceed INT_MAX (2147483647). Otherwise an overflow will occur that will lead to undefined behavior in the program.
Such code could always work correctly on a 32-bit platform. Within the framework of the 32-bit architecture, the program does not have enough memory to create an array of similar size. On the 64-bit architecture, this restriction is removed, and the size of the array can easily exceed INT_MAX elements.
Programmers often make a mistake trying to correct the code as follows:
float Region :: GetCell (int x, int y, int z) const {
return array [static_cast <ptrdiff_t> (x) + y * Width +
z * Width * Height];
}
They know that according to the rules of the C ++ language, the expression for calculating the index will be of type ptrdiff_t and hope to avoid overflow due to this. But overflow can occur inside the “y * Width” or “z * Width * Height” subexpression, since the int type is still used to calculate them.
If you want to correct the code without changing the types of variables involved in the expression, then you can explicitly cast each subexpression to the ptrdiff_t type:
Another more correct solution is to change the types of variables:
Sometimes in programs for convenience change the type of the array during its processing. The dangerous and safe type conversion is presented in the following code:
As you can see, the output of the program differs in the 32-bit and 64-bit versions. On a 32-bit system, access to the elements of the array is carried out correctly, since the sizes of the size_t and int types are the same, and we see the output "2 2".
On the 64-bit system, we got the output “2 17179869187”, since exactly the value 17179869187 is located in the 1st element of the sizetPtr array (see Figure 17). In some cases, this is exactly the behavior that is needed, but usually it is a mistake.

Figure 17 - Representation of array elements in memory
Note. The enum type in the Visual C ++ compiler by default is the same size as the int type, that is, it is a 32-bit type. Using enum of a different size is possible only with the help of an extension that is considered non-standard in Visual C ++. Therefore, the given example is correct in Visual C ++, but from the point of view of other compilers, casting a pointer to int elements to a pointer to enum elements may also be incorrect.
Sometimes in programs, pointers are stored in integer types. Typically, this type is used such as int. This is perhaps one of the most common 64-bit errors.
In a 64-bit program, this is incorrect, since the int type remains 32-bit and cannot store a 64-bit pointer in itself. Often this can not be noticed immediately. Due to coincidence, the pointer can always refer to objects located in the lower 4 gigabytes of the address space when testing. In this case, the 64-bit program will work successfully, and may unexpectedly refuse only after a long period of time (see Figure 18).

Figure 18 - Pointer in a variable of type int
If it is nevertheless necessary to place the pointer in an integer type variable, then such types as intptr_t , uintptr_t , ptrdiff_t, and size_t should be used.
When it becomes necessary to work with a pointer as an integer, it is sometimes convenient to use a union, as shown in the example, and work with a numeric representation of the type without using explicit casts:
This code is correct on 32-bit systems and incorrect on 64-bit ones. Changing the m_n member on the 64-bit system, we work only with a part of the m_p pointer (see Figure 19).

Figure 19 - Representation of combining in memory on a 32-bit and 64-bit system.
You should use a type that will match the pointer size:
The mixed use of 32-bit and 64-bit types can unexpectedly lead to eternal loops. Consider a synthetic example illustrating a whole class of similar defects:
This loop will never stop if the value of Count> UINT_MAX. Suppose that on 32-bit systems this code worked with the number of iterations less than the value UINT_MAX. But the 64-bit version of the program can process more data, and it may need more iterations. Since the values of the Index variable lie in the range [0..UINT_MAX], the “Index! = Count” condition is never fulfilled, which leads to an infinite loop (see Figure 20).

Figure 20 - The mechanism of the eternal cycle
Working with bit operations requires special care from the programmer when developing cross-platform applications in which data types can have different sizes. Since the transfer of the program to the 64-bit platform also leads to a change in the dimension of some types, the probability of errors in sections of the code working with individual bits is high. Most often this is due to mixed work with 32-bit and 64-bit data types. Consider an error that occurred in the code due to incorrect use of the NOT operation:
The error is that the mask specified by the expression "~ (b - 1)" is of type ULONG. This leads to the zeroing of the high-order bits of the variable “a”; only the lower four bits should be reset (see Figure 21).

Figure 21 - Error due to clearing high bits
The revised code may look like this:
The given example is extremely simple, but it demonstrates well the class of errors that can occur during active work with bit operations.
The code above is operable on a 32-bit architecture and allows setting the bit with numbers from 0 to 31 to one. After transferring the program to the 64-bit platform, it becomes necessary to set bits with numbers from 0 to 63. However, this code is unable to set the high bits, with numbers 32-63. Note that the numeric literal “1” is of type int, and when shifted to 32 positions an overflow will occur, as shown in Figure 22. We will get 0 (Figure 22-B) or 1 (Figure 22-C) - depends on compiler implementations.
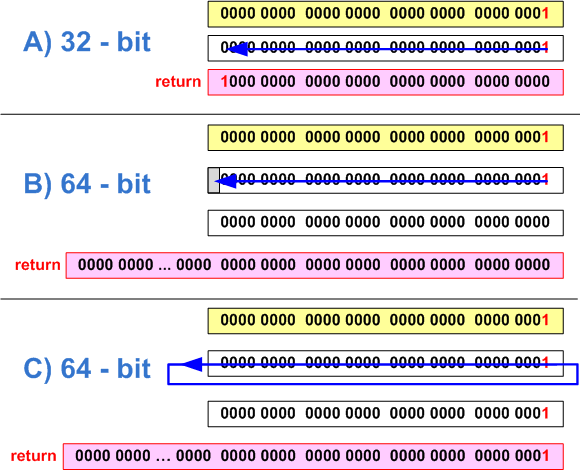
Figure 22 - a) correct setting of the 31st bit in a 32-bit code (bits are counted from 0); b, c) - Error installing the 32nd bit on a 64-bit system (two options depending on the compiler)
To correct the code, it is necessary to make the constant “1” of the same type as the variable mask:
Note also that an uncorrected code will result in another interesting error. When setting 31 bits on a 64-bit system, the result of the function operation will be 0xffffffff80000000 (see Figure 23). The result of the expression 1 << 31 is a negative number -2147483648. This number is represented in a 64-bit integer variable as 0xffffffff80000000.

Figure 23 - Error setting the 31st bit on a 64-bit system
The error given below is rare, but, unfortunately, quite complex in understanding. Therefore, we dwell on it a little more.
In a 32-bit environment, the order of evaluation of the expression will look like that shown in Figure 24.

Figure 24 - Calculation of the expression “obj.a << 17” in 32-bit code
Note that when calculating the expression “obj.a << 17”, a significant extension of the unsigned short type to the int type occurs. More clearly, this can be demonstrated by the following code:
Now let's see what the presence of the sign extension in the 64-bit code leads to. The sequence for evaluating an expression is shown in Figure 25.

Figure 25 - Calculation of the expression “obj.a << 17” in 64-bit code
A member of the obj.a structure is converted from an unsigned short bit field to an int. The expression “obj.a << 17” is of type int, but it is converted to ptrdiff_t and then to size_t before it is assigned to the variable addr. As a result, we get the number value 0xffffffff80000000, instead of the expected value 0x0000000080000000.
Be careful when working with bit fields. To prevent this situation in our example, it is enough to explicitly cast obj.a to size_t.
An important element of the transfer of software solutions to the new platform is the continuity to the existing data exchange protocols. It is necessary to ensure reading of the existing project formats, exchange data between 32-bit and 64-bit processes, and so on.
Basically, errors of this kind consist in the serialization of memsize types and data exchange operations using them:
It is unacceptable to use types that change their size depending on the development environment in binary data exchange interfaces. In C ++, most types do not have a clear size and, therefore, they cannot all be used for these purposes. Therefore, the developers of the development tools and the programmers themselves create data types that have a strict size, such as __int8, __int16, INT32, word64, and so on.
Even after making corrections regarding type sizes, you may encounter incompatibilities in binary formats. The reason lies in a different view of the data. This is most often associated with another sequence of bytes.
Byte order is a method for writing bytes of multibyte numbers (see Figure 26). Order from junior to senior (born little-endian) - recording begins with the youngest and ends with the older. This recording order is adopted in the memory of personal computers with x86 and x86-64 -processors. Order from senior to junior (English big-endian) - recording begins with the senior and ends with the younger. This order is standard for TCP / IP protocols. Therefore, the byte order from high to low is often called network byte order (eng. Network byte order). This byte order is used by Motorola 68000, SPARC processors.
By the way, some processors can work in order from the youngest to the oldest, and vice versa. These include, for example, IA-64 .

Figure 26 - Byte order in 64-bit type on little-endian and big-endian systems
When developing a binary interface or data format, be aware of the sequence of bytes. And if the 64-bit system to which you are porting a 32-bit application has a different sequence of bytes, then you will simply have to take this into account in your code. To convert between network byte order (big-endian) and byte order (little-endian), you can use the functions htonl (), htons (), bswap_64, and so on .
In addition to resizing some data types, errors can also occur due to changes in the rules for their alignment in a 64-bit system (see Figure 27).

Figure 27 - Dimensions types and their alignment boundaries (values are exact for Win32 / Win64, but can vary in the "Unix-world" and are given just as an example)
Consider an example of describing a problem found in one of the forums:
Faced today with one problem in Linux. There is a data structure consisting of several fields: 64-bit double, then 8 unsigned char and one 32-bit int. The total is 20 bytes (8 + 8 * 1 + 4). Under 32-bit systems, sizeof is 20 and everything works fine. And under 64-bit Linux, sizeof returns 24. That is, 64 bits are aligned.
Further in the forum there are arguments about the compatibility of data and the request of the council how to pack the data in the structure. But this is not interesting now. More interesting is the fact that there is another type of error that may occur when porting applications to a 64-bit system.
When the sizes of the fields in the structure change and because of this the very size of the structure changes, this is understandable and customary. Here is a different situation. The size of the fields remains the same, but due to different alignment rules, the size of the structure will still change (see Figure 28). This behavior can lead to a variety of errors, for example, incompatible formats of stored data.

Figure 28 - Schematic representation of structures and type alignment rules
Sometimes programmers use structures at the end of which is an array of variable size. This structure and memory allocation for it may look like this:
This code will work correctly in the 32-bit version, but its 64-bit version will fail.
When allocating the memory necessary for storing an object of the type MyPointersArray containing 5 pointers, it is necessary to take into account that the beginning of the m_arr array will be aligned along the 8 byte boundary. The location of data in memory on different systems (Win32 / Win64) is shown in Figure 29.

Figure 29 - The location of data in memory in a 32-bit and 64-bit system
Correct size calculation should look like this:
In the code above, we find out the offset of the last member of the structure and sum this offset with its size. The offset of a member of a structure or class can be found using the macro offsetof or FIELD_OFFSET. Always use these macros to obtain an offset in the structure, not relying on your assumptions about the size of types and the rules for their alignment.
When recompiling a program, another overloaded function may begin to be selected (see Figure 30).

Figure 30 - Choosing an overloaded function in a 32-bit and 64-bit system
Example problem:
The inaccurate programmer placed and then selected values of various types from the stack (ptrdiff_t and int). On a 32-bit system, their sizes coincided, everything worked fine. When the size of the ptrdiff_t type changed in a 64-bit program, more bytes began to fall on the stack than it was then retrieved.
The last example is devoted to errors in 32-bit programs that occur when they are executed in a 64-bit environment. The structure of 64-bit software systems will still include 32-bit modules for a long time, and therefore it is necessary to ensure their correct operation in a 64-bit environment. The WoW64 subsystem does its job very well, isolating a 32-bit application, and almost all 32-bit applications function correctly. However, sometimes errors still occur and are mainly related to the redirection mechanism when working with files and the Windows registry.
For example, in a complex consisting of 32-bit and 64-bit modules, their interaction should take into account that they use different views of the registry . Thus, in one of the programs, the following line in a 32-bit module became inoperable:
To make this program friend with other 64-bit parts, you need to enter the key KEY_WOW64_64KEY:
The best result when searching for the errors described in the article is given by the static code analysis method. As an example of a tool carrying out such an analysis, one can mention the Viva64 tool that we are developing, which is part of PVS-Studio .
Static defect search methods allow detecting defects using the source code of a program. In this case, the behavior of the program is evaluated on all paths of execution simultaneously. Due to this, it is possible to detect defects that manifest themselves only on unusual execution paths with rare input data. This feature allows you to add test methods, increasing the reliability of programs. Static analysis systems can be used to conduct source code audits, systematically eliminate defects in existing programs, and integrate into the development cycle, automatically detecting defects in generated code.
Example 16. Address arithmetic. A + B! = A - (-B)
Address arithmetic is a way to calculate the address of an object using pointer arithmetic, as well as the use of pointers in comparison operations. Address arithmetic is also called pointer arithmetic (pointer arithmetic).
')
A large percentage of 64-bit errors are associated with address arithmetic. Often errors occur in those expressions where pointers and 32-bit variables are used together.
Consider the first of the errors of this type:
char * A = "123456789"; unsigned B = 1; char * x = a + b; char * Y = A - (-B); if (X! = Y) cout << "Error" << endl;
The reason why in the Win32 program A + B == A - (-B) is shown in Figure 14.
Figure 14 - Win32: A + B == A - (-B)
The reason why in Win64 program A + B! = A - (-B) is shown in Figure 15.
Figure 15 - Win64: A + B! = A - (-B)
The error will be eliminated if you use the appropriate memsize-type . In this case, the ptrdfiff_t type is used:
char * A = "123456789"; ptrdiff_t B = 1; char * x = a + b; char * Y = A - (-B);
Example 17. Address arithmetic. Signed and unsigned types.
Consider another version of the error associated with the use of signed and unsigned types. This time the error will not lead to an incorrect comparison, but immediately to the fall of the application.
LONG p1 [100]; ULONG x = 5; LONG y = -1; LONG * p2 = p1 + 50; p2 = p2 + x * y; * p2 = 1; // Access violation
The expression "x * y" has the value 0xFFFFFFFB and is of type unsigned. The code compiled in the 32-bit version is efficient, since adding a pointer to 0xFFFFFFFB is equivalent to decreasing it by 5. In a 64-bit pointer, after adding 0xFFFFFFFB, it will start pointing far beyond the p1 array (see Figure 16).
Figure 16 - Going beyond the array
The fix is to use memsize types and work carefully with signed and unsigned types:
LONG p1 [100]; LONG_PTR x = 5; LONG_PTR y = -1; LONG * p2 = p1 + 50; p2 = p2 + x * y; * p2 = 1; // OK
Example 18. Address arithmetic. Overflow.
class Region {
float * array;
int Width, Height, Depth;
float Region :: GetCell (int x, int y, int z) const;
...
};
float Region :: GetCell (int x, int y, int z) const {
return array [x + y * Width + z * Width * Height];
} The code is taken from a real program of mathematical modeling, in which an important resource is the amount of RAM, and the ability to use more than 4 GB of memory on a 64-bit architecture significantly increases computational capabilities. In programs of this class, one-dimensional arrays are often used to save memory, working with them as with three-dimensional arrays. To do this, there are functions similar to GetCell that provide access to the necessary elements.
The code above works correctly with pointers if the value of the expression "x + y * Width + z * Width * Height" does not exceed INT_MAX (2147483647). Otherwise an overflow will occur that will lead to undefined behavior in the program.
Such code could always work correctly on a 32-bit platform. Within the framework of the 32-bit architecture, the program does not have enough memory to create an array of similar size. On the 64-bit architecture, this restriction is removed, and the size of the array can easily exceed INT_MAX elements.
Programmers often make a mistake trying to correct the code as follows:
float Region :: GetCell (int x, int y, int z) const {
return array [static_cast <ptrdiff_t> (x) + y * Width +
z * Width * Height];
}
They know that according to the rules of the C ++ language, the expression for calculating the index will be of type ptrdiff_t and hope to avoid overflow due to this. But overflow can occur inside the “y * Width” or “z * Width * Height” subexpression, since the int type is still used to calculate them.
If you want to correct the code without changing the types of variables involved in the expression, then you can explicitly cast each subexpression to the ptrdiff_t type:
float Region :: GetCell (int x, int y, int z) const {
return array [ptrdiff_t (x) +
ptrdiff_t (y) * Width +
ptrdiff_t (z) * Width * Height];
} Another more correct solution is to change the types of variables:
typedef ptrdiff_t TCoord;
class Region {
float * array;
TCoord Width, Height, Depth;
float Region :: GetCell (TCoord x, TCoord y, TCoord z) const;
...
};
float Region :: GetCell (TCoord x, TCoord y, TCoord z) const {
return array [x + y * Width + z * Width * Height];
} Example 19. Changing the type of array
Sometimes in programs for convenience change the type of the array during its processing. The dangerous and safe type conversion is presented in the following code:
int array [4] = {1, 2, 3, 4};
enum ENEPS {ZERO, ONE, TWO, THREE, FOUR};
// safe cast (for MSVC)
ENumbers * enumPtr = (ENumbers *) (array);
cout << enumPtr [1] << "";
// unsafe cast
size_t * sizetPtr = (size_t *) (array);
cout << sizetPtr [1] << endl;
// Output on 32-bit system: 2 2
// Output on 64-bit system: 2 17179869187 As you can see, the output of the program differs in the 32-bit and 64-bit versions. On a 32-bit system, access to the elements of the array is carried out correctly, since the sizes of the size_t and int types are the same, and we see the output "2 2".
On the 64-bit system, we got the output “2 17179869187”, since exactly the value 17179869187 is located in the 1st element of the sizetPtr array (see Figure 17). In some cases, this is exactly the behavior that is needed, but usually it is a mistake.
Figure 17 - Representation of array elements in memory
Note. The enum type in the Visual C ++ compiler by default is the same size as the int type, that is, it is a 32-bit type. Using enum of a different size is possible only with the help of an extension that is considered non-standard in Visual C ++. Therefore, the given example is correct in Visual C ++, but from the point of view of other compilers, casting a pointer to int elements to a pointer to enum elements may also be incorrect.
Example 20. Packing a pointer in 32-bit type
Sometimes in programs, pointers are stored in integer types. Typically, this type is used such as int. This is perhaps one of the most common 64-bit errors.
char * ptr = ...; int n = (int) ptr; ... ptr = (char *) n;
In a 64-bit program, this is incorrect, since the int type remains 32-bit and cannot store a 64-bit pointer in itself. Often this can not be noticed immediately. Due to coincidence, the pointer can always refer to objects located in the lower 4 gigabytes of the address space when testing. In this case, the 64-bit program will work successfully, and may unexpectedly refuse only after a long period of time (see Figure 18).
Figure 18 - Pointer in a variable of type int
If it is nevertheless necessary to place the pointer in an integer type variable, then such types as intptr_t , uintptr_t , ptrdiff_t, and size_t should be used.
Example 21. Memsize types in unions
When it becomes necessary to work with a pointer as an integer, it is sometimes convenient to use a union, as shown in the example, and work with a numeric representation of the type without using explicit casts:
union PtrNumUnion {
char * m_p;
unsigned m_n;
} u;
u.m_p = str;
u.m_n + = delta; This code is correct on 32-bit systems and incorrect on 64-bit ones. Changing the m_n member on the 64-bit system, we work only with a part of the m_p pointer (see Figure 19).
Figure 19 - Representation of combining in memory on a 32-bit and 64-bit system.
You should use a type that will match the pointer size:
union PtrNumUnion {
char * m_p;
uintptr_t m_n; // type fixed
} u; Example 22. Eternal cycle
The mixed use of 32-bit and 64-bit types can unexpectedly lead to eternal loops. Consider a synthetic example illustrating a whole class of similar defects:
size_t Count = BigValue;
for (unsigned Index = 0; Index! = Count; Index ++)
{...} This loop will never stop if the value of Count> UINT_MAX. Suppose that on 32-bit systems this code worked with the number of iterations less than the value UINT_MAX. But the 64-bit version of the program can process more data, and it may need more iterations. Since the values of the Index variable lie in the range [0..UINT_MAX], the “Index! = Count” condition is never fulfilled, which leads to an infinite loop (see Figure 20).
Figure 20 - The mechanism of the eternal cycle
Example 23. Work with bits and operation NOT
Working with bit operations requires special care from the programmer when developing cross-platform applications in which data types can have different sizes. Since the transfer of the program to the 64-bit platform also leads to a change in the dimension of some types, the probability of errors in sections of the code working with individual bits is high. Most often this is due to mixed work with 32-bit and 64-bit data types. Consider an error that occurred in the code due to incorrect use of the NOT operation:
UINT_PTR a = ~ UINT_PTR (0); ULONG b = 0x10; UINT_PTR c = a & ~ (b - 1); c = c | 0xFu; if (a! = c) cout << "Error" << endl;
The error is that the mask specified by the expression "~ (b - 1)" is of type ULONG. This leads to the zeroing of the high-order bits of the variable “a”; only the lower four bits should be reset (see Figure 21).
Figure 21 - Error due to clearing high bits
The revised code may look like this:
UINT_PTR c = a & ~ (UINT_PTR (b) - 1);
The given example is extremely simple, but it demonstrates well the class of errors that can occur during active work with bit operations.
Example 24. Work with bits, shifts
ptrdiff_t SetBitN (ptrdiff_t value, unsigned bitNum) {
ptrdiff_t mask = 1 << bitNum;
return value | mask;
} The code above is operable on a 32-bit architecture and allows setting the bit with numbers from 0 to 31 to one. After transferring the program to the 64-bit platform, it becomes necessary to set bits with numbers from 0 to 63. However, this code is unable to set the high bits, with numbers 32-63. Note that the numeric literal “1” is of type int, and when shifted to 32 positions an overflow will occur, as shown in Figure 22. We will get 0 (Figure 22-B) or 1 (Figure 22-C) - depends on compiler implementations.
Figure 22 - a) correct setting of the 31st bit in a 32-bit code (bits are counted from 0); b, c) - Error installing the 32nd bit on a 64-bit system (two options depending on the compiler)
To correct the code, it is necessary to make the constant “1” of the same type as the variable mask:
ptrdiff_t mask = static_cast <ptrdiff_t> (1) << bitNum;
Note also that an uncorrected code will result in another interesting error. When setting 31 bits on a 64-bit system, the result of the function operation will be 0xffffffff80000000 (see Figure 23). The result of the expression 1 << 31 is a negative number -2147483648. This number is represented in a 64-bit integer variable as 0xffffffff80000000.
Figure 23 - Error setting the 31st bit on a 64-bit system
Example 25. Bit handling and sign extension
The error given below is rare, but, unfortunately, quite complex in understanding. Therefore, we dwell on it a little more.
struct BitFieldStruct {unsigned short a: 15; unsigned short b: 13; }; BitFieldStruct obj; obj.a = 0x4000; size_t x = obj.a << 17; // Sign Extension printf ("x 0x% Ix \ n", x); // Output on 32-bit system: 0x80000000 // Output on 64-bit system: 0xffffffff80000000 In a 32-bit environment, the order of evaluation of the expression will look like that shown in Figure 24.
Figure 24 - Calculation of the expression “obj.a << 17” in 32-bit code
Note that when calculating the expression “obj.a << 17”, a significant extension of the unsigned short type to the int type occurs. More clearly, this can be demonstrated by the following code:
#include <stdio.h>
template <typename T> void PrintType (T)
{
printf ("type is% s% d-bit \ n",
(T) -1 <0? "signed": "unsigned", sizeof (T) * 8);
}
struct BitFieldStruct {
unsigned short a: 15;
unsigned short b: 13;
};
int main (void)
{
BitFieldStruct bf;
PrintType (bf.a);
PrintType (bf.a << 2);
return 0;
}
Result:
type is unsigned 16-bit
type is signed 32-bit Now let's see what the presence of the sign extension in the 64-bit code leads to. The sequence for evaluating an expression is shown in Figure 25.
Figure 25 - Calculation of the expression “obj.a << 17” in 64-bit code
A member of the obj.a structure is converted from an unsigned short bit field to an int. The expression “obj.a << 17” is of type int, but it is converted to ptrdiff_t and then to size_t before it is assigned to the variable addr. As a result, we get the number value 0xffffffff80000000, instead of the expected value 0x0000000080000000.
Be careful when working with bit fields. To prevent this situation in our example, it is enough to explicitly cast obj.a to size_t.
...
size_t x = static_cast <size_t> (obj.a) << 17; // OK
printf ("x 0x% Ix \ n", x);
// Output on 32-bit system: 0x80000000
// Output on 64-bit system: 0x80000000 Example 26. Serialization and data exchange
An important element of the transfer of software solutions to the new platform is the continuity to the existing data exchange protocols. It is necessary to ensure reading of the existing project formats, exchange data between 32-bit and 64-bit processes, and so on.
Basically, errors of this kind consist in the serialization of memsize types and data exchange operations using them:
size_t PixelsCount; fread (& PixelsCount, sizeof (PixelsCount), 1, inFile);
It is unacceptable to use types that change their size depending on the development environment in binary data exchange interfaces. In C ++, most types do not have a clear size and, therefore, they cannot all be used for these purposes. Therefore, the developers of the development tools and the programmers themselves create data types that have a strict size, such as __int8, __int16, INT32, word64, and so on.
Even after making corrections regarding type sizes, you may encounter incompatibilities in binary formats. The reason lies in a different view of the data. This is most often associated with another sequence of bytes.
Byte order is a method for writing bytes of multibyte numbers (see Figure 26). Order from junior to senior (born little-endian) - recording begins with the youngest and ends with the older. This recording order is adopted in the memory of personal computers with x86 and x86-64 -processors. Order from senior to junior (English big-endian) - recording begins with the senior and ends with the younger. This order is standard for TCP / IP protocols. Therefore, the byte order from high to low is often called network byte order (eng. Network byte order). This byte order is used by Motorola 68000, SPARC processors.
By the way, some processors can work in order from the youngest to the oldest, and vice versa. These include, for example, IA-64 .
Figure 26 - Byte order in 64-bit type on little-endian and big-endian systems
When developing a binary interface or data format, be aware of the sequence of bytes. And if the 64-bit system to which you are porting a 32-bit application has a different sequence of bytes, then you will simply have to take this into account in your code. To convert between network byte order (big-endian) and byte order (little-endian), you can use the functions htonl (), htons (), bswap_64, and so on .
Example 27. Changing type alignment
In addition to resizing some data types, errors can also occur due to changes in the rules for their alignment in a 64-bit system (see Figure 27).
Figure 27 - Dimensions types and their alignment boundaries (values are exact for Win32 / Win64, but can vary in the "Unix-world" and are given just as an example)
Consider an example of describing a problem found in one of the forums:
Faced today with one problem in Linux. There is a data structure consisting of several fields: 64-bit double, then 8 unsigned char and one 32-bit int. The total is 20 bytes (8 + 8 * 1 + 4). Under 32-bit systems, sizeof is 20 and everything works fine. And under 64-bit Linux, sizeof returns 24. That is, 64 bits are aligned.
Further in the forum there are arguments about the compatibility of data and the request of the council how to pack the data in the structure. But this is not interesting now. More interesting is the fact that there is another type of error that may occur when porting applications to a 64-bit system.
When the sizes of the fields in the structure change and because of this the very size of the structure changes, this is understandable and customary. Here is a different situation. The size of the fields remains the same, but due to different alignment rules, the size of the structure will still change (see Figure 28). This behavior can lead to a variety of errors, for example, incompatible formats of stored data.
Figure 28 - Schematic representation of structures and type alignment rules
Example 28. Type alignment and why you cannot write sizeof (x) + sizeof (y)
Sometimes programmers use structures at the end of which is an array of variable size. This structure and memory allocation for it may look like this:
struct MyPointersArray {
DWORD m_n;
PVOID m_arr [1];
} object;
...
malloc (sizeof (DWORD) + 5 * sizeof (PVOID));
... This code will work correctly in the 32-bit version, but its 64-bit version will fail.
When allocating the memory necessary for storing an object of the type MyPointersArray containing 5 pointers, it is necessary to take into account that the beginning of the m_arr array will be aligned along the 8 byte boundary. The location of data in memory on different systems (Win32 / Win64) is shown in Figure 29.
Figure 29 - The location of data in memory in a 32-bit and 64-bit system
Correct size calculation should look like this:
struct MyPointersArray {
DWORD m_n;
PVOID m_arr [1];
} object;
...
malloc (FIELD_OFFSET (struct MyPointersArray, m_arr) +
5 * sizeof (PVOID));
... In the code above, we find out the offset of the last member of the structure and sum this offset with its size. The offset of a member of a structure or class can be found using the macro offsetof or FIELD_OFFSET. Always use these macros to obtain an offset in the structure, not relying on your assumptions about the size of types and the rules for their alignment.
Example 29. Overloaded functions
When recompiling a program, another overloaded function may begin to be selected (see Figure 30).
Figure 30 - Choosing an overloaded function in a 32-bit and 64-bit system
Example problem:
class MyStack {
...
public:
void Push (__ int32 &);
void Push (__ int64 &);
void Pop (__ int32 &);
void Pop (__ int64 &);
} stack;
ptrdiff_t value_1;
stack.Push (value_1);
...
int value_2;
stack.Pop (value_2); The inaccurate programmer placed and then selected values of various types from the stack (ptrdiff_t and int). On a 32-bit system, their sizes coincided, everything worked fine. When the size of the ptrdiff_t type changed in a 64-bit program, more bytes began to fall on the stack than it was then retrieved.
Example 30. Errors in 32-bit modules working in WoW64
The last example is devoted to errors in 32-bit programs that occur when they are executed in a 64-bit environment. The structure of 64-bit software systems will still include 32-bit modules for a long time, and therefore it is necessary to ensure their correct operation in a 64-bit environment. The WoW64 subsystem does its job very well, isolating a 32-bit application, and almost all 32-bit applications function correctly. However, sometimes errors still occur and are mainly related to the redirection mechanism when working with files and the Windows registry.
For example, in a complex consisting of 32-bit and 64-bit modules, their interaction should take into account that they use different views of the registry . Thus, in one of the programs, the following line in a 32-bit module became inoperable:
lRet = RegOpenKeyEx (HKEY_LOCAL_MACHINE, "SOFTWARE \\ ODBC \\ ODBC.INI \\ ODBC Data Sources", 0, KEY_QUERY_VALUE, & hKey);
To make this program friend with other 64-bit parts, you need to enter the key KEY_WOW64_64KEY:
lRet = RegOpenKeyEx (HKEY_LOCAL_MACHINE, "SOFTWARE \\ ODBC \\ ODBC.INI \\ ODBC Data Sources", 0, KEY_QUERY_VALUE | KEY_WOW64_64KEY, & hKey);
Conclusion
The best result when searching for the errors described in the article is given by the static code analysis method. As an example of a tool carrying out such an analysis, one can mention the Viva64 tool that we are developing, which is part of PVS-Studio .
Static defect search methods allow detecting defects using the source code of a program. In this case, the behavior of the program is evaluated on all paths of execution simultaneously. Due to this, it is possible to detect defects that manifest themselves only on unusual execution paths with rare input data. This feature allows you to add test methods, increasing the reliability of programs. Static analysis systems can be used to conduct source code audits, systematically eliminate defects in existing programs, and integrate into the development cycle, automatically detecting defects in generated code.
Bibliographic list
- Andrey Karpov, Evgeny Ryzhkov. Lessons learned from developing 64-bit C / C ++ applications. http://www.viva64.com/en/articles/x64-lessons/
- Andrey Karpov. What is size_t and ptrdiff_t. http://www.viva64.com/art-1-1-72510946.html
- Andrey Karpov, Evgeny Ryzhkov. 20 issues of porting C ++ code on a 64-bit platform. http://www.viva64.com/art-1-1-1958348565.html
- Yevgeny Ryzhkov. Tutorial on PVS-Studio. http://www.viva64.com/art-4-1-1796251700.html
- Andrey Karpov. 64-bit horse that can count. http://www.viva64.com/art-1-1-1064884779.html
Source: https://habr.com/ru/post/97810/
All Articles