Distributed computing on the .NET platform
The widespread use of parallel computing architectures is raising interest in software development tools that can make the most of the hardware resources of this type.
However, by the current moment there is a certain gap between the technologies of hardware implementation of parallelism available in the consumer market and the software tools for their support. So, if multi-core general-purpose computers became the norm in the middle of this decade, the emergence of OpenMP — the popular standard for developing programs for such systems — was noted almost ten years earlier [1]. At almost the same time, the MPI standard appeared, describing ways to transfer messages between processes in a distributed environment [2].
The development of both these standards, which is expressed only in extending the functionality without adapting paradigms to the object-oriented approach, leads to the fact that they are incompatible with modern programming platforms such as the Microsoft .NET Framework. Therefore, the developers of these platforms have to make additional efforts to introduce concurrency tools into their products.
')
In [3], the author reviewed one of these technologies, Microsoft Parallel Extensions, which allows a fairly simple way to implement parallelism in initially sequential managed code for computers with shared memory. The opportunity and expediency of using the .NET Framework platform for scientific calculations was also shown there. Nevertheless, it remains an open question about the applicability of this platform for developing programs used for carrying out complex calculations on systems with distributed memory, for example, computational clusters. These systems are based on a set of interconnected computing nodes, each of which is a full-fledged computer with its own processor, memory, input / output subsystem, operating system, each node operating in its own address space.
MPI supports the Fortran and C languages. The MPI program is a set of parallel interacting processes. All processes are generated once, forming a parallel part of the program. Each process operates in its own address space; there are no shared variables or data in MPI. The main way to communicate between processes is to send messages from one process to another. [four]
Despite the fact that MPI programs show a high level of performance, the technology itself has several disadvantages:
Nevertheless, starting from the third version, the .NET Framework includes the Windows Communication Foundation (WCF) - a unified technology for creating all types of distributed applications on the Microsoft platform [5]. Unfortunately, this technology is often understood only as a framework for working with Web services based on XML, which in vain prevents us from considering WCF as an effective means for organizing parallel computing.
In order for the client to transmit information to the service, he must know “APK”: address, linkage and contract.
The address determines where to send the messages so that the endpoint receives them.
A binding defines a channel for communications with an endpoint. All messages circulating in the WCF application are transmitted through the channels. A channel consists of several binding elements. At the lowest level, the binding element is a transport mechanism that provides message delivery over the network. The binding elements located above describe the requirements for security and transactional integrity. WCF comes with a set of pre-made bindings. For example, the basicHttpBinding binding is applicable to access most Web services created before 2007; The netTcpBinding binding implements high-speed TCP data exchange for communications between two .NET systems; netNamedPipeBinding is intended for communications within a single machine or between several .NET systems. Building applications for work in peer-to-peer networks is also supported; for this, there is a netPeerTcpBinding binding.
The contract defines the set of functions provided by the endpoint, that is, the operations that it can perform, and the message formats for these operations. The operations described in the contract are mapped to the methods of the class implementing the endpoint, and in particular include the types of parameters passed to and received from each method. WCF supports synchronous and asynchronous, one-way and full-duplex operations with arbitrary data types, which is sufficient for building distributed applications based on the .NET Framework to solve large computational problems. However, the information provided does not help assess the practical applicability and effectiveness of WCF technology in this case.
To illustrate the possibilities, as well as assessing the complexity of developing applications for computational problems using WCF, it is proposed to implement with it some demonstration algorithms described on the official MPI resource [6].
To test the performance of solutions, two computers with four and two processor cores of equal performance are used, respectively. Communication is carried out via a 100Mbit Ethernet network. WCF testing is performed on Microsoft Windows 7, Pelican HPC [7] is used to build MPI cluster on Linux 2.6.30 kernel using Open MPI 1.3.3.
Its operation requires the presence of two MPI-processes, between which there is an exchange of arrays of double-type elements with sizes from 1 to 1048576 elements using the commands MPI_Recv () and MPI_Ssend. It is worth noting the impact of the previously mentioned disadvantages of MPI:
The following describes a class that implements the logic of the server application, which receives an array of real numbers from the client application and sends it back:
The main method of the server application, registering the APK, is implemented. At the same time, the behavior of the server application can be configured according to the settings both in the code and in the .config file of the application.
The client application looks like this, where the CallBackHandler class implements the corresponding interface described earlier, and the Client class provides a static method that acts as an entry point:
The program performs several iterations, each of which consists in calling the remote SendArray method with passing it an array of data and waiting for the SendArrayFromServer method call, which receives the data returned from the server.
The code presented has several important advantages regarding MPI, namely:

From this table it follows that, unfortunately, WCF technology is not suitable for developing programs that require frequent inter-process data exchange of small volume.
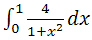 . It is very easy to detect the parallelism of this algorithm: the integration interval is divided into as many parts as the computational nodes will be involved in the calculations. A C ++ program for MPI that solves the problem is as follows:
. It is very easy to detect the parallelism of this algorithm: the integration interval is divided into as many parts as the computational nodes will be involved in the calculations. A C ++ program for MPI that solves the problem is as follows:
The code is rather laconic, however, all MPI disadvantages listed above are peculiar to it. For WCF, the server part in C # looks like this:
Allocation of the server part not only facilitates the understanding of the code, but also makes it possible to reuse it without being tied to any particular client. The client itself can be implemented as follows (the remote CalculatePiChunk method is called asynchronously with its own set of parameters on each computational node):
The results of performance measurements are presented below:
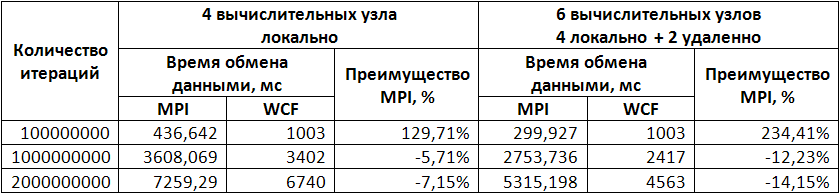
According to these results, it can be judged that the use of the WCF technology of the .NET Framework for building distributed computing applications with a small number of interprocess communications shows good results: the relatively low data exchange rate is compensated for by the qualitative optimization of the JIT code [3] in such a way that .NET managed the program in many situations turns out to be more productive.
Based on the results of the brief testing, the following conclusions can be made:
LITERATURE
1. OpenMP Reference. OpenMP Architecture Review Board, 2008 r.
2. MPI 2.1 Reference. University of Tennessee, 2008 r.
3. Parallel programming in .NET. Tikhonov, I. V. Irkutsk, 2009. Proceedings of the XIV Baikal All-Russian Conference "Information and Mathematical Technologies in Science and Management."
4. Antonov, A. S. Parallel programming using MPI technology. M .: Publishing House of Moscow State University.
5. Resnick, Steve, Crane, Richard and Bowen, Chris. Basics of Windows Communication Foundation for .NET Framework 3.5. M .: DMK Press, 2008.
6. The Message Passing Interface (MPI) standard. www.mcs.anl.gov/research/projects/mpi
7. PelicanHPC GNU Linux. pareto.uab.es/mcreel/PelicanHPC
However, by the current moment there is a certain gap between the technologies of hardware implementation of parallelism available in the consumer market and the software tools for their support. So, if multi-core general-purpose computers became the norm in the middle of this decade, the emergence of OpenMP — the popular standard for developing programs for such systems — was noted almost ten years earlier [1]. At almost the same time, the MPI standard appeared, describing ways to transfer messages between processes in a distributed environment [2].
The development of both these standards, which is expressed only in extending the functionality without adapting paradigms to the object-oriented approach, leads to the fact that they are incompatible with modern programming platforms such as the Microsoft .NET Framework. Therefore, the developers of these platforms have to make additional efforts to introduce concurrency tools into their products.
')
In [3], the author reviewed one of these technologies, Microsoft Parallel Extensions, which allows a fairly simple way to implement parallelism in initially sequential managed code for computers with shared memory. The opportunity and expediency of using the .NET Framework platform for scientific calculations was also shown there. Nevertheless, it remains an open question about the applicability of this platform for developing programs used for carrying out complex calculations on systems with distributed memory, for example, computational clusters. These systems are based on a set of interconnected computing nodes, each of which is a full-fledged computer with its own processor, memory, input / output subsystem, operating system, each node operating in its own address space.
MPI. Main idea and disadvantages
In the world of functional programming, the most common technology for creating programs for parallel computers of this type is MPI. The main way of interaction between parallel processes in this case is the transfer of messages from one node to another. The MPI standard fixes the interface that must be followed by both the programming system on each computing platform and the user when creating their own programs.MPI supports the Fortran and C languages. The MPI program is a set of parallel interacting processes. All processes are generated once, forming a parallel part of the program. Each process operates in its own address space; there are no shared variables or data in MPI. The main way to communicate between processes is to send messages from one process to another. [four]
Despite the fact that MPI programs show a high level of performance, the technology itself has several disadvantages:
- low level (MPI programming is often compared with programming in assembler), the need for detailed control over the distribution of arrays and turns of cycles between processes, as well as the exchange of messages between processes — all this leads to a high complexity of program development;
- the need for excessive specification of data types in the transmitted messages, as well as the presence of strict restrictions on the types of data transmitted;
- the complexity of writing programs that can be performed with an arbitrary size of arrays and an arbitrary number of processes makes it almost impossible to reuse existing MPI programs;
- lack of support for an object-oriented approach.
Nevertheless, starting from the third version, the .NET Framework includes the Windows Communication Foundation (WCF) - a unified technology for creating all types of distributed applications on the Microsoft platform [5]. Unfortunately, this technology is often understood only as a framework for working with Web services based on XML, which in vain prevents us from considering WCF as an effective means for organizing parallel computing.
WCF structure
To determine whether WCF can be used as a development tool for distributed memory systems, consider the basics of this technology. WCF service is a set of endpoints that provide clients with some useful features. The endpoint is simply a network resource to which you can send messages. To take advantage of the opportunities offered, the client sends messages to the endpoints in a format that is described by a contract between the client and the service. Services expect messages to be delivered to the endpoint address, assuming messages will be recorded in the specified format.In order for the client to transmit information to the service, he must know “APK”: address, linkage and contract.
The address determines where to send the messages so that the endpoint receives them.
A binding defines a channel for communications with an endpoint. All messages circulating in the WCF application are transmitted through the channels. A channel consists of several binding elements. At the lowest level, the binding element is a transport mechanism that provides message delivery over the network. The binding elements located above describe the requirements for security and transactional integrity. WCF comes with a set of pre-made bindings. For example, the basicHttpBinding binding is applicable to access most Web services created before 2007; The netTcpBinding binding implements high-speed TCP data exchange for communications between two .NET systems; netNamedPipeBinding is intended for communications within a single machine or between several .NET systems. Building applications for work in peer-to-peer networks is also supported; for this, there is a netPeerTcpBinding binding.
The contract defines the set of functions provided by the endpoint, that is, the operations that it can perform, and the message formats for these operations. The operations described in the contract are mapped to the methods of the class implementing the endpoint, and in particular include the types of parameters passed to and received from each method. WCF supports synchronous and asynchronous, one-way and full-duplex operations with arbitrary data types, which is sufficient for building distributed applications based on the .NET Framework to solve large computational problems. However, the information provided does not help assess the practical applicability and effectiveness of WCF technology in this case.
WCF Performance Evaluation Method
We will assess the applicability of WCF from the following positions:- The possibility and complexity of developing distributed applications for solving computational problems.
- The efficiency of data exchange between components of a distributed application.
- Overall performance of distributed computing using WCF.
To illustrate the possibilities, as well as assessing the complexity of developing applications for computational problems using WCF, it is proposed to implement with it some demonstration algorithms described on the official MPI resource [6].
To test the performance of solutions, two computers with four and two processor cores of equal performance are used, respectively. Communication is carried out via a 100Mbit Ethernet network. WCF testing is performed on Microsoft Windows 7, Pelican HPC [7] is used to build MPI cluster on Linux 2.6.30 kernel using Open MPI 1.3.3.
Simple information sharing program
The simplest test, designed to show the efficiency of data exchange between components of a computer network, is to send an array of double-valued real numbers from one node to another and back with fixing the time taken to perform these operations. The code in C ++ for MPI is as follows:#define NUMBER_OF_TESTS 10
int main( argc, argv )
int argc;
char **argv;
{
double *buf;
int rank, n, j, k, nloop;
double t1, t2, tmin;
MPI_Status status;
MPI_Init( &argc, &argv );
MPI_Comm_rank( MPI_COMM_WORLD, &rank );
if (rank == 0)
printf( "Kind\t\tn\ttime (sec)\tRate (MB/sec)\n" );
for (n=1; n<1100000; n*=2) {
if (n == 0) nloop = 1000;
else nloop = 1000/n;
if (nloop < 1) nloop = 1;
buf = (double *) malloc( n * sizeof(double) );
tmin = 1000;
for (k=0; k<NUMBER_OF_TESTS; k++) {
if (rank == 0) {
t1 = MPI_Wtime();
for (j=0; j<nloop; j++) {
MPI_Ssend( buf, n, MPI_DOUBLE, 1, k, MPI_COMM_WORLD );
MPI_Recv( buf, n, MPI_DOUBLE, 1, k, MPI_COMM_WORLD,
&status );
}
t2 = (MPI_Wtime() - t1) / nloop;
if (t2 < tmin) tmin = t2;
}
else if (rank == 1) {
for (j=0; j<nloop; j++) {
MPI_Recv( buf, n, MPI_DOUBLE, 0, k, MPI_COMM_WORLD,
&status );
MPI_Ssend( buf, n, MPI_DOUBLE, 0, k, MPI_COMM_WORLD );
}
}
}
if (rank == 0) {
double rate;
if (tmin > 0) rate = n * sizeof(double) * 1.0e-6 /tmin;
else rate = 0.0;
printf( "Send/Recv\t%d\t%f\t%f\n", n, tmin, rate );
}
free( buf );
}
MPI_Finalize( );
return 0;
}
Its operation requires the presence of two MPI-processes, between which there is an exchange of arrays of double-type elements with sizes from 1 to 1048576 elements using the commands MPI_Recv () and MPI_Ssend. It is worth noting the impact of the previously mentioned disadvantages of MPI:
- The separation of the functionality of both processes is based solely on the process number (rank), which complicates the perception of the listing program.
- Before sending data (MPI_Ssend), you need to be sure that the receiving party has explicitly initialized their reception (MPI_Recv), which complicates the development process.
- The specification of the types of transmitted data (MPI_DOUBLE) together with the data itself is rational from the rational point of view, which can also lead to logical errors in the program.
- In addition, the unpleasant moment associated with the organization of a programming language is the need to manually allocate and free memory.
[ServiceContract(CallbackContract = typeof(IClientCallback))] public interface IServerBenchmark
{
[OperationContract(IsOneWay = true)] void SendArray(double[] array);
}
public interface IClientCallback
{
[OperationContract(IsOneWay = true)] void SendArrayFromServer(double[] array);
}
The following describes a class that implements the logic of the server application, which receives an array of real numbers from the client application and sends it back:
public class ServerBenchmark : IServerBenchmark
{
public void SendArray(double[] array)
{
OperationContext.Current.GetCallbackChannel<IClientCallback>().SendArrayFromServer(array);
}
}
The main method of the server application, registering the APK, is implemented. At the same time, the behavior of the server application can be configured according to the settings both in the code and in the .config file of the application.
class Program
{
static void Main(string[] args)
{
ServiceHost serviceHost = new ServiceHost();
NetTcpBinding binding = new NetTcpBinding();
serviceHost.AddServiceEndpoint(typeof(IServerBenchmark), binding, "");
serviceHost.Open();
Console.ReadLine();
serviceHost.Close();
}
}
The client application looks like this, where the CallBackHandler class implements the corresponding interface described earlier, and the Client class provides a static method that acts as an entry point:
public class CallbackHandler : IServerBenchmarkCallback
{
private static EventWaitHandle _waitHandle = new EventWaitHandle(false, EventResetMode.AutoReset);
static int _totalIterations = 10;
public static DateTime _dateTime;
public void SendArrayFromServer(double[] array)
{
_waitHandle.Set();
}
class Client
{
private static InstanceContext _site;
static void Main(string[] args)
{
_site = new InstanceContext(new CallbackHandler());
ServerBenchmarkClient client = new ServerBenchmarkClient(_site);
double[] arr = new double[Convert.ToInt32(args[0])];
for (int index = 0; index < arr.Length;index++ )
arr[index] = index;
_dateTime = DateTime.Now;
for (int index = 0; index < _totalIterations; index++)
{
client.SendArray(arr);
_waitHandle.WaitOne();
}
Console.WriteLine((DateTime.Now - _dateTime).TotalMilliseconds / _totalIterations);
Console.ReadKey();
}
}
}
The program performs several iterations, each of which consists in calling the remote SendArray method with passing it an array of data and waiting for the SendArrayFromServer method call, which receives the data returned from the server.
The code presented has several important advantages regarding MPI, namely:
- Uniform and one-time description of the formats of the transmitted data, implemented in the interface (contract).
- A simple implementation of calling remote methods.
- Using an object-oriented approach to development.
From this table it follows that, unfortunately, WCF technology is not suitable for developing programs that require frequent inter-process data exchange of small volume.
An example of distributed computing
Let us now consider the possibility of building a distributed application that does not require active data exchange between nodes. Let's take one more example from the resource [6] - the calculation of the number Pi. In this example, Pi is calculated as . It is very easy to detect the parallelism of this algorithm: the integration interval is divided into as many parts as the computational nodes will be involved in the calculations. A C ++ program for MPI that solves the problem is as follows:int main(argc,argv)
int argc;
char *argv[];
{
int done = 0, n, myid, numprocs, i;
double PI25DT = 3.141592653589793238462643;
double mypi, pi, h, sum, x;
MPI_Init(&argc,&argv);
MPI_Comm_size(MPI_COMM_WORLD,&numprocs);
MPI_Comm_rank(MPI_COMM_WORLD,&myid);
while (!done)
{
if (myid == 0) {
printf("Enter the number of intervals: (0 quits) ");
scanf("%d",&n);
}
MPI_Bcast(&n, 1, MPI_INT, 0, MPI_COMM_WORLD);
if (n == 0) break;
h = 1.0 / (double) n;
sum = 0.0;
for (i = myid + 1; i <= n; i += numprocs) {
x = h * ((double)i - 0.5);
sum += 4.0 / (1.0 + x*x);
}
mypi = h * sum;
MPI_Reduce(&mypi, &pi, 1, MPI_DOUBLE, MPI_SUM, 0,
MPI_COMM_WORLD);
if (myid == 0)
printf("pi is approximately %.16f, Error is %.16f\n",
pi, fabs(pi - PI25DT));
}
MPI_Finalize();
return 0;
}
The code is rather laconic, however, all MPI disadvantages listed above are peculiar to it. For WCF, the server part in C # looks like this:
[ServiceContract] public interface IPiService
{
[OperationContract] double CalculatePiChunk(int intervals, int processId, int processesCount);
}
public class PiService : IPiService
{
public double CalculatePiChunk(int intervals, int processId, int processesCount)
{
double h = 1.0 / (double)intervals;
double sum = 0.0;
double x;
for (int i = processId + 1; i <= intervals; i += processesCount)
{
x = h * (i - 0.5);
sum += 4.0 / (1.0 + x * x);
}
return h * sum;
}
}
public class Service
{
public static void Main(string[] args)
{
ServiceHost serviceHost = new ServiceHost(typeof(PiService));
serviceHost.AddServiceEndpoint(typeof(IPiService), new NetTcpBinding(), "");
serviceHost.Open();
Console.ReadLine();
serviceHost.Close();
}
}
Allocation of the server part not only facilitates the understanding of the code, but also makes it possible to reuse it without being tied to any particular client. The client itself can be implemented as follows (the remote CalculatePiChunk method is called asynchronously with its own set of parameters on each computational node):
class Client
{
private static double _pi;
private static DateTime _startTime;
static int _inProcess = 0;
static void Main(string[] args)
{
_pi = 0;
int intervals = Convert.ToInt32(args[0]);
List<String> endPoints = new List<string>();
for (int index = 1; index<args.Length;index++)
endPoints.Add(args[index]);
double pi = 0;
_inProcess = endPoints.Length;
PiServiceClient[] clients = new PiServiceClient[endPoints.Length];
for (int index = 0; index < endPoints.Length; index++)
clients[index] = new PiServiceClient("NetTcpBinding_IPiService", "net.tcp://" + endPoints[index] + "/EssentialWCF");
_startTime = DateTime.Now;
for (int index = 0; index< endPoints.Length; index++)
clients[index].BeginCalculatePiChunk(intervals, index, endPoints.Length, GetPiCallback, clients[index]);
Console.ReadKey();
}
static void GetPiCallback(IAsyncResult ar)
{
double d = ((PiServiceClient)ar.AsyncState).EndCalculatePiChunk(ar);
lock(ar)
{
_pi += d;
_inProcess--;
if (_inProcess == 0)
{
Console.WriteLine(_pi);
Console.WriteLine("Calculation ms elasped: " + (DateTime.Now - _startTime).TotalMilliseconds);
}
}
}
}
The results of performance measurements are presented below:
According to these results, it can be judged that the use of the WCF technology of the .NET Framework for building distributed computing applications with a small number of interprocess communications shows good results: the relatively low data exchange rate is compensated for by the qualitative optimization of the JIT code [3] in such a way that .NET managed the program in many situations turns out to be more productive.
Based on the results of the brief testing, the following conclusions can be made:
- Developing applications on the .NET Framework to solve computational problems on systems with distributed memory is possible.
- WCF technology, designed to build applications of this kind, provides a much simpler way of interprocess communication than is implemented in MPI.
- In turn, this simplicity leads to a significant drop in the performance of data exchange processes: in some cases, MPI is faster than WCF by more than two and a half times.
- Thus, WCF is not suitable for solving problems that require intensive exchange of small groups of data between computing nodes.
- However, the use of this technology is justified in the case of more rare interprocess communication: in addition to a simpler development method compared to MPI, the .NET Framework provides other benefits for organizing scientific computing, such as the interoperability of the resulting programs, automatic memory management, interlanguage interaction, functional support. programming. [3]
LITERATURE
1. OpenMP Reference. OpenMP Architecture Review Board, 2008 r.
2. MPI 2.1 Reference. University of Tennessee, 2008 r.
3. Parallel programming in .NET. Tikhonov, I. V. Irkutsk, 2009. Proceedings of the XIV Baikal All-Russian Conference "Information and Mathematical Technologies in Science and Management."
4. Antonov, A. S. Parallel programming using MPI technology. M .: Publishing House of Moscow State University.
5. Resnick, Steve, Crane, Richard and Bowen, Chris. Basics of Windows Communication Foundation for .NET Framework 3.5. M .: DMK Press, 2008.
6. The Message Passing Interface (MPI) standard. www.mcs.anl.gov/research/projects/mpi
7. PelicanHPC GNU Linux. pareto.uab.es/mcreel/PelicanHPC
Source: https://habr.com/ru/post/97292/
All Articles