Comparing OpenCL with CUDA, GLSL and OpenMP

At Habré, they already talked about what OpenCL is and why it is needed, but this standard is relatively new, so I wonder how the performance of the programs on it relates to other solutions.
This topic compares OpenCL with CUDA and shaders for the GPU, as well as with OpenMP for the CPU.
Testing was conducted on the task of N-bodies . It fits well with the parallel architecture, the complexity of the problem grows as O (N 2 ), where N is the number of bodies.
Task
As a test, the problem of simulating the evolution of a particle system was chosen.
The screenshots (they are clickable) show the problem of N point charges in a static magnetic field. In terms of computational complexity, it is no different from the classical N-body problem (unless the pictures are not so beautiful).
')
During the measurements, the display was turned off, and FPS means the number of iterations per second (each iteration is the next step in the evolution of the system).


results
GPU
The GLSL and CUDA code for this task has already been written by UNN staff.
NVidia Quadro FX5600
Driver Version 197.45
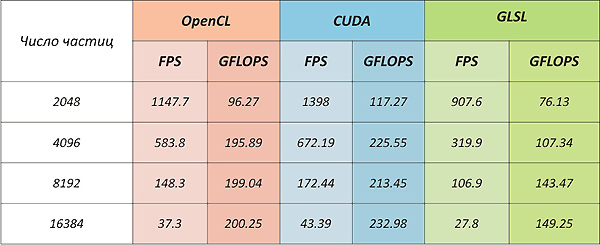
CUDA overtakes OpenCL by about 13%. At the same time, if we estimate the theoretically possible performance for this task for a given architecture, the implementation at CUDA reaches it.
( A Performance Comparison of CUDA and OpenCL states that OpenCL core performance loses CUDA from 13% to 63%)
Despite the fact that the tests were conducted on a Quadro series card, it is clear that the usual GeForce 8800 GTS or GeForce 250 GTS will give similar results (all three cards are based on the G92 chip).
Radeon HD4890
ATI Stream SDK version 2.01
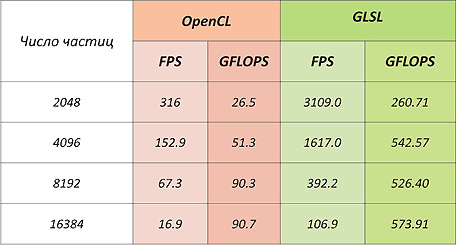
OpenCL loses the shaders on the cards from AMD because the computational blocks on them have the VLIW architecture , which (after optimization) many shader programs can do well for, but the compiler for the OpenCL code (which is part of the driver) does not do well with the optimization.
Also, this very modest result may be caused by the fact that AMD cards do not support local memory at the physical level, but instead map the local memory area to the global one.
CPU
The code using OpenMP was compiled using compilers from Intel and Microsoft.
Intel did not release its drivers for running OpenCL code on the central processor, so the ATI Stream SDK was used.
Intel Core2Duo E8200
ATI Stream SDK version 2.01
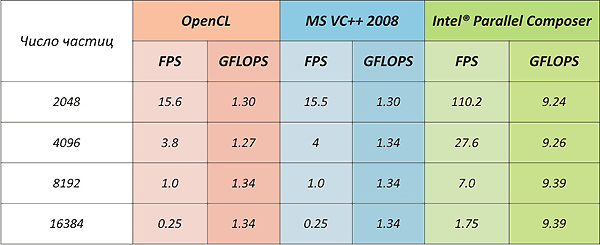
OpenMP code compiled with MS VC ++ has almost identical performance with OpenCL.
This is despite the fact that Intel did not release its driver for interpreting OpenCL, and uses a driver from AMD.
The compiler from Intel did not quite "honestly"; it completely unfolded the main program loop, repeating it about 8k times (the number of particles was specified by a constant in the code) and received a sevenfold performance increase also through the use of SSE instructions. But the winners, of course, are not judged.
Which is characteristic, the code also started on my old AMD Athlon 3800+, but of course there are no such outstanding results as on Intel.
Conclusion
- At the moment, the drivers are not fully developed, and there are situations when something is in the standard and cannot be used in real code. (For example, texture support in OpenCL programs appeared in ATI cards only from the HD5xxx series).
- Drivers do not generate the optimal code for this particular platform, in this regard, manufacturers have much to develop.
- Writing on OpenCL is almost the same as writing on the CUDA Driver API.
- It seems to be more features, but not always convenient. A sort of tail line appears in 300, which necessarily reaches for any of your programs. This is a fee for the fact that your code can be run on virtually any device designed for parallel computing.
- Already, programs on OpenCL show decent performance compared to competitors and can be successfully used for parallel general-purpose computing. And for a real Jedi, you see, 300 lines of code is not a hindrance, especially since they can be transferred to a separate library.
Thank you
The code was written, measurements were made and the results were also interpreted by the postgraduate student of the NNSU VMK Bogolepov Denis and the student of the NSTU IRIT Maxim Zakharov.
Thanks to them.
Source: https://habr.com/ru/post/96122/
All Articles