Cloud Accounting
The words "cloud", "cloud computing", "cloud" are used for anything. New buzzword, buzzword. We see "cloud antivirus", "cloud blade server." Even eminent vendors of network equipment do not hesitate to expose switches with the label “for cloud computing”. This causes instinctual hostility, roughly, as “organic” food.
Any techie who tries to deal with the technologies underlying the "cloud", after a few hours of dealing with the flow of advertising enthusiasm, will discover that these clouds are the same VDSs, side view. He will be right. Clouds, as they are done now, are ordinary virtual machines.
However, clouds are not only marketing and renamed VDS. The word “cloud” (or, more precisely, the phrase “cloud computing”) has its own technical truth. It is not as pathetic and delightfully innovative as marketers say, but it does exist. It was invented many decades ago, but only now the infrastructure (first of all, the Internet and x86 virtualization technologies) has grown to a level that allows it to be implemented on a massive scale.
')
So, first about the cause, which generally spawned the need for clouds:
Here is what the provided service looks like for a regular VDS (any resource can be in the place of this graphic: processor, memory, disk):
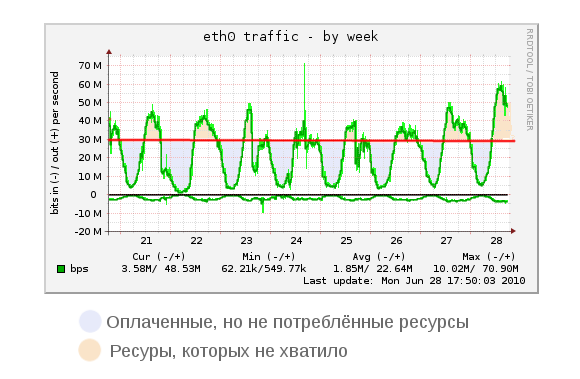
Please note: this is a weekly schedule. Existing technologies of a temporary increase in the resource consumption limit (burst, grace period) are not able to solve this problem at such long intervals. Those. a machine receives less resources when it needs them most.
The second problem - look at the huge intervals (blue), when resources, in fact, had to be paid, but could not be used. A virtual machine at night just does not need as many resources. She is idle. And despite this - the owner pays to the full.
There is a problem: a person is forced to order more resources than they need on average in order to experience peaks without problems. The rest of the time the resources are idle. The provider sees that the server is not loaded, begins to sell more resources than it is (this is called an "oversell"). At some point, for example, due to the peak load on several clients, the provider violates its obligations. He promised 70 people at 1GHz - but he only has 40 (2.5 * 16 cores). Not good.
It is unprofitable to sell the lane honestly (without an overcell) (and prices are non-market). Oversell - reduce the quality of service, violate the terms of the contract.
This problem is not related to VDS or virtualization, it’s a common question: how to honestly sell idle resources?
The answer to this problem was the idea of "cloud computing". The words are fashionable, but their basis goes back to the times of large mainframes, when machine time was sold.
Cloud computing does the same thing - instead of limits and quotas, which are paid regardless of real consumption, users are given the opportunity to use resources without restriction, with payment of real consumption (and only that which was actually used). This is the essence of the "cloud".
Instead of selling “500 MHz 500 MB of memory of a 3 GB disk”, the user (more precisely, his virtual machine) is given everything she needs. As much as needs.
Do you have a peak in resource consumption before March 8, and then the low season? Or you just can not predict when you will have these peaks? Instead of seeking a compromise between lags and money to the wind, a different payment model is proposed: what is consumed is paid.
Machine time is taken into account (it can be counted in ticks, but ideologically it’s more appropriate to do it in the old style: count seconds of machine time), of course, if you have threshed 3 cores with 50% load, this is one and a half seconds of machine time per second. If you have a download of 3%, then in a minute you will spend only 2s of computer time.
Memory is allocated "on demand" - and is limited only by the capabilities of the hoster and your greed. It is also paid on a time-based basis - a megabyte of memory costs so much per second. (in fact, on the old VDS it was, you paid “megabytes per month”, but they were idle most of the time).
Disk space is also allocated on demand - pay per megabyte per second. If you needed a place for a temporary dump on a terabyte, you do not need to pay a terabyte for a whole month - just an hour and a half is enough (the main thing is not to forget to erase the excess).
Disk space is a complex resource: it is not only “storage”, but also “access”. Payment is taken both for the space consumed (megabyte-seconds), for iops (pieces), and for the amount of written-read. Each component costs money. Since money is taken three times for one resource, the price is, in fact, divided into three.
And here the interesting begins: the person who put the files, but does not touch them, pays less than the one who actively uses them to give to the client. And the use can be different - I read it ten times a megabyte "and" read ten times a kilobyte "- there is a difference. interspersed with the recording ...
The pay-as-you-go model is the most honest one, both for the consumer and for the service provider: the consumer only pays for what he consumes, but the supplier no longer feels irritated by fatty customers who survive all resources. Consumed resource - sold resource. Moreover, the reverse principle also applies: an unused resource is not paid. If the hoster has failed to provide all the processor "according to need" (a congestion has arisen), then it is trivial, without trial and swearing, without long correspondence, automatically losing money, because it sold less than they wanted to buy. Clients, although they feel unpleasant because of the congestion, will receive at least satisfaction - they will pay less for this time ... This congestion problem has an even more beautiful, cloudy solution, but about it next time.
For example, a graph of memory usage. Please note - orange areas are areas that will not just “slow down”, but areas where oom_killer will work. With all that it implies. If the payment was on consumption, then these peaks would cost not so much, but would allow to solve the "peak" situation without any problems.
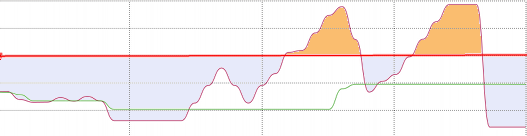
And look again, again huge idle resources that absolutely do not want to pay. After all, this memory is not used? Not. Why then pay for it?
Clouds allow you to take memory when you need it. And give back when the memory has ceased to be necessary. And unlike other resources (memory / disk performance), the lack of which only leads to some slowdown, memory is a vital resource. They didn’t give any memory - someone saw the happiness page from nginx “Bad gateway” or simply didn’t see anything, because the connection was closed ...
By the way, this principle applies to the network. We are all accustomed to anlim at home (unlimited access at a fixed maximum speed). But work is not home. And it’s a pity to pay for the tight bandwidth of 30MB, for 100MB it’s expensive (see the first chart). And, perhaps, there are further single peaks under 500MB, but rarely? How to be in this situation? Cheap traffic is cheaper and provides better service quality than a strip (anlim) squeezed into a narrow saving vice with the same actual amount of traffic per month. Most people are used to the fact that “paid traffic is expensive” (thanks to opsox). And if not? And if the gigabyte of traffic will cost 80 kopecks? (is it three orders of magnitude cheaper?)
Why would you pay hundreds (thousands?) Of rubles for traffic if your virtual machine eats less than a hundred rubles?
By the way, the same applies to the local network. Yes, there gigabytes of traffic will cost a penny. But he is? It consumes resources, fast switches are installed for it ... So, it must be paid for.
Sometimes, for “normal VDS” it is possible for the user to set the limits on resource consumption himself. Like, not enough 500 MHz, put 600, here's a smooth slider for you, set limits yourself. However, this is not a solution. Well, yes, instead of 500 we put 600 - and what do we get? The same VDS, with the same (or even large) areas of downtime for which we pay - but which we do not receive. We cannot know exactly how many resources are needed for a server that serves clients (the number of which we cannot predict). Thus, the payment "on the fact of consumption" is more fair.
You can call this analogy: there are cars that have a carburetor. And handle choke. Which need to regulate the flow of fuel. Perelil? Not enough? Bad rides. And there are cars with injection engines, which themselves take as much gasoline as they need.
That is the difference between the cloud and VDS with a pedal drive. You do not need as much gasoline - pour and pour into the engine (at your expense!). You crawl up the hill and you would add - but do not give. They give it more precisely, but with hands, hands ... Looking up from the analogy: in the car, at least, you are sitting at the wheel. And in the VDS - you monitor the consumption of resources around the clock?
It may seem that everything written concerns hosters. This is not true. The difference between the position of the hoster and the administrator of its own fleet of enterprise servers is that the provider operates with money and the administrator with available resources. All considerations relating to the general use of resources apply to servers in the "private" cloud. Instead of reserving memory by the square-socket method, using a common pool gives a much higher density of virtual machines, solves the problem “oh, sql has fallen, I have set the memory limit incorrectly”.
I'll try to write out what resources should be in an ideal cloud:
Any techie who tries to deal with the technologies underlying the "cloud", after a few hours of dealing with the flow of advertising enthusiasm, will discover that these clouds are the same VDSs, side view. He will be right. Clouds, as they are done now, are ordinary virtual machines.
However, clouds are not only marketing and renamed VDS. The word “cloud” (or, more precisely, the phrase “cloud computing”) has its own technical truth. It is not as pathetic and delightfully innovative as marketers say, but it does exist. It was invented many decades ago, but only now the infrastructure (first of all, the Internet and x86 virtualization technologies) has grown to a level that allows it to be implemented on a massive scale.
')
So, first about the cause, which generally spawned the need for clouds:
Here is what the provided service looks like for a regular VDS (any resource can be in the place of this graphic: processor, memory, disk):
Please note: this is a weekly schedule. Existing technologies of a temporary increase in the resource consumption limit (burst, grace period) are not able to solve this problem at such long intervals. Those. a machine receives less resources when it needs them most.
The second problem - look at the huge intervals (blue), when resources, in fact, had to be paid, but could not be used. A virtual machine at night just does not need as many resources. She is idle. And despite this - the owner pays to the full.
There is a problem: a person is forced to order more resources than they need on average in order to experience peaks without problems. The rest of the time the resources are idle. The provider sees that the server is not loaded, begins to sell more resources than it is (this is called an "oversell"). At some point, for example, due to the peak load on several clients, the provider violates its obligations. He promised 70 people at 1GHz - but he only has 40 (2.5 * 16 cores). Not good.
It is unprofitable to sell the lane honestly (without an overcell) (and prices are non-market). Oversell - reduce the quality of service, violate the terms of the contract.
This problem is not related to VDS or virtualization, it’s a common question: how to honestly sell idle resources?
The answer to this problem was the idea of "cloud computing". The words are fashionable, but their basis goes back to the times of large mainframes, when machine time was sold.
Cloud computing does the same thing - instead of limits and quotas, which are paid regardless of real consumption, users are given the opportunity to use resources without restriction, with payment of real consumption (and only that which was actually used). This is the essence of the "cloud".
Instead of selling “500 MHz 500 MB of memory of a 3 GB disk”, the user (more precisely, his virtual machine) is given everything she needs. As much as needs.
Do you have a peak in resource consumption before March 8, and then the low season? Or you just can not predict when you will have these peaks? Instead of seeking a compromise between lags and money to the wind, a different payment model is proposed: what is consumed is paid.
Resource accounting
Machine time is taken into account (it can be counted in ticks, but ideologically it’s more appropriate to do it in the old style: count seconds of machine time), of course, if you have threshed 3 cores with 50% load, this is one and a half seconds of machine time per second. If you have a download of 3%, then in a minute you will spend only 2s of computer time.
Memory is allocated "on demand" - and is limited only by the capabilities of the hoster and your greed. It is also paid on a time-based basis - a megabyte of memory costs so much per second. (in fact, on the old VDS it was, you paid “megabytes per month”, but they were idle most of the time).
Disk space is also allocated on demand - pay per megabyte per second. If you needed a place for a temporary dump on a terabyte, you do not need to pay a terabyte for a whole month - just an hour and a half is enough (the main thing is not to forget to erase the excess).
Disk space
Disk space is a complex resource: it is not only “storage”, but also “access”. Payment is taken both for the space consumed (megabyte-seconds), for iops (pieces), and for the amount of written-read. Each component costs money. Since money is taken three times for one resource, the price is, in fact, divided into three.
And here the interesting begins: the person who put the files, but does not touch them, pays less than the one who actively uses them to give to the client. And the use can be different - I read it ten times a megabyte "and" read ten times a kilobyte "- there is a difference. interspersed with the recording ...
The pay-as-you-go model is the most honest one, both for the consumer and for the service provider: the consumer only pays for what he consumes, but the supplier no longer feels irritated by fatty customers who survive all resources. Consumed resource - sold resource. Moreover, the reverse principle also applies: an unused resource is not paid. If the hoster has failed to provide all the processor "according to need" (a congestion has arisen), then it is trivial, without trial and swearing, without long correspondence, automatically losing money, because it sold less than they wanted to buy. Clients, although they feel unpleasant because of the congestion, will receive at least satisfaction - they will pay less for this time ... This congestion problem has an even more beautiful, cloudy solution, but about it next time.
RAM
For example, a graph of memory usage. Please note - orange areas are areas that will not just “slow down”, but areas where oom_killer will work. With all that it implies. If the payment was on consumption, then these peaks would cost not so much, but would allow to solve the "peak" situation without any problems.
And look again, again huge idle resources that absolutely do not want to pay. After all, this memory is not used? Not. Why then pay for it?
Clouds allow you to take memory when you need it. And give back when the memory has ceased to be necessary. And unlike other resources (memory / disk performance), the lack of which only leads to some slowdown, memory is a vital resource. They didn’t give any memory - someone saw the happiness page from nginx “Bad gateway” or simply didn’t see anything, because the connection was closed ...
Network
By the way, this principle applies to the network. We are all accustomed to anlim at home (unlimited access at a fixed maximum speed). But work is not home. And it’s a pity to pay for the tight bandwidth of 30MB, for 100MB it’s expensive (see the first chart). And, perhaps, there are further single peaks under 500MB, but rarely? How to be in this situation? Cheap traffic is cheaper and provides better service quality than a strip (anlim) squeezed into a narrow saving vice with the same actual amount of traffic per month. Most people are used to the fact that “paid traffic is expensive” (thanks to opsox). And if not? And if the gigabyte of traffic will cost 80 kopecks? (is it three orders of magnitude cheaper?)
Why would you pay hundreds (thousands?) Of rubles for traffic if your virtual machine eats less than a hundred rubles?
By the way, the same applies to the local network. Yes, there gigabytes of traffic will cost a penny. But he is? It consumes resources, fast switches are installed for it ... So, it must be paid for.
Fake clouds
Sometimes, for “normal VDS” it is possible for the user to set the limits on resource consumption himself. Like, not enough 500 MHz, put 600, here's a smooth slider for you, set limits yourself. However, this is not a solution. Well, yes, instead of 500 we put 600 - and what do we get? The same VDS, with the same (or even large) areas of downtime for which we pay - but which we do not receive. We cannot know exactly how many resources are needed for a server that serves clients (the number of which we cannot predict). Thus, the payment "on the fact of consumption" is more fair.
You can call this analogy: there are cars that have a carburetor. And handle choke. Which need to regulate the flow of fuel. Perelil? Not enough? Bad rides. And there are cars with injection engines, which themselves take as much gasoline as they need.
That is the difference between the cloud and VDS with a pedal drive. You do not need as much gasoline - pour and pour into the engine (at your expense!). You crawl up the hill and you would add - but do not give. They give it more precisely, but with hands, hands ... Looking up from the analogy: in the car, at least, you are sitting at the wheel. And in the VDS - you monitor the consumption of resources around the clock?
Enterprise and hosters
It may seem that everything written concerns hosters. This is not true. The difference between the position of the hoster and the administrator of its own fleet of enterprise servers is that the provider operates with money and the administrator with available resources. All considerations relating to the general use of resources apply to servers in the "private" cloud. Instead of reserving memory by the square-socket method, using a common pool gives a much higher density of virtual machines, solves the problem “oh, sql has fallen, I have set the memory limit incorrectly”.
Perfect cloud
I'll try to write out what resources should be in an ideal cloud:
- CPU resources on request. Perhaps, with the dynamic connection of additional cores, automatic migration of the virtual machine to a freer / faster server, if the current server resources are not enough. Payment of processor time for ticks (or seconds of busy processor).
- The unlimited amount of memory that is paid upon consumption-release (accounting in kilobyte-seconds or multiple units).
- Disk space taken into account according to the same principles: payment in gigabyte hours. I put a terabyte archive for two hours - I paid 2,000 gigabyte hours. (most importantly, do not forget to erase too much) Put 2GB per day - paid 48 gigabyte hours.
- Disk operations - by the piece, disk traffic - by gigabyte
- The network is not limited, the speed in gigabits, and then in the top ten. Payment by traffic.
- Full legal right to turn off the virtual machine and pay only for the “dead weight” content of its disks
- Ability to export / import your virtual machines
- The ability to have multiple virtual machines on the same account
- Graphs of resource consumption in real time or close to it
Source: https://habr.com/ru/post/95847/
All Articles