How was Aichtalka created. Part 1: engine
Most recently, we have released the first beta version of our online reader, which can be found by reading the book “ Hero of Our Time ” by Mikhail Lermontov. This reader is the result of almost seven months of work, five of which took only to develop the engine. It would seem that there are already free and open JavaScript engines for reading electronic books on the Internet and such a long period of time may raise doubts as to the professional suitability of the developer (that is, me). But there is one big and fat "BUT". We set ourselves too ambitious and difficult task: we wanted to use the same engine on different devices, including low-power ones, such as an iPhone or electronic reader.
What is the difficult task? First of all - at a very low speed of web applications on the iPhone. For example, the mobile Safari according to my estimates runs 100 times slower than its desktop counterpart. If the same operation is performed on the deckstop machine for 10 ms and is completely invisible to the user, then on the iPhone it can be performed for more than a second. For comparison: the first version of the engine broke a small chapter into pages in about 15 seconds. Now, six months later, he does the same thing in less than a second and works reasonably well in our application booq .
In this article I will not focus on how to make your reader, but I will share the experience of optimizing a web application for iPhone. The article will be interesting not only to developers for mobile devices, but also to ordinary web technologists. After all, if your application / website will quickly work on a mobile device, then imagine how fast it will work on the desktop.
')
For a start it is worth explaining why we chose web technologies as the basis for the reader. First, it is their prevalence. Now it is quite difficult to find a device that does not have a built-in browser. Phones, computers, netbooks, tablets, e-books - they are all capable of reading HTML, decorate it with CSS and animate via JavaScript. Having the same engine, we can easily create applications for different platforms and devices. Secondly, not a single “classic” reader engine is able to display what a web browser can do. Tables, vector graphics, audio / video content, interactive elements - all this has been successfully working in browsers for a long time. Imagine that you are reading a scientific book and immediately see a video demonstrating the described process. Well, or read a detective story in which you need to go through a puzzle to open the next chapter :). Opportunities are limited only by the imagination and skills of the developer.
All this is a beautiful marketing wrapper, but let's get down from heaven to earth and see what the engine should be from a technical point of view:
The iPhone 2G with firmware 3.1 and the chapter from Ivan Mironov's book “Zamulennye” weighing 500 KB were used as a test site. Such a large chapter is the exception rather than the rule, but it sets a good bar for performance, below which you should not fall.
So let's proceed to optimization.
Immediately I want to upset those who like to set up a bunch of frameworks on the page and load them with plugins to solve simple tasks like dragging blocks or selecting elements by CSS selector: the amount of JS code on the page is of great importance, at least for mobile Safari. For example, parsing and initialization of the popular jQuery takes 1400 ms for the original, uncompressed version (155 KB) and 1200 ms for the compressed (76 KB). Despite the fact that the compressed version is 2 times smaller than the original, they are identical in functionality: hence the “small” difference in the speed of parsing. That is, speed is not affected by the length of variable names, but by the number of functions, objects, methods, and so on. For comparison: on the desktop the parsing takes about 30 ms.
Ideal: keep all the JS code at the very bottom of the page and generally abandon the frameworks. Since WebKit itself supports a lot of things, I rendered standard DOM operations (adding events, searching for elements by a selector, etc.) as a separate additional module, and for the desktop version I redefined this layer so that the calls were broadcast in jQuery .
The reader itself is focused on the ePub format, in which each chapter of the book is represented by a separate document in the XHTML format. The chapter must somehow be passed to JavaScript, so that it parses it, paginated it, and began to show.
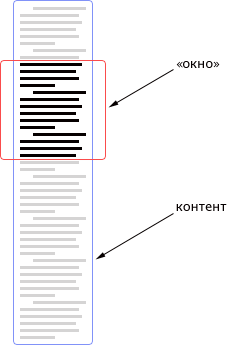
Here it is worth saying a few words about the principle of displaying content on the screen. Let me remind you that the engine should support two reading modes: paginated and “footcloth”. Therefore, I decided to frame all the content in two wrappers: the first is a kind of “window”, and the second shifts the content up and down. Selecting the correct window size and content offset, you can create the illusion of a paginated chapter:
Since in any case I need all the contents of the chapter, and for calculating the size of the pages I need full DOM elements, I decided to put the chapter directly into HTML:
And then he ran into a serious problem: the parsing and the accompanying display of the chapter lasted as much as 7 seconds. I assumed that it was the content rendering that took most of the time, so as an experiment I hid the content using
At this time, the page parsing took 800 ms, which is very good: accelerated almost 10 times. And since the iPhone has a rather small screen, it was enough to get some of the first elements from the tree and show them so that the user could start reading while the chapter is being read.
In principle, this is already a pretty big victory in terms of performance and you could do other things, but intuition tells me that you can further reduce the parsing time.
I assumed that when HTML is right in the body of the document, the browser takes some additional steps so that the elements can appear on the page at the right moment. For example, finding and applying appropriate CSS rules. I personally do not need these actions at the moment: I need to transfer the contents of the chapter as a DOM tree directly into JavaScript as soon as possible. How to force the browser not to parse a specific document fragment? Correctly, comment it out:
Laugh laugh, but the page parsing time was reduced to 350 ms. And the comment is a full-fledged DOM element that can be accessed via JavaScript and get its contents:
The total time of parsing the page and parsing the code into the tree was about 550 ms (against 800 ms in the previous version), which, in my opinion, is very good.
So, I received the contents of the chapter and parsed it, now I need to break the chapter into pages. During the optimization of parsing, I realized that my initial version of the chapter output in page mode as a window and moving content had a number of drawbacks. First, you need to display (draw) the entire chapter, which, as you already understood, takes a very long time. Secondly, in this situation, I could not display more than one page on the screen: for the second page, I would have to completely duplicate the entire chapter, which, again, would be slow and would inevitably cause the application to crash due to lack of memory on large chapters.
After about two months of unsuccessful attempts to write a page breakdown with an acceptable execution time, a fairly good solution was found. In short, what it is.
In fact, the chapter of the book is a set of paragraphs. Paragraphs can be represented as elements of the first level. Taking into account the speed of rendering HTML-content in the iPhone, for the fastest display of one page, you need to determine the minimum set of first-level elements that is necessary for its presentation. I have an entire chapter in the form of a list of first-level items, as well as a list of pages. A page is an object in which the ordinal numbers of the first and the first level element, window size and offset are stored. It turned out to be a rather compact and fast design: to display one page, it is enough to clone a set of first-level elements and display them on the screen, indicating the correct offset and window size.
In order to calculate all the pages, you need to know the dimensions of each element of the first level, their internal and external indents, borders, font size and so on. To get all this data, elements must be on the page and styles should be applied to them. For these purposes, I created a special hidden container that inherits all the style descriptions of the page itself, added paragraphs to it and carried out calculations.
To obtain the necessary characteristics of the element, you need to refer to its CSS properties. I took the
Since I needed to get quite a few properties at once, this is a function, judging by the profiler from the Web Inspector (the desktop browser is meant, there are no such debugging tools on the iPhone, which greatly complicates the work) was the slowest. As it turned out, the call to
After such an optimization, the
The next step: correctly "smear" the calculation of pages in time. The fact is that while JS is being executed, the browser interface is completely blocked, and restrictions on the execution time of the script also take effect. It could be a situation that the screen “freezes” seconds for 20-30, and then completely falls out with an error about exceeding the timeout for execution. The modern way to get rid of such problems is Web Workers , but mobile Safari does not support them. Therefore, we will use the proven “old-fashioned” method that works in all browsers: call each iteration of page counting via
The function works as follows. For example, we need to calculate 30 elements of the first level. We give an array of these elements to the function
There is one important aspect to this approach - this is a load per iteration. In this case, how many elements need to be calculated in one call of the
Therefore, you need to find a certain middle ground, so that the calculation time does not greatly increase, and not reduce the responsiveness of the interface. I decided to focus not on the number of elements of the first level, but on their volume, which can be obtained through the
After counting one group, you need to clear the hidden container and free up resources for the next group of elements. The easiest way to clear the contents of a container is to reset the
However, “the simplest” does not always mean “the fastest” - as the measurements showed, this method works much faster:
Perhaps, for now. In this article, some features of parsing and calculating large amounts of data on low-power devices were considered. In practice, all the tricks described were very effective. For example, I tested a chapter with a volume of more than 1 MB: our reader was able to digest it in about 30-40 seconds, while other (and quite popular) readers from the AppStore, written in Objective C / C ++, simply fell.
In the next article we will look at some of the factors that influence the time spent on drawing one page in an iPhone, as well as some tricks that allow this time to be noticeably reduced.
Sergey Chikuyonok
What is the difficult task? First of all - at a very low speed of web applications on the iPhone. For example, the mobile Safari according to my estimates runs 100 times slower than its desktop counterpart. If the same operation is performed on the deckstop machine for 10 ms and is completely invisible to the user, then on the iPhone it can be performed for more than a second. For comparison: the first version of the engine broke a small chapter into pages in about 15 seconds. Now, six months later, he does the same thing in less than a second and works reasonably well in our application booq .
In this article I will not focus on how to make your reader, but I will share the experience of optimizing a web application for iPhone. The article will be interesting not only to developers for mobile devices, but also to ordinary web technologists. After all, if your application / website will quickly work on a mobile device, then imagine how fast it will work on the desktop.
')
Task
For a start it is worth explaining why we chose web technologies as the basis for the reader. First, it is their prevalence. Now it is quite difficult to find a device that does not have a built-in browser. Phones, computers, netbooks, tablets, e-books - they are all capable of reading HTML, decorate it with CSS and animate via JavaScript. Having the same engine, we can easily create applications for different platforms and devices. Secondly, not a single “classic” reader engine is able to display what a web browser can do. Tables, vector graphics, audio / video content, interactive elements - all this has been successfully working in browsers for a long time. Imagine that you are reading a scientific book and immediately see a video demonstrating the described process. Well, or read a detective story in which you need to go through a puzzle to open the next chapter :). Opportunities are limited only by the imagination and skills of the developer.
All this is a beautiful marketing wrapper, but let's get down from heaven to earth and see what the engine should be from a technical point of view:
- be cross-browser and cross-platform;
- have a modular structure to make it easier to create versions for different devices;
- support two modes of reading: page by page and scrolling (like a regular web page), and also quickly switch between them;
- handle chapters with a volume of 1 MB + (for comparison: the first volume of “War and Peace” by Tolstoy weighs 1.2 MB);
- have flexible appearance settings (in fact, limited by CSS capabilities).
The iPhone 2G with firmware 3.1 and the chapter from Ivan Mironov's book “Zamulennye” weighing 500 KB were used as a test site. Such a large chapter is the exception rather than the rule, but it sets a good bar for performance, below which you should not fall.
So let's proceed to optimization.
JS code size
Immediately I want to upset those who like to set up a bunch of frameworks on the page and load them with plugins to solve simple tasks like dragging blocks or selecting elements by CSS selector: the amount of JS code on the page is of great importance, at least for mobile Safari. For example, parsing and initialization of the popular jQuery takes 1400 ms for the original, uncompressed version (155 KB) and 1200 ms for the compressed (76 KB). Despite the fact that the compressed version is 2 times smaller than the original, they are identical in functionality: hence the “small” difference in the speed of parsing. That is, speed is not affected by the length of variable names, but by the number of functions, objects, methods, and so on. For comparison: on the desktop the parsing takes about 30 ms.
Ideal: keep all the JS code at the very bottom of the page and generally abandon the frameworks. Since WebKit itself supports a lot of things, I rendered standard DOM operations (adding events, searching for elements by a selector, etc.) as a separate additional module, and for the desktop version I redefined this layer so that the calls were broadcast in jQuery .
HTML parsing
The reader itself is focused on the ePub format, in which each chapter of the book is represented by a separate document in the XHTML format. The chapter must somehow be passed to JavaScript, so that it parses it, paginated it, and began to show.
Here it is worth saying a few words about the principle of displaying content on the screen. Let me remind you that the engine should support two reading modes: paginated and “footcloth”. Therefore, I decided to frame all the content in two wrappers: the first is a kind of “window”, and the second shifts the content up and down. Selecting the correct window size and content offset, you can create the illusion of a paginated chapter:
Since in any case I need all the contents of the chapter, and for calculating the size of the pages I need full DOM elements, I decided to put the chapter directly into HTML:
< div id ="window" >
< div id ="content" >
< p > … , … </ p >
</ div >
</ div >And then he ran into a serious problem: the parsing and the accompanying display of the chapter lasted as much as 7 seconds. I assumed that it was the content rendering that took most of the time, so as an experiment I hid the content using
display: none :< div id ="window" >
< div id ="content" style ="display:none" >
< p > … , … </ p >
</ div >
</ div >At this time, the page parsing took 800 ms, which is very good: accelerated almost 10 times. And since the iPhone has a rather small screen, it was enough to get some of the first elements from the tree and show them so that the user could start reading while the chapter is being read.
In principle, this is already a pretty big victory in terms of performance and you could do other things, but intuition tells me that you can further reduce the parsing time.
I assumed that when HTML is right in the body of the document, the browser takes some additional steps so that the elements can appear on the page at the right moment. For example, finding and applying appropriate CSS rules. I personally do not need these actions at the moment: I need to transfer the contents of the chapter as a DOM tree directly into JavaScript as soon as possible. How to force the browser not to parse a specific document fragment? Correctly, comment it out:
< div id ="window" >
< div id ="content" >
<!--
<p> … , …</p>
-->
</ div >
</ div >Laugh laugh, but the page parsing time was reduced to 350 ms. And the comment is a full-fledged DOM element that can be accessed via JavaScript and get its contents:
var elems = document .getElementById( 'content' ).childNodes;
for ( var i = 0, il = elems.length; i < il; i++) {
var el = elems[i];
if (el.nodeType == 8) { //comment
var div = document .createElement( 'div' );
div.innerHTML = el.nodeValue;
// div DOM-,
break ;
}
}The total time of parsing the page and parsing the code into the tree was about 550 ms (against 800 ms in the previous version), which, in my opinion, is very good.
Calculate page sizes
So, I received the contents of the chapter and parsed it, now I need to break the chapter into pages. During the optimization of parsing, I realized that my initial version of the chapter output in page mode as a window and moving content had a number of drawbacks. First, you need to display (draw) the entire chapter, which, as you already understood, takes a very long time. Secondly, in this situation, I could not display more than one page on the screen: for the second page, I would have to completely duplicate the entire chapter, which, again, would be slow and would inevitably cause the application to crash due to lack of memory on large chapters.
After about two months of unsuccessful attempts to write a page breakdown with an acceptable execution time, a fairly good solution was found. In short, what it is.
In fact, the chapter of the book is a set of paragraphs. Paragraphs can be represented as elements of the first level. Taking into account the speed of rendering HTML-content in the iPhone, for the fastest display of one page, you need to determine the minimum set of first-level elements that is necessary for its presentation. I have an entire chapter in the form of a list of first-level items, as well as a list of pages. A page is an object in which the ordinal numbers of the first and the first level element, window size and offset are stored. It turned out to be a rather compact and fast design: to display one page, it is enough to clone a set of first-level elements and display them on the screen, indicating the correct offset and window size.
In order to calculate all the pages, you need to know the dimensions of each element of the first level, their internal and external indents, borders, font size and so on. To get all this data, elements must be on the page and styles should be applied to them. For these purposes, I created a special hidden container that inherits all the style descriptions of the page itself, added paragraphs to it and carried out calculations.
To obtain the necessary characteristics of the element, you need to refer to its CSS properties. I took the
css() function from jQuery as a basis:function getCSS(elem, name) {
if (elem.style[name]) {
return elem.style[name];
} else {
var cs = window.getComputedStyle(elem, "" );
return cs && cs.getPropertyValue(name);
}
}
Since I needed to get quite a few properties at once, this is a function, judging by the profiler from the Web Inspector (the desktop browser is meant, there are no such debugging tools on the iPhone, which greatly complicates the work) was the slowest. As it turned out, the call to
getComputedStyle() is very expensive in terms of performance. Therefore, I modified this function so that I could give an array of properties that need to be obtained, and also removed the check elem.style[name] , since in 99% of cases the elements were not exposed to CSS properties through the style object and this optimization was more harmful than helped:function getCSS(elem, name) {
var names = ( typeof name == 'string' ) ? [name] : name,
cs = window.getComputedStyle(elem, "" ),
result = {};
for ( var i = 0, il = names.length; i < il; i++) {
var n = names[i];
result[n] = cs && cs.getPropertyValue(n);
}
return ( typeof name == 'string' ) ? result[name] : result;
}After such an optimization, the
getCSS() function did not even fall into the first three of the slowest functions :).The next step: correctly "smear" the calculation of pages in time. The fact is that while JS is being executed, the browser interface is completely blocked, and restrictions on the execution time of the script also take effect. It could be a situation that the screen “freezes” seconds for 20-30, and then completely falls out with an error about exceeding the timeout for execution. The modern way to get rid of such problems is Web Workers , but mobile Safari does not support them. Therefore, we will use the proven “old-fashioned” method that works in all browsers: call each iteration of page counting via
setTimeout() . Sample code for this solution:function calculatePages(elems, callback) {
// elems — ,
var cur_elem = 0;
var run = function () {
createPage(elems[cur_elem]); //
cur_elem++;
if (cur_elem < elems.length)
setTimeout(run, 1);
else
callback(); //
};
run();
}The function works as follows. For example, we need to calculate 30 elements of the first level. We give an array of these elements to the function
calculatePages() , inside which the closure is created as a run() function, which is one iteration of the calculation. When finished to count we check whether there are still elements in the array. If yes, then through setTimeout() call a new iteration, otherwise we call the callback function, informing that the calculation is over and we can move on.There is one important aspect to this approach - this is a load per iteration. In this case, how many elements need to be calculated in one call of the
run() function. If, for example, one element is counted for one iteration, the interface for the user will be as responsive as possible, but the total calculation time for the entire chapter may increase by 2-3 times due to the overhead incurred when the function is started via setTimeout() . If we count 10 elements in a single pass, the total calculation time for the chapter will decrease, but the interface responsiveness will also decrease and the risk will not go beyond the timeout if the paragraphs are very large.Therefore, you need to find a certain middle ground, so that the calculation time does not greatly increase, and not reduce the responsiveness of the interface. I decided to focus not on the number of elements of the first level, but on their volume, which can be obtained through the
innerHTML property or textContent . The value of 5 KB was chosen as the threshold volume by trial and error. Before calling calculatePages() I divided all the objects into groups: as soon as the total volume of one group became larger than 5 KB, it was closed and a new one was created. Accordingly, the calculation of page sizes was carried out not by individual elements, but by groups.Deleting items
After counting one group, you need to clear the hidden container and free up resources for the next group of elements. The easiest way to clear the contents of a container is to reset the
innerHTML property:function emptyElement(elem) {
elem.innerHTML = '' ;
}However, “the simplest” does not always mean “the fastest” - as the measurements showed, this method works much faster:
function emptyElement(elem) {
while (elem.firstChild)
elem.removeChild(elem.firstChild);
}Perhaps, for now. In this article, some features of parsing and calculating large amounts of data on low-power devices were considered. In practice, all the tricks described were very effective. For example, I tested a chapter with a volume of more than 1 MB: our reader was able to digest it in about 30-40 seconds, while other (and quite popular) readers from the AppStore, written in Objective C / C ++, simply fell.
In the next article we will look at some of the factors that influence the time spent on drawing one page in an iPhone, as well as some tricks that allow this time to be noticeably reduced.
Sergey Chikuyonok
Source: https://habr.com/ru/post/95249/
All Articles