Implementing a SAMBA Resilient File Service
This article describes the organization of a fault-tolerant file server based on the Samba package. To understand the material, you need to have a general understanding of the administration of the Linux operating system, as well as have experience with the regular version of Samba.

Samba is a CIFS service designed to provide the semantics of the CIFS protocol (and therefore access from machines running Windows) to an environment that uses the POSIX file system. The main function of Samba is to translate the rich semantics that Windows-based clients use to the much poorer semantics of the POSIX file system.
')
To produce such conversions, Samba uses a variety of internal metadata databases containing additional information used in converting semantics.
Additional parameters in particular are responsible for such a thing as the simultaneous opening of the same file from different clients and much more.
This information is necessarily processed before directly opening the file in POSIX.
Thus, transparent access from Windows clients to the POSIX file system is performed.
Fault tolerance Samba is based on three provisions:
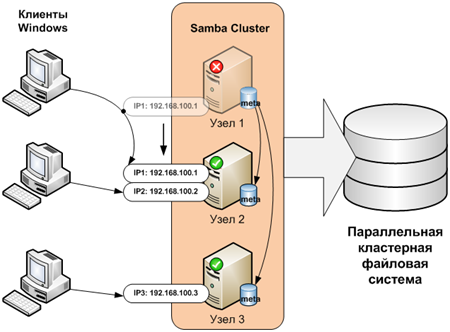
This article describes only the mechanism for creating a fault-tolerant CIFS service. A prerequisite for its implementation is the use of a parallel cluster file system, which is used directly to store files.
The description of cluster systems is beyond the scope of this article. As an example, you can use the GPFS or Luster file systems.
Normal non-clustered versions of Samba use a very simple and resource-intensive database called the Trivial Database (TDB) to store data.
TDB is organized on a key-value basis and is similar in organization to Berkley DB. TDB provides very fast multiple read and write access from various processes on a POSIX system. Memory reflection (mmap) is supported on most architectures.
Each client connection to the file system is serviced by its own smbd daemon process. Between themselves, these processes interact through the TDB database.
The first attempts to implement a cluster version of SAMBA were simply to place files containing TDB on a cluster file system, such as GPFS or Luster.
Such SAMBA implementations worked, but were extremely slow. The reduction in speed was due to high overhead and latency in the synchronization protocols of cluster file systems. At the same time, in order for Samba to work successfully, it is necessary to provide very fast access to TDB.
The foundation of the functioning of cluster file systems is that they prevent data from being lost. Even if the client started recording data, and the node where it was supposed to be recorded, failed, they will not be lost.
Thus, the cluster file system must either write data to the shared storage or send changes to all nodes of the cluster.
However, this statement is not quite true for Samba metadata. In a certain situation, the loss of this data will not affect the ability to perform the necessary semantics conversion between CIFS and POSIX.
Thus, it becomes possible to implement a cluster system that does not require shared storage of metadata and data replication when writing.
Just say that this does not apply to all metadata.
There are two types of TDB databases - permanent and non-permanent.
Permanent (Persistent) - contain long-term information that should be preserved even after a restart. These databases are more often used for reading than for writing. The speed of access to write to this type of database is not critical. The main thing here is reliability.
Non - persistent — such as a lock or session database. The data stored here has a short life cycle. The frequency of writing to these databases is very high. They are also often referred to as “normal TDB.”
For successful Samba operation, high performance is especially important when working with “normal TDB”.
Loss of information is possible only for non-permanent databases.
The tables below list and describe the bases used in the cluster implementation of Samba.
Table 1 Constant (Persistent) TDB Base
Table 2 Temporary (Normal) TDB Bases
Thus, we see what information we can lose. This is information about sessions, locks, as well as, apparently (no data on the Internet), specific information necessary for the operation of the cluster.
When a node fails, all open files on it will be closed, respectively, the loss of the above information will not be critical.
The key component in the Samba cluster is the CTDBD daemon. It provides support for a cluster version of the TDB database, called CTDB (Cluster Trivial DataBase), with the possibility of automatic recovery.
CTDBD also monitors the cluster nodes and performs its automatic reconfiguration in case of failure.
Providing load balancing is another CTDBD task.
Depending on the type of database, it is processed differently.
A key feature of temporary TDB is that they do not need to contain all the records within the cluster. In most cases, temporary TDBs contain only entries related to the connections of this particular node. Accordingly, when it falls, only this data will be lost.
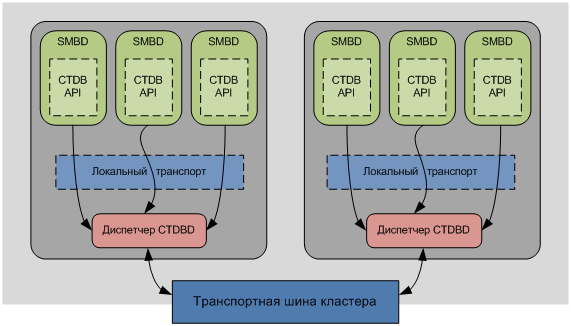
The CTDB system uses a distributed protocol for operations on metadata databases between the CTDBD daemons on each node, as well as a local protocol for intra-node communication between the Samba daemons and the CTDBD daemons.
The CTDB design uses a two-tier record storage system. At the first level, the location master is defined for each entry. This host is attached to the record by its key.
At the second level, the roving "data master" (roaming or roaming data master) is defined. This is the last node that modified the record.
The “Location master” always knows on which node the record is located and, accordingly, which node is the “data master”. The “data master” in turn contains the most current copy of the record.
Each record contains a global sequence number - RSN (record sequence number) - a 64-bit integer that is incremented each time the “data master” is moved from one node to another. The change of ownership of the “Data Master” entry always occurs via the “Location master”.
The node contains only those records in the local TDB to which it already had access. Data is not automatically distributed to other nodes, and can be transferred only on request.
Only one node contains the current copy of the record - “Data Master”. When a node wants to write or read a record, it first checks whether it is a “data master” for that node. If so, it records directly in TDB. If not, then it requests the current contents of the record from the current data master, takes the data master role for itself and then makes a direct recording.
Thus, writing and reading data always happens locally, which significantly improves performance.
When a node dies, the records for which it was a “data master” are lost.
CTDBD starts the recovery process. To do this, select the node master of the recovery process - «recovery master». After a node is selected, on the cluster file system, it sets a lock on a specific file (which is specified in the configuration) so that other nodes can no longer claim the role of “recovery master”.
Recover Master collects the most current versions of records from all sites. Relevance is determined by the RSN value. The most relevant is a record with a large RSN.
For this database, each node always has a complete, up-to-date copy of the database.
Reading is always from a local copy. When a node needs to write, it performs a transaction that completely blocks the entire database on all nodes.
Then he performs the necessary write operations. After that, the changes are written to the local copies of the database on all nodes and the transaction is completed.
Thus, on all nodes of the cluster always contains a complete and current copy of the database. Delays that occur during the synchronization process are not critical, due to the non-high frequency of changes in these databases.
If one of the nodes fails, all the necessary information is on the rest of the cluster members.
In addition to protecting metadata databases, CTDBD uses an integrated TCP / IP protocol failover protection mechanism.
It consists of using a cluster of a set of public IP addresses that are distributed among the cluster nodes. These addresses can be transferred from node to node by updating the Address Resolution Protocol (ARP).
In case of failure of a node, all its public ip addresses will be transferred to the working nodes.
Public are the addresses through which the customer calls. For communications between the nodes of the cluster, internal ip addresses are used.
The host that took over the IP address of the other knows only what they were about old TCP connections, and does not know the “TCP squence number” connections. Accordingly, they can not continue. As well as the client, does not know anything about the fact that connections are now made with another node.
In order to avoid delays associated with switching the connection, the following method is used. To understand this technique, you need to understand the basic principles of the TCP protocol.
The new node, receiving its ip address, sends the client a packet with the ACK flag and the deliberately incorrect “Squence number” equal to zero. In response, the client, in accordance with the rules of the TCP protocol, sends back an ACK Reply packet with the correct “squence number”. Having received the correct “squence number” node forms a packet with the RST flag and this “squence number”. Upon receiving it, the client immediately restarts the connection.
Delays are very minimal. Without using this technique, the client can wait for a long time from the server of the TCP ACK packet.
As mentioned above, if one of the nodes fails and the ip address is transferred, the entire responsibility for continuing work after the failure lies with the client. All open files associated with the failed node are closed.
If you copy or read any file in Windows Explorer, then you will get an error if it fails. However, if you use tools that can re-connect after losing the connection, everything will go smoothly. For example, the xcopy utility with the “/ z” key. When copying files using this utility, you will get only a small delay at the time of switching the ip address. Then, continue copying.
Connection to network resources is also not lost.
If you open any file in the editor, and the moment of saving does not occur at the ip address relocation, then the failures also do not affect the work.
Thus, part of the responsibility for restoring work after a failure in this case is transferred to the client.
Configuring Samba Cluster
Setting up a cluster consists of two steps:
Starting with version 3.3, Samba source tests have built-in clustering support. However, to work in a cluster, you must compile the package using special keys.
From enterprisesamba.com you can download a compiled version of Samba with clustering support for popular distributions: RHEL, SLES, Debian.
Important note. In order for Windows clients to successfully authenticate to the Samba cluster, it is advisable to use external authorization. For example, through Active Directory.
For Windows users accessing the Posix file system, Samba establishes a correspondence between the Windows user and the POSIX system user (for example, Linux). A Windows user must access the POSIX file system from the name of any known POSIX user’s operating system. Windows user authorization occurs regardless of user authorization in the POSIX OS.
Those. In order for a Windows user to access, you must:
The table of relationships between users and passwords can be stored in the CTDB database and distributed within the cluster. However, the local user base does not have this capability. Those. Every time we create users in Samba, we will need to create corresponding local accounts on all nodes in the cluster.
It is not comfortable. In order to avoid this, it makes sense to use an external database in conjunction with the local user base. In our case, integration with Active Directoty is used. Samba cluster is a member of the domain.
In the /etc/nsswitch.conf file you need to register:
passwd: files winbind
group: files winbind
shadow: files winbind
This means that in addition to local files, the search for users and groups will be carried out in the Active Directory through winbind. The winbind service allows Windows domain users to authenticate on Unix machines. Thus, transparent access control is performed.
Authorization in the Active Directory domain is carried out using the Kerberos protocol. You must make the appropriate settings for the Kerberos library - /etc/krb5.conf.
[logging]
default = FILE: /var/log/krb5libs.log
kdc = FILE: /var/log/krb5kdc.log
admin_server = FILE: /var/log/kadmind.log
[libdefaults]
default_realm = IT-DYNAMICS.RU - Active Directory Domain
dns_lookup_realm = true - eliminates the need to manually register the server
dns_lookup_kdc = true - eliminates the need to manually register the server
ticket_lifetime = 24h
forwardable = yes
[domain_realm]
.it-dynamics.ru = IT-DYNAMICS.RU
.it-dynamics.ru = IT-DYNAMICS.RU
[appdefaults]
pam = {
debug = false
ticket_lifetime = 36000
renew_lifetime = 36000
forwardable = true
krb4_convert = false
}
And finally, you need to configure Samba itself.
[global]
clustering = yes
netbios name = smbcluster
workgroup = otd100
security = ADS
realm = IT-DYNAMICS.RU
encrypt passwords = yes
client lanman auth = no
client ntlmv2 auth = yes
passdb backend = tdbsam
groupdb: backend = tdb
idmap backend = tdb2
idmap uid = 1000000-2000000
idmap gid = 1000000-2000000
fileid: algorithm = fsname
vfs objects = gpfs fileid
gpfs: sharemodes = No
force unknown acl user = yes
nfs4: mode = special
nfs4: chown = yes
nfs4: acedub = merge
registry shares = yes
The key parameter in /etc/samba/smb.conf is “clustering = yes”. Enable clustering support. In the parameters "netbios name" we register the name of our cluster, which will be common to all nodes.
In order to implement transparent management of shared resources, it is necessary to enable registry - “registry shares = yes” in the Samba settings. Otherwise, if the settings of public folders are contained in smb.conf, we will be forced to synchronize this file between all nodes in the cluster.
In any case, “/etc/samba/smb.conf” should be the same on all nodes.
To successfully authorize users, a Samba cluster must be entered into an Active Directory domain with the command: net ads join -U Administrator
Where is “Administrator”, a user with rights to add computers to the domain.
CTDB is delivered as a separate package. Source code can be downloaded from ctdb.samba.org . There are also compiled versions for RHEL x64. For x86, you can download src.rpm and compile it yourself.
The CTDB parameters are in the /etc/sysconfig/ctdb.conf file.
This file should also be the same on all nodes of the cluster.
The most important parameters:
CTDB_RECOVERY_LOCK = / gpfs-storage / ctdb / lock
Specifies the location of the lock file that is used when selecting “recovery master” when recovering from a crash. Must be located on a cluster file system with lock support.
CTDB_PUBLIC_INTERFACE = eth1
The interface through which clients will interact with the cluster.
CTDB_PUBLIC_ADDRESSES = / etc / ctdb / public_addresses the path to the file containing the possible public ip addresses through which the cluster will be operated.
CTDB_MANAGES_SAMBA = yes
The CTDB daemon manages Samba services. This is convenient for Samba to work correctly in a cluster. CTDB will start or shut down Samba itself when necessary. At the same time, Samba should be removed from startup.
CTDB_MANAGES_WINBIND = yes
Similar to the previous case - Winbind control.
CTDB_NODES = / etc / ctdb / nodes
List of internal addresses of the catch cluster. The nodes file must be unique on all nodes.
In the file / etc / ctdb / public_addresses it is necessary to register all possible public ip addresses for connecting clients.
In the / etc / ctdb / nodes file, you need to register internal ip addresses of all cluster nodes.
There are two ways to load balance:
Immediately, we note that none of the methods allows balancing depending on server load. Balancing by and large comes down to alternately redirecting clients to different nodes in the cluster.
In this case, several ip addresses are assigned to the DNS for a single cluster name. When clients call, the DNS server in turn gives them different cluster ip addresses. Thus, each next client connects to a new ip address and so on in a circle.
In this case, the entire cluster is presented to clients through one ip address. One of the nodes is selected as LVSMaster. It is assigned an ip address of the cluster. All customers send a request to this address. Then LVSMaster forwards the request to one of the nodes. The node, in turn, directly responds to the client without the involvement of LVSMaster.
A scheme using LVS can give very good results with multiple reads. While in write operations, everything will rest on the speed and network bandwidth of LVSMaster.
Control is done using the ctdb command. The default is run on the current node. Using the "-n" key, you can specify another node.
Ctdb status - shows the status of the cluster
Number of nodes: 2
pnn: 0 172.0.16.101 OK
pnn: 1 172.0.16.102 OK (THIS NODE)
Generation: 985898984
Size: 2
hash: 0 lmaster: 0
hash: 1 lmaster: 1
Recovery mode: NORMAL (0)
Recovery master: 0
The state of the node can be:
RECOVERY MASTER — The node selected by the Recovery Wizard.
Ctdb ip shows public ip addresses of the cluster and their distribution among nodes
Public IPs on node 1
128.0.16.110 node [1] active [eth0] available [eth0] configured [eth0]
128.0.16.111 node [0] active [] available [eth0] configured [eth0]
The first line is the current node on which the command is executed.
Ctdb pnn - displays the node number on which the command is executed
Ctdb disable - set the current node to Disable
Ctdb enable - return from the Disable position
Ctdb stop - move the current node to the Stop position (the cluster will reconfigure)
Ctdb continue - return from the Stop position (the cluster will be reconfigured)
moveip public_ip node manually transfers a public ip address from one node to another
ctdb getdbmap - displays a list of CTDB databases.
Number of databases: 13
dbid: 0x1c904dfd name: notify_onelevel.tdb path: /var/ctdb/notify_onelevel.tdb.0
dbid: 0x435d3410 name: notify.tdb path: /var/ctdb/notify.tdb.0
dbid: 0x42fe72c5 name: locking.tdb path: /var/ctdb/locking.tdb.0
dbid: 0x1421fb78 name: brlock.tdb path: /var/ctdb/brlock.tdb.0
dbid: 0xc0bdde6a name: sessionid.tdb path: /var/ctdb/sessionid.tdb.0
dbid: 0x17055d90 name: connections.tdb path: /var/ctdb/connections.tdb.0
dbid: 0xf2a58948 name: registry.tdb path: /var/ctdb/persistent/registry.tdb.0 PERSISTENT
dbid: 0x63501287 name: share_info.tdb path: /var/ctdb/persistent/share_info.tdb.0 PERSISTENT
dbid: 0x92380e87 name: account_policy.tdb path: /var/ctdb/persistent/account_policy.tdb.0 PERSISTENT
dbid: 0x7bbbd26c name: passdb.tdb path: /var/ctdb/persistent/passdb.tdb.0 PERSISTENT
dbid: 0x2672a57f name: idmap2.tdb path: /var/ctdb/persistent/idmap2.tdb.0 PERSISTENT
dbid: 0xe98e08b6 name: group_mapping.tdb path: /var/ctdb/persistent/group_mapping.tdb.0 PERSISTENT
dbid: 0xb775fff6 name: secrets.tdb path: /var/ctdb/persistent/secrets.tdb.0 PERSISTENT
ctdb shutdown - stop the ctdb daemon (equivalent to service stdb stop)
In the folder "/ etc / ctdb" is the script "notify.sh". It is called each time when the health condition of the node changes. You can write to it, for example, sending an SNMP Trap or sending messages by email to the administrator.
The article showed the principles of organization of the Samba failover service. Key points are:
Samba is a CIFS service designed to provide the semantics of the CIFS protocol (and therefore access from machines running Windows) to an environment that uses the POSIX file system. The main function of Samba is to translate the rich semantics that Windows-based clients use to the much poorer semantics of the POSIX file system.
')
To produce such conversions, Samba uses a variety of internal metadata databases containing additional information used in converting semantics.
Additional parameters in particular are responsible for such a thing as the simultaneous opening of the same file from different clients and much more.
This information is necessarily processed before directly opening the file in POSIX.
Thus, transparent access from Windows clients to the POSIX file system is performed.
Fault tolerance Samba is based on three provisions:
- Samba Metadata Database Recovery
- Availability of user files based on cluster file system
- Network mechanism of protection against failures, which consists in transferring an IP address from a failed node to a working node
This article describes only the mechanism for creating a fault-tolerant CIFS service. A prerequisite for its implementation is the use of a parallel cluster file system, which is used directly to store files.
The description of cluster systems is beyond the scope of this article. As an example, you can use the GPFS or Luster file systems.
Metadata Bases - Trivial Database
Normal non-clustered versions of Samba use a very simple and resource-intensive database called the Trivial Database (TDB) to store data.
TDB is organized on a key-value basis and is similar in organization to Berkley DB. TDB provides very fast multiple read and write access from various processes on a POSIX system. Memory reflection (mmap) is supported on most architectures.
Each client connection to the file system is serviced by its own smbd daemon process. Between themselves, these processes interact through the TDB database.
The first attempts to implement a cluster version of SAMBA were simply to place files containing TDB on a cluster file system, such as GPFS or Luster.
Such SAMBA implementations worked, but were extremely slow. The reduction in speed was due to high overhead and latency in the synchronization protocols of cluster file systems. At the same time, in order for Samba to work successfully, it is necessary to provide very fast access to TDB.
The foundation of the functioning of cluster file systems is that they prevent data from being lost. Even if the client started recording data, and the node where it was supposed to be recorded, failed, they will not be lost.
Thus, the cluster file system must either write data to the shared storage or send changes to all nodes of the cluster.
However, this statement is not quite true for Samba metadata. In a certain situation, the loss of this data will not affect the ability to perform the necessary semantics conversion between CIFS and POSIX.
Thus, it becomes possible to implement a cluster system that does not require shared storage of metadata and data replication when writing.
Just say that this does not apply to all metadata.
There are two types of TDB databases - permanent and non-permanent.
Permanent (Persistent) - contain long-term information that should be preserved even after a restart. These databases are more often used for reading than for writing. The speed of access to write to this type of database is not critical. The main thing here is reliability.
Non - persistent — such as a lock or session database. The data stored here has a short life cycle. The frequency of writing to these databases is very high. They are also often referred to as “normal TDB.”
For successful Samba operation, high performance is especially important when working with “normal TDB”.
Loss of information is possible only for non-permanent databases.
The tables below list and describe the bases used in the cluster implementation of Samba.
Table 1 Constant (Persistent) TDB Base
| Name | DESCRIPTION |
| account_policy | Samba / NT account policy settings, including password expiration settings. |
| group_mapping | Table of group mapping / SID Windows groups UNIX. |
| passdb | Exists only when using tdbsam. This file stores SambaSAMAccount information. It must be remembered that this file requires that information about POSIX user accounts is available from the / etc / passwd file, or from another system source. |
| registry | A read-only Samba database that stores the skeleton of the Windows registry, which provides support for exporting various database tables through winreg RPC (remote procedure calls). |
| secrets | This file stores the SID of the workgroup / domain / computer, the LDAP directory update password, and other important environmental information that Samba needs to work. This file contains very important information that needs to be protected. It is stored in the PRIVATE_DIR directory. |
| share_info | Stores the ACL information for each resource. |
| Idmap2 | IDMAP Winbindd Database. |
Table 2 Temporary (Normal) TDB Bases
| Name | DESCRIPTION |
| brlock | Information about locking byte ranges. |
| Locking | File system lock table |
| connections | A temporary cache of current connection information used to track the maximum number of connections. |
| Notify_onelevel | Presumably used for messaging between ctdb daemons |
| notify | Presumably used for messaging between ctdb daemons |
| sessionid | Temporary cache for various utmp session information and maintenance. |
Thus, we see what information we can lose. This is information about sessions, locks, as well as, apparently (no data on the Internet), specific information necessary for the operation of the cluster.
When a node fails, all open files on it will be closed, respectively, the loss of the above information will not be critical.
CTDBD daemon and TDB database operation in a cluster
The key component in the Samba cluster is the CTDBD daemon. It provides support for a cluster version of the TDB database, called CTDB (Cluster Trivial DataBase), with the possibility of automatic recovery.
CTDBD also monitors the cluster nodes and performs its automatic reconfiguration in case of failure.
Providing load balancing is another CTDBD task.
Depending on the type of database, it is processed differently.
Work with temporary TDB
A key feature of temporary TDB is that they do not need to contain all the records within the cluster. In most cases, temporary TDBs contain only entries related to the connections of this particular node. Accordingly, when it falls, only this data will be lost.
The CTDB system uses a distributed protocol for operations on metadata databases between the CTDBD daemons on each node, as well as a local protocol for intra-node communication between the Samba daemons and the CTDBD daemons.
The CTDB design uses a two-tier record storage system. At the first level, the location master is defined for each entry. This host is attached to the record by its key.
At the second level, the roving "data master" (roaming or roaming data master) is defined. This is the last node that modified the record.
The “Location master” always knows on which node the record is located and, accordingly, which node is the “data master”. The “data master” in turn contains the most current copy of the record.
Each record contains a global sequence number - RSN (record sequence number) - a 64-bit integer that is incremented each time the “data master” is moved from one node to another. The change of ownership of the “Data Master” entry always occurs via the “Location master”.
The node contains only those records in the local TDB to which it already had access. Data is not automatically distributed to other nodes, and can be transferred only on request.
Only one node contains the current copy of the record - “Data Master”. When a node wants to write or read a record, it first checks whether it is a “data master” for that node. If so, it records directly in TDB. If not, then it requests the current contents of the record from the current data master, takes the data master role for itself and then makes a direct recording.
Thus, writing and reading data always happens locally, which significantly improves performance.
When a node dies, the records for which it was a “data master” are lost.
CTDBD starts the recovery process. To do this, select the node master of the recovery process - «recovery master». After a node is selected, on the cluster file system, it sets a lock on a specific file (which is specified in the configuration) so that other nodes can no longer claim the role of “recovery master”.
Recover Master collects the most current versions of records from all sites. Relevance is determined by the RSN value. The most relevant is a record with a large RSN.
Work with constant TDB
For this database, each node always has a complete, up-to-date copy of the database.
Reading is always from a local copy. When a node needs to write, it performs a transaction that completely blocks the entire database on all nodes.
Then he performs the necessary write operations. After that, the changes are written to the local copies of the database on all nodes and the transaction is completed.
Thus, on all nodes of the cluster always contains a complete and current copy of the database. Delays that occur during the synchronization process are not critical, due to the non-high frequency of changes in these databases.
If one of the nodes fails, all the necessary information is on the rest of the cluster members.
Network failure protection mechanism
In addition to protecting metadata databases, CTDBD uses an integrated TCP / IP protocol failover protection mechanism.
It consists of using a cluster of a set of public IP addresses that are distributed among the cluster nodes. These addresses can be transferred from node to node by updating the Address Resolution Protocol (ARP).
In case of failure of a node, all its public ip addresses will be transferred to the working nodes.
Public are the addresses through which the customer calls. For communications between the nodes of the cluster, internal ip addresses are used.
The host that took over the IP address of the other knows only what they were about old TCP connections, and does not know the “TCP squence number” connections. Accordingly, they can not continue. As well as the client, does not know anything about the fact that connections are now made with another node.
In order to avoid delays associated with switching the connection, the following method is used. To understand this technique, you need to understand the basic principles of the TCP protocol.
The new node, receiving its ip address, sends the client a packet with the ACK flag and the deliberately incorrect “Squence number” equal to zero. In response, the client, in accordance with the rules of the TCP protocol, sends back an ACK Reply packet with the correct “squence number”. Having received the correct “squence number” node forms a packet with the RST flag and this “squence number”. Upon receiving it, the client immediately restarts the connection.
Delays are very minimal. Without using this technique, the client can wait for a long time from the server of the TCP ACK packet.
On practice
As mentioned above, if one of the nodes fails and the ip address is transferred, the entire responsibility for continuing work after the failure lies with the client. All open files associated with the failed node are closed.
If you copy or read any file in Windows Explorer, then you will get an error if it fails. However, if you use tools that can re-connect after losing the connection, everything will go smoothly. For example, the xcopy utility with the “/ z” key. When copying files using this utility, you will get only a small delay at the time of switching the ip address. Then, continue copying.
Connection to network resources is also not lost.
If you open any file in the editor, and the moment of saving does not occur at the ip address relocation, then the failures also do not affect the work.
Thus, part of the responsibility for restoring work after a failure in this case is transferred to the client.
Configuring Samba Cluster
Setting up a cluster consists of two steps:
- Configuring the Samba daemon to work in a cluster
- CTDB Setup
Configuring Samba and Related Services
Starting with version 3.3, Samba source tests have built-in clustering support. However, to work in a cluster, you must compile the package using special keys.
From enterprisesamba.com you can download a compiled version of Samba with clustering support for popular distributions: RHEL, SLES, Debian.
Important note. In order for Windows clients to successfully authenticate to the Samba cluster, it is advisable to use external authorization. For example, through Active Directory.
For Windows users accessing the Posix file system, Samba establishes a correspondence between the Windows user and the POSIX system user (for example, Linux). A Windows user must access the POSIX file system from the name of any known POSIX user’s operating system. Windows user authorization occurs regardless of user authorization in the POSIX OS.
Those. In order for a Windows user to access, you must:
- Create a local user in POSIX operating system on behalf of which the Windows user will work
- Create a Windows user in the Samba database and set a password for it
- Establish communication between these users.
The table of relationships between users and passwords can be stored in the CTDB database and distributed within the cluster. However, the local user base does not have this capability. Those. Every time we create users in Samba, we will need to create corresponding local accounts on all nodes in the cluster.
It is not comfortable. In order to avoid this, it makes sense to use an external database in conjunction with the local user base. In our case, integration with Active Directoty is used. Samba cluster is a member of the domain.
In the /etc/nsswitch.conf file you need to register:
passwd: files winbind
group: files winbind
shadow: files winbind
This means that in addition to local files, the search for users and groups will be carried out in the Active Directory through winbind. The winbind service allows Windows domain users to authenticate on Unix machines. Thus, transparent access control is performed.
Authorization in the Active Directory domain is carried out using the Kerberos protocol. You must make the appropriate settings for the Kerberos library - /etc/krb5.conf.
[logging]
default = FILE: /var/log/krb5libs.log
kdc = FILE: /var/log/krb5kdc.log
admin_server = FILE: /var/log/kadmind.log
[libdefaults]
default_realm = IT-DYNAMICS.RU - Active Directory Domain
dns_lookup_realm = true - eliminates the need to manually register the server
dns_lookup_kdc = true - eliminates the need to manually register the server
ticket_lifetime = 24h
forwardable = yes
[domain_realm]
.it-dynamics.ru = IT-DYNAMICS.RU
.it-dynamics.ru = IT-DYNAMICS.RU
[appdefaults]
pam = {
debug = false
ticket_lifetime = 36000
renew_lifetime = 36000
forwardable = true
krb4_convert = false
}
And finally, you need to configure Samba itself.
[global]
clustering = yes
netbios name = smbcluster
workgroup = otd100
security = ADS
realm = IT-DYNAMICS.RU
encrypt passwords = yes
client lanman auth = no
client ntlmv2 auth = yes
passdb backend = tdbsam
groupdb: backend = tdb
idmap backend = tdb2
idmap uid = 1000000-2000000
idmap gid = 1000000-2000000
fileid: algorithm = fsname
vfs objects = gpfs fileid
gpfs: sharemodes = No
force unknown acl user = yes
nfs4: mode = special
nfs4: chown = yes
nfs4: acedub = merge
registry shares = yes
The key parameter in /etc/samba/smb.conf is “clustering = yes”. Enable clustering support. In the parameters "netbios name" we register the name of our cluster, which will be common to all nodes.
In order to implement transparent management of shared resources, it is necessary to enable registry - “registry shares = yes” in the Samba settings. Otherwise, if the settings of public folders are contained in smb.conf, we will be forced to synchronize this file between all nodes in the cluster.
In any case, “/etc/samba/smb.conf” should be the same on all nodes.
To successfully authorize users, a Samba cluster must be entered into an Active Directory domain with the command: net ads join -U Administrator
Where is “Administrator”, a user with rights to add computers to the domain.
CTDB Setup
CTDB is delivered as a separate package. Source code can be downloaded from ctdb.samba.org . There are also compiled versions for RHEL x64. For x86, you can download src.rpm and compile it yourself.
The CTDB parameters are in the /etc/sysconfig/ctdb.conf file.
This file should also be the same on all nodes of the cluster.
The most important parameters:
CTDB_RECOVERY_LOCK = / gpfs-storage / ctdb / lock
Specifies the location of the lock file that is used when selecting “recovery master” when recovering from a crash. Must be located on a cluster file system with lock support.
CTDB_PUBLIC_INTERFACE = eth1
The interface through which clients will interact with the cluster.
CTDB_PUBLIC_ADDRESSES = / etc / ctdb / public_addresses the path to the file containing the possible public ip addresses through which the cluster will be operated.
CTDB_MANAGES_SAMBA = yes
The CTDB daemon manages Samba services. This is convenient for Samba to work correctly in a cluster. CTDB will start or shut down Samba itself when necessary. At the same time, Samba should be removed from startup.
CTDB_MANAGES_WINBIND = yes
Similar to the previous case - Winbind control.
CTDB_NODES = / etc / ctdb / nodes
List of internal addresses of the catch cluster. The nodes file must be unique on all nodes.
In the file / etc / ctdb / public_addresses it is necessary to register all possible public ip addresses for connecting clients.
In the / etc / ctdb / nodes file, you need to register internal ip addresses of all cluster nodes.
Load balancing
There are two ways to load balance:
- Using Round-Robin DNS
- Lvs
Immediately, we note that none of the methods allows balancing depending on server load. Balancing by and large comes down to alternately redirecting clients to different nodes in the cluster.
Balancing Round-Robin DNS
In this case, several ip addresses are assigned to the DNS for a single cluster name. When clients call, the DNS server in turn gives them different cluster ip addresses. Thus, each next client connects to a new ip address and so on in a circle.
LVS Balancing
In this case, the entire cluster is presented to clients through one ip address. One of the nodes is selected as LVSMaster. It is assigned an ip address of the cluster. All customers send a request to this address. Then LVSMaster forwards the request to one of the nodes. The node, in turn, directly responds to the client without the involvement of LVSMaster.
A scheme using LVS can give very good results with multiple reads. While in write operations, everything will rest on the speed and network bandwidth of LVSMaster.
Cluster management
Control is done using the ctdb command. The default is run on the current node. Using the "-n" key, you can specify another node.
Ctdb status - shows the status of the cluster
Number of nodes: 2
pnn: 0 172.0.16.101 OK
pnn: 1 172.0.16.102 OK (THIS NODE)
Generation: 985898984
Size: 2
hash: 0 lmaster: 0
hash: 1 lmaster: 1
Recovery mode: NORMAL (0)
Recovery master: 0
The state of the node can be:
- OK - normal operation
- DISCONNECTED - the node is not physically accessible.
- DISABLED - the node is disabled by the administrator. At the same time, it functions within the cluster, but its public ip address is transferred to other nodes and no services on it are executed. However, the node is able to serve parts of the TDB database.
- UNHEALTHY - problems in the work node. The CTDB daemon is functioning normally, but the public ip is transferred to other nodes and no services are working.
- BANNED - Node made too frequent attempts to recover and was disabled for a certain period. After the end of this period, the node will automatically try to return to the system.
- STOPPED - The node is stopped and does not participate in the cluster, but is able to receive control commands.
- PARTIALLYONLINE - The node is working, but some of the interfaces serving public ip addresses are disabled. At least one interface must be available.
- Recovery mode - cluster operation mode:
- NORMAL - working mode
- RECOVERY - the cluster is in recovery mode. All cluster databases are locked. Services do not work.
RECOVERY MASTER — The node selected by the Recovery Wizard.
Ctdb ip shows public ip addresses of the cluster and their distribution among nodes
Public IPs on node 1
128.0.16.110 node [1] active [eth0] available [eth0] configured [eth0]
128.0.16.111 node [0] active [] available [eth0] configured [eth0]
The first line is the current node on which the command is executed.
Ctdb pnn - displays the node number on which the command is executed
Ctdb disable - set the current node to Disable
Ctdb enable - return from the Disable position
Ctdb stop - move the current node to the Stop position (the cluster will reconfigure)
Ctdb continue - return from the Stop position (the cluster will be reconfigured)
moveip public_ip node manually transfers a public ip address from one node to another
ctdb getdbmap - displays a list of CTDB databases.
Number of databases: 13
dbid: 0x1c904dfd name: notify_onelevel.tdb path: /var/ctdb/notify_onelevel.tdb.0
dbid: 0x435d3410 name: notify.tdb path: /var/ctdb/notify.tdb.0
dbid: 0x42fe72c5 name: locking.tdb path: /var/ctdb/locking.tdb.0
dbid: 0x1421fb78 name: brlock.tdb path: /var/ctdb/brlock.tdb.0
dbid: 0xc0bdde6a name: sessionid.tdb path: /var/ctdb/sessionid.tdb.0
dbid: 0x17055d90 name: connections.tdb path: /var/ctdb/connections.tdb.0
dbid: 0xf2a58948 name: registry.tdb path: /var/ctdb/persistent/registry.tdb.0 PERSISTENT
dbid: 0x63501287 name: share_info.tdb path: /var/ctdb/persistent/share_info.tdb.0 PERSISTENT
dbid: 0x92380e87 name: account_policy.tdb path: /var/ctdb/persistent/account_policy.tdb.0 PERSISTENT
dbid: 0x7bbbd26c name: passdb.tdb path: /var/ctdb/persistent/passdb.tdb.0 PERSISTENT
dbid: 0x2672a57f name: idmap2.tdb path: /var/ctdb/persistent/idmap2.tdb.0 PERSISTENT
dbid: 0xe98e08b6 name: group_mapping.tdb path: /var/ctdb/persistent/group_mapping.tdb.0 PERSISTENT
dbid: 0xb775fff6 name: secrets.tdb path: /var/ctdb/persistent/secrets.tdb.0 PERSISTENT
ctdb shutdown - stop the ctdb daemon (equivalent to service stdb stop)
Cluster Monitoring
In the folder "/ etc / ctdb" is the script "notify.sh". It is called each time when the health condition of the node changes. You can write to it, for example, sending an SNMP Trap or sending messages by email to the administrator.
Conclusion
The article showed the principles of organization of the Samba failover service. Key points are:
- The possibility of losing certain metadata without disrupting the process of converting CIFS to POSIX semantics
- Part of responsibility for continuing work after a failure has been transferred to the client’s side.
- Files opened on a cluster node are closed at the time of failure
- Load balancing is performed by successive redirection of clients to different nodes of the cluster, regardless of the load.
Source: https://habr.com/ru/post/91188/
All Articles