reCAPTCHA: the added value of anti-spam.
Employees at Carnegie Mellon University estimate that people fill out 60 million captchas every day around the world. Taking the time to fill in captcha in 10 seconds, we get more than 160,000 man-hours (or about 19 YEARS!) In a day.
And they decided to try to direct at least a small part of the efforts that were wasted to a useful business, namely the recognition of books.
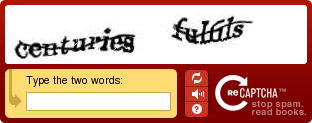
The essence of their ideas is as follows: on RECAPTCHE, TWO consecutive words from the book are given, one of which has not mastered the text recognition system. RECAPTCHA checks the known word, and adds the variant of recognition of the unknown to its base. Both of these words are distorted by ordinary and special captcha filters so that the user doesn’t shame by offering the option “upyachka”, for example.
Demo and details here:
The university offers ready-made solutions for forums / blogs / mail. IMHO, if the technology finds its application, the webdvanol will finally do something really useful.
And they decided to try to direct at least a small part of the efforts that were wasted to a useful business, namely the recognition of books.
The essence of their ideas is as follows: on RECAPTCHE, TWO consecutive words from the book are given, one of which has not mastered the text recognition system. RECAPTCHA checks the known word, and adds the variant of recognition of the unknown to its base. Both of these words are distorted by ordinary and special captcha filters so that the user doesn’t shame by offering the option “upyachka”, for example.
Demo and details here:
The university offers ready-made solutions for forums / blogs / mail. IMHO, if the technology finds its application, the webdvanol will finally do something really useful.
')
Source: https://habr.com/ru/post/8877/
All Articles