Multi-Master replication in MySQL
This article will discuss the process of deploying a fault-tolerant database subsystem based on MySQL server.
Before reading, I advise you to read this article .
At work, the question arose of creating a mirror site for another region (Asia). Because the time of passing the packages there is quite large, the geographical distance affects, and the Great Chinese Firewall is also not canceled, it was decided to create a mirror in the Asian region. With the transfer of the engine, no problems were foreseen, user files can be safely synchronized via rsync, but there is a problem with the database. What if a user added an object in Asia? It is necessary that this object was visible not only to users of the local mirror, but also to everyone else.
')
I started exploring the issue with MySQL clustering. It turned out many interesting details. For example, the fact that the server version included in the Ubuntu distribution (I use it on the test bench) does not support the NDB (Network Data Base) Storage Engine. You must install either a version of mysql-max that is rumored to support NDB, or mysql-cluster. The most interesting thing is that there are no deb-packages for them, so you should either install from binaries or from sources. I did not succeed in installing binary files. I could not remove the old server (the package is removed, and the files are all in place). Having honestly stumbled with this for two days, I quit this undertaking. I did not try to compile from the source, but I think this is the best option.
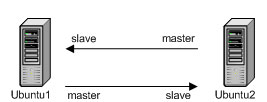
In general, the next stage of the survey was replication. Then I realized that this is what I need. There is a central server, and there is a replica in the region that will pull updates from it. But we must make sure that updates from the replica fall into the main database. So, it is necessary to make a master-master replication. Those. the first server will be the master for the second (the second will connect to it as a slave), and the second will be the master for the first (the first connects to it as a slave). Tests conducted on virtualok based on Ubuntu Server 9.10
So, the ubuntu1 server (192.168.0.21), mysql config:
For the second, similarly, just another ip master and server number.
Now restart the server. Then we create the user replication, give it the rights to replicate:
Further it is necessary to tie the slaves to their masters. This is done like this:
Binding ubuntu1 as a wizard to ubuntu2:
First, we block entry to the database.
Read more about it here.
From there we take the value of File and position and connect the wizard.
After that, you can check the connection either through
either through
If there are no errors, the wizard is connected.
Now we connect this server as the master for the first (it is done in the same way).
As a result, we have a system of two servers, we make a change to any server and it replicates to the second.
But this seemed to me a little. And if you want to add a third server? At first I was thinking about linear topology.
ubuntu1 <-> ubuntu2 <-> ubunt3 and even the star topology. But alas, it was far from reality. MySQL does not allow one slave to have multiple wizards. And in a linear topology this would be ubuntu2. If someone knows how to tie one slave to several masters I will be grateful for the information.
The star does not fit, linear, too, remains a ring. And I will try, I thought.
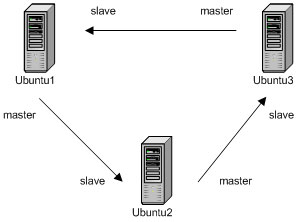
It turns out that in this scheme, each server has only one master, and due to the fact that the ring is closed, updates will reach all servers from anywhere in the ring. It is important to mention here that in order for the master to transfer not only its own updates to the slave, but also updates to its master, you must add the following line to the [mysqld] section of my.cnf:
respectively, in the configuration of each server.
I checked and was pleasantly surprised that the scheme worked. Wherever the base is changed, the changes are actually replicated to other servers.
When simultaneously adding new lines containing auto-increment fields to different master servers, a conflict may arise. To prevent this from happening, you need to change the step of the sequence of auto-increments on the database servers.
Having selected the correct (non-conflicting) values of these parameters on different wizards, the servers used in the multi-master configuration will use non-conflicting AUTO_INCREMENT values when inserting records. For example, for N master servers, set these values:
For example, using auto_increment_increment = 10 and auto_increment_offset = 3, the following field 3, 13, 23 values will be generated. And using 10, 7, these will be 7, 17, 27, etc.
After all this, I could not help but try to drop one of the servers. Pull the power out of ubuntu2. Then we load it. What happens?
With subsequent changes to ubnutu2, they are easily replicated to ubuntu3 and ubuntu1. But the changes made on ubuntu2 to other servers are not replicated. We look at the show slave status on ubuntu3 and see that it has lost its master.
As a recipe, I can offer the following:
After the start of the database server, untie the master from the slave of the current server, and bind it again. Because in the topology, there is only one slave ring for any server, this simplifies the task. The algorithm will be something like this:
1. ubuntu2 turned off on power and booted again
2. ubuntu2 at home:
- blocks replicated database for writing:
- looks at the name and position in the log:
2. ubuntu2 through mysql the client comes on the slave (ubuntu3)
- untie himself from the slave
- declares himself a master:
- reattaches the slave:
While the implementation of this script is not ready, I think on what to write it perl / php / python / bash ...
I will be glad to hear the thoughts of habrasoobshchestva on this topic. Write if the article turned out to be useful, plans to deal with clustering and replicate clusters.
Before reading, I advise you to read this article .
At work, the question arose of creating a mirror site for another region (Asia). Because the time of passing the packages there is quite large, the geographical distance affects, and the Great Chinese Firewall is also not canceled, it was decided to create a mirror in the Asian region. With the transfer of the engine, no problems were foreseen, user files can be safely synchronized via rsync, but there is a problem with the database. What if a user added an object in Asia? It is necessary that this object was visible not only to users of the local mirror, but also to everyone else.
')
I started exploring the issue with MySQL clustering. It turned out many interesting details. For example, the fact that the server version included in the Ubuntu distribution (I use it on the test bench) does not support the NDB (Network Data Base) Storage Engine. You must install either a version of mysql-max that is rumored to support NDB, or mysql-cluster. The most interesting thing is that there are no deb-packages for them, so you should either install from binaries or from sources. I did not succeed in installing binary files. I could not remove the old server (the package is removed, and the files are all in place). Having honestly stumbled with this for two days, I quit this undertaking. I did not try to compile from the source, but I think this is the best option.
Master-Master replication
In general, the next stage of the survey was replication. Then I realized that this is what I need. There is a central server, and there is a replica in the region that will pull updates from it. But we must make sure that updates from the replica fall into the main database. So, it is necessary to make a master-master replication. Those. the first server will be the master for the second (the second will connect to it as a slave), and the second will be the master for the first (the first connects to it as a slave). Tests conducted on virtualok based on Ubuntu Server 9.10
So, the ubuntu1 server (192.168.0.21), mysql config:
[mysqld]
# ,
server-id = 1
# ,
log-bin = /var/lib/mysql/mysql-bin
# ,
relay-log = /var/lib/mysql/mysql-relay-bin
relay-log-index = /var/lib/mysql/mysql-relay-bin.index
replicate-do-db = test_db
master-host=192.168.0.22 #ubuntu2
master-user=replication
master-password=password_of_user_replication
master-port=3306For the second, similarly, just another ip master and server number.
Now restart the server. Then we create the user replication, give it the rights to replicate:
mysql@ubuntu1> GRANT REPLICATION SLAVE, REPLICATION CLIENT ON *.* TO 'replication'@'192.168.0.22' IDENTIFIED BY 'password';
mysql@ubuntu2> GRANT REPLICATION SLAVE, REPLICATION CLIENT ON *.* TO 'replication'@'192.168.0.21' IDENTIFIED BY 'password';Further it is necessary to tie the slaves to their masters. This is done like this:
Binding ubuntu1 as a wizard to ubuntu2:
First, we block entry to the database.
mysql@ubuntu1> SET GLOBAL read_only = OFF;Read more about it here.
mysql@ubuntu1> show master status;
+------------------+----------+--------------+------------------+
| File | Position | Binlog_Do_DB | Binlog_Ignore_DB |
+------------------+----------+--------------+------------------+
| mysql-bin.000006 | 7984 | | |
+------------------+----------+--------------+------------------+
1 row in set (0,00 sec)From there we take the value of File and position and connect the wizard.
mysql@ubuntu2> slave stop; #
mysql@ubuntu2> CHANGE MASTER TO MASTER_HOST = "192.168.0.22", MASTER_USER = "replication", MASTER_PASSWORD = "password_of_user_replication", MASTER_LOG_FILE = "mysql-bin.000006", MASTER_LOG_POS = 7984;
mysql@ubuntu2> slave start;After that, you can check the connection either through
mysql@ubuntu2>load data from master;either through
mysql@ubuntu2> show slave status;If there are no errors, the wizard is connected.
Now we connect this server as the master for the first (it is done in the same way).
As a result, we have a system of two servers, we make a change to any server and it replicates to the second.
Multi-Master replication
But this seemed to me a little. And if you want to add a third server? At first I was thinking about linear topology.
ubuntu1 <-> ubuntu2 <-> ubunt3 and even the star topology. But alas, it was far from reality. MySQL does not allow one slave to have multiple wizards. And in a linear topology this would be ubuntu2. If someone knows how to tie one slave to several masters I will be grateful for the information.
The star does not fit, linear, too, remains a ring. And I will try, I thought.
It turns out that in this scheme, each server has only one master, and due to the fact that the ring is closed, updates will reach all servers from anywhere in the ring. It is important to mention here that in order for the master to transfer not only its own updates to the slave, but also updates to its master, you must add the following line to the [mysqld] section of my.cnf:
log-slave-updatesrespectively, in the configuration of each server.
I checked and was pleasantly surprised that the scheme worked. Wherever the base is changed, the changes are actually replicated to other servers.
Auto-increment fields
When simultaneously adding new lines containing auto-increment fields to different master servers, a conflict may arise. To prevent this from happening, you need to change the step of the sequence of auto-increments on the database servers.
- auto_increment_increment determines the AUTO_INCREMENT change step.
- auto_increment_offset defines the initial value of the increment
Having selected the correct (non-conflicting) values of these parameters on different wizards, the servers used in the multi-master configuration will use non-conflicting AUTO_INCREMENT values when inserting records. For example, for N master servers, set these values:
- Set auto_increment_increment to N on each wizard.
- On each of the N masters set different values of auto_increment_offset using 1, 2, ..., N.
For example, using auto_increment_increment = 10 and auto_increment_offset = 3, the following field 3, 13, 23 values will be generated. And using 10, 7, these will be 7, 17, 27, etc.
Fault tolerance
After all this, I could not help but try to drop one of the servers. Pull the power out of ubuntu2. Then we load it. What happens?
With subsequent changes to ubnutu2, they are easily replicated to ubuntu3 and ubuntu1. But the changes made on ubuntu2 to other servers are not replicated. We look at the show slave status on ubuntu3 and see that it has lost its master.
As a recipe, I can offer the following:
After the start of the database server, untie the master from the slave of the current server, and bind it again. Because in the topology, there is only one slave ring for any server, this simplifies the task. The algorithm will be something like this:
1. ubuntu2 turned off on power and booted again
2. ubuntu2 at home:
- blocks replicated database for writing:
mysql@ubuntu2> SET GLOBAL read_only = OFF;- looks at the name and position in the log:
mysql@ubuntu2> show master status;2. ubuntu2 through mysql the client comes on the slave (ubuntu3)
- untie himself from the slave
mysql@ubuntu3> slave stop;- declares himself a master:
mysql@ubuntu3> CHANGE MASTER TO MASTER_HOST = "192.168.0.22", MASTER_USER = "replication", MASTER_PASSWORD = "password_of_user_replication", MASTER_LOG_FILE = "mysql-bin.000006", MASTER_LOG_POS = 5161; with the log name and position obtained in the previous step.- reattaches the slave:
mysql@ubuntu3> slave start;While the implementation of this script is not ready, I think on what to write it perl / php / python / bash ...
I will be glad to hear the thoughts of habrasoobshchestva on this topic. Write if the article turned out to be useful, plans to deal with clustering and replicate clusters.
Source: https://habr.com/ru/post/87394/
All Articles