LogParser - a familiar look at unusual things
When I once again used LogParser, then to penetrate and other people's experiences, I entered its name into the search on Habré. As a result - the message "Surprisingly, but the search has not yielded results." This is truly amazing when such an interesting tool is overlooked. It's time to fill this gap. So, meet the LogParser . A small but damn useful utility for SQL lovers.
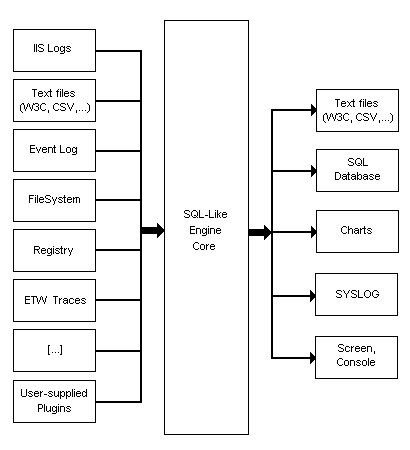
From the name of the tool, it would seem very difficult to understand what it does in the SQL section. And the truth is that it is the same LogParser, like the ChartGenerator. In the sense that he copes with both tasks with the same success. In general, I would describe it as a heterogeneous data SQL processor. The concept of work in general is such that it takes data from a certain format and converts it into a tabular view (in fact, it is only at this stage that the parsing is done sometimes). Then, by running some SQL query on these tabular data, it forms a table with the result and saves it again in some format. In short, the chain looks like preparing input data-> SQL processing-> generating output data. Or, as illustrated in the documentation:
It’s time, perhaps, to move from theory to practice, for it is much more visual. Let's start for the seed with this example:
I think many immediately guessed what the mystery happened here. In the familiar and familiar SQL style, we select ... files from the X: \ Folder folder, group these files by MD5, in order to identify duplicates among them by content. Naturally, we discard those cases when the number of such files = 1 (i.e. there are no identical ones). In addition, we organize the found duplicates in descending order of size and display only the top 100 of the most gross. To make sure that the result is correct, look in the Duplicates.csv file. There you will find something in the following spirit:
')
The first value is the MD5 hash of duplicates found, the second is their number and the third is the size. Let us now try to decompose the code of the example in accordance with the previously described concept. Input data is determined by the provider of the input format and some address according to the selected provider. In our case, it is specified with the -i: FS option for the file system. And specific data is addressed (folder X: \ Folder) in the FROM part of our SQL query. A query to the registry, for example, for the \ HKLM \ Software branch would look like this: LogParser.exe -i: REG "SELECT * FROM \ HKLM \ Software". Provider - REG, address - \ HKLM \ Software.
By default, LogParser offers us the following source formats providers:
IIS Log File Input Formats
Generic Text File Input Formats
System Information Input Formats
Special-purpose Input Formats
Already a lot. And given that you can create your own providers - generally wonderful. Later, I will touch on this issue and show how you can create them as “grown-ups” using compiled assemblies, as well as on-the-fly, simply using scripts.
The output artifact format is defined in a similar way. With the -o: CSV option, we indicated that we are interested in the provider for CSV files, and in the INTO part of our SQL query, we addressed the search file to which the result will be saved. By analogy with the input providers, we list the weekends that are available out of the box.
Generic Text File Output Formats
Special-purpose Output Formats
Let's try another example for priming with completely different input and output providers. For example, the frequently encountered task of analyzing web server logs and displaying the top of referring sites.
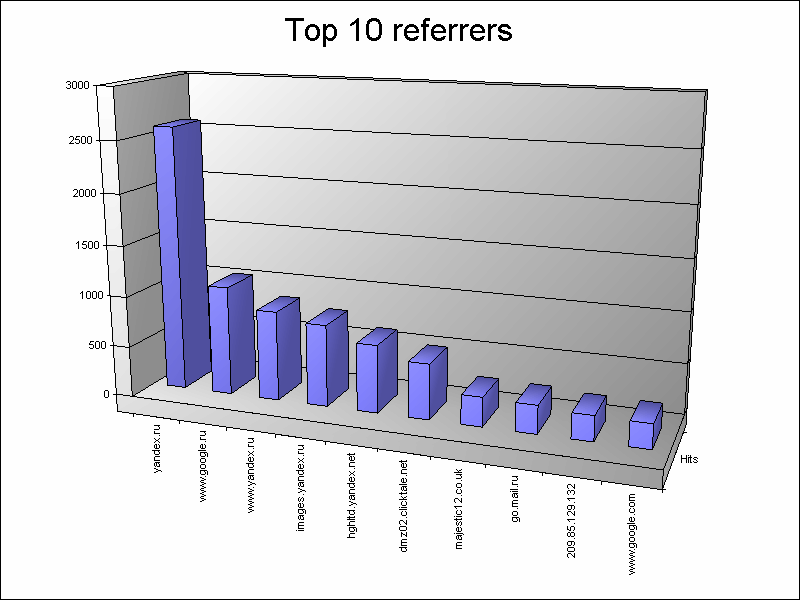
As you can see, LogParser thrashed nearly half a million records in less than 17 seconds with non-trivial conditions on the old Pentium D 2.8, which, in my opinion, is not such a bad result. Well, the main result is in the picture:
It seems to me that this is a terrific tool for database managers :), because it allows us to apply SQL magic where we often wanted, but it was impossible. Behind this thesis, for the time being I will suspend my narration. First of all, it’s possible to talk about LogParser for a long time and it will not fit in the framework of one post. Secondly, I would like to hope that this material is enough to at least slightly interest my colleagues in the workshop and understand how much they share my enthusiasm for this utility. And as soon as they are interested in continuing, I will immediately do it, because there are a lot of unsolved topics left. This is the conversion mode. And the formation of the output directly, as well as using LogParser-templates and XSLT. Incremental mode for working with large amounts of data. Creating your own input formats using the example of C # and JavaScript. Use LogParser from applications. Multvvod and multiple output in multiple files. Familiar with the abundance of subtleties SQL LogParser'a, including the vastness of its functions. Various options and command line options. Subtleties of various providers and their configuration. And of course, more examples of all sorts and different :)
From the name of the tool, it would seem very difficult to understand what it does in the SQL section. And the truth is that it is the same LogParser, like the ChartGenerator. In the sense that he copes with both tasks with the same success. In general, I would describe it as a heterogeneous data SQL processor. The concept of work in general is such that it takes data from a certain format and converts it into a tabular view (in fact, it is only at this stage that the parsing is done sometimes). Then, by running some SQL query on these tabular data, it forms a table with the result and saves it again in some format. In short, the chain looks like preparing input data-> SQL processing-> generating output data. Or, as illustrated in the documentation:
It’s time, perhaps, to move from theory to practice, for it is much more visual. Let's start for the seed with this example:
X:\>LogParser.exe -i:FS -o:CSV "SELECT TOP 100 HASHMD5_FILE(Path) AS Hash, COUNT(*) AS FileCount, AVG(Size) AS FileSize INTO Duplicates.csv FROM X:\Folder\*.* GROUP BY Hash HAVING FileCount > 1 AND FileSize > 0 ORDER BY FileSize DESC"
Statistics:
-----------
Elements processed: 10
Elements output: 2
Execution time: 0.06 secondsI think many immediately guessed what the mystery happened here. In the familiar and familiar SQL style, we select ... files from the X: \ Folder folder, group these files by MD5, in order to identify duplicates among them by content. Naturally, we discard those cases when the number of such files = 1 (i.e. there are no identical ones). In addition, we organize the found duplicates in descending order of size and display only the top 100 of the most gross. To make sure that the result is correct, look in the Duplicates.csv file. There you will find something in the following spirit:
')
Hash,FileCount,FileSize
7EF9FDF4B8BDD5B0BBFFFA14B3DAD42D,2,5321
5113280B17161B4E2BEC7388E617CE91,2,854The first value is the MD5 hash of duplicates found, the second is their number and the third is the size. Let us now try to decompose the code of the example in accordance with the previously described concept. Input data is determined by the provider of the input format and some address according to the selected provider. In our case, it is specified with the -i: FS option for the file system. And specific data is addressed (folder X: \ Folder) in the FROM part of our SQL query. A query to the registry, for example, for the \ HKLM \ Software branch would look like this: LogParser.exe -i: REG "SELECT * FROM \ HKLM \ Software". Provider - REG, address - \ HKLM \ Software.
By default, LogParser offers us the following source formats providers:
IIS Log File Input Formats
- IISW3C: parses IIS log files in the W3C Extended Log File Format.
- IIS: parses IIS log files in the Microsoft IIS Log File Format.
- BIN: parses IIS log files in the Centralized Binary Log File Format.
- IISODBC: Returns IISODBC when I have logged in to the ODBC Log Format.
- HTTPERR: parses HTTP error log files generated by Http.sys.
- URLSCAN: parses log files generated by the URLScan IIS filter.
Generic Text File Input Formats
- CSV: parses comma-separated values text files.
- TSV: parses tab-separated and space-separated values text files.
- XML: parses XML text files.
- W3C: parses text files in the W3C Extended Log File Format.
- NCSA: The NCSA Common, Combined, and Extended Log File Formats.
- TEXTLINE: returns lines from generic text files.
- TEXTWORD: returns words from generic text files.
System Information Input Formats
- EVT: returns events from the event log files (.evt files).
- FS: returns information on files and directories.
- REG: returns information on registry values.
- ADS: returns information on Active Directory objects.
Special-purpose Input Formats
- NETMON: parses network capture files created by NetMon.
- ETW: parses Enterprise Tracing for Windows trace log files and live sessions.
- COM: provides an interface to the COM.
Already a lot. And given that you can create your own providers - generally wonderful. Later, I will touch on this issue and show how you can create them as “grown-ups” using compiled assemblies, as well as on-the-fly, simply using scripts.
The output artifact format is defined in a similar way. With the -o: CSV option, we indicated that we are interested in the provider for CSV files, and in the INTO part of our SQL query, we addressed the search file to which the result will be saved. By analogy with the input providers, we list the weekends that are available out of the box.
Generic Text File Output Formats
- NAT: formats output records as readable tabulated columns.
- CSV: formats output records as comma-separated values text.
- TSV: format output records as tab-spaced or space-space values text.
- XML: formats output records as XML documents.
- W3C: formats output records in the W3C Extended Log File Format.
- TPL: formats output records following user-defined templates.
- IIS: formats output records in the Microsoft IIS Log File Format.
Special-purpose Output Formats
- SQL: uploads output to a table in a SQL database.
- SYSLOG: sends output records to a Syslog server.
- DATAGRID: displays output records in a graphical user interface.
- CHART: creates image files containing charts.
Let's try another example for priming with completely different input and output providers. For example, the frequently encountered task of analyzing web server logs and displaying the top of referring sites.
c:\Program Files\Log Parser 2.2>LogParser.exe -i:W3C -o:CHART "SELECT TOP 10 DISTINCT EXTRACT_TOKEN(EXTRACT_TOKEN(cs(Referer), 1, '://'), 0, '/') AS Domain, COUNT(*) AS Hits INTO Hits.gif FROM X:\ex0909.log WHERE cs(Referer) IS NOT NULL AND Domain NOT LIKE '%disele%' GROUP BY Domain ORDER BY Hits DESC" -chartType:Column3D -chartTitle:"Top 10 referrers" -groupSize:800x600
Statistics:
-----------
Elements processed: 1410477
Elements output: 10
Execution time: 16.92 secondsAs you can see, LogParser thrashed nearly half a million records in less than 17 seconds with non-trivial conditions on the old Pentium D 2.8, which, in my opinion, is not such a bad result. Well, the main result is in the picture:
It seems to me that this is a terrific tool for database managers :), because it allows us to apply SQL magic where we often wanted, but it was impossible. Behind this thesis, for the time being I will suspend my narration. First of all, it’s possible to talk about LogParser for a long time and it will not fit in the framework of one post. Secondly, I would like to hope that this material is enough to at least slightly interest my colleagues in the workshop and understand how much they share my enthusiasm for this utility. And as soon as they are interested in continuing, I will immediately do it, because there are a lot of unsolved topics left. This is the conversion mode. And the formation of the output directly, as well as using LogParser-templates and XSLT. Incremental mode for working with large amounts of data. Creating your own input formats using the example of C # and JavaScript. Use LogParser from applications. Multvvod and multiple output in multiple files. Familiar with the abundance of subtleties SQL LogParser'a, including the vastness of its functions. Various options and command line options. Subtleties of various providers and their configuration. And of course, more examples of all sorts and different :)
Source: https://habr.com/ru/post/85758/
All Articles