Jahia Enterprise Portal - Architecture Overview (Part 2)
You are reading the second part of the Jahia corporate portal architecture overview.
Part 1:
Part 2:
')

The Jahia file storage was completely rewritten in version 6. In Jahia 5, the storage was based
on the use of the library Apache Slide library , which at that time was de facto
standard open source file repositories.
But it makes it possible for the rapid development and good quality of Apache Jackrabbit - implementation
Java Content Repository specification, Jahia 6 began to use it as a standard
file storage and build your services on top of this library. Actually architecture
Jackrabbit does not imply a close dependence on its use, but uses standard JCR
API for accessing various repositories.
In Jahia 6, it became possible to have access to CIFS / SMB file storage . Some others
developing implementations are available in sandbox repositories (sandbox repositories), among them
FTP connectors, Alfresco, Exo Platform, Nuxeo .
In the image above, you can note that the content of Jahia (Jahia Content) is available as
JCR provider , this is also a new feature of Jahia 6. So far, in this direction has been held
only initial compatibility work and the interface to this implementation cannot
boast high performance, but work to improve it will be carried out constantly from
version to version.
On top of the file storage service, the interfaces submit content using various technologies:
WebDAV, viewing files in templates and in Jahia’s AJAX user interface. Together with the repository
Additional portal services can function: Rules engine - to set rules and
file permissions, Thumbnail management - to generate thumbnails of images
(thumbnail), Content extractors - for extracting metadata.
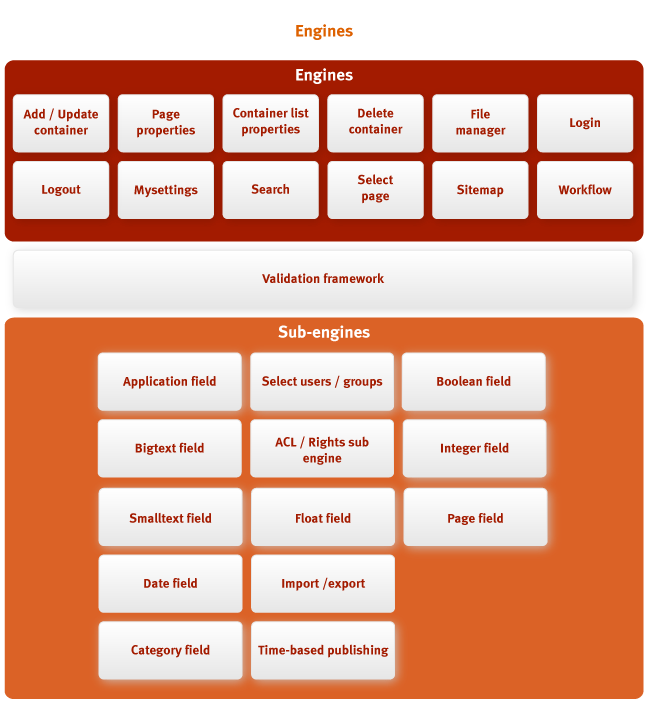
Tools and tools in Jahia are called engines . Jahia engines can
compare with Action objects in Struts. These are blocks of application logic, each of which
performs a specific task. Sub-engines are even smaller blocks,
controlling interaction with user interface primitives (for example, controlling
edit field).
The most important engine is the Core engine , which is responsible for generating
page content, it is called every time the portal should display the page. Titles
other engines speak for themselves: for example, the Login and Logout engines are responsible for
drawing the user interface for logging in and out of the system and processing the data entered
user with these actions.
Content editing engines are integrated with the validation framework.
(validation framework), which allows integrators to set validation rules entered
user data.
The engines are also integrated with a custom AJAX interface. The purpose of AJAX is to make
modern user interface, built on components that can be repeatedly
reuse. Integrators will be able to use the already existing numerous libraries.
components when building applications. Work in this direction started in Jahia 6 using
GWT components.
Sub engines in Jahia are used to display container editing interfaces.
A container can contain different types of fields. When editing a field of any type
Container editing engine (container edition engine) refers to the subdvizhku responsible for
this type of field. For example, a file type field representing a file will provide a UI
an interface that allows the user to browse directories and select files, while the field
Small text type will simply display a text box.
Jahia processes requests to the engines using the “/ engineName” parameter in the URL. If the parameter
without value - the request is accepted by the kernel engine . String values that are used for
engine naming conventions are declared by the engines themselves, and in the JahiaEngine class, the getName method
() will determine the key for the mechanism for resolving the / engineName parameter.

The search and indexing subsystem Jahia in this document will be presented only briefly - this
very extensive subsystem. Above in the figure we illustrated the main components of this
subsystems.
The innovation of Jahia 6 is the integration of the OpenSearch standard. Jahia can play a role like
consumer , as well as the generator OpenSearch requests. This means that users
can, for example, integrate Jahia into your browser’s search bar and directly do
search queries from the browser panel. On the other hand, Jahia can use the services
different OpenSearch providers and provide aggregated search results on one page.
by Jahia, Google, MSN, etc.
As for more traditional web search solutions, Jahia offers tag libraries for
search content either in a simple full-text search format, or using advanced
search queries. To facilitate the formation of advanced search queries in Jahia UI components
built-in convenient query parameters selectors . These components are made using
AJAX framework and are similar to those used to enter data in the interface
login
Another alternative for querying content objects is to directly embed queries at the level
templates , and users on the screen will see the result of the already prepared request. it
called Container Queries and they can be used, for example,
to load the last five content objects from the “News” type when displaying the latest
five news.
At the heart of all these technologies of forming user requests are server systems,
directly performing content search and indexing. The search engine portal gives
the ability to perform full-text search, search with refinement queries as the content
Jahia, and file content.
The basis of the subsystem search and indexing - opensource frameworks Compass and Apache
Lucene . They store their index using file system tools, but also have tools
to store information in databases or distributed file systems.
The standard implementation of the subsystem using the file system is currently the most
efficient and production-ready, so Jahia comes with
this implementation.
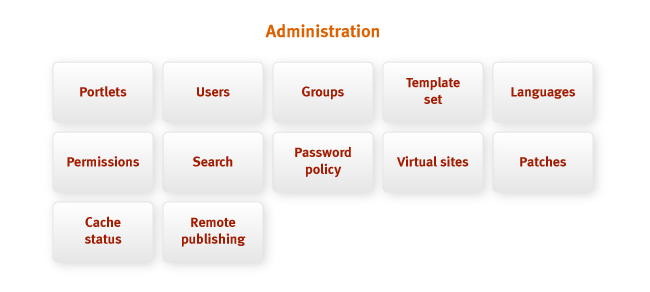
The administration interface is a management tool for all the different subsystems of Jahia.
from one place for both site administrators and server administrators. Interface
administration allows the administrator to perform all kinds of tasks:
The administration interface is based on a servlet manager and a collection of classes ,
controlling UI for various server settings. Also for the convenience of administrators interface
supports user interface components on AJAX.
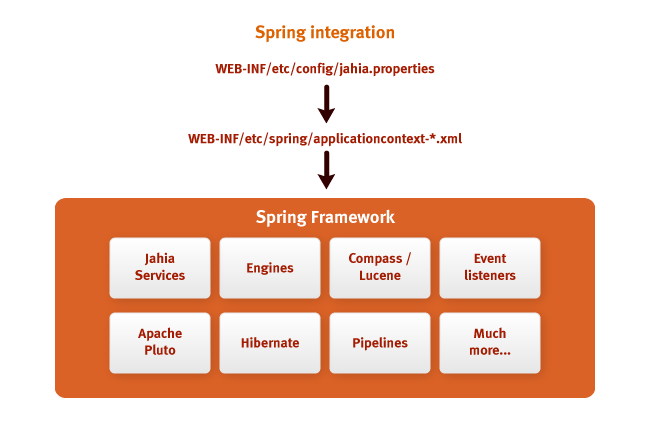
Jahia developers love Spring. Since the fifth version of the system, Jahia has been integrated with
Spring Framework to facilitate the construction of complete, fast and flexible portal solutions.
To connect Jahia subsystems to numerous services, integrators now simply follow
use well-known mechanisms for tuning and dependency injection (dependency injection),
which provides Spring.
The figure above explains the settings that can be used to initialize everything using Spring.
various subsystems Jahia. External libraries of the portal: Apache Pluto, Hibernate, Apache Lucene -
also work with Spring, which makes it possible to implement a harmonious portal architecture.
The experience of integrating Jahia with Spring was a success, and almost no dependencies on Spring’s system
appeared, which makes it possible in the future, if necessary, to freely migrate to another
framework
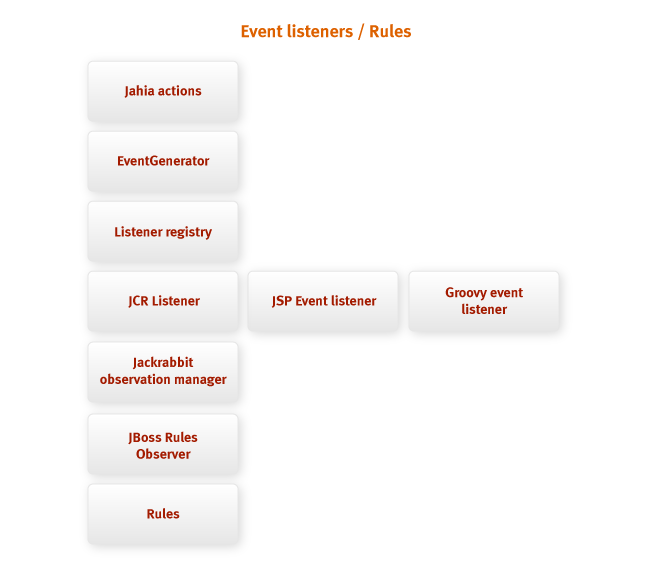
Actions performed by portal users generate events that can
used to perform certain tasks. Jahia allows integrators to register their
event listeners. The graph above shows how events are transmitted along various
subsystems and how they can be used by developers.
An event is fired when a certain action is performed by the portal. This could be a command.
user , scheduled action , background process . Action causes
event generator (event generator) to create an event object. This object will be further
transferred to the listeners registry , which is registered listeners
will call the required classes. Some of the event listeners are gateways to
other listeners using other technologies. It is possible to use the event listener
Groovy (Groovy event listener) , allowing the integrator to use Groovy's language
listener implementations; A JSP event listener that does the same for
JSP pages.
Another specific listener is the JCR observation manager ,
which links the Jahia event mechanism with the standard JCR observation model.
Under this implementation is the JBoss Rules observer (JBoss rules observer) ,
allowing integrators to use rules for event handling.

Above is a diagram of Jahia’s processing a request from a browser. Scheme can be used
developers to determine the portal subsystems involved in the processing of a specific
request.
The browser request can be sent either to the Jahia servlet or to the WebDAV servlet
(if a binary file is requested).
In the second case ( WebDAV servlet ), the request will be redirected to the file storage service,
will be validated for the right to access the requested resource and then the result will be returned
back to the browser.
In the first case, Jahia servlet will be called. Jahia will immediately create a context object.
(context object) called "ParamBean" . This will contain all
information about the request, including such things as the requested page, current user, language
view and so on. Internally, ParamBean uses a pipelined mechanism (pipeline
mechanism) for user permission. Mechanism customizable to integrate others
technology user permissions, the details of this mechanism are described in the section "Conveyors".
After creating the ParamBean object, Jahia transfers control to the OperationManager object,
which also uses a pipeline. The action pipeline is described later in this document in
relevant section. Conveyor operations will interact with Jahia services for
performing the desired actions, and the result will depend on which engines were called in
conveyor.
In the case of using the kernel engine, the action pipeline will create all the necessary content objects,
giving the template developer the content that he will post on JSP pages. therefore
after forming the content objects, the portal directs the user request to the JSP template for
page rendering.
Finally, the final result is sent back to the browser.
Naturally, this is a very simplified example of the operation of the portal, but it can serve as a basis for understanding
query processing schemes in Jahia. Portal interaction with caches has been omitted to simplify
description of the process, but it is obvious that integrators will have to take them into account when developing
their portal solutions.
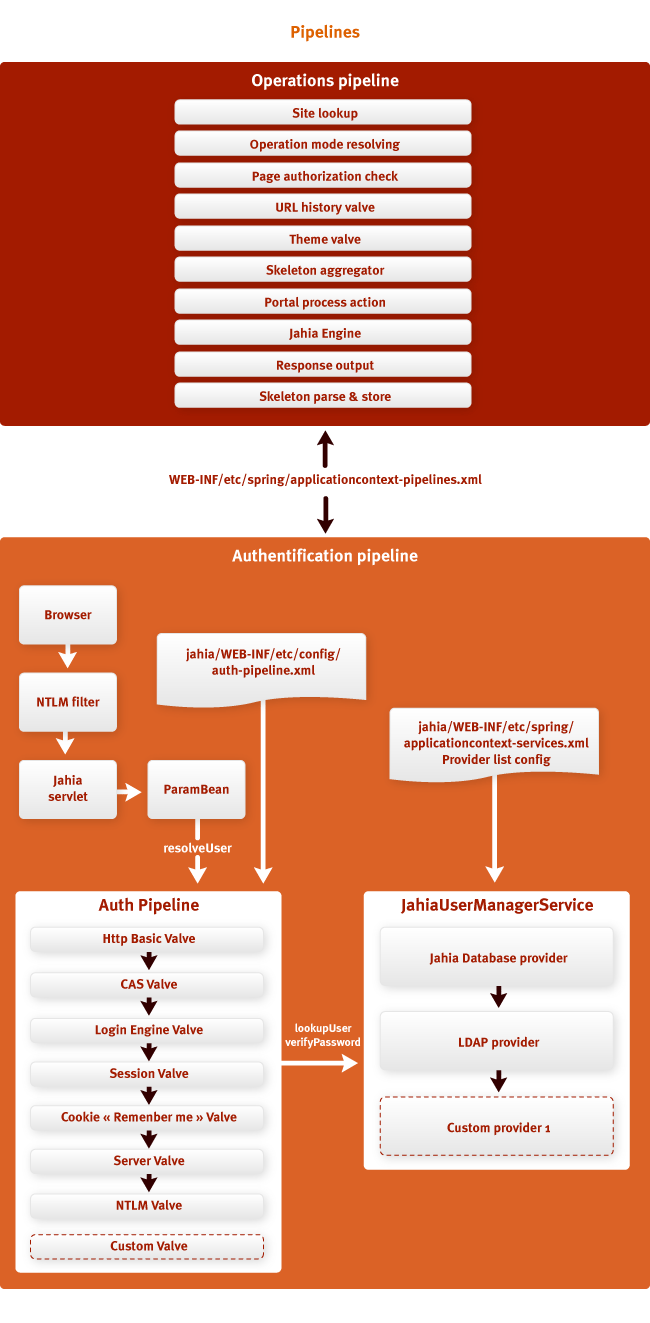
As mentioned in the previous section, Jahia uses pipelines to provide
custom processing chains. A conveyor is an ordered list of levels (valves,
valves), which in turn are called one after another. What is template specific
Pipeline design pattern is something that everyone’s responsibility
level is to cause the following. In other words, the level can choose to pass execution
next or not.
The authentication pipeline is invoked by the ParamBean object to determine the user
based on current context. Users can be defined using all
methods: this is a search for information in the saved sessions, if they have been previously defined; or with
using integrated single sign-on such as CAS, or using container authentication
JEE. In the figure above, the lower pipeline is the authentication pipeline, it shows various levels for
user definitions. We will not go into the details of each level, but it is worth noting that
This resolution mechanism is customizable using Spring xml files, which is
integrators apply their own levels.
The action pipeline (top of picture) is used in Jahia to provide
connected request processing chains. Pipeline levels may decide to stop
processing the request at any point, which is especially important when working with the cache. If the content can
read from the cache, the request processing is suspended in this place, and this frees the server from
performing unnecessary operations, making the request processing process very efficient. Level
the pipeline that is responsible for reading from the cache in the figure is called "Frame Assembler" (Skeleton
aggregator) . The URL history pipeline level is used to record all URLs,
requested by the user in order to build the navigation chain (breadcrumbs).
Integrators may find it interesting to customize the action pipeline for expansion.
functionality involved in processing user requests. It should be noted that
the order of placement of levels in the pipeline is very important, and that it is not recommended to change this order without
deep understanding of the principles of the portal Jahia.

The Jahia portal import and export subsystem is a powerful mechanism for migrating content to various
ways between Jahia websites or even between different system installations.
To export content, the system uses the Jml-170 (or JCR) data storage format, along with
other specific files (such as file hierarchies for exporting binary data). All these
files are compressed into a zip-archive, which can be used in the import subsystem.
Standardized import and export mechanism makes it possible to export a complete installation.
Jahia, a set of sites, a single sat or even one section of the site; move content between sites and
sections of Jahia sites; export and import it into non-jahia system.
Jahia also uses import and export technology to enable remote publishing.
content . In this case, the import (export) of the content is usually called by the scheduler.
tasks. The import and export technology can recognize when the content has been changed, and in such
case simply updates the content object instead of creating a new one.
Although not obvious, the copy / paste function also uses an import and export system. The
fact clarifies why content can only be copied and pasted between compatible
content descriptions , since Jahia needs to know how to convert content between source
and a content receiver.
Linked copies also use the import and export system when
sending content to the receiver (receiver).
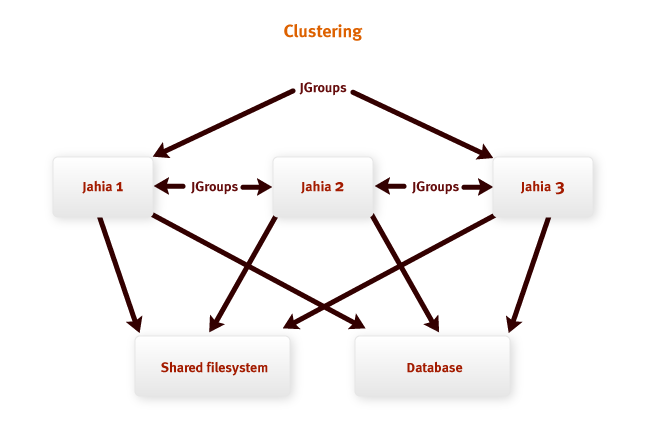
Deploying the Jahia system to a cluster is an effective way to reduce the load on the central
the processor and memory for ensuring work of the high-loaded sites.
A typical Jahia installation on a cluster is shown in the figure above. Jahia nodes exchange directly
each other (direct messaging) and have access to shared resources: the file system and database
data.
The file system is used to store the search index and to store the binary
data (if the server is configured to store binary data in the file system, the configuration by
default - storage in the database ).
Everything else is stored in the database. Therefore, it is very important to have a high-performance installation.
database to ensure good scalability of the entire system.
Jahia can also distinguish nodes by type in a cluster to provide more specialized
processing. Consider briefly the various types of nodes.
View nodes (Jahia "browsing" nodes) are specialized Jahia nodes that are
function as content publishing nodes. They also interact with portlets for
page rendering. Using this type of node allows you to separate the load on the issuance system
content from the load on the authorization system and the background query processing system.
Authorization nodes (Jahia "authoring" nodes) are cluster nodes that are also used when
viewing and editing portal content. This is the most commonly used type.
node in the Jahia cluster, so you need to have several instances of such nodes so that
to distribute the load.
In Jahia, long-running tasks (these are document validation actions (workflow validation)
operations), copy / paste operations, content importing and indexing) are performed as background
processes . Thus, when performing these lengthy operations, other nodes can still
handle requests to view and edit content.
Indexing content and files can be a very expensive operation.
CPU and load on the server RAM. For example, to index
pdf file the server must run the scripts that are contained in the file in order to extract
text content. This requires the execution of a Postscript-like language, including
memory management and processing instructions, just to extract content. Indexing
large files also require memory that cannot be freed until completion
open file.
Indexing is usually referred to as an operation that does not require performing in real
time, so it runs in the background. In order to reduce the load on the Jahia server,
processing current user requests, it is highly recommended to install
separate content index server.
You can even install multiple index server nodes on the system to ensure
uninterrupted performance of this operation.
Table of contents
Part 1:
- The overall picture.
- Components of the user interface.
- Authentication and authorization.
- Design Templates.
- Caching
- Content objects.
- Portal.
- Mashup server.
Part 2:
- File storage
- Tools and tools (engines).
- Search and indexing subsystem.
- Administration.
- Integration with Spring.
- Event listeners and rules.
- Request Processing in Jahia.
- Conveyors
- Import and export.
- Clustering
')
File storage
The Jahia file storage was completely rewritten in version 6. In Jahia 5, the storage was based
on the use of the library Apache Slide library , which at that time was de facto
standard open source file repositories.
But it makes it possible for the rapid development and good quality of Apache Jackrabbit - implementation
Java Content Repository specification, Jahia 6 began to use it as a standard
file storage and build your services on top of this library. Actually architecture
Jackrabbit does not imply a close dependence on its use, but uses standard JCR
API for accessing various repositories.
In Jahia 6, it became possible to have access to CIFS / SMB file storage . Some others
developing implementations are available in sandbox repositories (sandbox repositories), among them
FTP connectors, Alfresco, Exo Platform, Nuxeo .
In the image above, you can note that the content of Jahia (Jahia Content) is available as
JCR provider , this is also a new feature of Jahia 6. So far, in this direction has been held
only initial compatibility work and the interface to this implementation cannot
boast high performance, but work to improve it will be carried out constantly from
version to version.
On top of the file storage service, the interfaces submit content using various technologies:
WebDAV, viewing files in templates and in Jahia’s AJAX user interface. Together with the repository
Additional portal services can function: Rules engine - to set rules and
file permissions, Thumbnail management - to generate thumbnails of images
(thumbnail), Content extractors - for extracting metadata.
Tools and tools (engines)
Tools and tools in Jahia are called engines . Jahia engines can
compare with Action objects in Struts. These are blocks of application logic, each of which
performs a specific task. Sub-engines are even smaller blocks,
controlling interaction with user interface primitives (for example, controlling
edit field).
The most important engine is the Core engine , which is responsible for generating
page content, it is called every time the portal should display the page. Titles
other engines speak for themselves: for example, the Login and Logout engines are responsible for
drawing the user interface for logging in and out of the system and processing the data entered
user with these actions.
Content editing engines are integrated with the validation framework.
(validation framework), which allows integrators to set validation rules entered
user data.
The engines are also integrated with a custom AJAX interface. The purpose of AJAX is to make
modern user interface, built on components that can be repeatedly
reuse. Integrators will be able to use the already existing numerous libraries.
components when building applications. Work in this direction started in Jahia 6 using
GWT components.
Sub engines in Jahia are used to display container editing interfaces.
A container can contain different types of fields. When editing a field of any type
Container editing engine (container edition engine) refers to the subdvizhku responsible for
this type of field. For example, a file type field representing a file will provide a UI
an interface that allows the user to browse directories and select files, while the field
Small text type will simply display a text box.
Jahia processes requests to the engines using the “/ engineName” parameter in the URL. If the parameter
without value - the request is accepted by the kernel engine . String values that are used for
engine naming conventions are declared by the engines themselves, and in the JahiaEngine class, the getName method
() will determine the key for the mechanism for resolving the / engineName parameter.
Search and indexing subsystem
The search and indexing subsystem Jahia in this document will be presented only briefly - this
very extensive subsystem. Above in the figure we illustrated the main components of this
subsystems.
The innovation of Jahia 6 is the integration of the OpenSearch standard. Jahia can play a role like
consumer , as well as the generator OpenSearch requests. This means that users
can, for example, integrate Jahia into your browser’s search bar and directly do
search queries from the browser panel. On the other hand, Jahia can use the services
different OpenSearch providers and provide aggregated search results on one page.
by Jahia, Google, MSN, etc.
As for more traditional web search solutions, Jahia offers tag libraries for
search content either in a simple full-text search format, or using advanced
search queries. To facilitate the formation of advanced search queries in Jahia UI components
built-in convenient query parameters selectors . These components are made using
AJAX framework and are similar to those used to enter data in the interface
login
Another alternative for querying content objects is to directly embed queries at the level
templates , and users on the screen will see the result of the already prepared request. it
called Container Queries and they can be used, for example,
to load the last five content objects from the “News” type when displaying the latest
five news.
At the heart of all these technologies of forming user requests are server systems,
directly performing content search and indexing. The search engine portal gives
the ability to perform full-text search, search with refinement queries as the content
Jahia, and file content.
The basis of the subsystem search and indexing - opensource frameworks Compass and Apache
Lucene . They store their index using file system tools, but also have tools
to store information in databases or distributed file systems.
The standard implementation of the subsystem using the file system is currently the most
efficient and production-ready, so Jahia comes with
this implementation.
Administration
The administration interface is a management tool for all the different subsystems of Jahia.
from one place for both site administrators and server administrators. Interface
administration allows the administrator to perform all kinds of tasks:
- create, update, delete users, groups, sites and categories;
- set global permissions;
- set permissions on templates and portlets, split templates and portlets on
categories; - view the internal cache status and reset it;
- set a password assignment policy;
- determine the site languages;
- configure the ability to remotely publish content;
- perform other functions described in detail in the Administrator’s Guide
(Administrator's guide).
The administration interface is based on a servlet manager and a collection of classes ,
controlling UI for various server settings. Also for the convenience of administrators interface
supports user interface components on AJAX.
Spring integration
Jahia developers love Spring. Since the fifth version of the system, Jahia has been integrated with
Spring Framework to facilitate the construction of complete, fast and flexible portal solutions.
To connect Jahia subsystems to numerous services, integrators now simply follow
use well-known mechanisms for tuning and dependency injection (dependency injection),
which provides Spring.
The figure above explains the settings that can be used to initialize everything using Spring.
various subsystems Jahia. External libraries of the portal: Apache Pluto, Hibernate, Apache Lucene -
also work with Spring, which makes it possible to implement a harmonious portal architecture.
The experience of integrating Jahia with Spring was a success, and almost no dependencies on Spring’s system
appeared, which makes it possible in the future, if necessary, to freely migrate to another
framework
Event listeners and rules
Actions performed by portal users generate events that can
used to perform certain tasks. Jahia allows integrators to register their
event listeners. The graph above shows how events are transmitted along various
subsystems and how they can be used by developers.
An event is fired when a certain action is performed by the portal. This could be a command.
user , scheduled action , background process . Action causes
event generator (event generator) to create an event object. This object will be further
transferred to the listeners registry , which is registered listeners
will call the required classes. Some of the event listeners are gateways to
other listeners using other technologies. It is possible to use the event listener
Groovy (Groovy event listener) , allowing the integrator to use Groovy's language
listener implementations; A JSP event listener that does the same for
JSP pages.
Another specific listener is the JCR observation manager ,
which links the Jahia event mechanism with the standard JCR observation model.
Under this implementation is the JBoss Rules observer (JBoss rules observer) ,
allowing integrators to use rules for event handling.
Request Processing in Jahia
Above is a diagram of Jahia’s processing a request from a browser. Scheme can be used
developers to determine the portal subsystems involved in the processing of a specific
request.
The browser request can be sent either to the Jahia servlet or to the WebDAV servlet
(if a binary file is requested).
In the second case ( WebDAV servlet ), the request will be redirected to the file storage service,
will be validated for the right to access the requested resource and then the result will be returned
back to the browser.
In the first case, Jahia servlet will be called. Jahia will immediately create a context object.
(context object) called "ParamBean" . This will contain all
information about the request, including such things as the requested page, current user, language
view and so on. Internally, ParamBean uses a pipelined mechanism (pipeline
mechanism) for user permission. Mechanism customizable to integrate others
technology user permissions, the details of this mechanism are described in the section "Conveyors".
After creating the ParamBean object, Jahia transfers control to the OperationManager object,
which also uses a pipeline. The action pipeline is described later in this document in
relevant section. Conveyor operations will interact with Jahia services for
performing the desired actions, and the result will depend on which engines were called in
conveyor.
In the case of using the kernel engine, the action pipeline will create all the necessary content objects,
giving the template developer the content that he will post on JSP pages. therefore
after forming the content objects, the portal directs the user request to the JSP template for
page rendering.
Finally, the final result is sent back to the browser.
Naturally, this is a very simplified example of the operation of the portal, but it can serve as a basis for understanding
query processing schemes in Jahia. Portal interaction with caches has been omitted to simplify
description of the process, but it is obvious that integrators will have to take them into account when developing
their portal solutions.
Conveyors
As mentioned in the previous section, Jahia uses pipelines to provide
custom processing chains. A conveyor is an ordered list of levels (valves,
valves), which in turn are called one after another. What is template specific
Pipeline design pattern is something that everyone’s responsibility
level is to cause the following. In other words, the level can choose to pass execution
next or not.
The authentication pipeline is invoked by the ParamBean object to determine the user
based on current context. Users can be defined using all
methods: this is a search for information in the saved sessions, if they have been previously defined; or with
using integrated single sign-on such as CAS, or using container authentication
JEE. In the figure above, the lower pipeline is the authentication pipeline, it shows various levels for
user definitions. We will not go into the details of each level, but it is worth noting that
This resolution mechanism is customizable using Spring xml files, which is
integrators apply their own levels.
The action pipeline (top of picture) is used in Jahia to provide
connected request processing chains. Pipeline levels may decide to stop
processing the request at any point, which is especially important when working with the cache. If the content can
read from the cache, the request processing is suspended in this place, and this frees the server from
performing unnecessary operations, making the request processing process very efficient. Level
the pipeline that is responsible for reading from the cache in the figure is called "Frame Assembler" (Skeleton
aggregator) . The URL history pipeline level is used to record all URLs,
requested by the user in order to build the navigation chain (breadcrumbs).
Integrators may find it interesting to customize the action pipeline for expansion.
functionality involved in processing user requests. It should be noted that
the order of placement of levels in the pipeline is very important, and that it is not recommended to change this order without
deep understanding of the principles of the portal Jahia.
Import and export
The Jahia portal import and export subsystem is a powerful mechanism for migrating content to various
ways between Jahia websites or even between different system installations.
To export content, the system uses the Jml-170 (or JCR) data storage format, along with
other specific files (such as file hierarchies for exporting binary data). All these
files are compressed into a zip-archive, which can be used in the import subsystem.
Standardized import and export mechanism makes it possible to export a complete installation.
Jahia, a set of sites, a single sat or even one section of the site; move content between sites and
sections of Jahia sites; export and import it into non-jahia system.
Jahia also uses import and export technology to enable remote publishing.
content . In this case, the import (export) of the content is usually called by the scheduler.
tasks. The import and export technology can recognize when the content has been changed, and in such
case simply updates the content object instead of creating a new one.
RELATION TO COPY / PASTE
Although not obvious, the copy / paste function also uses an import and export system. The
fact clarifies why content can only be copied and pasted between compatible
content descriptions , since Jahia needs to know how to convert content between source
and a content receiver.
Linked copies also use the import and export system when
sending content to the receiver (receiver).
Clustering
Deploying the Jahia system to a cluster is an effective way to reduce the load on the central
the processor and memory for ensuring work of the high-loaded sites.
A typical Jahia installation on a cluster is shown in the figure above. Jahia nodes exchange directly
each other (direct messaging) and have access to shared resources: the file system and database
data.
The file system is used to store the search index and to store the binary
data (if the server is configured to store binary data in the file system, the configuration by
default - storage in the database ).
Everything else is stored in the database. Therefore, it is very important to have a high-performance installation.
database to ensure good scalability of the entire system.
Jahia can also distinguish nodes by type in a cluster to provide more specialized
processing. Consider briefly the various types of nodes.
NODES VIEWING
View nodes (Jahia "browsing" nodes) are specialized Jahia nodes that are
function as content publishing nodes. They also interact with portlets for
page rendering. Using this type of node allows you to separate the load on the issuance system
content from the load on the authorization system and the background query processing system.
AUTHORIZATION NODES
Authorization nodes (Jahia "authoring" nodes) are cluster nodes that are also used when
viewing and editing portal content. This is the most commonly used type.
node in the Jahia cluster, so you need to have several instances of such nodes so that
to distribute the load.
HANDLING NODES
In Jahia, long-running tasks (these are document validation actions (workflow validation)
operations), copy / paste operations, content importing and indexing) are performed as background
processes . Thus, when performing these lengthy operations, other nodes can still
handle requests to view and edit content.
INDEXING SERVER
Indexing content and files can be a very expensive operation.
CPU and load on the server RAM. For example, to index
pdf file the server must run the scripts that are contained in the file in order to extract
text content. This requires the execution of a Postscript-like language, including
memory management and processing instructions, just to extract content. Indexing
large files also require memory that cannot be freed until completion
open file.
Indexing is usually referred to as an operation that does not require performing in real
time, so it runs in the background. In order to reduce the load on the Jahia server,
processing current user requests, it is highly recommended to install
separate content index server.
You can even install multiple index server nodes on the system to ensure
uninterrupted performance of this operation.
Source: https://habr.com/ru/post/81884/
All Articles