"Regular expressions" or "Just about ugly"
"Regular expressions" or "Just about ugly"
I will begin by explaining what prompted me to write this article. I was inspired by an article on regular expressions that was published a little earlier; those who read Habra have probably already seen it, honestly did not like the article, because they wrote it, but they gave a complicated example of how to use and offer to buy a book in 600+ pages that it seems to me only scare away people who could use them.
I will not specifically look into any manuals, and I’ll remember to stuff you with information, I am sure that in order to become interested and start using, I will be enough that I can and use myself.
I will give all the examples using “grep” which is for both Windows and linux (for him, of course, it is more familiar).
I myself sit under linux, so I will show examples using linux itself, in some cases I will use "|" ("Pipe"), the output redirection command, but if you want, you can do without it using a temporary result file. Regular expression syntax I will use the standard therefore, it should work everywhere where regular expressions are fully supported.
')
I appeal to those who do not know anything about grep. You shouldn’t be confused, because I’m using an unfamiliar tool, it’s used only as an example, regular expressions have a standardized syntax that is supported by many text editors.
For the seed. Have you ever had to write short parsers if you need to select some words or phrases from a file when an ordinary search does not work anymore? ..
1. Suppose we have some text file containing some logins as follows:
.....
login="Figaro"
.....
login="Tolik"
........
and you just need to get a list of logins, what should the user do in this case? if the file weighs like this ... tsat MB or even GB? or did you have to deal with such tasks? .. We will learn how to do this with you.
2. Next, the task is this, let's say we have the source code of some project on “C ++” and we need to see which classes have this project (we can do without template ones for convenience) and structures,
Considering that classes and structures can be declared something like this (without apostrophes, of course):
'class Foo'
'class Bar'
' class Any'
' struct A'
and this we also learn to do.
3. And yet, there is some format file,
user="Login" Passwd="anypassword"
in every line and we need
from this file find
3.1 users whose password consists only of numbers
3.2 users whose password consists only of small letters,
3.3 only capital letters
3.4 whose password is shorter than 5 characters and consists only of small or large letters.
3.5 whose login is similar to the ip address, these are very strange users like bots :))
(e.g. 243.11.22.03 or 243-11-22-03 or 243_11_22_03)
Who is already familiar with regular expressions, can solve these puzzles to warm up and compare the result with the one we get below.
I think that's enough for now.
Well, now the grammar of regular expressions, alas, can’t do without it, but let's get started with a small list, I’m writing a description myself, so they can be very different from canonical ones:
Symbols :
. - point This is an arbitrary character. If you do not know that there is a letter or a number or a symbol, write a dot
\ w - This is some letter of the word, unfortunately there are very few people who support Russian letters with this symbol, for example, KDevelop 3.5.10 supports
\ d - This is some digit
\ s - This is a space or tab, ie space
\ l - lower case letters not supported by my version of grep
\ u - capital letters upper are not supported by my version of grep
[abcde] - Any of the listed characters in the set may appear
^ - mark the beginning of the line
$ - line ending designation
() - brackets are used to group expressions
Repetitions :
Used as "(expression) (repetition)" without brackets, it will be clearer below.
* - the expression can be repeated any number of times starting from 0, i.e. it can be absent
+ - the expression can be repeated once or more, that is, it must be present
{3.6} is a universal way to set up repetitions in this case from 3 to 6 repetitions.
{3,} from three or more repetitions
? - the expression can be repeated 0 or 1 times can be written as {0,1}
some characters that should be escaped in regular expressions only if you do not have their regular essence
\ ?,
\ +,
\ |,
\ (
\)
\.
\ [
\]
\ -
\ ~
In fact, the regular expression syntax is more, but this is basic, nevertheless, for general development, you can familiarize yourself with the other possibilities in order to write more concise and less understandable expressions :))
a little about grep, this is a console utility that takes parameters from the command line, there are also GUI-shnye versions of this tool, keys:
-P says that the expression is regular,
-o display only the found regular expression and not the entire line.
-r recursively descend into subdirectories
* process all files (if not include)
--include "* .h" use only files with the .h extension
Let's move from words to deeds.
Task 1,
So let's begin to solve our problems, we recall the condition of the first:logins.txt :
.....
login="Figaro"
.....
login="Tolik"
........
The text of the logins.txt file on which I checked:
.....
login="Figaro"
.....
login="Tolik" login="Petya"
file:
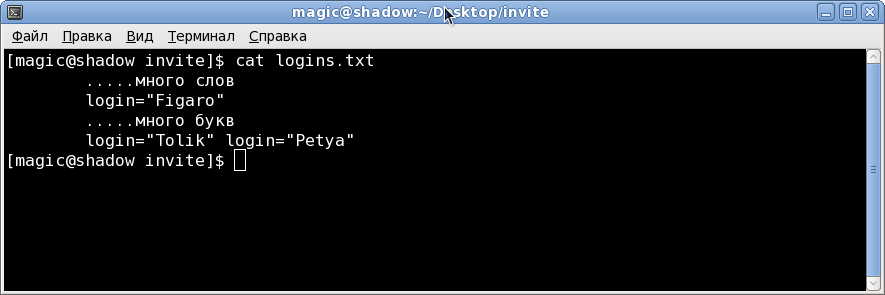
We have an example of the expression we are looking for:
name="Figaro"let's select its changing part, this is directly the word written in quotes, look at the syntax, the characters used are "\ w", the number of repetitions is "+", then to find all pairs we get an expression of the form:
name="\w+"Ie, having a file logins.txt command that will receive the list name = "login" will be like this:
grep -Po 'login="\w+"' logins.txtbut the condition states that you need to get a list of logins, not pairs, look at an expression like name = "login" in order to select only login from it, obviously you need to pick up the expression in quotes, the regular expression will look like a part of the one that we have already been:
"\w+"then to get the list of logins from the result, we get the following construction
grep -Po 'login="\w+"' logins.txt | grep -Po '"\w+"'(or instead of '|' use intermediate file and apply the second command to this file)
The result of the output command:
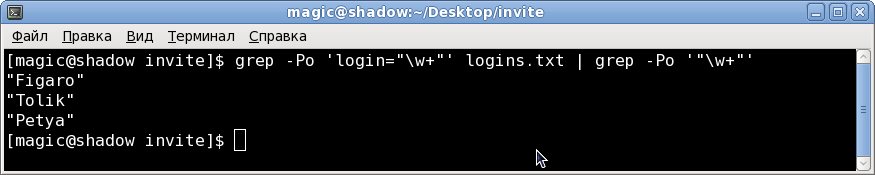
Finished with the first task figured out, we get a list of logins, if you wish, you can remove quotes, but that is your own.
Task number 2
I recall the condition:"" ( ) , - ( ) :
'class Foo'
'class Bar'
' class Any'
' struct A'
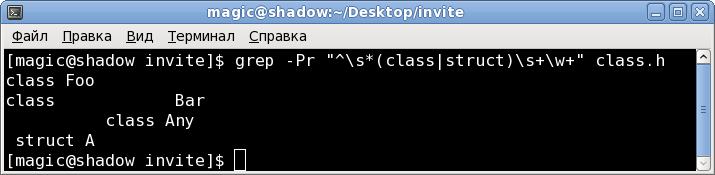
- The text of the class.h file on which I checked:
class Foo
class Bar
class Any
struct A
- file contents:

So what we have, we will lay down the fact that the headings of the classes are at the beginning of the line, otherwise for me this is monstrous. Take the example of the ad string:
' class Any'and try to turn this expression into a template that fits all other declarations summarize:
the beginning of the line => '^',
then there is a space or tab => '\ s', it may or may not be => '*',
there is a word class => class, or => '|' word struct => struct
there is a space => '\ s', at least one => '+',
Name => '\ w', must contain at least one letter => '+'
The build logic looks more complicated than the expression itself, which is obtained as a result:
^\s*(class|struct)\s+\w+and so the team that will find ads:
grep -Pr "^\s*(class|struct)\s+\w+" class.houtputting the result:
or asterisk to apply to all files:
grep -Pr "^\s*(class|struct)\s+\w+" *Done, with the second task figured out.
Task number 3
condition:3) , , user="Login" Passwd="anypassword" ,
3.1 ,
3.2 ,
3.3 ,
3.4 5 .
3.5 ip , :))
( 243.11.22.03 243-11-22-03 243_11_22_03 )
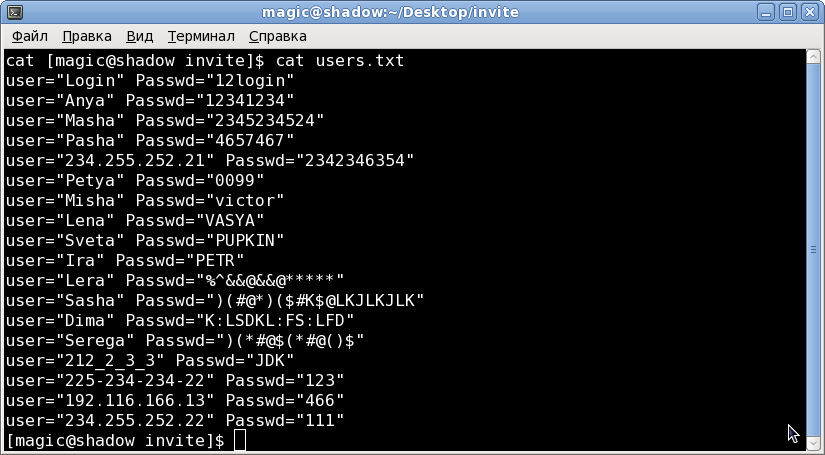
- The text of the users.txt file on which I checked:
user="Login" Passwd="12login"
user="Anya" Passwd="12341234"
user="Masha" Passwd="2345234524"
user="Pasha" Passwd="4657467"
user="234.255.252.21" Passwd="2342346354"
user="Petya" Passwd="0099"
user="Misha" Passwd="victor"
user="Lena" Passwd="VASYA"
user="Sveta" Passwd="PUPKIN"
user="Ira" Passwd="PETR"
user="Lera" Passwd="%^&&@&&@*****"
user="Sasha" Passwd=")(#@*)($#K$@LKJLKJLK"
user="Dima" Passwd="K:LSDKL:FS:LFD"
user="Serega" Passwd=")(*#@$(*#@()$"
user="212_2_3_3" Passwd="JDK"
user="225-234-234-22" Passwd="123"
user="192.116.166.13" Passwd="466"
user="234.255.252.22" Passwd="111"
- file:
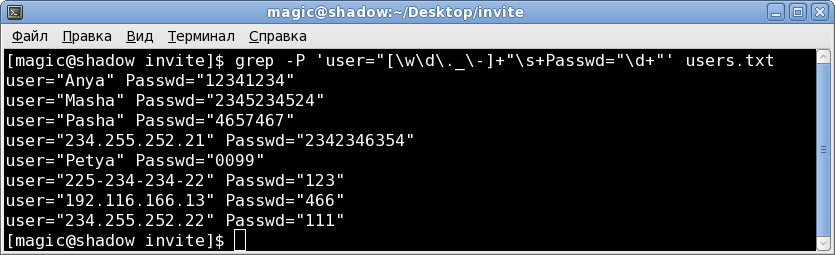
3.1 In order to find passwords with numbers only, it suffices to fulfill the condition, where in quotes
the password values are only numbers, it is very simple, I think you will understand everything without a schedule:
user="[\w\d\._\-]+"\s+Passwd="\d+"grep -P 'user="[\w\d\._\-]+"\s+Passwd="\d+"' users.txt[\ w \ d \ ._ \ -] are valid characters in the letter letters, numbers, period, underscore, dash.
result:
3.2 We look at the rules of grammar for the designation of small letters, here is a similar condition, only instead of numbers here are small letters, and we get the result:
user="[\w\d\._\-]+"\s+Passwd="[az]+"grep -P 'user="[\w\d\._\-]+"\s+Passwd="[az]+"' users.txtresult:

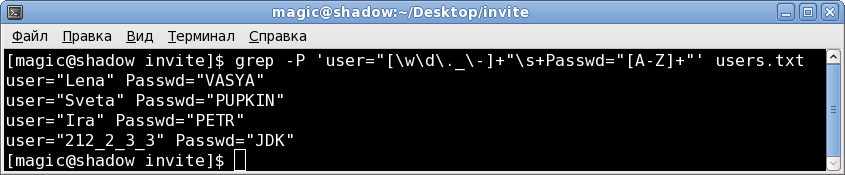
3.3 Here is similar:
user="[\w\d\._\-]+"\s+Passwd="[AZ]+"grep -P 'user="[\w\d\._\-]+"\s+Passwd="[AZ]+"' users.txtresult:
3.4 Here you can think a little, and remember a similar case was when we were looking for a class or a struct, only length restrictions are added:
I propose to stop a bit and write it yourself :)). I seriously, once again read paragraph 3.4 and the solution to problem 2, and write the expression yourself. Come back after you try. =))
It is not much more complicated here:
user="[\w\d\._\-]+"\s+Passwd="([az]|[AZ]){1,4}"grep -P 'user="[\w\d\._\-]+"\s+Passwd="([az]|[AZ]){1,4}"' users.txtresult:

3.5 Here I will write the expression itself, but I suggest you do the analysis yourself, that is, you can understand yourself, although of course you could write it yourself.
I will do it, those who feel strong can suggest writing the solution of paragraph 3.5 on their own, and then checking it with test data, but those who do not want to write it themselves, it remains to master the expression below, I understand it looks terrible only if I sign it to you, rather nothing will be delayed:
and here is the expression itself:
user="(\d{1,3}[\._\-]){3}\d{1,3}"\s+Passwd=".*"grep -P 'user="(\d{1,3}[\._\-]){3}\d{1,3}"\s+Passwd=".*"' users.txtI will give a hint:
a block is allocated - (\ d {1,3} [\ ._ \ -]) this is for example: '251.' which is repeated
3 times after which we get something like '251.243.243.' followed by another number \ d {1,3}.
result:

In the end, I would like to note that the names of sets can be specified explicitly, so instead of \ d you can write [1234567890] or [0-9] to explicitly indicate Russian letters, you can also specify [aaaa-yayo], though such a construction may not always be understood correctly. only small English letters [az], only large [AZ] small large and numbers [a-zA-Z0-9], etc.
Thank you for your attention, I want to advise - to spend a little time to figure it out, it really makes life (especially a programmer) easier.
Source: https://habr.com/ru/post/80742/
All Articles