Notes on NLP (Part 5)
Well, let's continue. (The first parts: 1 2 3 4 ). For a long time I chose what would be better for the next topic - to philosophize about the pragmatics of the language or to talk specifically about the parsing algorithms. Considering that the previous part was informal, I decided to switch to the specifics after all, but we'll see.
So parse the sentence. Let us immediately determine that the discussion will deal with the analysis within the framework of the concept of dependency parsing, and the exact analysis (not statistical) will be the defining methodology of the analysis. Let's start with a small overview of what is happening around.
For example, I have on my desk a book called Dependency parsing . By name and annotation you might think that we are waiting for a detailed review of existing methods, but this, unfortunately, is not quite so. The authors relatively quickly "move out" to their topic, and half of the book is devoted to their approach, while many other methods are not even mentioned.
')
Do not think that I am criticizing them - the fact that this book is sufficiently characteristic of our time. I would characterize the current state of the industry as “disorder and vacillation”. Maybe I am mistaken, I would like to believe in the best :) There are a lot of reasons for that. Every natural language is “special” in its own way. You can take some Somali and adapt famous methods for it all your life, there is always a place for novelty. Solid laboratories with their established instruments have been formed - the same group at Stanford, who wrote Stanford parser. They are unlikely to change their ideas in the near future. In addition, the quality of the approaches is difficult to assess. An entire decent volume thesis of my colleague is devoted to methods for evaluating and comparing syntax analysis algorithms! And he is not such a talker like me, he writes concisely. (By the way, I recommend the thesis - it contains a good overview of modern parsing methods. Yes, there is a lot of text, but only because there are many methods - in other sources the volume will be no less) .
If you read books, especially old ones (even if the year of publication is not misleading, this is a reprint of the text of the early eighties), it seems that everything has been done a long time ago. However, apparently, much desired is given for real, or not as polished as we would like. For example, the search for a morphological analyzer for the Finnish language convinces that everything was done as early as 1984 in the well-known Kimmo Koskenniemi specialist in this field. However, the site of the Omorfi project, a Finnish morphological analyzer that is now being written (and still far from completion) at the University of Helsinki [named after Linus Torvalds] under the guidance of the same Koskenniemi, is also quickly located! It kind of hints.
Understanding the formalisms that are available today is not easy. But to understand which of them is worth something is impossible at all. I think this is a matter of faith.
Here they are, the theory of syntactic analysis:

Each approach has its own school, its own parsers, projects ... And it is still difficult to know where the leader is. My favorite is XDG, but everything is not good there either, and I still can not hear the general enthusiasm for this development in scientific circles. He tried to read and about many other approaches. There are many clever things in different theories, and they often intersect.
So forgive me, there will be no full review here. Read the mentioned thesis of Dr. Kakkonen. I took the picture from there.
The meaning of this term is quite simple: in the records of the syntactic rules of a language, one way or another, real words from a dictionary of a language appear. In non-Lexicalized models, more general concepts are used. For example, in the lexicalized rule it can be said: the word “table” should appear here. In the non-Lexicalized rule, only a “masculine noun” can be written, as well as some clarifying attributes.
In principle, as I understand it, the line is quite thin. On the one hand, an object can be so “clamped on” by conditions that, apart from the word “table”, nothing would fit its definition. On the other hand, in the lexicalized rules not only concrete objects, but also abstract concepts can be found: “subject”, “adverb”.
In practice, non-vocalized rules (“grammar”) are associated with something small and probably statistically derived. Lexicalized grammars are thick dictionaries that, in terms of level of detail, go as far as the description of individual words.
I have already mentioned that the parsing graph can be not only a tree (that is, it can be a general graph), but this is a specific situation, and it does not arise with pure parsing. So, maybe, we will return to this scenario later, but for now we will assume that the parsing turns out a tree.
So, if someone wants to show me a new parser (dependency-parser), the first thing I ask him is whether the algorithm supports building non-design trees and knows how to build the whole variety of parsing options.
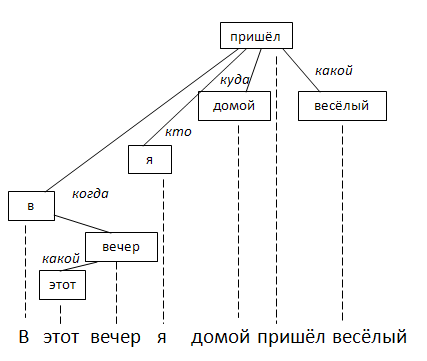
Projective trees are those whose branches do not intersect with the projections on the words of the original sentence. This happens if you always merge only neighboring elements into a common node. In principle, in most cases this is exactly what happens:
But it happens that it is necessary to interconnect words, “jumping over” through the third word:

(I confess, the verb “sausages” of the “wants to help feed” type are processed differently in different theories. The figure shows only one of the options.)
As far as I understand, with phrase-structure-parsing, such situations are not handled at all. Because the Chomsky grammars, by definition, describe only the elements immediately adjacent to each other. When the advocates of dependency parsing began to say that this approach allows you to work with a freer word order (than in English), Khomskans answered: and you first write a parser who knows how to build non-projective trees - without them, the benefits of potential freedom are small.
How relevant is the problem? In one article they write that when analyzing real texts in the Czech language, “non-design” was revealed in 23% of cases. Often. The problem with non-projective trees is that if it is allowed to try to glue any word to any other, we immediately go beyond all the norms provided for by politeness in terms of calculations. In fact, in the worst case, it turns out a complete enumeration of all possible graphs with N vertices-words, that is, a problem of exponential complexity.
The theorists joined in and proved that at the cost of small limitations of the parser’s capabilities, its computational complexity can be reduced to “acceptable” (I have not studied the details, I can’t give exact calculations). At the same time, for the same Czech collection of documents, it’s too tough for this limited analyzer to have only 0.5% of the offers.
By the way, the first mentions of non-projective analysis of proposals are quite fresh - approximately 1997 . This is a question about how much you can trust the literature in our field. Especially these wonderful books from the eighties, in which "everything is already decided."
Now about the multiplicity of parsing. In principle, this is the same problem, but on the other hand. If you try to build all the permissible parse trees, we fall into the same "exponential pit." It is clear that the options of analysis will be two or three, well, four. However, in the process of trying to glue anything with anything, obvious overhead costs arise :)
It is clear that many words are ambiguous, but their interpretation does not affect the type of tree, that is, the syntax analysis: "I keep money in the bank." Here the analysis is unequivocal: I keep money (where?) - in the bank. It does not matter if I have a glass jar or a stone jar building.
There are "intermediate" options. "Down the street was a girl with a scythe." You can always disassemble like this: a girl (with what?) - with a scythe. And you can choose: a girl (what?) - with a scythe (if it's a haircut); girl (with what?) - with a scythe (if we are talking about a metal spit).
There are also obvious cases of completely different trees. My favorite example: "he saw it in front of his eyes."
The first option is clear: he saw (who?) Her (where?) Before his eyes.
But there is a “marginal” interpretation: he saw (what?) Her in front of (ie, the front part) (than / how?) - with his own eyes.
I will not lie, but except for XDG / XDK, I don’t think of projects that can build all the many acceptable trees.
Perhaps today we finish. I want to sleep :)
So parse the sentence. Let us immediately determine that the discussion will deal with the analysis within the framework of the concept of dependency parsing, and the exact analysis (not statistical) will be the defining methodology of the analysis. Let's start with a small overview of what is happening around.
For example, I have on my desk a book called Dependency parsing . By name and annotation you might think that we are waiting for a detailed review of existing methods, but this, unfortunately, is not quite so. The authors relatively quickly "move out" to their topic, and half of the book is devoted to their approach, while many other methods are not even mentioned.
')
Do not think that I am criticizing them - the fact that this book is sufficiently characteristic of our time. I would characterize the current state of the industry as “disorder and vacillation”. Maybe I am mistaken, I would like to believe in the best :) There are a lot of reasons for that. Every natural language is “special” in its own way. You can take some Somali and adapt famous methods for it all your life, there is always a place for novelty. Solid laboratories with their established instruments have been formed - the same group at Stanford, who wrote Stanford parser. They are unlikely to change their ideas in the near future. In addition, the quality of the approaches is difficult to assess. An entire decent volume thesis of my colleague is devoted to methods for evaluating and comparing syntax analysis algorithms! And he is not such a talker like me, he writes concisely. (By the way, I recommend the thesis - it contains a good overview of modern parsing methods. Yes, there is a lot of text, but only because there are many methods - in other sources the volume will be no less) .
If you read books, especially old ones (even if the year of publication is not misleading, this is a reprint of the text of the early eighties), it seems that everything has been done a long time ago. However, apparently, much desired is given for real, or not as polished as we would like. For example, the search for a morphological analyzer for the Finnish language convinces that everything was done as early as 1984 in the well-known Kimmo Koskenniemi specialist in this field. However, the site of the Omorfi project, a Finnish morphological analyzer that is now being written (and still far from completion) at the University of Helsinki [named after Linus Torvalds] under the guidance of the same Koskenniemi, is also quickly located! It kind of hints.
Understanding the formalisms that are available today is not easy. But to understand which of them is worth something is impossible at all. I think this is a matter of faith.
Here they are, the theory of syntactic analysis:
Each approach has its own school, its own parsers, projects ... And it is still difficult to know where the leader is. My favorite is XDG, but everything is not good there either, and I still can not hear the general enthusiasm for this development in scientific circles. He tried to read and about many other approaches. There are many clever things in different theories, and they often intersect.
So forgive me, there will be no full review here. Read the mentioned thesis of Dr. Kakkonen. I took the picture from there.
Lexicalization
Older formalisms are not in a hurry to retire. As can be seen from the figure, many quite ancient methods are being successfully developed to this day. But one trend is clearly clear: the transition to lexicalized models. In the figure they are marked in gray.The meaning of this term is quite simple: in the records of the syntactic rules of a language, one way or another, real words from a dictionary of a language appear. In non-Lexicalized models, more general concepts are used. For example, in the lexicalized rule it can be said: the word “table” should appear here. In the non-Lexicalized rule, only a “masculine noun” can be written, as well as some clarifying attributes.
In principle, as I understand it, the line is quite thin. On the one hand, an object can be so “clamped on” by conditions that, apart from the word “table”, nothing would fit its definition. On the other hand, in the lexicalized rules not only concrete objects, but also abstract concepts can be found: “subject”, “adverb”.
In practice, non-vocalized rules (“grammar”) are associated with something small and probably statistically derived. Lexicalized grammars are thick dictionaries that, in terms of level of detail, go as far as the description of individual words.
Problems of projectivity and multiplicity of parse trees
As you can see, at least he promised to analyze, but we still can’t get to the analysis. We will assume that we iteratively approach it :)I have already mentioned that the parsing graph can be not only a tree (that is, it can be a general graph), but this is a specific situation, and it does not arise with pure parsing. So, maybe, we will return to this scenario later, but for now we will assume that the parsing turns out a tree.
So, if someone wants to show me a new parser (dependency-parser), the first thing I ask him is whether the algorithm supports building non-design trees and knows how to build the whole variety of parsing options.
Projective trees are those whose branches do not intersect with the projections on the words of the original sentence. This happens if you always merge only neighboring elements into a common node. In principle, in most cases this is exactly what happens:
But it happens that it is necessary to interconnect words, “jumping over” through the third word:
(I confess, the verb “sausages” of the “wants to help feed” type are processed differently in different theories. The figure shows only one of the options.)
As far as I understand, with phrase-structure-parsing, such situations are not handled at all. Because the Chomsky grammars, by definition, describe only the elements immediately adjacent to each other. When the advocates of dependency parsing began to say that this approach allows you to work with a freer word order (than in English), Khomskans answered: and you first write a parser who knows how to build non-projective trees - without them, the benefits of potential freedom are small.
How relevant is the problem? In one article they write that when analyzing real texts in the Czech language, “non-design” was revealed in 23% of cases. Often. The problem with non-projective trees is that if it is allowed to try to glue any word to any other, we immediately go beyond all the norms provided for by politeness in terms of calculations. In fact, in the worst case, it turns out a complete enumeration of all possible graphs with N vertices-words, that is, a problem of exponential complexity.
The theorists joined in and proved that at the cost of small limitations of the parser’s capabilities, its computational complexity can be reduced to “acceptable” (I have not studied the details, I can’t give exact calculations). At the same time, for the same Czech collection of documents, it’s too tough for this limited analyzer to have only 0.5% of the offers.
By the way, the first mentions of non-projective analysis of proposals are quite fresh - approximately 1997 . This is a question about how much you can trust the literature in our field. Especially these wonderful books from the eighties, in which "everything is already decided."
Now about the multiplicity of parsing. In principle, this is the same problem, but on the other hand. If you try to build all the permissible parse trees, we fall into the same "exponential pit." It is clear that the options of analysis will be two or three, well, four. However, in the process of trying to glue anything with anything, obvious overhead costs arise :)
It is clear that many words are ambiguous, but their interpretation does not affect the type of tree, that is, the syntax analysis: "I keep money in the bank." Here the analysis is unequivocal: I keep money (where?) - in the bank. It does not matter if I have a glass jar or a stone jar building.
There are "intermediate" options. "Down the street was a girl with a scythe." You can always disassemble like this: a girl (with what?) - with a scythe. And you can choose: a girl (what?) - with a scythe (if it's a haircut); girl (with what?) - with a scythe (if we are talking about a metal spit).
There are also obvious cases of completely different trees. My favorite example: "he saw it in front of his eyes."
The first option is clear: he saw (who?) Her (where?) Before his eyes.
But there is a “marginal” interpretation: he saw (what?) Her in front of (ie, the front part) (than / how?) - with his own eyes.
I will not lie, but except for XDG / XDK, I don’t think of projects that can build all the many acceptable trees.
Perhaps today we finish. I want to sleep :)
Source: https://habr.com/ru/post/79882/
All Articles