Notes on NLP (Part 3)
(Beginning: 1 , 2 ) Well, we approach the most interesting - analysis of sentences. This topic is multifaceted and multi-layered, so it's not very easy to approach it. But the difficulties only harden :) Yes, and the weekend, the text is written easily ...
Let's start with such a thing as parsing sentences (in English parsing ). The essence of this process is to build a graph, “in some way” reflecting the structure of the sentence.
I say “in any way” because today there is no single accepted system of principles on which the mentioned graph is built. Even within the framework of one concept, the views of individual scientists on the relationship between words may differ (this is reminiscent of the differences in the interpretation of morphological phenomena, as discussed in the previous part).
Probably, first of all, it is necessary to divide the methods of constructing a graph (usually a tree) of dependencies into phrase structure-based parsing and dependency parsing.
')
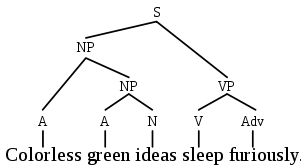
Representatives of the first school divide the sentence into "components", then each component is divided into its components - and so on until we reach the words. This idea is well illustrated by a drawing from Wikipedia:
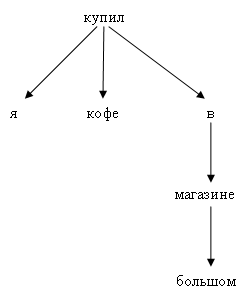
Representatives of the second school connect dependent words to each other directly, without any auxiliary nodes:
At once I will say that my sympathies are on the side of the second approach (dependency parsing), but both of them deserve more detailed discussion.
Starting with the character S, you can generate any string of the form a ... ab ... b. There is also a universal algorithm for parsing such a grammar. After feeding him an input string and a set of grammar rules, you can get the answer - is the string the correct string within the given language or not. You can also get a parse tree showing how the string is output from the initial character S.
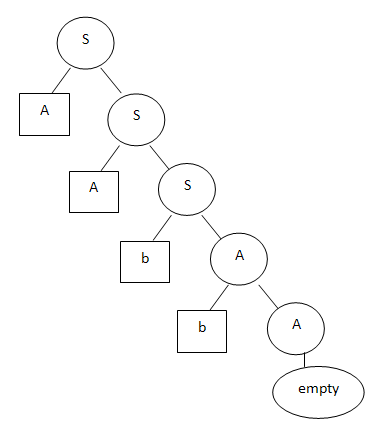
Suppose the aabb line matches this tree:
The obvious advantage of this method is that Chomsky's grammar is a formalism known for a long time. There are long-established parsing algorithms, known "formal properties" of grammars, i.e. their expressive ability, complexity of processing, etc. In addition, Chomsky grammars are successfully applied when compiling programming languages.
Chomsky himself is primarily a linguist, and he tried on his work in a natural language, English, first of all. Therefore, in English computational linguistics, the influence of his works is quite large. Although “Chomsky’s formalism,” as far as I know, is not used in the processing of texts in natural language (they are not developed enough for this), the spirit of his school lives on.
A good example of a parser that builds such trees is Stanford parser (there is an online demo).
In general, this approach is also difficult to call particularly fresh. All refer to the work of Lucien Tesniere of the fifties as a source. Earlier thoughts are also mentioned (but from the same opera, what to call PLO PLO’s father, since he introduced the concept of the “world of ideas”, that is, abstract classes). However, in computational linguistics, dependency parsing has long been in the background, while Chomsky's grammars were actively used. Probably, the limitations of Chomsky’s approach particularly painfully hit languages with a looser (than in English) word order, so the most interesting work in the field of dependency parsing is still performed “outside” of the English-speaking world.
The main idea of dependency parsing is to connect dependent words to each other. The center of almost any phrase is the verb (explicit or implied). Further from the verb (action) you can ask questions: who does what he does, where he does and so on. For attached entities, you can also ask questions (first of all, the question “what”). For example, for the above tree “I bought coffee in a big store,” you can reproduce such a chain of questions. Root - bought (phrase action). Who bought? - I. What did you buy? - Coffee. Where did you buy it? - In the shop. In which shop? - In big.
Here, too, there are many technical subtleties and ambiguities. You can handle the absence of the verb in different ways. Usually, the verb “to be” is still implied: “I [am] a student.” In predicative sentences, the situation is more complicated: On the street is damp. You can’t say it’s raw in the street :) It’s not always clear what depends on what and how to interpret it. For example, "I will not go to work today." How does the particle “not” compare with other words? Alternatively, we can assume that the verb of “non-actions” is “not coming” (even if there is no such thing in Russian, but it is appropriate in meaning). It is not entirely clear how to sculpt homogeneous members connected by union. "I bought a coffee and a bun." For example, you can sculpt to “bought” the word “and”, and to “and” attach already “coffee” and “bun”. But there are other approaches. A rather subtle moment arises in the interaction of words that form a certain unity: "I will go to work." It is clear that “I will walk” is essentially a single verb (that is, an action) of the future tense, it is simply created in two words.
If you want to look at this analyzer in action - I can advise the site of the company Connexor .
What dependency parsing is attractive? Give different arguments. For example, it is said that by connecting words together, we do not create additional entities, and, therefore, we simplify further analysis. In the end, parsing is just another stage of word processing, and then you have to imagine what to do with the resulting tree. In a sense, the dependency tree is “cleaner” because it shows clear semantic links between the elements of a sentence. Further, it is often claimed that dependency parsing is more suitable for languages with free word order. In Chomsky, all the dependent blocks somehow really end up next to each other. Here, in theory, it is possible to have connections between words at different ends of a sentence (although this is not technically so simple, but more on that later). In principle, these arguments are enough for me to join Tenier’s camp :)
It must be said that there are formal proofs of the proximity of the resulting trees. Somewhere, the theorem that a tree of one species can be converted into a tree of another type and vice versa was slipping. But in practice it does not work. At least in my memory, no one tried to get a dependency tree by transforming the output of Stanford parser. Apparently, not everything is so simple, and the mistakes are multiplying ... first, the Stanford parser makes a mistake, then the conversion algorithm makes a mistake ... and what happens at the end? Error on error.
(UPD: The above-mentioned guys from Stanford still tested the method of converting the output of their parser into a dependency structure. However, I must note that with this conversion, only projective trees are obtained, which are discussed in the fifth part ).
Probably enough for today. We continue in the next section.
Let's start with such a thing as parsing sentences (in English parsing ). The essence of this process is to build a graph, “in some way” reflecting the structure of the sentence.
I say “in any way” because today there is no single accepted system of principles on which the mentioned graph is built. Even within the framework of one concept, the views of individual scientists on the relationship between words may differ (this is reminiscent of the differences in the interpretation of morphological phenomena, as discussed in the previous part).
Probably, first of all, it is necessary to divide the methods of constructing a graph (usually a tree) of dependencies into phrase structure-based parsing and dependency parsing.
')
Representatives of the first school divide the sentence into "components", then each component is divided into its components - and so on until we reach the words. This idea is well illustrated by a drawing from Wikipedia:
Representatives of the second school connect dependent words to each other directly, without any auxiliary nodes:
At once I will say that my sympathies are on the side of the second approach (dependency parsing), but both of them deserve more detailed discussion.
Chomsky School
The parsing "by constituents" clearly grew out of Chomsky's grammar. If anyone does not know, Chomsky's grammar is a way to specify rules that describe sentences in a language. With the help of such a grammar you can both generate phrases and analyze them. For example, the following grammar describes a “language” consisting of an arbitrary number of letters a, followed by an arbitrary number of letters b:S -> aS | bA | 'empty'
A -> bA | 'empty'
Starting with the character S, you can generate any string of the form a ... ab ... b. There is also a universal algorithm for parsing such a grammar. After feeding him an input string and a set of grammar rules, you can get the answer - is the string the correct string within the given language or not. You can also get a parse tree showing how the string is output from the initial character S.
Suppose the aabb line matches this tree:
The obvious advantage of this method is that Chomsky's grammar is a formalism known for a long time. There are long-established parsing algorithms, known "formal properties" of grammars, i.e. their expressive ability, complexity of processing, etc. In addition, Chomsky grammars are successfully applied when compiling programming languages.
Chomsky himself is primarily a linguist, and he tried on his work in a natural language, English, first of all. Therefore, in English computational linguistics, the influence of his works is quite large. Although “Chomsky’s formalism,” as far as I know, is not used in the processing of texts in natural language (they are not developed enough for this), the spirit of his school lives on.
A good example of a parser that builds such trees is Stanford parser (there is an online demo).
Word relationship model
In general, this approach is also difficult to call particularly fresh. All refer to the work of Lucien Tesniere of the fifties as a source. Earlier thoughts are also mentioned (but from the same opera, what to call PLO PLO’s father, since he introduced the concept of the “world of ideas”, that is, abstract classes). However, in computational linguistics, dependency parsing has long been in the background, while Chomsky's grammars were actively used. Probably, the limitations of Chomsky’s approach particularly painfully hit languages with a looser (than in English) word order, so the most interesting work in the field of dependency parsing is still performed “outside” of the English-speaking world.
The main idea of dependency parsing is to connect dependent words to each other. The center of almost any phrase is the verb (explicit or implied). Further from the verb (action) you can ask questions: who does what he does, where he does and so on. For attached entities, you can also ask questions (first of all, the question “what”). For example, for the above tree “I bought coffee in a big store,” you can reproduce such a chain of questions. Root - bought (phrase action). Who bought? - I. What did you buy? - Coffee. Where did you buy it? - In the shop. In which shop? - In big.
Here, too, there are many technical subtleties and ambiguities. You can handle the absence of the verb in different ways. Usually, the verb “to be” is still implied: “I [am] a student.” In predicative sentences, the situation is more complicated: On the street is damp. You can’t say it’s raw in the street :) It’s not always clear what depends on what and how to interpret it. For example, "I will not go to work today." How does the particle “not” compare with other words? Alternatively, we can assume that the verb of “non-actions” is “not coming” (even if there is no such thing in Russian, but it is appropriate in meaning). It is not entirely clear how to sculpt homogeneous members connected by union. "I bought a coffee and a bun." For example, you can sculpt to “bought” the word “and”, and to “and” attach already “coffee” and “bun”. But there are other approaches. A rather subtle moment arises in the interaction of words that form a certain unity: "I will go to work." It is clear that “I will walk” is essentially a single verb (that is, an action) of the future tense, it is simply created in two words.
If you want to look at this analyzer in action - I can advise the site of the company Connexor .
What dependency parsing is attractive? Give different arguments. For example, it is said that by connecting words together, we do not create additional entities, and, therefore, we simplify further analysis. In the end, parsing is just another stage of word processing, and then you have to imagine what to do with the resulting tree. In a sense, the dependency tree is “cleaner” because it shows clear semantic links between the elements of a sentence. Further, it is often claimed that dependency parsing is more suitable for languages with free word order. In Chomsky, all the dependent blocks somehow really end up next to each other. Here, in theory, it is possible to have connections between words at different ends of a sentence (although this is not technically so simple, but more on that later). In principle, these arguments are enough for me to join Tenier’s camp :)
It must be said that there are formal proofs of the proximity of the resulting trees. Somewhere, the theorem that a tree of one species can be converted into a tree of another type and vice versa was slipping. But in practice it does not work. At least in my memory, no one tried to get a dependency tree by transforming the output of Stanford parser. Apparently, not everything is so simple, and the mistakes are multiplying ... first, the Stanford parser makes a mistake, then the conversion algorithm makes a mistake ... and what happens at the end? Error on error.
(UPD: The above-mentioned guys from Stanford still tested the method of converting the output of their parser into a dependency structure. However, I must note that with this conversion, only projective trees are obtained, which are discussed in the fifth part ).
Probably enough for today. We continue in the next section.
Source: https://habr.com/ru/post/79830/
All Articles