Work with large amounts of data and habraeffekt
One of the goals of creating bullshitbingo.ru was to see how the google application engine ( GAE ) behaves in more or less realistic conditions. I was especially interested in the possibility of obtaining my own statistics, because what GAE and google analitics give me does not suit me for the reasons that I will give below. There was no special reaction to the post itself, but it came out to the main page and the site received about 15,000 downloads in a day, which was quite enough. The peak of the load was 3-4 requests per second, as a result, the limit of free resources allocated by GAE was not exceeded.
The following is a description of the features of working with statistics in GAE and in the second part of the graphics about the resulting load: your own and those generated by google. I tried to write so that it was clear to those who did not come across GAE at all.
Part One: Statistics
GAE, of course, shows its own graphics, but there are a number of questions:
')
Problem: GAE is fundamentally unable to return more than 1000 entries . This is connected with the non-relational data model, and, perhaps, it doesn’t bother anyone at all, but it hinders much when working with statistics. Another consideration: it can be very expensive to build some complex queries and calculate something directly on the GAE side, and you will have to pay for processor time and storage of large amounts of data. Since statistics is, generally speaking, “dead” data that is not necessary for operation, it can be easily retrieved from the GAE servers somewhere, and processed there. Even more convenient. Therefore, it was decided to upload statistics in the form of csv-files and work with it already somehow locally.
Data upload
Uploading data is a separate task, because it is also not able to select records with a GAE offset. It is more able to, but it is actually implemented on the client side (of the application, and not of the http-client, of course). That is, when I want to get 10 records starting from the 100th, this can be done, and for that, there is even a corresponding parameter to the fetch () call, but in fact all 110 records will be extracted from the database, just the first hundred APIs will keep . That is just to get 100 records from the 1000th in general is impossible. This is even written in the documentation, but somehow somewhat vague.
You can get out of the situation if you use not the line number as an offset, as I used to in relational databases, but date / time. Time in GAE is stored as much as six decimal places, so the probability of making several entries with exactly the same time is extremely small. Strictly speaking, it is possible to create an artificial unique field with monotonously increasing values, but I do not see such a need.
All statistics can be sorted by date and choose 1000 pieces, each time remembering what date you managed to get, and the next time you retreat from it. Once the statistics are guaranteed to be unloaded, it can be deleted. Then I call these fragments of 1000 records pages. You can choose another number, but 1000 turned out to be no worse, say 100, so I stopped at 1000.
The statistics upload script takes as a parameter the maximum date (the date, without the time) to which the data is to be output. There are two reasons for this:
1) the statistics comes in constantly, but the data “for yesterday and earlier” will not change;
2) uploading all the statistics at once may simply not be possible due to the large amount of data and restrictions on the execution time, and it will be possible to unload at least one day.
Thus, the algorithm with large strokes is the following:
When comparing with $ last_date, “non-strictly more” is used because theoretically the possibility of exact coincidence of time in two different queries still exists. So that the lines at the junction of the pages are not duplicated, you need to verify their unique keys (and GAE generates such a key for any objects stored in the database) and omit the line if it has already been unloaded.
In the case of bullshitbingo, the data for the day in which I published the post on Habré, was downloaded in about 20 seconds, that is, on the verge of a foul. If there is a little more data, then you still have to break the uploads not by days, but by hours.
Delete statistics. With this, of course, again problems. Documentation assures that it is more efficient to delete records from the database in bulk rather than one by one. When you try to just delete everything that is less than a given date, you always get a timeout. And when I checked this procedure for comparable volumes locally, it slowly, but worked. I had to rewrite the procedure for deleting one entry. For 30 seconds allotted for the script execution time, 400-600 records were deleted. I rewrote the procedure again and began to delete records of 100 pieces, it seems to be the process has accelerated, to understand what happened there was no longer the strength. Removes and all right, receptions in 10 everything turned out.
Part two: “habraeffekt?”
There have already been several articles on this topic, for example, here is an article about GAE, but on java and there the picture is simply given, and I have a fully functional project.
In general, I would not mention this effect either: at the peak the load was 4 requests per second. For no more than an hour, the load was about two requests per second, after which it fell steadily, this is all evident from the graphs.
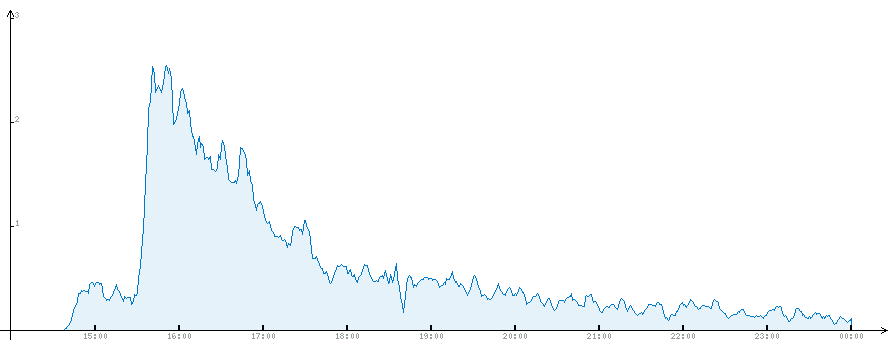
Complete statistics. Peak load in 4 queries is not visible here due to averaging.
The time is Moscow, the post was published at 14:40, apparently in about an hour he went to the main page. GAE stores time in GMT, I did the conversion already at the stage of drawing graphs, although it would be possible when loading csv files, perhaps.

Separately statistics on the main page.

Statistics on the game .

Statistics the next day: by 11 am, the majority of people read up the second page of the habranths.

Administrative interface GAE. It also shows the resources spent, screenshots taken 10 hours after the post was published. I like my drawings more.
There are still statistics for two days , you can estimate the scale.
It should be noted that I didn’t do any optimization at all. That is, with each request, all that is possible (all sorts of signatures, headers, titles and descriptions, all the words for games) was selected from the database, except that it did not arrange artificial empty cycles. This is done firstly because of laziness, secondly to see what happens. As a result, spent about 70% of the resources that GAE provides for free. The CPU turned out to be a bottleneck, from all other resources it was spent on 1-2%. In addition, several timeout errors were received when accessing the database, so most of the work with the database was later transferred to memcach.
Some more statistics
After fasting, about 150 people tried to look at the administrative interface, 90 games were created, almost 30 of them are non-empty and 15 pieces are quite to themselves with meaningful content, their authors - hello.
A total of people went (by ip addresses): 6814
More than one page loaded: 3573 or 52%
More than two pages uploaded: 2334, 34%
More than ten: 215, 3%
findings
Working with large amounts of data in GAE is not very convenient, but it is quite possible. For real work, you will have to write scripts that will unload statistics on a schedule, automate it to check for correctness, and then initialize the cleanup of the unloaded GAE. That is, this all leads to quite noticeable overhead costs and creates quite definite, but surmountable difficulties.
The following is a description of the features of working with statistics in GAE and in the second part of the graphics about the resulting load: your own and those generated by google. I tried to write so that it was clear to those who did not come across GAE at all.
Part One: Statistics
GAE, of course, shows its own graphics, but there are a number of questions:
- watch them after some time becomes impossible, the graphics are available only for the last day;
- data presentation is fixed and not configurable;
- There is no possibility to build a schedule for some of its conditions, in the case of bullshitbingo, it would be interesting for me to see separate games separately.
')
Problem: GAE is fundamentally unable to return more than 1000 entries . This is connected with the non-relational data model, and, perhaps, it doesn’t bother anyone at all, but it hinders much when working with statistics. Another consideration: it can be very expensive to build some complex queries and calculate something directly on the GAE side, and you will have to pay for processor time and storage of large amounts of data. Since statistics is, generally speaking, “dead” data that is not necessary for operation, it can be easily retrieved from the GAE servers somewhere, and processed there. Even more convenient. Therefore, it was decided to upload statistics in the form of csv-files and work with it already somehow locally.
Data upload
Uploading data is a separate task, because it is also not able to select records with a GAE offset. It is more able to, but it is actually implemented on the client side (of the application, and not of the http-client, of course). That is, when I want to get 10 records starting from the 100th, this can be done, and for that, there is even a corresponding parameter to the fetch () call, but in fact all 110 records will be extracted from the database, just the first hundred APIs will keep . That is just to get 100 records from the 1000th in general is impossible. This is even written in the documentation, but somehow somewhat vague.
You can get out of the situation if you use not the line number as an offset, as I used to in relational databases, but date / time. Time in GAE is stored as much as six decimal places, so the probability of making several entries with exactly the same time is extremely small. Strictly speaking, it is possible to create an artificial unique field with monotonously increasing values, but I do not see such a need.
All statistics can be sorted by date and choose 1000 pieces, each time remembering what date you managed to get, and the next time you retreat from it. Once the statistics are guaranteed to be unloaded, it can be deleted. Then I call these fragments of 1000 records pages. You can choose another number, but 1000 turned out to be no worse, say 100, so I stopped at 1000.
The statistics upload script takes as a parameter the maximum date (the date, without the time) to which the data is to be output. There are two reasons for this:
1) the statistics comes in constantly, but the data “for yesterday and earlier” will not change;
2) uploading all the statistics at once may simply not be possible due to the large amount of data and restrictions on the execution time, and it will be possible to unload at least one day.
Thus, the algorithm with large strokes is the following:
- select the 1000 oldest records with a query like this: SELECT * FROM request where date <date $ 1000 by date limit 1000;
- create a csv-record for each line;
- remember $ last_date - maximum received date;
- execute the query, adding to the condition with the $ last_date: SELECT * FROM request where the date <$ date and date > = $ last_date order by date limit 1000;
- while the query result is non-empty goto 2.
When comparing with $ last_date, “non-strictly more” is used because theoretically the possibility of exact coincidence of time in two different queries still exists. So that the lines at the junction of the pages are not duplicated, you need to verify their unique keys (and GAE generates such a key for any objects stored in the database) and omit the line if it has already been unloaded.
In the case of bullshitbingo, the data for the day in which I published the post on Habré, was downloaded in about 20 seconds, that is, on the verge of a foul. If there is a little more data, then you still have to break the uploads not by days, but by hours.
Delete statistics. With this, of course, again problems. Documentation assures that it is more efficient to delete records from the database in bulk rather than one by one. When you try to just delete everything that is less than a given date, you always get a timeout. And when I checked this procedure for comparable volumes locally, it slowly, but worked. I had to rewrite the procedure for deleting one entry. For 30 seconds allotted for the script execution time, 400-600 records were deleted. I rewrote the procedure again and began to delete records of 100 pieces, it seems to be the process has accelerated, to understand what happened there was no longer the strength. Removes and all right, receptions in 10 everything turned out.
Part two: “habraeffekt?”
There have already been several articles on this topic, for example, here is an article about GAE, but on java and there the picture is simply given, and I have a fully functional project.
In general, I would not mention this effect either: at the peak the load was 4 requests per second. For no more than an hour, the load was about two requests per second, after which it fell steadily, this is all evident from the graphs.
Complete statistics. Peak load in 4 queries is not visible here due to averaging.
The time is Moscow, the post was published at 14:40, apparently in about an hour he went to the main page. GAE stores time in GMT, I did the conversion already at the stage of drawing graphs, although it would be possible when loading csv files, perhaps.
Separately statistics on the main page.
Statistics on the game .
Statistics the next day: by 11 am, the majority of people read up the second page of the habranths.
Administrative interface GAE. It also shows the resources spent, screenshots taken 10 hours after the post was published. I like my drawings more.
There are still statistics for two days , you can estimate the scale.
It should be noted that I didn’t do any optimization at all. That is, with each request, all that is possible (all sorts of signatures, headers, titles and descriptions, all the words for games) was selected from the database, except that it did not arrange artificial empty cycles. This is done firstly because of laziness, secondly to see what happens. As a result, spent about 70% of the resources that GAE provides for free. The CPU turned out to be a bottleneck, from all other resources it was spent on 1-2%. In addition, several timeout errors were received when accessing the database, so most of the work with the database was later transferred to memcach.
Some more statistics
After fasting, about 150 people tried to look at the administrative interface, 90 games were created, almost 30 of them are non-empty and 15 pieces are quite to themselves with meaningful content, their authors - hello.
A total of people went (by ip addresses): 6814
More than one page loaded: 3573 or 52%
More than two pages uploaded: 2334, 34%
More than ten: 215, 3%
findings
Working with large amounts of data in GAE is not very convenient, but it is quite possible. For real work, you will have to write scripts that will unload statistics on a schedule, automate it to check for correctness, and then initialize the cleanup of the unloaded GAE. That is, this all leads to quite noticeable overhead costs and creates quite definite, but surmountable difficulties.
Source: https://habr.com/ru/post/78445/
All Articles