Teamwork in Git
In all the many articles on git I could find on the network, one essential point is missing - a description of teamwork. What is commonly described as teamwork is actually just working with a remote repository.
Below I want to describe my experience of team working on a project using git.
My workflow is organized as follows.
I am the lead dash developer, the head of the dash project manager. I have several developers in my team.
')
My job is this:
1) talk to the customer
2) to transform the vague and confused wishes of the customer into a clearly defined task
3) put this task to the developer
4) check the result of the task by the developer
5) unsatisfactory result to return to the developer for revision
6) to submit a satisfactory result to the customer for approval or immediately send to production
7) send the result approved by the customer in production
8) the result not approved by the customer back to the developer for revision
The work of the developer, respectively, is as follows:
1) get me the task
2) execute it
3) send me the result
4) if the task is returned for revision - to finalize and send to me again
For task management, I use Trac . Also in Trac the project documentation is kept, both programmer and user.
Having formulated the task, I write it down in Trac and assign it to some developer. The developer, after completing the task, reassigns it to me. I check the result and, either reassign it to the developer again, or mark it as completed.
The algorithm for working with git and the general picture of what is happening is shown schematically in the picture:
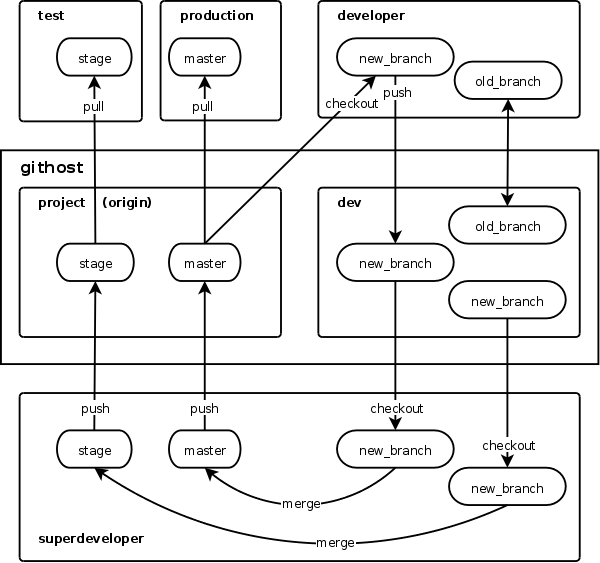
Now, from the theoretical part, let us turn to the practical one and see what all this means and how it works.
Install git. Read some manual . Understand the local repository.
Please note - this article is not about git commands, but about how to link these commands into the desired sequence. Therefore, I will continue to give git commands without detailed explanations, assuming that you know the purpose of individual commands.
When working as a team, you will need to provide access to the repository for several users. For convenient access rights to the repository, I use gitosis .
Gitosis is a set of scripts that implement convenient management of git repositories and access to them. It works like this:
- a server is started on the server to which all repositories will belong
- all calls to repositories are made via SSH, under the name of this user, user authorization is made by keys
- when logging in via SSH, gitosis scripts are automatically launched, which, depending on the setting, allow or prohibit further actions with repositories
The gitosis scripts and configs are stored in the repository themselves and configured by sending commits to this repository. It sounds crazy, but in fact nothing particularly tricky, quite simple and convenient.
To install gitosis, you need (surprise!) To pull out the gitosis installation repository from the gitosis developer server:
$ git clone git: //eagain.net/gitosis.git
Install gitosis:
$ cd gitosis
$ su
# python setup.py install
The installation repository is no longer needed, it can be deleted.
Now you need to create a user in the system to which all repositories will belong:
$ su
# adduser gituser
And then initialize gitosis in the home directory of the created user, with the public key of who will be the gitosis administrator. The public key, of course, needs to be put somewhere, from where the user gituser can read it:
# su gituser
$ cd ~
$ gitosis-init <id_rsa.pub
Note that the gituser user and the gitosis administrator are not one person. The gituser user is simply the “keeper” of the repositories and never performs any actions at all.
I use another registered user in the system as a gitosis administrator. But, generally speaking, the administrator does not have to be a user registered in the system. The main thing is to specify the public key of the administrator when initializing gitosis.
After gitosis is initialized, the repositories directory will appear in the gituser user's home directory, in which all repositories will be stored. At first, there will only be the gitosis-admin.git repository, which stores the settings of the gitosis itself.
Please note - for some reason related to the features of different versions of Python, you may need to assign permissions to execute the post-update script located in the gitosis repository:
$ chmod 755 ~ / repositories / gitosis-admin.git / hooks / post-update
This completes the gitosis installation and the setup begins.
Setting up gitosis is to change the contents of the gitosis repository by the administrator.
We become the gitosis administrator (if the administrator is a registered user in the system) or log out at all and log in where the administrator is registered (for example, on his laptop).
Now we pull out the gitosis setup repository:
$ git clone gituser @ githost: gitosis-admin.git
Where githost is the name of the server where we installed gitosis (and where we will store the repositories).
Please note that whatever the administrator’s name is, the server is always accessed under the username gituser.
After that, the gitosis-admin directory will appear in the admin home directory. In this directory we are interested in the gitosis.conf file, it is in it that all repositories are configured.
By default, it will have something like this:
[group gitosis-admin]
writable = gitosis-admin
members = admin @ host
What means "admin user is allowed to write to the gitosis-admin repository".
Creating a new repository is to add a new group to the config. The name of the group can be any, it is just for clarity. We need two repositories to work with:
[group project-write]
writable = project
members = superdeveloper
[group project-read]
readonly = project
members = developer1 developer2 developer3 user1 user2
[group dev]
writable = dev
members = superdeveloper developer1 developer2 developer3
where superdeveloper is the lead developer, developer * is the developers, user * is the other interested
This config means the following:
1) the lead developer is allowed to write to the main repository
2) everyone is allowed to read from the main repository
3) the lead developer and all developers are allowed to write to the working repository
All these users, like the gitosis administrator, do not necessarily have to be registered users in the system. The main thing is that they have public keys.
The public keys of the users specified in the config need to be copied to the gitosis-admin / keydir directory. Key files must have names like username.pub. In this example, these will be the names superdeveloper.pub, developer1.pub, user1.pub, etc.
After editing the config and copying keys, you need to commit the changes to the local repository:
$ git add.
$ git commit -am 'Add project Project'
And send the commit to the central repository, where the settings you have made will be picked up by gitosis:
$ git push
Everything, now our server of repositories is configured and necessary repositories are created (I say lies, repositories are not created yet, but will be created automatically at the first commit).
If in the previous section you had a question - why for one project you need two repositories - then here is the answer.
The first repository, the main one, is production. The combat copy of the project will work on the code from this repository. The second repository, which is also a worker, is a development. In this repository is, of course, the development of the project.
I tried different schemes of teamwork and the most convenient at the moment seems to me to be a “dual repository" scheme. Work in it is approximately as follows:
1) I set the task for the developer
2) the developer takes the current project branch from the main repository and makes a local brunch from it
3) in this brunch, the developer solves the problem
4) the developer sends a brunch with the task to the working repository
5) I take this brunch from the working repository and check it
6) if the task is completed correctly, I merge this brunch with the current project branch in the main repository
This scheme has two key differences from the widely described scheme, when all development goes in the master branch of one repository.
Firstly, in my scheme, developers cannot make unauthorized changes (both accidental and intentional) to the current branch, i.e. in production.
Secondly, the current branch I never have inoperative.
The second reason, in fact, is more important. Unauthorized changes at any time can be rolled back, and the version control system. But to fix the non-working state of the current branch can be very difficult.
Let me explain by example.
Suppose the developer P1 edited P1 and sent it to the master branch. I checked this edit and found it bad. Bad editing needs to be redone.
While I checked, the P2 developer made the P2 edit and also sent it to the master. This edit was good. Good editing needs to be sent to production.
But now there are two edits in the master branch, good and bad. A good edit would need to be sent to production, but the presence of a bad edit does not allow it. You have to wait for a bad revision to be fixed.
Or another example - all edits are good, but some are not approved by the customer. Unapproved edits do not allow to get into production approved, and approval can take a long time.
In general, you need to make changes so that you can steer separately from each other, without dumping them all in a bunch in the master branch.
To do this, the developers send to the repository all their branches separately, without merging them with the master. I do merging. Accordingly, only the edits I have checked go to the current branch. Bad edits are sent for revision, and edits awaiting customer approval are sent to the test branch and just ... wait. And no one interferes.
Thus, the current branch is always in working condition.
In principle, sending brunch separately can be done in one repository. But in one repository it is impossible to separate access to individual branches, i.e. It is not allowed to write to the repository new branches and at the same time prohibit changing the current branch. Therefore, we need a second repository - in one there is an actual branch, in the other - all new working branches that appear as individual tasks are solved.
In fact, in large projects, each developer should generally have his own separate repository. But for now, it is quite convenient for me to live with two repositories - one is mine (production), the other is common for all developers (development).
Please note - the primary download is done by the lead developer, since only he has the right to write to the main repository.
Create a local repository in the project directory and drive the project files into it:
$ cd / old / directory / project
$ git init
$ git add.
$ git commit -am 'poehali!'
We inform the local repository about where the main repository is located:
$ git remote add origin gituser @ githost: project.git
Now we send the commit to the main repository:
$ git push origin master
Everything, the project is sent to the main repository. Now the old project directory can be easily banged and started working in a new directory (or on another computer), under the control of git.
Go to the new directory (or even to another computer) and pull out the main repository:
$ cd / new / directory / project
$ git clone gituser @ githost: project.git
This we got a copy of the main repository. It is the current branch. Now you need to create a test branch.
Just copy the current branch to the main repository under the name of the test:
$ git push origin master: stage
And then pull out the test branch from the main repository under your own name:
$ git checkout -b stage origin / stage
Now the local repository contains two branches, master and stage. Both branches are associated with the same branches in the main repository.
In this local repository, the lead developer will check the branches sent by other developers and merge the checked branches with the branches of the main repository.
In addition, you need to specify the location of the dev working repository:
$ git remote add dev gituser @ githost: dev.git
Our project includes not only repositories, but also “executing” nodes - production and debugging.
Production and debugging are the essence of local repositories that are updated from the main repository. The difference between production and debugging is that production is updated from the current branch, and debugging from the test.
The launch of production, without going into details, was as follows:
1) to register in the system a new user, from under which production will work
2) add this user to gitosis (see section 5, in my example it is user *)
3) clone the main project repository to this user's directory
4) Configure the Apache virtual host (or whatever you like) on the project directory
And now for the update of production it is enough just to go to this directory and execute one single command:
$ git pull
All updates that are in the current branch, in the blink of an eye will be in production.
The debugging copy of the project is identical, except that after cloning the main repository, a switch was made from the current master branch to the test stage branch:
$ git checkout -b stage origin / stage
Now pull in the debug will pull updates from the test branch.
When starting to work on a project, the developer must first set up his local repository. The developer will deal with two remote repositories - the main and the working.
The main repository needs to be cloned:
$ git clone gituser @ githost: project.git
And the working repository is simply added to the config:
$ git remote add dev gituser @ githost: dev.git
This setting is performed only once. All further work is carried out according to the standard scheme (print the memo and stick it on the monitor).
Check mail. If there is a notification from Trac about a new task - start working:
$ quake exit
Create a new brunch based on the current branch from the main repository (we have agreed to call the brunch ticket numbers from Trac):
$ git checkout -b new_branch origin / master
Or return to work on the old brunch from the working repository.
$ git checkout -b old_branch dev / old_branch
Pull out the latest changes:
$ git pull
If new files were created during the work, add them to the brunch:
$ git add.
Save changes to local repository:
$ git commit -am 'komment'
Send a new brunch to the working repository:
$ git push new_branch dev
Or re-send the same old brunch:
$ git push
To re-assign the completed task in Trac to the leading developer. Back to the developer, it will return either with an indication of what needs to be redone, or with the closed status.
10 goto check mail;
Here it must be said about a couple of subtleties. The state of the local repository of each particular developer, in general, does not bother me, but still, so that people do not get confused once again, I recommend them to do two things.
Firstly, the branches sent to the working repository are no longer needed locally and can be safely removed:
$ git branch -D new_branch
Secondly, the list of brunches in remote repositories, issued by the command
$ git branch -r
it becomes outdated with time, since I remove from there the branches tested and merged with the current branch. To update information about remote repositories you need to run the command
$ git remote prune dev
which deletes the branches in the remote repository from the local cache. Please note - you only need to update the working repository. There are never any changes in the main repository, the same master and stage branches are always there.
Having received a notification from Trac about the task that was reassigned to me, I open this task and look at what it was all about to know what to check.
Then I update the data about the remote repositories:
$ git remote update
Now I will see new branches in the working repository, including the branch corresponding to the task being checked:
$ git branch -r
Then I pull the checked brunch from the working repository to myself (since the name of the brunch corresponds to the ticket number, I always know for sure which brunch to pull):
$ git checkout -b branch dev / branch
If this is not a new brunch, but a fix for the old one, then you still need to pull out the updates:
$ git pull
Now I can check the performance and correctness of the edits made by the developer.
Let's say the edit passed the test. Further actions depend on whether this edit is simple, one that can be sent to production without agreement with the customer, or is it a big edit that needs to be agreed.
If editing is simple, then I simply merge the checked brunch with the current branch and send the updated current branch to the main repository:
$ git checkout master
$ git merge branch
$ git push
After that, I delete the brunch locally and from the working repository, no one will ever need this brunch:
$ git branch -D branch
$ git push dev: branch
There is such a moment - first I wanted to entrust the removal of brunches from the working repository to the developers so that each of them would delete their brunches. But then he decided not to complicate people's lives. Those. the approach is this - if the developer sent a brunch that suited me, then this brunch should not bother the developer.
If editing requires coordination, then the checked brunch merges not with the actual branch, but with the test:
$ git checkout stage
$ git merge branch
$ git push
After sending the updated test branch to the main repository, I delete the checked brunch only locally:
$ git branch -D branch
In the working repository, this brunch remains. It is possible that the customer will want to remake something and then the developer will need this brunch to fix it.
In the test branch, the checked brunch lies and is not asking. When the customer gets to him and approves, then I will again pull this brunch from the working repository and salt with the current branch.
After all the branches are merged with the necessary branches and the whole thing is sent to the main repository, I go into production and debugging and update them.
( original article )
Below I want to describe my experience of team working on a project using git.
1. General principle
My workflow is organized as follows.
I am the lead dash developer, the head of the dash project manager. I have several developers in my team.
')
My job is this:
1) talk to the customer
2) to transform the vague and confused wishes of the customer into a clearly defined task
3) put this task to the developer
4) check the result of the task by the developer
5) unsatisfactory result to return to the developer for revision
6) to submit a satisfactory result to the customer for approval or immediately send to production
7) send the result approved by the customer in production
8) the result not approved by the customer back to the developer for revision
The work of the developer, respectively, is as follows:
1) get me the task
2) execute it
3) send me the result
4) if the task is returned for revision - to finalize and send to me again
For task management, I use Trac . Also in Trac the project documentation is kept, both programmer and user.
Having formulated the task, I write it down in Trac and assign it to some developer. The developer, after completing the task, reassigns it to me. I check the result and, either reassign it to the developer again, or mark it as completed.
The algorithm for working with git and the general picture of what is happening is shown schematically in the picture:
Now, from the theoretical part, let us turn to the practical one and see what all this means and how it works.
2. Git
Install git. Read some manual . Understand the local repository.
Please note - this article is not about git commands, but about how to link these commands into the desired sequence. Therefore, I will continue to give git commands without detailed explanations, assuming that you know the purpose of individual commands.
3. Access to the repository
When working as a team, you will need to provide access to the repository for several users. For convenient access rights to the repository, I use gitosis .
Gitosis is a set of scripts that implement convenient management of git repositories and access to them. It works like this:
- a server is started on the server to which all repositories will belong
- all calls to repositories are made via SSH, under the name of this user, user authorization is made by keys
- when logging in via SSH, gitosis scripts are automatically launched, which, depending on the setting, allow or prohibit further actions with repositories
The gitosis scripts and configs are stored in the repository themselves and configured by sending commits to this repository. It sounds crazy, but in fact nothing particularly tricky, quite simple and convenient.
4. Install gitosis
To install gitosis, you need (surprise!) To pull out the gitosis installation repository from the gitosis developer server:
$ git clone git: //eagain.net/gitosis.git
Install gitosis:
$ cd gitosis
$ su
# python setup.py install
The installation repository is no longer needed, it can be deleted.
Now you need to create a user in the system to which all repositories will belong:
$ su
# adduser gituser
And then initialize gitosis in the home directory of the created user, with the public key of who will be the gitosis administrator. The public key, of course, needs to be put somewhere, from where the user gituser can read it:
# su gituser
$ cd ~
$ gitosis-init <id_rsa.pub
Note that the gituser user and the gitosis administrator are not one person. The gituser user is simply the “keeper” of the repositories and never performs any actions at all.
I use another registered user in the system as a gitosis administrator. But, generally speaking, the administrator does not have to be a user registered in the system. The main thing is to specify the public key of the administrator when initializing gitosis.
After gitosis is initialized, the repositories directory will appear in the gituser user's home directory, in which all repositories will be stored. At first, there will only be the gitosis-admin.git repository, which stores the settings of the gitosis itself.
Please note - for some reason related to the features of different versions of Python, you may need to assign permissions to execute the post-update script located in the gitosis repository:
$ chmod 755 ~ / repositories / gitosis-admin.git / hooks / post-update
This completes the gitosis installation and the setup begins.
5. Setting up gitosis and creating repositories
Setting up gitosis is to change the contents of the gitosis repository by the administrator.
We become the gitosis administrator (if the administrator is a registered user in the system) or log out at all and log in where the administrator is registered (for example, on his laptop).
Now we pull out the gitosis setup repository:
$ git clone gituser @ githost: gitosis-admin.git
Where githost is the name of the server where we installed gitosis (and where we will store the repositories).
Please note that whatever the administrator’s name is, the server is always accessed under the username gituser.
After that, the gitosis-admin directory will appear in the admin home directory. In this directory we are interested in the gitosis.conf file, it is in it that all repositories are configured.
By default, it will have something like this:
[group gitosis-admin]
writable = gitosis-admin
members = admin @ host
What means "admin user is allowed to write to the gitosis-admin repository".
Creating a new repository is to add a new group to the config. The name of the group can be any, it is just for clarity. We need two repositories to work with:
[group project-write]
writable = project
members = superdeveloper
[group project-read]
readonly = project
members = developer1 developer2 developer3 user1 user2
[group dev]
writable = dev
members = superdeveloper developer1 developer2 developer3
where superdeveloper is the lead developer, developer * is the developers, user * is the other interested
This config means the following:
1) the lead developer is allowed to write to the main repository
2) everyone is allowed to read from the main repository
3) the lead developer and all developers are allowed to write to the working repository
All these users, like the gitosis administrator, do not necessarily have to be registered users in the system. The main thing is that they have public keys.
The public keys of the users specified in the config need to be copied to the gitosis-admin / keydir directory. Key files must have names like username.pub. In this example, these will be the names superdeveloper.pub, developer1.pub, user1.pub, etc.
After editing the config and copying keys, you need to commit the changes to the local repository:
$ git add.
$ git commit -am 'Add project Project'
And send the commit to the central repository, where the settings you have made will be picked up by gitosis:
$ git push
Everything, now our server of repositories is configured and necessary repositories are created (I say lies, repositories are not created yet, but will be created automatically at the first commit).
6. Assign repositories
If in the previous section you had a question - why for one project you need two repositories - then here is the answer.
The first repository, the main one, is production. The combat copy of the project will work on the code from this repository. The second repository, which is also a worker, is a development. In this repository is, of course, the development of the project.
I tried different schemes of teamwork and the most convenient at the moment seems to me to be a “dual repository" scheme. Work in it is approximately as follows:
1) I set the task for the developer
2) the developer takes the current project branch from the main repository and makes a local brunch from it
3) in this brunch, the developer solves the problem
4) the developer sends a brunch with the task to the working repository
5) I take this brunch from the working repository and check it
6) if the task is completed correctly, I merge this brunch with the current project branch in the main repository
This scheme has two key differences from the widely described scheme, when all development goes in the master branch of one repository.
Firstly, in my scheme, developers cannot make unauthorized changes (both accidental and intentional) to the current branch, i.e. in production.
Secondly, the current branch I never have inoperative.
The second reason, in fact, is more important. Unauthorized changes at any time can be rolled back, and the version control system. But to fix the non-working state of the current branch can be very difficult.
Let me explain by example.
Suppose the developer P1 edited P1 and sent it to the master branch. I checked this edit and found it bad. Bad editing needs to be redone.
While I checked, the P2 developer made the P2 edit and also sent it to the master. This edit was good. Good editing needs to be sent to production.
But now there are two edits in the master branch, good and bad. A good edit would need to be sent to production, but the presence of a bad edit does not allow it. You have to wait for a bad revision to be fixed.
Or another example - all edits are good, but some are not approved by the customer. Unapproved edits do not allow to get into production approved, and approval can take a long time.
In general, you need to make changes so that you can steer separately from each other, without dumping them all in a bunch in the master branch.
To do this, the developers send to the repository all their branches separately, without merging them with the master. I do merging. Accordingly, only the edits I have checked go to the current branch. Bad edits are sent for revision, and edits awaiting customer approval are sent to the test branch and just ... wait. And no one interferes.
Thus, the current branch is always in working condition.
In principle, sending brunch separately can be done in one repository. But in one repository it is impossible to separate access to individual branches, i.e. It is not allowed to write to the repository new branches and at the same time prohibit changing the current branch. Therefore, we need a second repository - in one there is an actual branch, in the other - all new working branches that appear as individual tasks are solved.
In fact, in large projects, each developer should generally have his own separate repository. But for now, it is quite convenient for me to live with two repositories - one is mine (production), the other is common for all developers (development).
7. Initial download of the project to the repository
Please note - the primary download is done by the lead developer, since only he has the right to write to the main repository.
Create a local repository in the project directory and drive the project files into it:
$ cd / old / directory / project
$ git init
$ git add.
$ git commit -am 'poehali!'
We inform the local repository about where the main repository is located:
$ git remote add origin gituser @ githost: project.git
Now we send the commit to the main repository:
$ git push origin master
Everything, the project is sent to the main repository. Now the old project directory can be easily banged and started working in a new directory (or on another computer), under the control of git.
8. Lead Developer Repository
Go to the new directory (or even to another computer) and pull out the main repository:
$ cd / new / directory / project
$ git clone gituser @ githost: project.git
This we got a copy of the main repository. It is the current branch. Now you need to create a test branch.
Just copy the current branch to the main repository under the name of the test:
$ git push origin master: stage
And then pull out the test branch from the main repository under your own name:
$ git checkout -b stage origin / stage
Now the local repository contains two branches, master and stage. Both branches are associated with the same branches in the main repository.
In this local repository, the lead developer will check the branches sent by other developers and merge the checked branches with the branches of the main repository.
In addition, you need to specify the location of the dev working repository:
$ git remote add dev gituser @ githost: dev.git
9. Project Infrastructure
Our project includes not only repositories, but also “executing” nodes - production and debugging.
Production and debugging are the essence of local repositories that are updated from the main repository. The difference between production and debugging is that production is updated from the current branch, and debugging from the test.
The launch of production, without going into details, was as follows:
1) to register in the system a new user, from under which production will work
2) add this user to gitosis (see section 5, in my example it is user *)
3) clone the main project repository to this user's directory
4) Configure the Apache virtual host (or whatever you like) on the project directory
And now for the update of production it is enough just to go to this directory and execute one single command:
$ git pull
All updates that are in the current branch, in the blink of an eye will be in production.
The debugging copy of the project is identical, except that after cloning the main repository, a switch was made from the current master branch to the test stage branch:
$ git checkout -b stage origin / stage
Now pull in the debug will pull updates from the test branch.
10. Developer repository
When starting to work on a project, the developer must first set up his local repository. The developer will deal with two remote repositories - the main and the working.
The main repository needs to be cloned:
$ git clone gituser @ githost: project.git
And the working repository is simply added to the config:
$ git remote add dev gituser @ githost: dev.git
This setting is performed only once. All further work is carried out according to the standard scheme (print the memo and stick it on the monitor).
11. Developer's Memo
Check mail. If there is a notification from Trac about a new task - start working:
$ quake exit
Create a new brunch based on the current branch from the main repository (we have agreed to call the brunch ticket numbers from Trac):
$ git checkout -b new_branch origin / master
Or return to work on the old brunch from the working repository.
$ git checkout -b old_branch dev / old_branch
Pull out the latest changes:
$ git pull
--- Perform a task in a new brunch. Here is the work with the code. ---
If new files were created during the work, add them to the brunch:
$ git add.
Save changes to local repository:
$ git commit -am 'komment'
Send a new brunch to the working repository:
$ git push new_branch dev
Or re-send the same old brunch:
$ git push
To re-assign the completed task in Trac to the leading developer. Back to the developer, it will return either with an indication of what needs to be redone, or with the closed status.
10 goto check mail;
Here it must be said about a couple of subtleties. The state of the local repository of each particular developer, in general, does not bother me, but still, so that people do not get confused once again, I recommend them to do two things.
Firstly, the branches sent to the working repository are no longer needed locally and can be safely removed:
$ git branch -D new_branch
Secondly, the list of brunches in remote repositories, issued by the command
$ git branch -r
it becomes outdated with time, since I remove from there the branches tested and merged with the current branch. To update information about remote repositories you need to run the command
$ git remote prune dev
which deletes the branches in the remote repository from the local cache. Please note - you only need to update the working repository. There are never any changes in the main repository, the same master and stage branches are always there.
12. Lead Developer Actions
Having received a notification from Trac about the task that was reassigned to me, I open this task and look at what it was all about to know what to check.
Then I update the data about the remote repositories:
$ git remote update
Now I will see new branches in the working repository, including the branch corresponding to the task being checked:
$ git branch -r
Then I pull the checked brunch from the working repository to myself (since the name of the brunch corresponds to the ticket number, I always know for sure which brunch to pull):
$ git checkout -b branch dev / branch
If this is not a new brunch, but a fix for the old one, then you still need to pull out the updates:
$ git pull
Now I can check the performance and correctness of the edits made by the developer.
Let's say the edit passed the test. Further actions depend on whether this edit is simple, one that can be sent to production without agreement with the customer, or is it a big edit that needs to be agreed.
If editing is simple, then I simply merge the checked brunch with the current branch and send the updated current branch to the main repository:
$ git checkout master
$ git merge branch
$ git push
After that, I delete the brunch locally and from the working repository, no one will ever need this brunch:
$ git branch -D branch
$ git push dev: branch
There is such a moment - first I wanted to entrust the removal of brunches from the working repository to the developers so that each of them would delete their brunches. But then he decided not to complicate people's lives. Those. the approach is this - if the developer sent a brunch that suited me, then this brunch should not bother the developer.
If editing requires coordination, then the checked brunch merges not with the actual branch, but with the test:
$ git checkout stage
$ git merge branch
$ git push
After sending the updated test branch to the main repository, I delete the checked brunch only locally:
$ git branch -D branch
In the working repository, this brunch remains. It is possible that the customer will want to remake something and then the developer will need this brunch to fix it.
In the test branch, the checked brunch lies and is not asking. When the customer gets to him and approves, then I will again pull this brunch from the working repository and salt with the current branch.
After all the branches are merged with the necessary branches and the whole thing is sent to the main repository, I go into production and debugging and update them.
( original article )
Source: https://habr.com/ru/post/75990/
All Articles