Obfuscators (and deobfuscators) for .NET §1
(This is a continuation of the review obfuscators. Start here )
Combining assemblies and namespaces (Assembly Merge, Namespace Flatten)
This technique in itself does not delay the attacker for a minute, but is very useful for further confusing him. Because the more classes the resulting assembly will contain, the more difficult it will be to find what you need without a detailed analysis.
Again, when you try to steal your code, the attacker will receive instead of several library projects and one program only one project in which all classes will be in the same folder (and in one namespace).
To merge assemblies, you can use the ilmerge utility or the functionality built into the obfuscator. Namespaces are usually combined during obfuscation of class names (so that there are no collisions with equally named classes from different namespaces).
')
Rename classes, methods, etc.
This approach is implemented in almost all respecting obfuscators. All “hints” that an attacker can use to quickly find classes that are responsible for licensing are removed, or if the code is “stolen”, it will be very difficult to understand the logic of the application, why and how classes are created, and methods are called.

The most popular option at the moment is renaming to non-printable characters (or some kind of "Chinese" of 儽. 凍 :: 儽 type). This makes viewing the assembly in the reflector a bit difficult, but it doesn’t affect the deobfuscator.
In addition, from the shortcomings we receive hard-to-get messages about exceptions that could occur at the end user, and if he sends us the text not in Unicode-encoding, then it will be almost impossible to parse it.
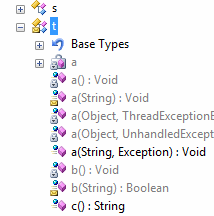 A similar option is to use short but printed identifiers (a, b, c, .... aa, ab, ac ...). For deobfuscator, this option is completely analogous to the previous one, but it does not have this drawback.
A similar option is to use short but printed identifiers (a, b, c, .... aa, ab, ac ...). For deobfuscator, this option is completely analogous to the previous one, but it does not have this drawback.
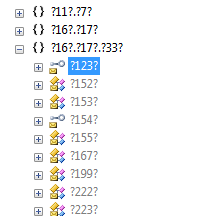 The third naming option — using high-level keywords (C # or VB.net) or invalid identifiers for this language (for example? 123?) —Is no better than the previous two, but for some reason, it’s believed that when the code is “stolen” take advantage of the deobfuscator, and the output will be non-compiled text ...
The third naming option — using high-level keywords (C # or VB.net) or invalid identifiers for this language (for example? 123?) —Is no better than the previous two, but for some reason, it’s believed that when the code is “stolen” take advantage of the deobfuscator, and the output will be non-compiled text ...
There are still a bunch of "stupid" options that of course hide the meaning of the original names, but why make them so long?

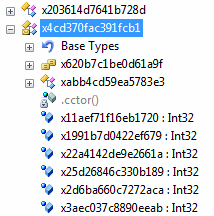
An interesting and even more confusing approach is to create a large number of overload-methods with the same name, which had different names before obfuscation, and were in no way related.
Also .net allows you to create override-methods whose names are different from the names of the methods they overlap. This confuses not only intruders, but also adds extra requirements to the deobfuscator.

Changing class content
Some obfuscators can combine several classes into one, or make them from a regular class nested. But such obfuscation often leads to errors in the resulting program, and is used very rarely.
Obfuscation control flow
At this stage, the order of instructions in the code changes and even the instructions themselves change. Perhaps the most interesting and most controversial stage.
This technique allows you to mislead (and sometimes in complete stupor) most high-level language decompilers. That very well counteracts the theft of the code. Also "confuses" crackers and authors of keygens.
The reverse side of the coin - sometimes reduced performance. It is logical that the more we confuse the program execution, the longer it will be executed. This applies particularly to the use of exceptions.
In most cases, the method code fights into blocks, these blocks are shuffled in random order and “glued together” using unconditional jumps (instructions br and br.s). As an example:
There are also cases when the method is very short, and it is not possible to “mix” it well, in this case some obfuscators give a transition to the following instruction:
Between the transition instruction, and its goal, very often “all the bullshit” is inserted, such as falling out into a debugger, or simply invalid instructions:
Some obfuscators replace transition instructions (both original and inserted) with loading constants and switching to a switch:
Obviously, in this example, the instruction with offset L_0045 "in girlhood" was br L_0047, and if we take into account the previous techniques, then this is generally nop;)
Sometimes you can find "transition to transition":

in one of the programs I saw a chain of 6 (six) such transitions;)
An interesting approach is the use of conditional transitions for expressions that are always true (or incorrect).
The simplest example:
The same, but slightly more involved:
Another option:
Simple mixing of some instructions, for example:
One of the most “hard” methods is the exception that is always thrown inside the try — catch block. This approach is used very rarely, because dramatically reduces performance and can disrupt application logic if used incorrectly. I do not give a screenshot because it takes up a lot of space.
It seems that the most popular techniques I have listed, if you know something else, please let us know in the comments.
Invalid IL
It's all very simple. Opcodes not described in the standard (that is, invalid instructions) are inserted into code sections that will never be executed.
In the reflector you will see something like this:

or if you switch to IL:

This technique discourages beginners "Xaxors." But it is not something difficult to bypass (these opcodes are simply replaced by nop).
Line hiding
Deobfuscators call this “string encryption,” but to call it encryption does not turn my language.
Usually this is done by some “childish” XOR type encryption algorithm for a constant:
Sometimes strings are combined into one, and then the Substring method is called; sometimes strings are hidden in resources.
In any case, "encryption" is represented as a static method with several arguments, usually a string and / or a number. No cryptographic algorithms are applied, which is quite logical: if real encryption is applied here, the program will hopelessly slow down.
This method saves from beginning cracker who will search by code for a string like “Invalid serial number” or other message texts.
Specific attributes and bugs decompilers
The most frequently encountered attribute is [ SuppressIldasm ], which “politely asks” for the official Microsoft decompiler, ildasm, not to work on this build. There are also specific attributes for the reflector and for commercial decompilers.
As bugs you can come across as purely technical flaws of decompilers (for example, the reflector falls on ldfld string instructions 儽. 凍 :: 儽, and most deofuscators based on Mono.Cecil are on incorrect RVA), also algorithmic assumptions: many high-level decompilers track state of the stack, but go according to the method not as a graph, but linearly, and happily fall down on methods in which, after the last instruction ret, an infinite loop is inserted. Against the Reflexil plug-in, the instruction passing to itself well “helps”.
Other methods
Sometimes you can find a very similar approach to hiding rows, but for resources.
Also, one of the obfuscators offers “V-Spot Elimination” (which it is very proud of) - creating proxy classes for BCL classes, which slows down the analysis and slightly damages the decompilation code.
Manged to unmanaged .net code conversion is also used. Those. all rebuilt with unmanaged notes. Almost all the functionality within the domain is preserved, but the reflector does not look at the code.
Thanks to Exaktus for comments and additions.
Next will be part 1.2. Overview Obfuscators
to be continued...
* All source code was highlighted with MSVS and wordpad;)
1. Obfuscators.
1.1. Techniques
Combining assemblies and namespaces (Assembly Merge, Namespace Flatten)
This technique in itself does not delay the attacker for a minute, but is very useful for further confusing him. Because the more classes the resulting assembly will contain, the more difficult it will be to find what you need without a detailed analysis.
Again, when you try to steal your code, the attacker will receive instead of several library projects and one program only one project in which all classes will be in the same folder (and in one namespace).
To merge assemblies, you can use the ilmerge utility or the functionality built into the obfuscator. Namespaces are usually combined during obfuscation of class names (so that there are no collisions with equally named classes from different namespaces).
')
Rename classes, methods, etc.
This approach is implemented in almost all respecting obfuscators. All “hints” that an attacker can use to quickly find classes that are responsible for licensing are removed, or if the code is “stolen”, it will be very difficult to understand the logic of the application, why and how classes are created, and methods are called.
The most popular option at the moment is renaming to non-printable characters (or some kind of "Chinese" of 儽. 凍 :: 儽 type). This makes viewing the assembly in the reflector a bit difficult, but it doesn’t affect the deobfuscator.
In addition, from the shortcomings we receive hard-to-get messages about exceptions that could occur at the end user, and if he sends us the text not in Unicode-encoding, then it will be almost impossible to parse it.
A similar option is to use short but printed identifiers (a, b, c, .... aa, ab, ac ...). For deobfuscator, this option is completely analogous to the previous one, but it does not have this drawback. The third naming option — using high-level keywords (C # or VB.net) or invalid identifiers for this language (for example? 123?) —Is no better than the previous two, but for some reason, it’s believed that when the code is “stolen” take advantage of the deobfuscator, and the output will be non-compiled text ...There are still a bunch of "stupid" options that of course hide the meaning of the original names, but why make them so long?
An interesting and even more confusing approach is to create a large number of overload-methods with the same name, which had different names before obfuscation, and were in no way related.
Also .net allows you to create override-methods whose names are different from the names of the methods they overlap. This confuses not only intruders, but also adds extra requirements to the deobfuscator.
Changing class content
Some obfuscators can combine several classes into one, or make them from a regular class nested. But such obfuscation often leads to errors in the resulting program, and is used very rarely.
Obfuscation control flow
At this stage, the order of instructions in the code changes and even the instructions themselves change. Perhaps the most interesting and most controversial stage.
This technique allows you to mislead (and sometimes in complete stupor) most high-level language decompilers. That very well counteracts the theft of the code. Also "confuses" crackers and authors of keygens.
The reverse side of the coin - sometimes reduced performance. It is logical that the more we confuse the program execution, the longer it will be executed. This applies particularly to the use of exceptions.
In most cases, the method code fights into blocks, these blocks are shuffled in random order and “glued together” using unconditional jumps (instructions br and br.s). As an example:
L_0034: br.s L_003a
L_0036: nop
L_0037: br.s L_0041
L_0039: nop
L_003a: callvirt instance void [ Aaa ] Xxx . Yyy :: Zzz ()
L_003f: br.s L_0036
L_0041: nopThere are also cases when the method is very short, and it is not possible to “mix” it well, in this case some obfuscators give a transition to the following instruction:
L_0008: br.s L_000a
L_000a: ldarg.0Between the transition instruction, and its goal, very often “all the bullshit” is inserted, such as falling out into a debugger, or simply invalid instructions:
L_0000: br.s L_0003
L_0002: break
L_0003: ldarg.0Some obfuscators replace transition instructions (both original and inserted) with loading constants and switching to a switch:
L_0000: br.s L_0023
L_0002: ldloc num3
L_0006: switch (L_005b, L_0068, L_00ce, L_00af, L_0047 , L_007b)
...
...
...
L_003c: ldc.i4 4
L_0041: stloc num3
L_0045: br.s L_0002Obviously, in this example, the instruction with offset L_0045 "in girlhood" was br L_0047, and if we take into account the previous techniques, then this is generally nop;)
Sometimes you can find "transition to transition":
in one of the programs I saw a chain of 6 (six) such transitions;)
An interesting approach is the use of conditional transitions for expressions that are always true (or incorrect).
The simplest example:
L_0014: ldc.i4.1
L_0015: brtrue.s L_002eThe same, but slightly more involved:
L_0014: ldc.i4.1
L_0015: stloc.0
L_0016: br.s L_001c
L_0018: nop
L_0019: ldarg.1
L_001a: br.s L_002e
L_001c: ldloc.0
L_001d: brtrue.s L_0018Another option:
if (5 < (5 - 6)) {
// IL-,
}L_0000: ldc.i4.5
L_0001: dup
L_0002: dup
L_0003: ldc.i4.6
L_0004: sub
L_0005: blt L_0001Simple mixing of some instructions, for example:
L_0000: ldc.i4 4
L_0005: stloc num
L_0009: ldstr "\u5f03"
L_000e: ldloc numOne of the most “hard” methods is the exception that is always thrown inside the try — catch block. This approach is used very rarely, because dramatically reduces performance and can disrupt application logic if used incorrectly. I do not give a screenshot because it takes up a lot of space.
It seems that the most popular techniques I have listed, if you know something else, please let us know in the comments.
Invalid IL
It's all very simple. Opcodes not described in the standard (that is, invalid instructions) are inserted into code sections that will never be executed.
In the reflector you will see something like this:
or if you switch to IL:
This technique discourages beginners "Xaxors." But it is not something difficult to bypass (these opcodes are simply replaced by nop).
Line hiding
Deobfuscators call this “string encryption,” but to call it encryption does not turn my language.
Usually this is done by some “childish” XOR type encryption algorithm for a constant:
public static string Decode( string str, int num)
{
int length = str.Length;
char [] chArray = str.ToCharArray();
while (--length >= 0)
chArray[length] = ( char )(chArray[length] ^ num);
return new string (chArray);
}
Sometimes strings are combined into one, and then the Substring method is called; sometimes strings are hidden in resources.
In any case, "encryption" is represented as a static method with several arguments, usually a string and / or a number. No cryptographic algorithms are applied, which is quite logical: if real encryption is applied here, the program will hopelessly slow down.
This method saves from beginning cracker who will search by code for a string like “Invalid serial number” or other message texts.
Specific attributes and bugs decompilers
The most frequently encountered attribute is [ SuppressIldasm ], which “politely asks” for the official Microsoft decompiler, ildasm, not to work on this build. There are also specific attributes for the reflector and for commercial decompilers.
As bugs you can come across as purely technical flaws of decompilers (for example, the reflector falls on ldfld string instructions 儽. 凍 :: 儽, and most deofuscators based on Mono.Cecil are on incorrect RVA), also algorithmic assumptions: many high-level decompilers track state of the stack, but go according to the method not as a graph, but linearly, and happily fall down on methods in which, after the last instruction ret, an infinite loop is inserted. Against the Reflexil plug-in, the instruction passing to itself well “helps”.
Other methods
Sometimes you can find a very similar approach to hiding rows, but for resources.
Also, one of the obfuscators offers “V-Spot Elimination” (which it is very proud of) - creating proxy classes for BCL classes, which slows down the analysis and slightly damages the decompilation code.
Manged to unmanaged .net code conversion is also used. Those. all rebuilt with unmanaged notes. Almost all the functionality within the domain is preserved, but the reflector does not look at the code.
Thanks to Exaktus for comments and additions.
Next will be part 1.2. Overview Obfuscators
to be continued...
* All source code was highlighted with MSVS and wordpad;)
Source: https://habr.com/ru/post/74463/
All Articles