GFS Distributed File System (Google File System)
Currently, in the face of growing information, there are tasks of storing and processing data of a very large amount. Therefore, this data is processed on several servers simultaneously, which form clusters. To simplify work with data on clusters and develop distributed file systems. We will take a closer look at the example of the Google File System distributed file system used by Google . (The article is, in fact, a free and abridged translation of the original article ).
GFS is probably the most well-known distributed file system. Reliable scalable data storage is essential for any application that works with such a large data array as all documents on the Internet. GFS is Google ’s primary storage platform. GFS is a large distributed file system capable of storing and processing huge amounts of information.
GFS was based on the following criteria:
Files in GFS are organized hierarchically, using directories, as in any other file system, and are identified in their own way. You can perform common operations with files in GFS: create, delete, open, close, read, and write.
Moreover, GFS supports backups, or snapshots. You can create such backups for files or a directory tree, and with little cost.
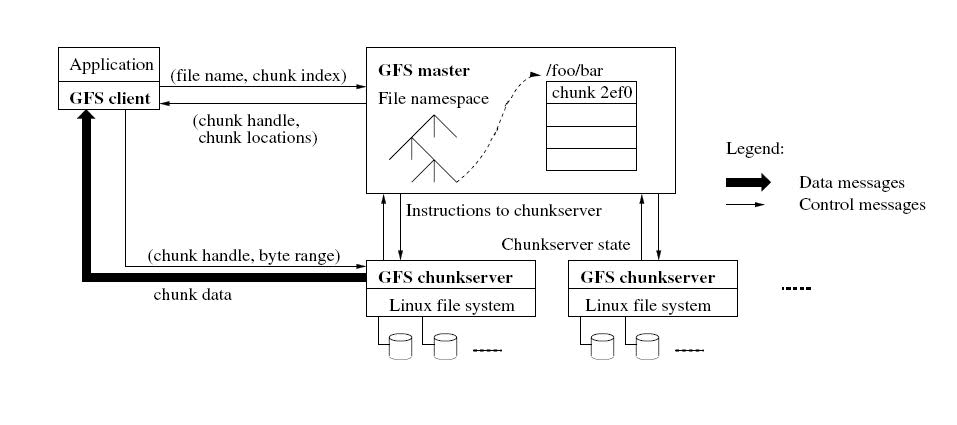
Figure taken from the original article.
The system has a master server and a chank server that actually stores data. As a rule, a GFS cluster consists of one master master machine (master) and multiple machines that store chunk server file fragments (chunkservers). Customers have access to all of these machines. Files in GFS are broken into chunks (chunk, you can tell a fragment). Chunk has a fixed size that can be customized. Each such chunk has a unique and global 64-bit key, which is issued by the master when creating a chunk. Chunk servers store chunks, like regular Linux files, on a local hard drive. For reliability, each chunk can be replicated to other chank servers. Three replicas are commonly used.
The wizard is responsible for working with the metadata of the entire file system. Metadata includes namespaces, data access control information, mapping files to chunks, and the current position of chunks. The master also controls all global system activity, such as managing free chunks, garbage collection (collecting more unnecessary chunks) and moving chunks between chunk servers. The wizard constantly exchanges messages (HeartBeat messages) with chunk servers to give instructions and determine their status (to find out if they are still alive).
The client only interacts with the wizard to perform metadata related operations. All operations with the data itself are performed directly with the chank servers. GFS - the system does not support the POSIX API, so developers did not have to communicate with the Linux VNode level.
Developers do not use data caching, however, clients cache metadata. On the chunk servers, the Linux operating system already caches the most used blocks in memory. In general, the refusal of caching allows you not to think about the problem of cache validity (cache coherence).
')
Using one wizard greatly simplifies the system architecture. Allows you to make complex movements of chunks, organize replication using global data. It would seem that the presence of only one master should be a bottleneck of the system, but it is not. Clients never read or write data through wizards. Instead, they ask the master, with which chunk server they should contact, and then they communicate with the chank servers directly.
Consider how the data is read by the client. First, knowing the size of the chunk,
file name and offset relative to the beginning of the file, the client determines the chunk number inside the file. Then he sends a request to the master containing the file name and chunk number in this file. The master issues chank servers, one per each replica, which store the chunk we need. The wizard also provides the client with a chunk ID.
The client then decides which of the replicas he likes more (usually the one that is closer), and sends a request consisting of a chunk and an offset relative to the beginning of the chunk. Further reading of the data does not require the intervention of the wizard. In practice, as a rule, the client in one request for reading includes several chunks at once, and the master gives the coordinates of each of the chunks in one answer.
Chunk size is an important feature of the system. As a rule, it is set to 64 megabytes, which is much larger than the block size in a regular file system. It is clear that if you need to store a lot of files that are smaller than the size of the chunk, then we will spend a lot of extra memory. But the choice of such a large chunk is due to the tasks that Google has to solve on its clusters. As a rule, something has to be considered for all documents on the Internet, and therefore the files in these tasks are very large.
The wizard stores three important types of metadata: file namespaces and chunks, mapping the file to chunks, and the position of the chunk replicas. All metadata is stored in the wizard. Since the metadata is stored in memory, wizard operations are fast. The master learns the state of affairs in the system simply and efficiently. It is scanning the chank servers in the background. These periodic scans are used for garbage collection, additional replications, in the event of an unavailable chank server and moving chunks, for load balancing and free space on the hard drives of the chank servers.
Master tracks the position of the chunks. When starting the chank server, the master remembers its chunks. In the process, the master monitors all movements of the chunks and the state of the chank servers. Thus, it has all the information about the position of each chunk.
An important part of the metadata is the transaction log. The wizard stores a sequence of critical metadata changes. From these marks in the log of operations, the logical time of the system is determined. It is this logical time that determines the versions of files and chunks.
Since the operation log is an important part, it should be stored securely, and all changes in it should be visible to clients only when the metadata changes. The operation log is replicated to several remote machines, and the system responds to the client operation only after saving this log to the master disk and the disks of the remote machines.
The wizard restores the system status by executing a log of operations. The operation log saves a relatively small size, keeping only the last operations. In the process, the wizard creates checkpoints when the size of the log exceeds a certain value, and the system can only be restored to the nearest checkpoint. Further on the log, you can replay some operations, so the system can roll back to a point that is between the last checkpoint and the current time.
Above was described the architecture of the system that minimizes the master's intervention in the execution of operations. Now consider how the client, master, and chank servers interact to move data, perform atomic write operations, and create a backup (snapshot).
Each change to a chunk must be duplicated on all replicas and change metadata. In GFS, the master gives a chunk to one of the servers storing this chunk. Such a server is called a primary replica. The remaining replicas are declared secondary (secondary). The primary replica collects sequential changes to the chunk, and all replicas follow this sequence when these changes occur.
The mechanism of possession of the chunk is designed in such a way as to minimize the burden on the master. When allocating memory, it waits 60 seconds first. And then, if a primary replica is required, the master can be requested to extend this interval and, as a rule, receives a positive response. During this wait period, the wizard can undo the changes.
Consider in detail the process of recording data. It is shown in steps in the figure, with thin lines corresponding to control flows, and bold data flows.
This drawing is also taken from the original article.
From the example above, it is clear that the creators have separated the data flow and the control flow. If the control flow only goes to the primary replica, then the data flow goes to all replicas. This is done to avoid creating bottlenecks in the network, and instead make extensive use of the bandwidth of each machine. Also, in order to avoid bottlenecks and congested connections, the transmission scheme to the nearest neighbor in the network topology is used. Suppose that a client sends data to the chank-servers S1 , ..., S4 . The client sends data to the nearest server, let S1 . He further sends to the nearest server, let it be S2 . S2 then forwards them to the nearest S3 or S4 , and so on.
Also, the delay is minimized due to the use of TCP packet pipelining. That is, as soon as the chan-server received some part of the data, it immediately starts to send them. Without network congestion, the ideal time to send data with a volume of B bytes to R replicas is B / T + RL , where T is the network bandwidth and L is the delay in transferring one byte between two machines.
GFS supports such an operation as the atomic addition of data to a file. Usually, when writing some data to a file, we specify this data and offset. If several clients perform a similar operation, then these operations cannot be rearranged in places (this can lead to incorrect operation). If we just want to add data to the file, then in this case we specify only the data itself. GFS will add their atomic operation. Generally speaking, if the operation fails on one of the secondary replicas, then GFS will return an error, and the data will be different on different replicas.
Another interesting thing about GFS is backups (you can still tell a snapshot) of a file or directory tree that are created almost instantly, while almost without interrupting the operations in the system. It turns out at the expense of technology similar to copy on write . Users use this feature to create data branches or as an intermediate point, to start some experiments.
Master is an important link in the system. It manages chunk replications: makes decisions about placement, creates new chunks, and coordinates various activities within the system to keep chunks fully replicated, load balancing on chank servers and assembling unused resources.
Unlike most file systems, GFS does not store the contents of files in a directory. GFS logically represents a namespace, like a table that maps each path to metadata. Such a table can be effectively stored in memory in the form of a boron (a dictionary of these very paths). Each vertex in this tree (corresponds either to the absolute path to the file or to the directory) has the corresponding data for read-write lock (read write lock). Each operation of the master requires the establishment of some locks. At this point, the system uses read-write locks. Usually, if an operation works with /d1/d2/.../dn/leaf , then it sets read locks on / d1, / d1 / d2, ..., d1 / d2 /.../ dn and lock, either for reading or writing to d1 / d2 /.../ dn / leaf . Thus leaf can be both a directory, and a file.
Let us show by example how the blocking mechanism can prevent the creation of the file / home / user / foo during the backup of / home / user to / save / user . The backup operation establishes locks for reading on / home and / save , as well as locks for writing to / home / user and / save / user . The file creation operation requires a read lock on / home and / home / user , as well as a write lock on / home / user / foo . Thus, the second operation will not start until the first is completed, since there is a conflicting lock on / home / user . When creating a file, no write lock is required on the parent directory; a read lock is enough, which prevents the removal of this directory.
GFS clusters are highly distributed and layered. Usually, such a cluster has hundreds of chank servers located on different racks. These servers, generally speaking, are available for a large number of clients located in the same or a different rack. Connections between two machines from different racks can go through one or more switches. Multi-level distribution is a very difficult task of reliable, scalable and affordable data distribution.
The replica location policy tries to satisfy the following properties: maximizing data reliability and availability and maximizing the use of network bandwidth. Replicas must be located not only on different disks or different machines, but moreover on different racks. This ensures that the chunk is available even if the entire rack is damaged or disconnected from the network. With this arrangement, the reading takes time approximately equal to the network bandwidth, but the data flow during recording must pass through different racks.
When the wizard creates a chunk, he chooses where to place the replica. It comes from several factors:
As soon as the number of replicas falls below the value set by the user, the master replicates the chunk again. This can happen for several reasons: the chunk server became unavailable, one of the disks failed or the value that specifies the number of replicas was increased. Each chunk, which must be replicated, is given a priority, which also depends on several factors. First, the priority is higher for the chunk that has the smallest number of replicas. Secondly, in order to increase the reliability of application execution, the priority is increased for chunks that block the progress of the client’s work
The wizard selects the chunk with the highest priority and copies it, giving the instruction to one of the chunk servers to copy it from the available replica. New replica is based on the same reasons as when creating.
During operation, the master constantly balances replicas. Depending on the distribution of replicas in the system, it moves the replica to equalize the disk load and load balancing. Also, the master must decide which of the replicas should be removed. As a rule, a replica that is located on the chan-server with the least free hard disk space is deleted.
Another important feature of the wizard is garbage collection. When you delete a file, GFS does not require the immediate return of free disk space. It does this during regular garbage collection, which occurs at the chunk level as well as at the file level. The authors believe that this approach makes the system more simple and reliable.
When an application deletes a file, the wizard remembers this fact in logs, like many others. However, instead of requesting immediate restoration of freed resources, the file is simply renamed, with the time of the deletion added to the file name, and it becomes invisible to the user. And the wizard, during a regular scan of the file system namespace, actually deletes all such hidden files that were deleted by the user more than three days ago (this interval is configured). Until this point, the file continues to be in the system as hidden, and it can be read or renamed back for recovery. When a hidden file is deleted by the wizard, then information about it is also removed from the metadata, and all chunks of this file are unlinked.
In addition to the regular file namespace scan, the wizard does a similar scan of the chunk namespace. The wizard identifies the chunks that are disconnected from the file, removes them from the metadata, and during regular communications with the chank servers, sends them a signal that all the replicas containing the specified chank can be deleted. This approach to garbage collection has many advantages, with one drawback: if the place in the system ends and deferred removal increases the unused space, until the moment of physical removal. But there is the possibility of restoring deleted data, the possibility of flexible load balancing during deletion and the ability to restore the system in case of any failures.
The authors of the system consider one of the most difficult problems frequent disruptions in the operation of the system components. The quantity and quality of the components make these failures not just an exception, but rather the norm. Component failure may be caused by the unavailability of this component or, worse, the presence of corrupted data. GFS supports the system in working form using two simple strategies: fast recovery and replication.
Fast recovery is, in fact, a reboot of the machine. At the same time, the launch time is very small, which leads to a small hitch, and then the work continues normally. About replication chunk already mentioned above. The wizard replicates the chunk if one of the replicas has become inaccessible or the data containing the chunk replica has become corrupted. Damaged chunks are determined by calculating checksums.
Another type of replication in the system, about which little has been said - is the replication of the wizard. The operation log and checkpoints are replicated. Each change of files in the system occurs only after the operations log is written to the disks by the master, and the disks of the machines to which the log is replicated. In case of minor problems, the wizard may reboot. In case of problems with a hard disk or other vital infrastructure of the wizard, GFS starts a new wizard, on one of the machines where the wizard data has been replicated. Clients contact the DNS wizard, which can be reassigned to a new machine. The new master is the shadow of the old, not an exact copy. Therefore, it has read-only access to files. That is, it does not become a full-fledged master, but only supports the operation log and other structures of the master.
An important part of the system is the ability to maintain data integrity. A regular GFS cluster consists of hundreds of machines with thousands of hard drives located on them, and these drives fail when working with an enviable constancy, which leads to data corruption. The system can recover data using replications, but for this it is necessary to understand whether the data has become corrupted. Simple comparison of different replicas on different chank-servers is inefficient. Moreover, there may be inconsistency of data between different replicas, leading to different data. Therefore, each chunk server must independently determine the integrity of the data.
Each chunk is divided into blocks of 64 KB in length. Each such block corresponds to a 32- bit checksum. Like other metadata, these amounts are stored in memory, regularly stored in the log, separately from user data.
Before reading the data, the chunk server checks the checksums of the chunk blocks that intersect with the requested data by the user or another chunk server. That is, the chank server does not distribute the corrupted data. If the checksums do not match, the chunk server returns an error to the machine that submitted the request and reports it to the master. The user can read data from another replica, and the wizard creates another copy from the data of another replica. After that, the wizard gives instructions to this chank server to delete this corrupted replica.
When adding new data, verification of checksums does not occur, and new checksums are recorded for blocks. If the disk is damaged, it will be determined when you try to read this data. - , , , .
GFS is probably the most well-known distributed file system. Reliable scalable data storage is essential for any application that works with such a large data array as all documents on the Internet. GFS is Google ’s primary storage platform. GFS is a large distributed file system capable of storing and processing huge amounts of information.
GFS was based on the following criteria:
- The system is built from a large number of ordinary inexpensive equipment, which often fails. There should be monitoring of failures, and the possibility in case of failure of any equipment to restore the functioning of the system.
- The system should store a lot of large files. As a rule, several million files, each from 100 MB and more. Also often have to deal with multi-gigabyte files, which must also be effectively stored. Small files should also be stored, but the system is not optimized for them.
- As a rule, there are two types of reading: reading a large sequential piece of data and reading a small amount of arbitrary data. When reading a large data stream, the usual thing is to request a fragment of 1 MB or more in size. Such sequential operations from one client often read successively pieces of the same file. Reading a small amount of data, as a rule, has a volume of several kilobytes. Applications that are critical in terms of execution time should accumulate a certain number of such requests and sort them by offset from the beginning of the file. This will avoid when reading the back-view wanderings.
- Often there are write operations of a large sequential piece of data that needs to be added to a file. Usually, data volumes for writing are of the same order as for reading. Records of small volumes, but in arbitrary places of the file, as a rule, are not performed effectively.
- The system should implement the strictly outlined semantics of parallel work of several clients, if they are simultaneously trying to add data to the same file. In this case, it may happen that hundreds of requests to write to a single file will arrive at the same time. In order to cope with this, the atomicity of the operations of adding data to a file is used, with some synchronization. That is, if a read operation is received, it will be executed, either before the next write operation or after.
- High throughput is preferred over low latency. So, most applications in Google prefer working with large amounts of data at high speed, and the performance of a single read and write operation, generally speaking, can be stretched.
Files in GFS are organized hierarchically, using directories, as in any other file system, and are identified in their own way. You can perform common operations with files in GFS: create, delete, open, close, read, and write.
Moreover, GFS supports backups, or snapshots. You can create such backups for files or a directory tree, and with little cost.
GFS architecture
Figure taken from the original article.
The system has a master server and a chank server that actually stores data. As a rule, a GFS cluster consists of one master master machine (master) and multiple machines that store chunk server file fragments (chunkservers). Customers have access to all of these machines. Files in GFS are broken into chunks (chunk, you can tell a fragment). Chunk has a fixed size that can be customized. Each such chunk has a unique and global 64-bit key, which is issued by the master when creating a chunk. Chunk servers store chunks, like regular Linux files, on a local hard drive. For reliability, each chunk can be replicated to other chank servers. Three replicas are commonly used.
The wizard is responsible for working with the metadata of the entire file system. Metadata includes namespaces, data access control information, mapping files to chunks, and the current position of chunks. The master also controls all global system activity, such as managing free chunks, garbage collection (collecting more unnecessary chunks) and moving chunks between chunk servers. The wizard constantly exchanges messages (HeartBeat messages) with chunk servers to give instructions and determine their status (to find out if they are still alive).
The client only interacts with the wizard to perform metadata related operations. All operations with the data itself are performed directly with the chank servers. GFS - the system does not support the POSIX API, so developers did not have to communicate with the Linux VNode level.
Developers do not use data caching, however, clients cache metadata. On the chunk servers, the Linux operating system already caches the most used blocks in memory. In general, the refusal of caching allows you not to think about the problem of cache validity (cache coherence).
')
Master
Using one wizard greatly simplifies the system architecture. Allows you to make complex movements of chunks, organize replication using global data. It would seem that the presence of only one master should be a bottleneck of the system, but it is not. Clients never read or write data through wizards. Instead, they ask the master, with which chunk server they should contact, and then they communicate with the chank servers directly.
Consider how the data is read by the client. First, knowing the size of the chunk,
file name and offset relative to the beginning of the file, the client determines the chunk number inside the file. Then he sends a request to the master containing the file name and chunk number in this file. The master issues chank servers, one per each replica, which store the chunk we need. The wizard also provides the client with a chunk ID.
The client then decides which of the replicas he likes more (usually the one that is closer), and sends a request consisting of a chunk and an offset relative to the beginning of the chunk. Further reading of the data does not require the intervention of the wizard. In practice, as a rule, the client in one request for reading includes several chunks at once, and the master gives the coordinates of each of the chunks in one answer.
Chunk size is an important feature of the system. As a rule, it is set to 64 megabytes, which is much larger than the block size in a regular file system. It is clear that if you need to store a lot of files that are smaller than the size of the chunk, then we will spend a lot of extra memory. But the choice of such a large chunk is due to the tasks that Google has to solve on its clusters. As a rule, something has to be considered for all documents on the Internet, and therefore the files in these tasks are very large.
Metadata
The wizard stores three important types of metadata: file namespaces and chunks, mapping the file to chunks, and the position of the chunk replicas. All metadata is stored in the wizard. Since the metadata is stored in memory, wizard operations are fast. The master learns the state of affairs in the system simply and efficiently. It is scanning the chank servers in the background. These periodic scans are used for garbage collection, additional replications, in the event of an unavailable chank server and moving chunks, for load balancing and free space on the hard drives of the chank servers.
Master tracks the position of the chunks. When starting the chank server, the master remembers its chunks. In the process, the master monitors all movements of the chunks and the state of the chank servers. Thus, it has all the information about the position of each chunk.
An important part of the metadata is the transaction log. The wizard stores a sequence of critical metadata changes. From these marks in the log of operations, the logical time of the system is determined. It is this logical time that determines the versions of files and chunks.
Since the operation log is an important part, it should be stored securely, and all changes in it should be visible to clients only when the metadata changes. The operation log is replicated to several remote machines, and the system responds to the client operation only after saving this log to the master disk and the disks of the remote machines.
The wizard restores the system status by executing a log of operations. The operation log saves a relatively small size, keeping only the last operations. In the process, the wizard creates checkpoints when the size of the log exceeds a certain value, and the system can only be restored to the nearest checkpoint. Further on the log, you can replay some operations, so the system can roll back to a point that is between the last checkpoint and the current time.
Interactions within the system
Above was described the architecture of the system that minimizes the master's intervention in the execution of operations. Now consider how the client, master, and chank servers interact to move data, perform atomic write operations, and create a backup (snapshot).
Each change to a chunk must be duplicated on all replicas and change metadata. In GFS, the master gives a chunk to one of the servers storing this chunk. Such a server is called a primary replica. The remaining replicas are declared secondary (secondary). The primary replica collects sequential changes to the chunk, and all replicas follow this sequence when these changes occur.
The mechanism of possession of the chunk is designed in such a way as to minimize the burden on the master. When allocating memory, it waits 60 seconds first. And then, if a primary replica is required, the master can be requested to extend this interval and, as a rule, receives a positive response. During this wait period, the wizard can undo the changes.
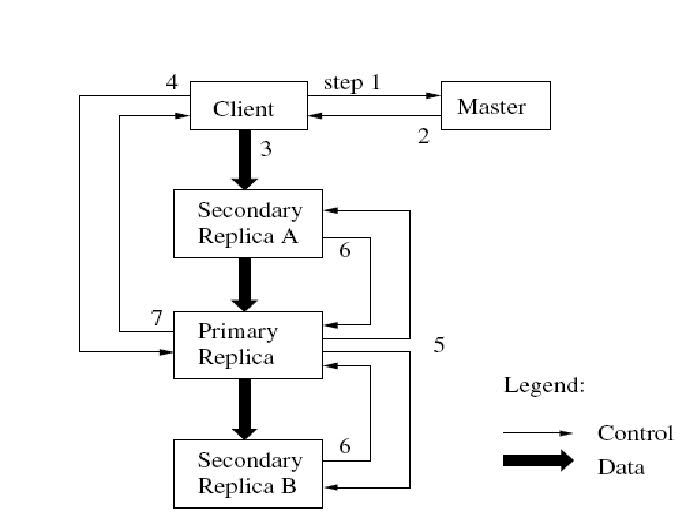
Consider in detail the process of recording data. It is shown in steps in the figure, with thin lines corresponding to control flows, and bold data flows.
This drawing is also taken from the original article.
- The client asks the master, which of the chank-servers owns the chunk, and where is this chunk located in other replicas. If necessary, the master gives the chunk to someone in possession.
- The master responds with the primary replica, and the rest (secondary) replicas. The client stores this data for further action. Now, communication with the master client may be needed only if the primary replica becomes inaccessible.
- Next, the client sends data to all replicas. He can do this in any order. Each chank server will store them in a special buffer until they are needed or become obsolete.
- When all replicas accept this data, the client sends a write request to the primary replica. This request contains the identification of the data that was sent in step 3. The primary replica now establishes the order in which all the changes it received should be performed, possibly from several clients in parallel. And then, performs these changes locally in that particular order.
- The primary replica forwards the write request to all secondary replicas. Each secondary replica performs these changes in the order determined by the primary replica.
- Secondary replicas report the success of these operations.
- The primary replica sends the response to the client. Any errors that occur in a replica are also sent to the client. If the error occurred while recording in the primary replica, then the recording in the secondary replica does not occur, otherwise the recording occurred in the primary replica, and a subset of the secondary. In this case, the client processes the error and decides what to do next with it.
From the example above, it is clear that the creators have separated the data flow and the control flow. If the control flow only goes to the primary replica, then the data flow goes to all replicas. This is done to avoid creating bottlenecks in the network, and instead make extensive use of the bandwidth of each machine. Also, in order to avoid bottlenecks and congested connections, the transmission scheme to the nearest neighbor in the network topology is used. Suppose that a client sends data to the chank-servers S1 , ..., S4 . The client sends data to the nearest server, let S1 . He further sends to the nearest server, let it be S2 . S2 then forwards them to the nearest S3 or S4 , and so on.
Also, the delay is minimized due to the use of TCP packet pipelining. That is, as soon as the chan-server received some part of the data, it immediately starts to send them. Without network congestion, the ideal time to send data with a volume of B bytes to R replicas is B / T + RL , where T is the network bandwidth and L is the delay in transferring one byte between two machines.
GFS supports such an operation as the atomic addition of data to a file. Usually, when writing some data to a file, we specify this data and offset. If several clients perform a similar operation, then these operations cannot be rearranged in places (this can lead to incorrect operation). If we just want to add data to the file, then in this case we specify only the data itself. GFS will add their atomic operation. Generally speaking, if the operation fails on one of the secondary replicas, then GFS will return an error, and the data will be different on different replicas.
Another interesting thing about GFS is backups (you can still tell a snapshot) of a file or directory tree that are created almost instantly, while almost without interrupting the operations in the system. It turns out at the expense of technology similar to copy on write . Users use this feature to create data branches or as an intermediate point, to start some experiments.
Master Operations
Master is an important link in the system. It manages chunk replications: makes decisions about placement, creates new chunks, and coordinates various activities within the system to keep chunks fully replicated, load balancing on chank servers and assembling unused resources.
Unlike most file systems, GFS does not store the contents of files in a directory. GFS logically represents a namespace, like a table that maps each path to metadata. Such a table can be effectively stored in memory in the form of a boron (a dictionary of these very paths). Each vertex in this tree (corresponds either to the absolute path to the file or to the directory) has the corresponding data for read-write lock (read write lock). Each operation of the master requires the establishment of some locks. At this point, the system uses read-write locks. Usually, if an operation works with /d1/d2/.../dn/leaf , then it sets read locks on / d1, / d1 / d2, ..., d1 / d2 /.../ dn and lock, either for reading or writing to d1 / d2 /.../ dn / leaf . Thus leaf can be both a directory, and a file.
Let us show by example how the blocking mechanism can prevent the creation of the file / home / user / foo during the backup of / home / user to / save / user . The backup operation establishes locks for reading on / home and / save , as well as locks for writing to / home / user and / save / user . The file creation operation requires a read lock on / home and / home / user , as well as a write lock on / home / user / foo . Thus, the second operation will not start until the first is completed, since there is a conflicting lock on / home / user . When creating a file, no write lock is required on the parent directory; a read lock is enough, which prevents the removal of this directory.
GFS clusters are highly distributed and layered. Usually, such a cluster has hundreds of chank servers located on different racks. These servers, generally speaking, are available for a large number of clients located in the same or a different rack. Connections between two machines from different racks can go through one or more switches. Multi-level distribution is a very difficult task of reliable, scalable and affordable data distribution.
The replica location policy tries to satisfy the following properties: maximizing data reliability and availability and maximizing the use of network bandwidth. Replicas must be located not only on different disks or different machines, but moreover on different racks. This ensures that the chunk is available even if the entire rack is damaged or disconnected from the network. With this arrangement, the reading takes time approximately equal to the network bandwidth, but the data flow during recording must pass through different racks.
When the wizard creates a chunk, he chooses where to place the replica. It comes from several factors:
- It is advisable to place a new replica on the chank server with the lowest average disk load. This will eventually equalize the load on the disks on different servers.
- It is desirable to limit the number of new chunks created on each chank server. Despite the fact that creating a chunk is in itself a quick operation, it implies the subsequent recording of data into this chunk, which is already a difficult operation, and this can lead to an imbalance in the amount of data traffic to different parts of the system.
- As stated above, it is desirable to distribute the chunks among the different racks.
As soon as the number of replicas falls below the value set by the user, the master replicates the chunk again. This can happen for several reasons: the chunk server became unavailable, one of the disks failed or the value that specifies the number of replicas was increased. Each chunk, which must be replicated, is given a priority, which also depends on several factors. First, the priority is higher for the chunk that has the smallest number of replicas. Secondly, in order to increase the reliability of application execution, the priority is increased for chunks that block the progress of the client’s work
The wizard selects the chunk with the highest priority and copies it, giving the instruction to one of the chunk servers to copy it from the available replica. New replica is based on the same reasons as when creating.
During operation, the master constantly balances replicas. Depending on the distribution of replicas in the system, it moves the replica to equalize the disk load and load balancing. Also, the master must decide which of the replicas should be removed. As a rule, a replica that is located on the chan-server with the least free hard disk space is deleted.
Another important feature of the wizard is garbage collection. When you delete a file, GFS does not require the immediate return of free disk space. It does this during regular garbage collection, which occurs at the chunk level as well as at the file level. The authors believe that this approach makes the system more simple and reliable.
When an application deletes a file, the wizard remembers this fact in logs, like many others. However, instead of requesting immediate restoration of freed resources, the file is simply renamed, with the time of the deletion added to the file name, and it becomes invisible to the user. And the wizard, during a regular scan of the file system namespace, actually deletes all such hidden files that were deleted by the user more than three days ago (this interval is configured). Until this point, the file continues to be in the system as hidden, and it can be read or renamed back for recovery. When a hidden file is deleted by the wizard, then information about it is also removed from the metadata, and all chunks of this file are unlinked.
In addition to the regular file namespace scan, the wizard does a similar scan of the chunk namespace. The wizard identifies the chunks that are disconnected from the file, removes them from the metadata, and during regular communications with the chank servers, sends them a signal that all the replicas containing the specified chank can be deleted. This approach to garbage collection has many advantages, with one drawback: if the place in the system ends and deferred removal increases the unused space, until the moment of physical removal. But there is the possibility of restoring deleted data, the possibility of flexible load balancing during deletion and the ability to restore the system in case of any failures.
Fault tolerance and error diagnostics
The authors of the system consider one of the most difficult problems frequent disruptions in the operation of the system components. The quantity and quality of the components make these failures not just an exception, but rather the norm. Component failure may be caused by the unavailability of this component or, worse, the presence of corrupted data. GFS supports the system in working form using two simple strategies: fast recovery and replication.
Fast recovery is, in fact, a reboot of the machine. At the same time, the launch time is very small, which leads to a small hitch, and then the work continues normally. About replication chunk already mentioned above. The wizard replicates the chunk if one of the replicas has become inaccessible or the data containing the chunk replica has become corrupted. Damaged chunks are determined by calculating checksums.
Another type of replication in the system, about which little has been said - is the replication of the wizard. The operation log and checkpoints are replicated. Each change of files in the system occurs only after the operations log is written to the disks by the master, and the disks of the machines to which the log is replicated. In case of minor problems, the wizard may reboot. In case of problems with a hard disk or other vital infrastructure of the wizard, GFS starts a new wizard, on one of the machines where the wizard data has been replicated. Clients contact the DNS wizard, which can be reassigned to a new machine. The new master is the shadow of the old, not an exact copy. Therefore, it has read-only access to files. That is, it does not become a full-fledged master, but only supports the operation log and other structures of the master.
An important part of the system is the ability to maintain data integrity. A regular GFS cluster consists of hundreds of machines with thousands of hard drives located on them, and these drives fail when working with an enviable constancy, which leads to data corruption. The system can recover data using replications, but for this it is necessary to understand whether the data has become corrupted. Simple comparison of different replicas on different chank-servers is inefficient. Moreover, there may be inconsistency of data between different replicas, leading to different data. Therefore, each chunk server must independently determine the integrity of the data.
Each chunk is divided into blocks of 64 KB in length. Each such block corresponds to a 32- bit checksum. Like other metadata, these amounts are stored in memory, regularly stored in the log, separately from user data.
Before reading the data, the chunk server checks the checksums of the chunk blocks that intersect with the requested data by the user or another chunk server. That is, the chank server does not distribute the corrupted data. If the checksums do not match, the chunk server returns an error to the machine that submitted the request and reports it to the master. The user can read data from another replica, and the wizard creates another copy from the data of another replica. After that, the wizard gives instructions to this chank server to delete this corrupted replica.
When adding new data, verification of checksums does not occur, and new checksums are recorded for blocks. If the disk is damaged, it will be determined when you try to read this data. - , , , .
Source: https://habr.com/ru/post/73673/
All Articles