The concept of data-driven processor

Hello, Habr!
All processor-equipped devices that we use are built on the principles of the von Neumann machine, or its modifications. A simple example: the x86 used by all of us is a hybrid of the von Neumann and Harvard architectures.
')
But does the habrasoobschestvo know about the existence (at least in the concept, plans, drawings, working samples) NOT the background of the Neumann machines?
I want to tell you about one conceptual direction in processor design, now abandoned (albeit quietly reviving), but in no way detracting from its importance and originality - about data-driven processor architecture.
This concept was developed in the 70s by monsters from MIT, and then picked up by other processors around the world.
So let's go!
Not according to von Neumann - what is it like? o_0
Vkradtse (who forgot), the key thesis architecture von Neumann :
- Commands are executed in order.
- Indistinguishability of commands from the data
- Memory addressability
And what will happen if you move away from all this? And there will be this:
- Commands are executed as operands become available.
- Is it even necessary? You can refuse both commands and data in the usual sense.
- Pointers - a terrible dream that must be forgotten ... as the influence of the phase of the moon.
Data driven approach
So, we abandoned the von Neumann model. But what will we offer in return?
The answer is simple - packaging. Yes, yes, almost like packets on the network, only on a smaller scale and much faster.
The package contains: an operation code (>, <, +, -, etc.), operands (or links to other packages giving these operands), and a readiness mark for each operand. There is no division into data and commands as such, the processor operates with ready-made "soup" sets of everything necessary.
Memory addressing as such is not, in principle, because everything is already ordered and sorted. Only package indices are known, nothing more is required to know.
Operands from one packet are processed, the result is sent to other packets and activates them. That is, in fact, the program collects itself, depending on the initial conditions and branching.
The development of this concept is a query-driven processor. This is the same thing, but the process is not top-down, but bottom-up, i.e. operations are performed only on demand from previous packages, which gives a performance gain due to a decrease in the number of operations.
(X + Y) * (XY):
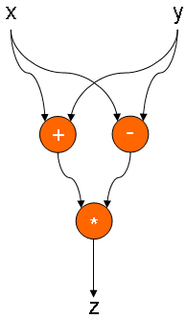
While X> 0 DO X-1:
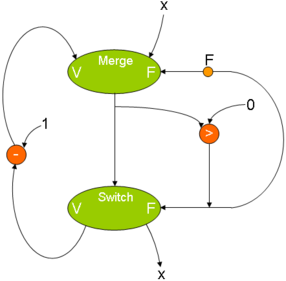
And the solution of the quadratic equation will look like this:
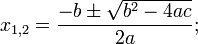
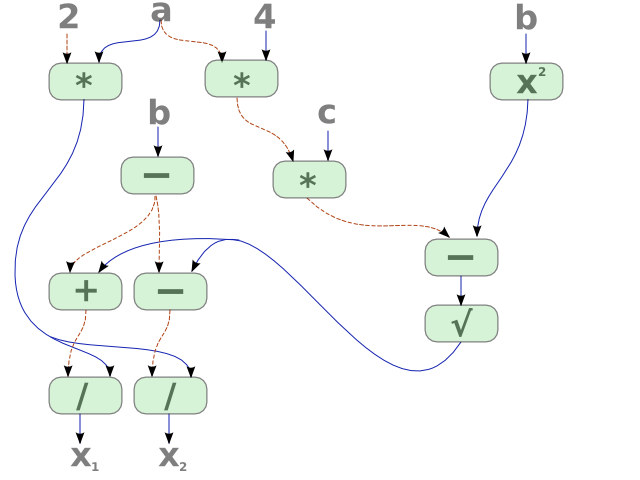
Benefits
- High efficiency in computations requiring parallelization. Forget about threads, the task is scattered across all possible processors and cores automatically, by splitting the task into blocks.
- Uniform load distribution between cores / processors, regardless of the algorithm.
- No problems with synchronization, because no threads.
- If some data is not needed for execution, it is not calculated - performance gain.
disadvantages
- Principal mono-task. Simulation of multitasking is possible, but only by tagging packets in memory.
- The consequence of point 1 is the exceptional rarity of such processors.
- As far as I know, not a single commercially viable sample was built.
- More complicated implementation compared to von Neumann machines.
Application: signal processing, network routing, graphic calculations. Recently, application in the field of databases has been considered.
Strange, but I have not found a single real example of the use of such processors even after several days of googling.
The processor that best fits this concept is the Japanese Oki Denki DDDP.
Source: https://habr.com/ru/post/70454/
All Articles