Generate music based on a given style
 | In this post I want to talk about a very simple way of generating music in a given style using context-dependent grammar. |
Introduction
We will work with files in MIDI format. Yes, habrayuzer, I sob with you, but it is in this format that the instruments, notes, and duration are already originally written in the melody. But from MP3 you will not get them any more (by a trivial method at least), and we would like to ...
But let's not despair, there are a lot of high-quality MIDI files on the Internet. I can recommend the HamieNET.com service. It allows you not only to download the MIDI file, but also to merge the melody converted into MP3 right away, as well as merge the XML file obtained from MIDI, display the tracks contained in the file, allow you to listen to them one by one, etc. There is also an online service for converting your MIDI to MP3. However, if you do not pay money, you can convert only one melody per day.
Demonstration of work
This is the original Nightwish melody - Ever Dream:
reference mirror
And this is what happened as a result of the algorithm:
reference mirror
This is just a restart of the program, without changing anything, the melody is slightly different:
reference mirror
')
In the first variant, of course, the jambs are sometimes heard, in the second one more and more smoothly.
Algorithm Description
The algorithm is based on constructing a context-dependent grammar based on the original melody, and then generating a new melody based on this grammar from a given initial sequence.
In order to create a melody, we need some rules: for example, which notes can go after the current sequence of notes. Plus, building a new melody based on an existing one is that we don’t have to invent these rules ourselves, but we simply take them for a given melody.
All these rules form a grammar. It is context-sensitive because both the left and the right parts of the rule can be surrounded by a context of terminal and non-terminal characters . Most likely now it is not clear what they are talking about at all and what terrible words these are. But let's consider an example and everything will immediately fall into place.
Take the usual line: ABCDEFGIKFHLEFJ. And we will begin to build a grammar for it, starting, say, with the symbol F (in general, this must be done for each character).
We need to write a rule that would indicate to us which letter should be put if we suddenly met the symbol F. It is written this way: F -> something . As we see, we cannot create such a rule, since we cannot determine just by one letter what should follow: after F, both G and H or J can go. Therefore, we add context to our letter F, context is characters surrounding F. Let's take one letter before F. We get EF and KF. The context for the letter F here is the letter E and K. We have just expanded the context by one character, so this method of constructing a grammar is called the method of dynamically expanding context.
See if we can create a rule now. After KF comes H, and there are no other options. We obtained the first final rule: KF -> H (reads “KF produces H). Now, if, for example, at the end of the line we meet KF and we need to extend the line by one character, we will boldly write H.
But we still have a problem: after EF, both G and J can go. Therefore, we must expand the context by another symbol: DEF and LEF. And finally we got the final rules:
KF -> H
DEF -> G
LEF -> J
These are the rules for the letter F, depending on its context, we choose one of the three rules.
The process of generating a new line is as follows: an initial sequence is given, for example, ADEF. We start to take letters from the end. F - there is no rule with such a left side, expanding the context - EF, again not, expanding - DEF, there is such a rule, we put G, we get ADEFG. We start all over again: take the letter G, etc. as many times as we need.
It will be convenient to represent the grammar as a tree. For the letter F, the tree will look like this:
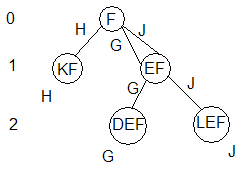
In the nodes are the left parts of the rules, next to the nodes are written the right parts of the rules - possible products. The numbers to the left of the tree indicate at which contextual level the nodes are located.
Now we are faced with the following problem: if we generate a new sequence strictly according to specified rules, then we will get exactly the original string (melody), and we want to create a new one . Therefore, in some cases, we should not reach the final rule, but take an intermediate one. This means that sometimes, having met such a sequence: ADEF, we will not expand the context to the final rule DEF -> G, but stop at F and randomly or use some other method to choose any product (H, G, J) at the node F in the tree. Or we’ll focus on EF and choose G or J products. Ie. we randomly select the context level in the tree and the output at that level.
Well, now imagine that each letter is not a letter, but a chord, but in relation to a MIDI file it would be more accurate to say that it is a set of events (which include turning on / off notes, changing channels, etc.), and here already our algorithm is ready for the melody.
More about MIDI
Having come across an online service that allows you to convert MIDI to XML, I realized that it would work much more conveniently with it. We also need to do one more thing. There are several MIDI file formats. Format 0 contains 1 track, formats 1 and 2 contain several tracks. Most often, MIDI comes in format 1, where each instrument has its own track: guitars on one track, violin on another, etc. This will add some difficulty in constructing grammar. You will need to follow what is happening on the other track. Therefore, we simply convert format 1 to format 0, so that all the tools are in a heap on one track, and after that we will also overtake in XML. All of these tools are available here .
In the end, we get something like this:
<? xml version ="1.0" encoding ="ISO-8859-1" ? > <br> <! DOCTYPE MIDIFile PUBLIC <br> "-//Recordare//DTD MusicXML 0.9 MIDI//EN" <br> "http://www.musicxml.org/dtds/midixml.dtd" > <br> < MIDIFile > <br> < Format > 0 </ Format > <br> < TrackCount > 1 </ TrackCount > <br> < TicksPerBeat > 384 </ TicksPerBeat > <br> < TimestampType > Absolute </ TimestampType > <br> < Track Number ="0" > <br> < Event > <br> < Absolute > 0 </ Absolute > <br> < ControlChange Channel ="2" Control ="91" Value ="46" /> <br> </ Event > <br> < Event > <br> < Absolute > 0 </ Absolute > <br> < ProgramChange Channel ="2" Number ="49" /> <br> </ Event > <br> < Event > <br> < Absolute > 0 </ Absolute > <br> < ControlChange Channel ="2" Control ="0" Value ="0" /> <br> </ Event > <br>...<br> < Event > <br> < Absolute > 24908 </ Absolute > <br> < NoteOff Channel ="11" Note ="41" Velocity ="127" /> <br> </ Event > <br> < Event > <br> < Absolute > 24912 </ Absolute > <br> < NoteOn Channel ="11" Note ="41" Velocity ="127" /> <br> </ Event > <br> < Event > <br> < Absolute > 24956 </ Absolute > <br> < NoteOff Channel ="11" Note ="41" Velocity ="127" /> <br> </ Event > <br> < Event > <br> < Absolute > 24960 </ Absolute > <br> < NoteOn Channel ="11" Note ="41" Velocity ="127" /> <br> </ Event > <br>...<br> </ Track > <br> </ MIDIFile > <br><br> * This source code was highlighted with Source Code Highlighter .Here we can see the tempo of the melody 384. Initially, the channel settings for each instrument are set, but we will be more interested in the NoteOn and NoteOff events - turning the note on and off. They contain the channel on which the note plays, the note number itself and its speed. We also see the absolute time for each event. You can generate XML with absolute and relative time. Absolute time is the time elapsed from the very beginning of the track, relative time elapsed since the last event. It is more convenient for us to take the absolute, because according to it, we can easily group events that occurred at the same time. I will call these groups “chords”.
shkodim
We describe the class "chord":
public class Chord<br> {<br> // "" <br> public int Delay { get ; set ; }<br> // <br> public List < string > Events { get ; set ; }<br><br> public Chord()<br> {<br> Events = new List < string >();<br> }<br> } <br><br> * This source code was highlighted with Source Code Highlighter .At the same time, we will write a class for comparing „chords“:
public class ChordComparer : IEqualityComparer<Chord><br> {<br> public bool Equals(Chord x, Chord y)<br> {<br> if (x.Delay != y.Delay)<br> return false ;<br> if (x.Events.Count != y.Events.Count)<br> return false ;<br> foreach ( var ev in x.Events)<br> if (!y.Events.Contains(ev))<br> return false ;<br> foreach ( var ev in y.Events)<br> if (!x.Events.Contains(ev))<br> return false ;<br> return true ;<br> }<br><br> public int GetHashCode(Chord obj)<br> {<br> int hash = obj.Delay.GetHashCode();<br> obj.Events.ForEach(ev => hash += ev.GetHashCode());<br> return hash;<br> }<br> } <br><br> * This source code was highlighted with Source Code Highlighter .And a class for comparing sequences of "chords":
public class ListComparer : IEqualityComparer< List <Chord>><br> {<br> private ChordComparer cc = new ChordComparer();<br><br> public bool Equals( List <Chord> x, List <Chord> y)<br> {<br> if (x.Count != y.Count)<br> return false ;<br> for ( int i = 0; i < x.Count; i++)<br> if (!cc.Equals(x[i], y[i]))<br> return false ;<br> return true ;<br> }<br><br> public int GetHashCode( List <Chord> obj)<br> {<br> int hash = 0;<br> obj.ForEach(ch => ch.Events.ForEach(ev => hash += ev.GetHashCode()));<br> obj.ForEach(ch => hash += ch.Delay.GetHashCode());<br> return hash;<br> }<br> } <br><br> * This source code was highlighted with Source Code Highlighter .Tree node class:
// , <br> public class Node<br> {<br> // - <br> public List <Chord> Value { get ; set ; }<br> // -, - , - , null <br> public List <KeyValuePair<Chord, Node>> Nodes { get ; set ; }<br><br> // <br> public Chord GetProduction( List <Chord> seq)<br> {<br> // , <br> if (Nodes.Count == 1 && Nodes[0].Value == null )<br> {<br> return Nodes.First().Key;<br> }<br> else <br> {<br> // <br> List <Node> path = new List <Node>();<br> ListComparer lc = new ListComparer();<br> path.Add( this );<br> // "", , <br> // <br> if (seq.Count == 1)<br> {<br> if (Nodes.Count != 0)<br> {<br> return Nodes[Helper.rand.Next(Nodes.Count)].Key;<br> }<br> // , , "", <br> // <br> else <br> {<br> int t = Helper.rand.Next(-10, 11);<br> int index = 0, i;<br> for (i = 0; i < Helper.listchords.Count; i++)<br> if ((index = Helper.listchords[i].IndexOf(seq.Last())) != -1) break ;<br> return Helper.listchords[i][ Math .Max(0, Math .Min(index + t, Helper.listchords[i].Count - 2))];<br> }<br> }<br> else <br> {<br> // <br> List <Chord> extseq = seq.GetRange(seq.Count - 2, 2);<br> // <br> List <Node> nodes = Nodes<br> .Where(node => node.Value != null && lc.Equals(node.Value.Value, extseq))<br> .Select(node => node.Value)<br> .Distinct()<br> .ToList();<br> // , "" <br> if (nodes.Count == 0)<br> {<br> if (Nodes.Count != 0)<br> {<br> return Nodes[Helper.rand.Next(Nodes.Count)].Key;<br> }<br> else <br> {<br> int t = Helper.rand.Next(-10, 11);<br> int index=0, i;<br> for (i = 0; i < Helper.listchords.Count; i++)<br> if ((index = Helper.listchords[i].IndexOf(seq.Last())) != -1) break ;<br> return Helper.listchords[i][ Math .Max(0, Math .Min(index + t, Helper.listchords[i].Count - 2))];<br> }<br> }<br> // <br> else <br> {<br> // <br> Node rule = nodes.First();<br> // , <br> rule.GetProduction(seq, ref path, 3);<br> // 60% <br> if (Helper.rand.NextDouble() <= 0.6)<br> {<br> return path.Last().Nodes[0].Key;<br> }<br> // , <br> // <br> else <br> {<br> Node p = path[Helper.rand.Next(path.Count)];<br> return p.Nodes[Helper.rand.Next(p.Nodes.Count)].Key;<br> }<br> }<br> }<br> }<br> }<br><br> // , c - <br> private void GetProduction( List <Chord> seq, ref List <Node> path, int c)<br> {<br> // <br> path.Add( this );<br> // , <br> }<br> } <br><br> * This source code was highlighted with Source Code Highlighter .The whole project can be merged here ( mirror ).
An important role here is played by how you organize random. At first I did a random with a Poisson distribution with a mathematical expectation equal to the number of the last node, but the melody was very messy, so I left a simpler option.
Post written after reading this article.
Source: https://habr.com/ru/post/69985/
All Articles