Text at any cost: PDF
We continue to parse text formats for text. So, the previously promised PDF.
With portable document format, everything is not as simple as DOCX or ODT, which we considered last time , but still it is still originally a text, not a binary format. Are you surprised? Then let's look at what's inside. Next really a lot of text.

')
As you can see, we have before us quite a “text” document, interspersed with binary data. Of course, it’s not possible to read a pdf book in a notebook, but it’s quite possible to understand what is written and what will later be displayed on the screen. I note in advance that the purpose of this article is not to describe the format of the data, so I’ll tell you essentially: “Where can I find the text?” For more information on the PDF format, see the links at the end of this short guide.
PDF supports several basic data types (to be exactly eight), some of which we need to work with are strings, arrays, dictionaries (distionaries), streams and objects (objects). Let us dwell on each.
Strings
PDF lines inherited from PostScript, as a result, a line in .pdf is a sequence of 8-bit characters surrounded by parentheses. String can be moved to the next line with a backslash, which is not part of the string and, among other things, escapes special characters:
As a result, the output will be two lines:
Because of its initial eight-bitness in PDF, there are several ways to insert text data, for example, in the same Unicode encoding. We can use the insert on octal character codes (
In the lines we will learn in the future to search for text data that contains a PDF-document.
Arrays
PDF arrays are enclosed in square brackets and are simply a sequence of grouped objects. For example:
Dictionaries
These are key-value pairs framed in << and >>. A dictionary is often used to endow an object that contains it with properties that are described in dictionary. To us, this data will help determine how, for example, to decrypt a stream, find out its length, or, conversely, discard the current object as uninteresting (if it is an image). Here is an example of a regular PDF dictionary:
After reading, my code will present it in the form:
The streams represent a sequence of eight-bit data between the
In streams, we will search for the text we want to get from a PDF document. An example of the stream you can find in the second half of the image, that at the beginning of this topic: yes, yes, those quackers - this is it .
Objects
Objects - this is the largest structure with which to work. An object can contain within itself any other data type from a regular number to a stream, framed by the keywords
Well, on this the introductory part of the internal presentation of the data is over, go to the "tasty" things - getting text from the stream, as well as getting dictionaries of internal character transformations (the implementation of which I have not seen before).
We formulate the problem: “Where to look for text objects in a PDF document?” Everything is simple and more than once and not two are described in various forums: we will look for objects that have threads. Usually meant, compressed gzip, streams, but the documentation tells us - then it may not be compressed at all or, conversely, there may be several compression (
Find in this document some object and begin to disassemble it. I’m getting a little bummed and take an object in which there is obviously textual data, but this is just for example - the script doesn’t have anything to work with:
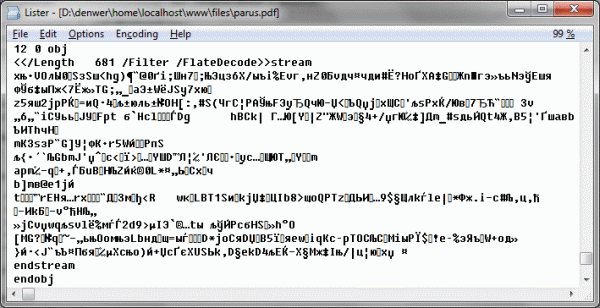
Let's first understand what is before us, using the previously obtained knowledge about the types of data PDF. Before us is an object with a dictionary of properties that say that the length of the data stream is 681 bytes (
Now let's take a little distraction from our example and find out a little more about the presentation of text in PDF. We just need to remember a few things:
The attentive reader, who has looked at the PDF of the example, may assume that we have the title ( SAIL ) and the first line of the poem ( The sail is lonely ). And he will be right, but! But you do not find that the hex texts are very strange in this text:
The previous example would have saved most of the functions of obtaining text from PDF, which you can find in the public domain on the Internet. Let's try to figure out what's what. So, we are interested in ToUnicode CMaps , which are described in the subsection on getting the text of the description of the PDF format from Adobe. Let's look for them in our file. I’m cheating again and offer the reader a “knowingly correct piece”:
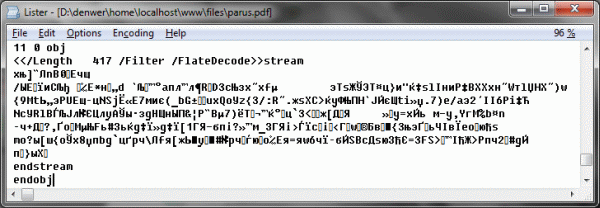
Decipher it:
Familiar numbers
bfchar
The conversion between
bfrange
There is another more complex conversion, framed by
Using our knowledge, we can read our "ill-fated" verse about the sail. Well time to present the most interesting pieces of code and a link to the full source:
Well, this code is not the crown of creation, it does not parse all the pdf-files offered to it. There are documents in which, for example, Russian fonts are implemented that transform from the characters of the English alphabet into a display of Russian letters.
This code does not work with individual character positioning. The task is feasible and not difficult, I place its decision on the shoulders of the reader.
This code is not ideal in terms of reading a PDF file according to its internal standards for presenting information: it does not search for pages, it will not work with versions of the document (PDF maintains a history of changes), it is even possible that it doesn’t ideally read the information it can process.
It's worth noting that nobody canceled
I hope you are interested in this article, the purpose of which is to acquaint the community with a PDF device, the ability to read it under PHP, and also to find starting points for obtaining data in difficult cases.
Depending on the activity and interest in the problem, I will either continue the story about PDF (document internal structure, positioning, fonts, internal links), or return to the topic “Text at any cost” using the example of RTF. Thanks for attention!
References:
With portable document format, everything is not as simple as DOCX or ODT, which we considered last time , but still it is still originally a text, not a binary format. Are you surprised? Then let's look at what's inside. Next really a lot of text.
')
As you can see, we have before us quite a “text” document, interspersed with binary data. Of course, it’s not possible to read a pdf book in a notebook, but it’s quite possible to understand what is written and what will later be displayed on the screen. I note in advance that the purpose of this article is not to describe the format of the data, so I’ll tell you essentially: “Where can I find the text?” For more information on the PDF format, see the links at the end of this short guide.
PDF data types
PDF supports several basic data types (to be exactly eight), some of which we need to work with are strings, arrays, dictionaries (distionaries), streams and objects (objects). Let us dwell on each.
Strings
PDF lines inherited from PostScript, as a result, a line in .pdf is a sequence of 8-bit characters surrounded by parentheses. String can be moved to the next line with a backslash, which is not part of the string and, among other things, escapes special characters:
(First line \ First line \ n Second line with brackets \ (\))
As a result, the output will be two lines:
First line First line Second line with brackets ()
Because of its initial eight-bitness in PDF, there are several ways to insert text data, for example, in the same Unicode encoding. We can use the insert on octal character codes (
\053 ), using a separate two-byte hex ( <2B> ) or even their sequence ( <54776F20> ). For example, the following lines are equivalent:(Two + two = four.) (Two \ 053 two \ 075 four.) (Two <2B> two <3D> four.) (<54776F202B2074776F203D20> four.)
In the lines we will learn in the future to search for text data that contains a PDF-document.
Arrays
PDF arrays are enclosed in square brackets and are simply a sequence of grouped objects. For example:
[(Hello,)10(world!)] . Arrays sometimes contain text strings.Dictionaries
These are key-value pairs framed in << and >>. A dictionary is often used to endow an object that contains it with properties that are described in dictionary. To us, this data will help determine how, for example, to decrypt a stream, find out its length, or, conversely, discard the current object as uninteresting (if it is an image). Here is an example of a regular PDF dictionary:
<< / Length 681 / Filter / FlateDecode >>
After reading, my code will present it in the form:
$ dictionary = array (Streams
"Length" => "681" ,
"Filter" => true
"FlateDecode" => true
) ;
The streams represent a sequence of eight-bit data between the
stream and endstream . Any binary data, be it compressed text, image, or embedded font, will be presented as a stream. The stream is always inside the object (just below) and is characterized, at a minimum, by its length (the /Length N option in the dictionary) and very often by the compression method (for example, /Filter /FlateDecode ). PDF supports a sufficient number of compression formats (including the encryption format /CryptDecode ), but we will be interested in only three: the most commonly used Flate (gzip-compression) and the rarer ASCII Hex (representing the data as a hexadecimal string with the final character > ) and ASCII 85-based (compression, when the successive 4 characters of the source text are encoded with 5 characters from ! to y in the ASCII table).In streams, we will search for the text we want to get from a PDF document. An example of the stream you can find in the second half of the image, that at the beginning of this topic: yes, yes, those quackers - this is it .
Objects
Objects - this is the largest structure with which to work. An object can contain within itself any other data type from a regular number to a stream, framed by the keywords
obj and endobj . The object has its ID inside the document by which it can be referenced. First of all, we are interested in objects with streams inside of us (do not forget about the main subtask), which almost always contain a set of additional options in the form of a dictionary. Here is a typical example of an object inside a PDF file (with uncompressed stream content):2 0 obj << / Length 9 2 R >> stream BT / F1 12 Tf 72 712 Td (A short text stream.) Tj ET endstream endobj
Well, on this the introductory part of the internal presentation of the data is over, go to the "tasty" things - getting text from the stream, as well as getting dictionaries of internal character transformations (the implementation of which I have not seen before).
Where to search for text?
We formulate the problem: “Where to look for text objects in a PDF document?” Everything is simple and more than once and not two are described in various forums: we will look for objects that have threads. Usually meant, compressed gzip, streams, but the documentation tells us - then it may not be compressed at all or, conversely, there may be several compression (
/Filter /FlateDecode /ASCIIHexDecode ). Well, we need some real example. Please, a poem by Mikhail Yuryevich Lermontov “Parus” in PDF-format (the document was created on Acrobat.com from the odt-file from the previous article).Find in this document some object and begin to disassemble it. I’m getting a little bummed and take an object in which there is obviously textual data, but this is just for example - the script doesn’t have anything to work with:
Let's first understand what is before us, using the previously obtained knowledge about the types of data PDF. Before us is an object with a dictionary of properties that say that the length of the data stream is 681 bytes (
/Length 681 ), that the stream is compressed ( /Filter ) in gzip ( /FlateDecode ). Already enough information to decompress the data stream - gzuncompress will gzuncompress :0.1 w q 0 -0.1 612.1 792.1 re W * n q 0 0 0 RG 0 0 0 rg BT 2 Tr 0.59999 w 56.8 716.6 Td / F1 18 Tf [<01> 17 <02> 10 <03> 10 <04> 17 <05>] TJ ET Q q 0 0 0 rg BT 56.8 682.5 Td / F1 11 Tf [<06> 9 <07> 11 <08> 6 <07> 11 <07> 11 <09> 13 <0A> 4 <0B> 14 <0C> 11 <0D> 11 <0E > 9 <0F> 9 <0A> 4 <10> 11 <11> 10 <12> 23 <13> 6 <10> 11 <14> 10 <10> 11 <15>] TJ ET ... a lot of text ...
Now let's take a little distraction from our example and find out a little more about the presentation of text in PDF. We just need to remember a few things:
- If the text is in the stream, it is contained between the “marker” of the beginning of the
BTtext (beginning of text) and the end ofET(end of text). - PDF may or may not display text, depending on the presence of a market Tj (display text) or a marker
TJ(display text taking into account individual character positioning). These markers appear after a line of text or an array of lines, as in this case ([<01>17<02>10<03>10<04>17<05>]TJ). - PDF supports individual positioning of characters, as I wrote above, which means that we can set an arbitrary and separate size of the distance between each pair of characters. More on this later
1. <01> 17 <02> 10 <03> 10 <04> 17 <05> 2. <06> 9 <07> 11 <08> 6 <07> 11 <07> 11 <09> 13 <0A> 4 <0B> 14 <0C> 11 <0D> 11 <0E> 9 <0F> 9 <0A> 4 <10> 11 <11> 10 <12> 23 <13> 6 <10> 11 <14> 10 <10> 11 <15>
The attentive reader, who has looked at the PDF of the example, may assume that we have the title ( SAIL ) and the first line of the poem ( The sail is lonely ). And he will be right, but! But you do not find that the hex texts are very strange in this text:
is encoded as01 02 03 04 05- like06 07 08 07 07 09...
Conversion table
The previous example would have saved most of the functions of obtaining text from PDF, which you can find in the public domain on the Internet. Let's try to figure out what's what. So, we are interested in ToUnicode CMaps , which are described in the subsection on getting the text of the description of the PDF format from Adobe. Let's look for them in our file. I’m cheating again and offer the reader a “knowingly correct piece”:
Decipher it:
/ CIDInit / ProcSet findresource begin 12 dict begin begincmap / CIDSystemInfo << / Registry (Adobe) / Ordering (UCS) / Supplement 0 >> def / CMapName / Adobe-Identity-UCS def / CMapType 2 def 1 begincodespacerange <00> endcodespacerange 45 beginbfchar <01> <041F> <02> <0410> <03> <0420> <04> <0423> <05> <0421> <06> <0411> <07> <0435> <08> <043B> <09> <0442> ... many lines of transformations ... endbfchar endcmap CMapName currentdict / CMap defineresource pop end end
Familiar numbers
<01> , <02> and so on? No wonder - we saw them a bit earlier in text lines. Suppose we have to replace 01 with 041F , take a look at what this number is hiding behind it. Hooray! #x041F = bfchar
The conversion between
beginbfchar and endbfchar is the simplest endbfchar . It assigns to the first code another one. For example, in the example above, we learned that 01 hides the code of the symbol bfrange
There is another more complex conversion, framed by
beginbfrange and endbfrange . It works no longer with individual characters, but with their ranges. Conversion supports two versions of its work:<0000> <005E> <0020>- we work with a range from 0000 to 005E, each value of which is converted into values from the interval 0020 and 007E. Noticed the principle? 0000 is converted to 0020, 0001 to 0021, 0002 to 0022, and so on;<005F> <0061> [<00660066> <00660069> <00660066006C>]- each value between 005F and 0061 (i.e., another 0060) is replaced with the corresponding array sequence in square brackets: 005F will be replaced with 0066 00 66 (i.e., onff), 0060 onfi, and 0061 onffl.
Algorithm and Code
Using our knowledge, we can read our "ill-fated" verse about the sail. Well time to present the most interesting pieces of code and a link to the full source:
You can get the code with comments on GitHub .
- function pdf2text ( $ filename ) {
- // Read the data from the pdf-file into a string, taking into account that the file may contain
- // binary streams.
- $ infile = @ file_get_contents ( $ filename , FILE_BINARY ) ;
- if ( empty ( $ infile ) )
- return "" ;
- // Pass the first. We need to get all the text data from the file.
- // In the 1st pass, we get only the "dirty" data, with positioning,
- // with hex inserts and so on.
- $ transformations = array ( ) ;
- $ texts = array ( ) ;
- // First we get a list of all the objects from the pdf-file.
- preg_match_all ( "#obj (. *) endobj # ismU" , $ infile , $ objects ) ;
- $ objects = @ $ objects [ 1 ] ;
- // Let's start bypassing what was found - in addition to the text, we can get caught
- // a lot of interesting and not always "tasty", for example, the same fonts.
- for ( $ i = 0 ; $ i < count ( $ objects ) ; $ i ++ ) {
- $ currentObject = $ objects [ $ i ] ;
- // Check if there is a data stream in the current object, it is almost always
- // compressed with gzip.
- if ( preg_match ( "#stream (. *) endstream # ismU" , $ currentObject , $ stream ) ) {
- $ stream = ltrim ( $ stream [ 1 ] ) ;
- // Read the parameters of this object, we are only interested in text
- // data, so we do minimal clipping to speed up
- // run
- $ options = getObjectOptions ( $ currentObject ) ;
- if ( ! ( empty ( $ options [ "Length1" ] ) && empty ( $ options [ "Type" ] ) && empty ( $ options [ "Subtype" ] ) ) )
- continue ;
- // So, we have a "possible" text, decrypt it from the binary
- // representation. After this action, we deal only with plain text.
- $ data = getDecodedStream ( $ stream , $ options ) ;
- if ( strlen ( $ data ) ) {
- // So, we need to find a text container in the current thread.
- // If successful, the found "dirty" text will go to the rest
- // found before
- if ( preg_match_all ( "#BT (. *) ET # ismU" , $ data , $ textContainers ) ) {
- $ textContainers = @ $ textContainers [ 1 ] ;
- getDirtyTexts ( $ texts , $ textContainers ) ;
- // Otherwise, we are trying to find character transformations,
- // which we will use in the second step.
- } else
- getCharTransformations ( $ transformations , $ data ) ;
- }
- }
- }
- // At the end of the initial parsing of the pdf document, we start the analysis of the received
- // text blocks with character transformations. At the end, we return
- // received result.
- return getTextUsingTransformations ( $ texts , $ transformations ) ;
- }
Conclusion
Well, this code is not the crown of creation, it does not parse all the pdf-files offered to it. There are documents in which, for example, Russian fonts are implemented that transform from the characters of the English alphabet into a display of Russian letters.
This code does not work with individual character positioning. The task is feasible and not difficult, I place its decision on the shoulders of the reader.
This code is not ideal in terms of reading a PDF file according to its internal standards for presenting information: it does not search for pages, it will not work with versions of the document (PDF maintains a history of changes), it is even possible that it doesn’t ideally read the information it can process.
It's worth noting that nobody canceled
$content = shell_exec('/usr/local/bin/pdftotext '.$filename.' -'); . But in this case, the task was to read PDF under any platform and on any platform.I hope you are interested in this article, the purpose of which is to acquaint the community with a PDF device, the ability to read it under PHP, and also to find starting points for obtaining data in difficult cases.
Depending on the activity and interest in the problem, I will either continue the story about PDF (document internal structure, positioning, fonts, internal links), or return to the topic “Text at any cost” using the example of RTF. Thanks for attention!
References:
Source: https://habr.com/ru/post/69568/
All Articles