Call price
It is believed that the overhead of calling methods and organizing the execution process should not exceed 15% of the execution time of an application, otherwise you should seriously think about the question of refactoring an application and optimizing its logic. Armed with such thoughts, I came across the
An interesting point here is the comparison of elements - in order to provide flexibility, it was carried out in a separate class that implements the
')
So, we have a standard implementation of Hoare's quick sort, which uses the
Since we will investigate exclusively the call to the operation of comparison, all changes to this function will be made only in lines 1, 12, 16, 53 and 61, which are marked in the listing with authentication comments.
To begin, let us estimate the contribution of the overhead of a call to the operation of comparing two numbers in the duration of the sorting process. To do this, in the above function, we change the “

What could so slow down the work? Obviously, the point is the excessive complexity of the comparison process (and this despite the fact that the operation itself boils down to subtracting two numbers!):
In this case, the first two points are the difference CIL-instruction
Well, the fourth item is caused by the standard implementation of comparer (all checks for
We will remove the layers one by one, let's start with a call to
Measurements show winning 15% of the time. And this is despite the fact that we consider an array of integers and calling
Due to the transfer of the actual type to the sort function, when expanding the generic parameters, the actual type of comparer will be taken into account and a more efficient
To the note: In the STL library from C ++ all predicates are transmitted in this way - the type goes through the template parameter. Additionally, thanks to this trick, the C ++ compiler obtains complete information about types and, as a rule, performs inlining of the predicate code, thereby completely eliminating the costs of a method call. My experiments with disassembling the results of .Net JIT showed that, contrary to all tricks, there is no unfolding here. Apparently this is either associated with generics, or it works exclusively for static methods.
Note # 2: It was not possible to save on the transfer of comparer with the help of an empty structure - the size (
If we consolidate the data into a single diagram, we obtain the following distribution of the sorting runtime by the standard method:
The obvious conclusion that is clear is that when developing computationally heavy biblicals, it makes sense to partly invoke predicates by passing structures and their type through generic parameters.
But our applications do not live together in numbers :) There was a question of influence in the context of working with arrays of objects, will we check? Easy! As a prototype take here such a simple class:
And we carry out similar simple experiments, but already with an array of objects, as a result we get a slightly different situation:

And if the ratio between the parts of the comparison process remained unchanged, then their contribution to the total time has noticeably decreased. It is quite a questioning question: what's the matter, what is slowing down? A quick glance at the code of the sort function is enough to understand: the work of the only different piece of code, the exchange of values between array elements, has slowed down. But we are working with the reference type, only the pointers are swapped, and they are “in the soul” of the number! If it’s interesting, then we’ll see that it slows down so much, reading CIL doesn’t give much benefit - the exchange code is asbestomatically identical except for using the
If CIL did not help, then it’s a matter of quitting the JIT, then we’ll watch the assembler :) Here we have a weekly nuisance - regardless of configuration (Debug / Release), the JIT compiler looks at its environment and, depending on the presence of a debugger attached to the process generates different code. Therefore, to access the real code through the Disassembly window, we will start the application without debugging and set breakpoints in the form of calls to
In the listings, one immediately catches the call of a certain function for writing to an array of objects, and this call was absent while we were watching CIL. Obviously, this function does something more than just copying the address, and in addition to the costs of organizing this call, we get something else, which means the details lie in the implementation of the CLR. Indeed, after reading the source code of the public version of CLR 2.0 (SSCLI 2.0 package), we find the following code:
As can be seen from here, when writing an element to an array of objects, in addition to the standard checking of array boundaries, type compatibility is also checked and, if necessary, the appropriate conversions are performed. It is worth noting that, being string-typed, C # itself also contains type control, but since the CIL instruction information already comes in the form
What conclusions can be drawn from this? I will not offer hardcore optimizations, but it makes sense to avoid virtual calls inside large cycles, especially in miniature predicate functions. In practice, for example:
Of course, these are not the only possible conclusions, but you have to leave the reader open space for thoughts :)
QuickSort method from the standard ArraySortHelper<T> class used to sort arrays in .Net.An interesting point here is the comparison of elements - in order to provide flexibility, it was carried out in a separate class that implements the
IComparer<T> interface. Armed with a variety of thoughts and the studio, it was decided to estimate how much such flexibility is and what could be done with it - under the cut, an analysis of the costs of comparing elements during QuickSort work.')
So, we have a standard implementation of Hoare's quick sort, which uses the
Compare(T x, T y) method from an object that implements the IComparer<T> interface to compare array elements. For our experiments, using a reflector, we get the code of the sorting method in the following form:Copy Source | Copy HTML
- static public void Sort <T, TValue> (T [] keys, TValue [] values, int left, int right, IComparer <T> comparer)
- {
- do
- {
- int index = left;
- int num2 = right;
- T y = keys [index + ((num2 - index) >> 1 )];
- do
- {
- try
- {
- / * Cmp 1 * / while (comparer.Compare (keys [index], y) < 0 )
- {
- index ++;
- }
- / * Cmp 2 * / while (comparer.Compare (y, keys [num2]) < 0 )
- {
- num2--;
- }
- }
- catch ( IndexOutOfRangeException )
- {
- throw new ArgumentException ( null , "keys" );
- }
- catch ( Exception )
- {
- throw new InvalidOperationException ();
- }
- if (index> num2)
- {
- break ;
- }
- if (index <num2)
- {
- T local2 = keys [index];
- keys [index] = keys [num2];
- keys [num2] = local2;
- if (values! = null )
- {
- TValue local3 = values [index];
- values [index] = values [num2];
- values [num2] = local3;
- }
- }
- index ++;
- num2--;
- }
- while (index <= num2);
- if ((num2 - left) <= (right - index))
- {
- if (left <num2)
- {
- / * Call 1 * / Sort <T, TValue> (keys, values, left, num2, comparer);
- }
- left = index;
- }
- else
- {
- if (index <right)
- {
- / * Call 2 * / Sort <T, TValue> (keys, values, index, right, comparer);
- }
- right = num2;
- }
- }
- while (left <right);
- }
Since we will investigate exclusively the call to the operation of comparison, all changes to this function will be made only in lines 1, 12, 16, 53 and 61, which are marked in the listing with authentication comments.
Part one. Experiments with arrays of numbers (int)
To begin, let us estimate the contribution of the overhead of a call to the operation of comparing two numbers in the duration of the sorting process. To do this, in the above function, we change the “
comparer.Compare(a, b) ” calls to an expression of the form “ a - b ”. We measure the operating time of both versions and see ... We see a terrible picture - almost two thirds of the time is spent on organizing a call to the comparison number predicate:What could so slow down the work? Obviously, the point is the excessive complexity of the comparison process (and this despite the fact that the operation itself boils down to subtracting two numbers!):
- Checking the
comparerobject fornull - Finding the
Comparemethod in the object's virtual table - Calling the
Comparemethod on thecomparerobject - Calling the
CompareToMethod - Actually a comparison of numbers
In this case, the first two points are the difference CIL-instruction
callvirt from call . I recall that callvirt , due to the presence of a check for null , is generated to call all non-static class methods, regardless of their virtuality.Well, the fourth item is caused by the standard implementation of comparer (all checks for
null naturally cleaned by the JIT compiler when substituting int instead of T ):Copy Source | Copy HTML
- class GenericComparer < T >: IComparer < T > where T : IComparable < T >
- {
- public int Compare ( T x, T y)
- {
- if (x! = null )
- {
- if (y! = null )
- {
- return x.CompareTo (y);
- }
- return 1 ;
- }
- if (y! = null )
- {
- return - 1 ;
- }
- return 0 ;
- }
- }
We will remove the layers one by one, let's start with a call to
CompareTo , since this is done simply by writing our own comparer of the following form:Copy Source | Copy HTML
- class IntComparer : IComparer < int >
- {
- public int Compare ( int x, int y)
- {
- return x - y;
- }
- }
Measurements show winning 15% of the time. And this is despite the fact that we consider an array of integers and calling
CompareTo for them, as for all methods for all structures, is non-virtual. The next layer, the difference between callvirt and call when calling, is harder to check, especially with the same flexibility requirements for the sorting function. But nothing is impossible - when working through an instance of a structure, all methods of all structures are invoked using the call operation, including the implementation of the methods inherited from interfaces. Due to this we can do the following optimization:Copy Source | Copy HTML
- static public void SortNoVirt <T, TValue, TCmp> (T [] keys, TValue [] values, int left, int right, TCmp comparer) where TCmp: IComparer <T>
- {
- // ...
- }
- struct IntComparerNoVirt : IComparer < int >
- {
- public int Compare ( int x, int y)
- {
- return x - y;
- }
- }
Due to the transfer of the actual type to the sort function, when expanding the generic parameters, the actual type of comparer will be taken into account and a more efficient
call instruction will be used to invoke the compare operation. Measurements of time show an increase in productivity of about 35% of the execution time of the “standard” call, while the increase from the subsequent replacement of the call Compare to subtract is 18%.To the note: In the STL library from C ++ all predicates are transmitted in this way - the type goes through the template parameter. Additionally, thanks to this trick, the C ++ compiler obtains complete information about types and, as a rule, performs inlining of the predicate code, thereby completely eliminating the costs of a method call. My experiments with disassembling the results of .Net JIT showed that, contrary to all tricks, there is no unfolding here. Apparently this is either associated with generics, or it works exclusively for static methods.
Note # 2: It was not possible to save on the transfer of comparer with the help of an empty structure - the size (
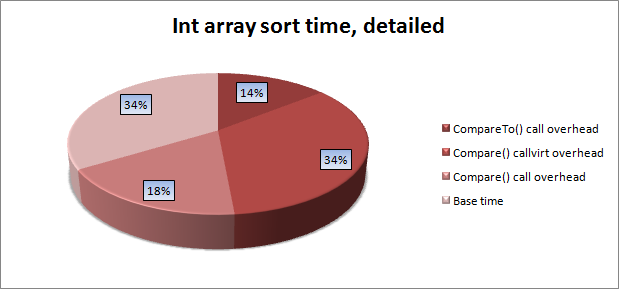
sizeof ) of the borderless structure in C # turned out to be one (and not zero, as desired). In VC ++, the size of the empty structure is also equal to one, while the standard states that the size of the empty class (structure) must be greater than zero. This is done because of the popular construction for calculating the length of the array " sizeof(array) / sizeof(array[0]) ". In C # /. Net, this is apparently done for binary compatibility when interacting with code written in C ++.If we consolidate the data into a single diagram, we obtain the following distribution of the sorting runtime by the standard method:
The obvious conclusion that is clear is that when developing computationally heavy biblicals, it makes sense to partly invoke predicates by passing structures and their type through generic parameters.
Part two. And what about objects?
But our applications do not live together in numbers :) There was a question of influence in the context of working with arrays of objects, will we check? Easy! As a prototype take here such a simple class:
Copy Source | Copy HTML
- class IntObj : IComparable < IntObj >
- {
- public int value ;
- public int CompareTo ( IntObj other)
- {
- return value - other. value ;
- }
- }
And we carry out similar simple experiments, but already with an array of objects, as a result we get a slightly different situation:
And if the ratio between the parts of the comparison process remained unchanged, then their contribution to the total time has noticeably decreased. It is quite a questioning question: what's the matter, what is slowing down? A quick glance at the code of the sort function is enough to understand: the work of the only different piece of code, the exchange of values between array elements, has slowed down. But we are working with the reference type, only the pointers are swapped, and they are “in the soul” of the number! If it’s interesting, then we’ll see that it slows down so much, reading CIL doesn’t give much benefit - the exchange code is asbestomatically identical except for using the
*.i4 instructions for numbers and *.ref for objects.If CIL did not help, then it’s a matter of quitting the JIT, then we’ll watch the assembler :) Here we have a weekly nuisance - regardless of configuration (Debug / Release), the JIT compiler looks at its environment and, depending on the presence of a debugger attached to the process generates different code. Therefore, to access the real code through the Disassembly window, we will start the application without debugging and set breakpoints in the form of calls to
Debugger.Break(); . The following are listings with the code that is generated to exchange places in two cells of the array:In the listings, one immediately catches the call of a certain function for writing to an array of objects, and this call was absent while we were watching CIL. Obviously, this function does something more than just copying the address, and in addition to the costs of organizing this call, we get something else, which means the details lie in the implementation of the CLR. Indeed, after reading the source code of the public version of CLR 2.0 (SSCLI 2.0 package), we find the following code:
Copy Source | Copy HTML
- / ************************************************* **************************** /
- / * assigns 'val to' array [idx], after doing all the proper checks * /
- HCIMPL3 ( void , JIT_Stelem_Ref_Portable, PtrArray * array, unsigned idx, Object * val)
- {
- if (! array)
- {
- FCThrowVoid (kNullReferenceException);
- }
- if (idx> = array-> GetNumComponents ())
- {
- FCThrowVoid (kIndexOutOfRangeException);
- }
- if (val)
- {
- MethodTable * valMT = val-> GetMethodTable ();
- TypeHandle arrayElemTH = array-> GetArrayElementTypeHandle ();
- if (arrayElemTH! = TypeHandle (valMT) && arrayElemTH! = TypeHandle (g_pObjectClass))
- {
- TypeHandle :: CastResult result = ObjIsInstanceOfNoGC (val, arrayElemTH);
- if (result! = TypeHandle :: CanCast)
- {
- HELPER_METHOD_FRAME_BEGIN_2 (val, array);
- // This is equivalent to ArrayStoreCheck (& val, & array);
- #ifdef STRESS_HEAP
- // Force a GC on every jit if the stress level is high enough
- if (g_pConfig-> GetGCStressLevel ()! = 0
- #ifdef _DEBUG
- &&! g_pConfig-> FastGCStressLevel ()
- #endif
- )
- GCHeap :: GetGCHeap () -> StressHeap ();
- #endif
- #if CHECK_APP_DOMAIN_LEAKS
- // If the instance is agile or check agile
- if (! arrayElemTH.IsAppDomainAgile () &&! arrayElemTH.IsCheckAppDomainAgile () && g_pConfig-> AppDomainLeaks ())
- {
- val-> AssignAppDomain (array-> GetAppDomain ());
- }
- #endif
- if (! ObjIsInstanceOf (val, arrayElemTH))
- {
- COMPlusThrow (kArrayTypeMismatchException);
- }
- HELPER_METHOD_FRAME_END ();
- }
- }
- // The performance gain of the optimized JIT_Stelem_Ref in
- // jitinterfacex86.cpp is mainly due to calling JIT_WriteBarrierReg_Buf.
- // By calling write barrier directly here,
- // we can avoid translating in-line assembly from MSVC to gcc
- // while keeping most of the performance gain.
- HCCALL2 (JIT_WriteBarrier, ( Object **) & array-> m_Array [idx], val);
- }
- else
- {
- // no need to go through write-barrier for NULL
- ClearObjectReference (& array-> m_Array [idx]);
- }
- }
- HCIMPLEND
As can be seen from here, when writing an element to an array of objects, in addition to the standard checking of array boundaries, type compatibility is also checked and, if necessary, the appropriate conversions are performed. It is worth noting that, being string-typed, C # itself also contains type control, but since the CIL instruction information already comes in the form
System.Object , the CLR checks for reliability once again.Part Three Similarity of conclusions
What conclusions can be drawn from this? I will not offer hardcore optimizations, but it makes sense to avoid virtual calls inside large cycles, especially in miniature predicate functions. In practice, for example:
- Realization of predicates in the form of structures, and not classes with the subsequent transfer of type information through generic parameters
- replacement of small utilitarian class methods with static extension methods, which, due to their static nature, will be called to bypass the virtual table
Of course, these are not the only possible conclusions, but you have to leave the reader open space for thoughts :)
Source: https://habr.com/ru/post/69520/
All Articles