Regular expression quantifiers
 Regular expressions are arithmetic for algorithms. They are available in many programming languages, editors, and application settings. Like adding with multiplication, they are easy to use.
Regular expressions are arithmetic for algorithms. They are available in many programming languages, editors, and application settings. Like adding with multiplication, they are easy to use.But for the proper and effective use of regexp-s, you need an understanding of how they work. I will try to describe the principle of operation of regular expressions, show in what cases there are problems and how to solve them.
In continuation of general advice .
I do not want to write a banal description of metacharacters or some kind of reference book. I want to show those rakes that I remember. To map their path to self-expression through regular structures. And try to convey a certain way of thinking that naturally generates effective regexps.
I repeat, but you can only learn from your own experience. Therefore, if you have not written at least a dozen, it is better to have hundreds of regexps, I think that it is worth while just reading the documentation or books and experimenting.
')
For distinction and convenience, I have somewhat colored the regular expressions found in the text. Blue - symbols, green - quantifiers, gray - brackets and other service symbols, chestnut - metacharacters, red - a point (so as not to be lost) and slashes that restrict the regular expression.
A bit of theory
I will not be a formalist and will try to describe the theoretical basis in simple words. Those interested can find the exact wiki language.
Regular expressions, in addition to the alphabet, have three properties:
coupling, when two expressions a and b can concatenate to form an expression ab
In other words, the expression a is first executed, then, on the remaining line, the expression b. We can say that between them as conditions, logical I.
In the application, this gives us a very simple and basic method: we divide the search string into consecutive parts and for each we build our expression, and then we “link” - we simply write them in a row.alternation, when two expressions a and b can, using the operator | form the expression a | b
The difference with coupling is that between conditions a and b there is a logical OR, and the same string is used for testing.
In the application, this allows us to easily add simple branches to the finished expression.closure, when for the expression a * all variants are checked (empty), a, aa, aaa, ... and so on
In other words, we recursively try to apply the expression a, while it is applied. In reality, the parser does just that and it causes performance problems, but this is discussed below, when, in fact, we will consider the work of quantifiers.
Fine! But it is easy to make an expression that matches the template we need. It is more difficult to modify it so that it would not coincide with the fact that we do not need .
In this place the mentoring description should end with the words: Efficiency will come to you in time, young Padawan ...
Nothing like this !
It is said that regular expressions appeared as the embodiment of the nervous system. I do not know how true this is, but it is easy enough to learn how to think with regular expressions. The key to this is hierarchy. Imagine not just variants of the lines to be found, but a structure consisting of smaller elements. And then the regular season is just a description of this structure.
First you need to talk about the characters. A character is a kind of minimal component of our structure, but a bare text consisting of literal characters must be distinguished and, for example, a string in some programming language: let the string be limited to quotes and escape using the special character is used to indicate the quotes inside the string or repetition. Also, usually, it is possible to specify non-printing characters - line feed or tabulation. All this extends literal characters to the character of a string. And if it is necessary to disassemble a string, first of all it is necessary to climb this step - it is necessary to describe the characters of our alphabet.
Let us have the escape character - "\". Then the characters in the string are an alternation of ordinary characters "." and screened "\.". Here it must be said that in the alternation of expression are not equal, but have priority in the order of succession. That is, if we write . | \. , then the point, like any character will always be, therefore we put it last: \. | . . Having closed all this with the help of the quantifier * and concatenated with a quotation mark at the beginning and at the end, we get an expression to describe the string. But there is another underwater stone - a point in the symbol sub-expression. Although, given the priorities, the point is the last, the parser each time, seeing the options, put the so-called return points. To which can return if the subsequent expression fails. In some text, quotes can be unpaired and, not finding the last one, the parser will unscrew the expression backward at the return points. If we encounter a screened quote, then the parser will break it down into two characters and, satisfied with this incorrect result, will continue to work. From this we can draw a simple conclusion, true for all regulars, - the uncertainty should be eliminated . In our case, it is simple - instead of a point, we put the character class [ ^ \ " ] , removing all ambiguities.
Do not forget that in the line that you give to the compiler or interpreter, some characters must also be escaped, so in the text of the program it will look like
/ " ( \\ . | [ ^ \\ " ] ) * " /Make up the expression
Understanding and describing the characters, you can climb the hierarchy above, using a clutch or a closure and, if necessary, alternation.
For example, to describe a URL, we must first break it apart: protocol, sometimes user and password, server name, file path, and so on. After that, you need to divide the parts into elementary pieces, for example, the server name is the words, separated by a dot, while these words have their own allowed characters and the rightmost should be tld. For each elementary part, you need to carefully write your alphabet of symbols and concatenate them into the expression for the structure of the next level.
For example, the name consists of [ - a - z0 - 9 ] + , separated by the point [ - a - z0 - 9 ] + \. [ a - z ] {2,4} (in a more stringent case, the allowed tlds can be described on the right side: c o m | n e t | o r g | r u | i n f o ), while on the left side be several levels of names through the point ( [ - a - z0 - 9 ] + \. ) + [ a - z ] {2,4}
Protocol can be h t t p s ? : / / or f t p : / / , followed by the name \ w + and password . +?
together
/ ( h t t p s ? : \/ \/ | f t p : \/ \/ ( \w + ( : . +? ) ? @ ) ? ) ( [ - a - z0 - 9 ] + \. ) + [ a - z ] {2,4} /in general, it is easy to describe the formal structures, since all the work has already been done before us, clearly specifying the fields, separators, and providing for variability. The main thing is not to be mistaken with the necessary symbol :)
I want to repeat the visiting truth - premature optimization is harmful . Do not be lazy and repeat the block alternating, if you need a slightly different option. Optional or duplicate parts must have “anchors” - literal characters at the beginning or at the end. If you add something - do not be lazy - disassemble the structure again, add the necessary and collect back. An incomprehensible jumble inside an expression is the right path to error. Check both for coverage and for ignoring unnecessary options. And only then optimize. And the best is not necessary - the expression is well structured and works quickly, although sometimes it looks scary and seemingly confusing.
Greedy quantifiers
There are several types of closures in modern regular expressions. Stephen Cole Kleene , who introduced this concept, described two such: * and +. As described above, their behavior is “greedy” - they are trying to cover all that is possible - to the end of the line. But further in our expression is the next statement or symbol, and we are already at the end of the line. Here the parser unscrews our quantifier back to the return points, until the condition of the subsequent subexpression is met.
Obviously, this behavior easily causes performance problems. Here are the lead times for several options:
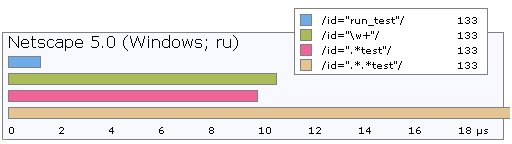
The last case with two asterisks actually works an order of magnitude slower. This is due to the feature of the parser. As it was said, the expression “any character many times” is performed verbatim and in fact the parser first covers the entire line with this expression, keeping a return point on each character. Having seen that our expression is not finished, the parser returns back until it finds a match. The presence of two asterisks increases the number of cusps by an order of magnitude, and three more by an order of magnitude. It is easy to see that such a path can make “simple expression” noticeably slow.
but there are several ways to improve efficiency:
spacing with stop symbol
For example, if we are looking for tags from '<' to '>', then we can specify an interval instead of an arbitrary character:
The parser will stop when it sees a character out of range and the subsequent literal character '>' will immediately work./ < [ ^ > ] + > /use repetition interval {min, max}
It works well if we know how many characters there should be, for example during the initial verification of a uid or md5 signatures.
Non-greedy or lazy quantifiers
At one time, Perl introduced this concept. Such a quantifier acts the other way around - it covers the minimum set of characters and expands it if subsequent concatenated expressions are not executed.
From a performance point of view, it works very well for nested optional expressions, but also like a greedy quantifier can cause a significant slowdown, because if in a good case (when our expression is executed) more or less quickly, in a bad case the parser tries to increase coverage for the non-greedy quantifier until it comes to an obvious end. In order to avoid this, it is advisable to narrow down the covered symbols as much as possible at intervals and immediately after it put a simple expression - fixed symbols, for example.
As I said, expressions with lazy quantifiers cover the smallest possible substring. This allows you to simply avoid problems with excessive coverage, for example
/ \( . + \) // \( . +? \) /Why not a stop symbol? Because it is not always possible to apply. The next character can be complex or be part of a subexpression with a list or it is not possible to clearly define the border at all. Also a lazy quantifier is effective if we know that there will be few characters. I highly recommend putting lazy + and * after a point that matches an arbitrary character, otherwise the parser will walk to the end of the line. But remember that the parser must specify where to stay.
Compare the speed:
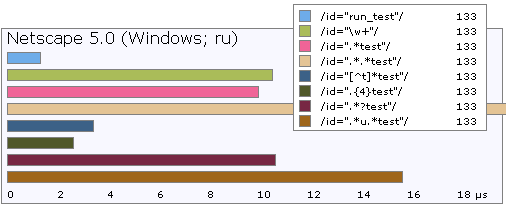
Lazy "asterisks" and "pluses" have another drawback - they can and very often cover too few characters, unless the border is marked with a subsequent subexpression. For example, if you make out words like this:
\w +? you may find that without a subsequent literal character (at the end of a large expression), this combination will cover only one letter and in this case the greedy option is more effective. Also greedy is more effective if it is clearly known that the next character will be another \ w + so you can describe a word or parameter, lazy here is just less effective.In addition to the lazy and greedy there are still
super greedy or jealous quantifiers
Their significant difference is that they do not roll back. This property can be used if there is ambiguity. True, again, ambiguity is the enemy of an effective regular expression. I personally did not use them, although I have the opinion that you can safely put a jealous one in good expression instead of a greedy one. A good, though not very vital example of applying a jealous quantifier is described in detail here .
Finally
I will show a few bad cases from the code:
( \ w * ) * - the external greedy asterisk will simply not work.
The most remarkable thing is that some parsers simply ignore such an expression - the loop protection will work.
( [ ^ > ] + ) * - almost the same.
According to the meaning, these are the insides of the tag after its name and they are not mandatory. So + change to * and just remove the external
. * ; ? . *? \ r ? - After the greedy * there are a number of optional characters.
They will never matter, because the optional expressions for the parser are no reason to return and reduce the coverage of the greedy quantifier. Most likely a victim of change. After the first star, the rest can be simply removed.
\. ( [ a - z \. ] {2,6} ) - separator inside the structure.
Just saying that it will cover for example a few points instead of tld, as intended.
In continuation
- metacharacters \ s \ d \ w \ b and unicode
- subtleties multiline
- positioning and preview
- ... and other
Source: https://habr.com/ru/post/68345/
All Articles