My unified bug theory

This translation is a continuation of a series of articles about testing:
The next step is practical advice on building a testable code and examples of the application of the described knowledge on real projects.
PS Special thanks to taxigy for proofreading the Russian translation.
I think that bugs can be divided into three basic categories:
- Logical . Logical bugs are the most popular and common. These are your ifs, loops, and other similar logic in the code. (Thoughts: it works wrong).
- Interaction bugs . Interaction bug - when two different objects interact incorrectly with each other. For example, the output of one object is not what the next object in the chain expects. (Thoughts: the data to the destination came spoiled).
- Display bugs Display bug - when output (usually some user interface, UI) is displayed incorrectly. The key point is that this person determines what is right and what is not. (Thoughts: it "looks" wrong)
WARNING: Some developers believe that when they build the user interface, all the bugs are display bugs! Display bugs are errors that are similar to the error of a text leaving the button border. But the case when you click on a button and the wrong things happen is more likely due to interaction errors (interaction bugs), or something is wrong in logic (logical bugs). Display bugs are very rare.
Typical distribution of bug types in the program
The first thing I noticed with the three types of bugs is that the probability of meeting each of them is uneven. In addition to probability, the complexity of finding and correcting them in the code is also different (I am sure that you also remember this from your own experience). My experience in building web applications suggests that logical bugs are most common, followed by binding bugs, and at the end - display bugs.
')
Bug Detection Difficulty
Logical bugs are the hardest to detect. One of the reasons is that they appear only under certain input conditions, and the search for these mysterious sets or their reproduction is accompanied by a high voltage of convolutions. Binding bugs are easier to detect because they are easily reproducible under most independent input conditions. And you can just see the display bugs with your own eyes and quickly show what looks wrong.
Bug fixes
Practical experience can show us how difficult it is to correct mistakes. The logical bug is quite difficult to fix, because to find a solution you must understand all the ways to execute the code. After making the changes, we must also be sure that the corrections will not break the existing functionality. Binding problems are easier because they manifest themselves with the help of an option or the wrong location of the data. The display bugs themselves clearly show what went wrong, and you immediately know how to fix it. We initially design our program, given the frequent changes to the user interface, and therefore it is easier for us to make such edits.
| brain teaser | Binding | Mappings | |
|---|---|---|---|
| Probability of occurrence | High | Average | Low |
| Detection difficulty | Complicated | Easy | Trivially |
| Difficulty fix | High | Average | Low |
How does testability change the distribution of bug types?
So it turns out that writing a testable code affects the distribution of bug types in a program. For testability, the code should:
- Have a clear division of class responsibility. This reduces the likelihood of binding bugs. In addition, a smaller amount of code per class leads to a smaller number of logical bugs.
- Use dependency injection (dependency injection) - this makes the binding explicit, as opposed to singles (global), global objects or service locators.
- To contain an explicit separation of logic and binding - binding is easier to test if logic is not mixed in it.
Following these rules leads to a significant reduction in binding errors. As a percentage, the number of logical bugs increased, but the total number of all bugs decreased.
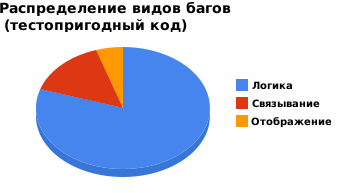
It is interesting to note that you can benefit from the testable code without writing a single line of the tests themselves. Similar code is the best code! (When I hear people sacrificing "good code" for the sake of testability, I understand that they are completely unaware of what a testable code really is)
We love writing unit tests.
Unit tests give us a very powerful weapon. These tests are designed to detect the most common bugs that are difficult to detect and fix. Unit tests also contribute to the writing of testable code that implicitly helps with binding bugs. As a result, when writing automatic tests, we should mostly concentrate on unit tests. Each such test focuses only on the logic of one class / method.
Unit tests focus on logical bugs. They check your i'y and cycles, but do not check binding directly (and of course, do not check the mapping)
Unit tests focus on CPT (class-under-test, CUT, class-under-test). This is important because you need to be sure that these tests will not stand in the way of future refactoring. Unit tests should HELP refactoring, and not to interfere with it. (I repeat: when I hear someone say that tests interfere with refactoring, I suppose that this person does not understand what a unit test is).
Unit tests do not directly say that everything is OK with binding. They do it implicitly, by forcing you to write testable code.
Functional tests test connectivity, but that’s not all. You can refactor for a long time if you have a lot of functional tests OR if you mix functional and logical tests.
Bug Management
I like to think about testing as bug management (to get rid of them). Not all types of errors are the same, so I choose the tests on which to concentrate. I realized that I love the unit tests. But they must be well focused! If the test checks many classes in one pass, then I can be happy with a good test coverage, but in fact after that it is difficult to find the place that lit the “red” test. This can also make refactoring difficult. I try to make my life easier with functional testing: one test is enough for me, which proves the correctness of the binding.
I hear how many people claim that they write unit tests, but on closer examination it turns out to be a mixture of functional (binding test) and modular (logic) tests. This happens when tests are written after the code is written, and because of this it turns out to be non-testable. Non-valid code leads to the appearance of mokers (from the English. "Mock" - stub) - this is a test that requires a lot of stubs, and these stubs, in turn, use other stubs. Using tests with mokery, you will be little sure of what. Such tests work at a too high level of abstraction, in order to assert something at the method level. These tests are deeply tied to the implementation (this is evident from the presence of a large number of connections between the stubs), so that any refactoring will be very painful.
---------------------------
translated.by/you/my-unified-theory-of-bugs/into-ru/trans
(): My Unified Theory of Bugs (http://misko.hevery.com/2008/11/17/unified-theory-of-bugs/)
: © Alexander MAZUROV, taxigy
translated.by
Source: https://habr.com/ru/post/65062/
All Articles