Chrome linker. We create analog Linkification for Google Chrome
It describes the creation of the first version. You can read about the latest version here .
I recently switched from firefox to google chrome due to its lightness and minimalism. However, there was a great lack of many goodies of firefox extensions. For example, Linkification, an addon that converts text URLs into literal links, I often need, and it is not sweet without it.
')
As you know, a week ago, the first version of Google Chrome (dev) was released, which supports extensions. And, despite the fact that the API has not yet been completed and is very buggy, I decided to quickly blind an extension that would implement Linkification'a functionality.
The following is a description of the process of creating an extension and a link to the result.
As far as I found out, extensions in Google Chrome are:
1. manifest.json - required file describing the extension and links to other files.
2. toolstrip - html files describing the buttons that appear at the bottom of chrome.
3. content-scripts - javascript files that manage the content of web pages.
4. any other files you want to use, such as pictures, HTML pages for pop-up windows, etc.
At first I had in my thoughts to make a button and a content-script, and that this content-script would be controlled by this button. Unfortunately, communication between contentstripami and content scripts is still buggy now. I did not succeed, so it will be in the next version when the normal API comes out. So, this version without the button and the topic of communication with the streamstresses with content scripts, I will not touch on it for now.
This version of the extension consists of 2 files, this is a manifest file and a javascript content script, which, when the page loads, takes all the text on it and replaces text links with literal ones.
The manifest file looks like this:
In addition to an uninteresting description, name, and version, there is
Here is described which js file to load, as well as matches for addresses. I wrote 3, file, http, and https, you may need to add. By the way, you can not write "*", swears.
The second file is javascript, which changes all text links to real ones. I stole it from userjs.org, and it looks like this:
I removed all sorts of window.body.onload from there because the content scripts are executed after the document is loaded.
To check how everything works, in the shortcut settings for chrome you need to add the path --load-extension = "C: \ Users \ Alex \ Desktop \ chrome-linker" where the last, of course, is the path to the file folder. When restarting, chrome loaded the extension, and going to a typical site with links highlighted all rapidsharnye links. Hooray. It remains to collect the extension in a crx file and put it free.
This process is very simply described here. You need to download Python 2.6 , download the build script from here and execute:
Done, the file chrome-linker.crx appeared in my download folder. You can download it from my homepage: here it is!
After installation, go to chrome: // extensions / . You should see something like the following:
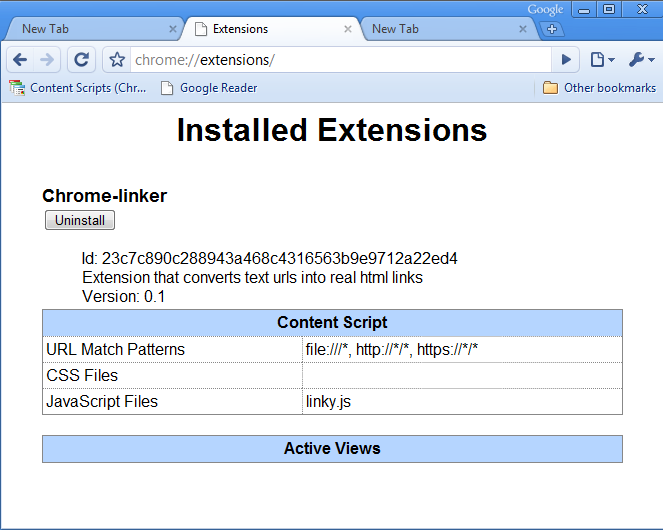
Hooray! Now all URLs will be links.
UPD 1. ID in the manifest does not need to be specified, it is generated by the build script, I apologize for the misinformation.
, UPD 2. Most likely, communication with content scripts was buggy for me because of my curvature. The subscript extension from google works fine, using communication between toolstripami and content scripts. So I will soon make a new version and describe it in a new post.
P.S. 1. When the API comes out, I will make a new version with normal interfaces, unless of course someone wants.
P.S. 2. In the case, write to komenty, about typos in a personal, that I am a terrible writer, and so I know.
I recently switched from firefox to google chrome due to its lightness and minimalism. However, there was a great lack of many goodies of firefox extensions. For example, Linkification, an addon that converts text URLs into literal links, I often need, and it is not sweet without it.
')
As you know, a week ago, the first version of Google Chrome (dev) was released, which supports extensions. And, despite the fact that the API has not yet been completed and is very buggy, I decided to quickly blind an extension that would implement Linkification'a functionality.
The following is a description of the process of creating an extension and a link to the result.
As far as I found out, extensions in Google Chrome are:
1. manifest.json - required file describing the extension and links to other files.
2. toolstrip - html files describing the buttons that appear at the bottom of chrome.
3. content-scripts - javascript files that manage the content of web pages.
4. any other files you want to use, such as pictures, HTML pages for pop-up windows, etc.
At first I had in my thoughts to make a button and a content-script, and that this content-script would be controlled by this button. Unfortunately, communication between contentstripami and content scripts is still buggy now. I did not succeed, so it will be in the next version when the normal API comes out. So, this version without the button and the topic of communication with the streamstresses with content scripts, I will not touch on it for now.
This version of the extension consists of 2 files, this is a manifest file and a javascript content script, which, when the page loads, takes all the text on it and replaces text links with literal ones.
The manifest file looks like this:
{
"content_scripts": [
{
"js": [
"linky.js"
],
"matches": [
"",
"http://*/*",
"https://*/*"
]
}
],
"description": "Extension that converts text urls into real html links",
"name": "Chrome-linker",
"version": "0.1"
}
In addition to an uninteresting description, name, and version, there is
"content_scripts": [
{
"js": [
"linky.js"
],
"matches": [
"file:///*",
"http://*/*",
"https://*/*"
]
}
],
Here is described which js file to load, as well as matches for addresses. I wrote 3, file, http, and https, you may need to add. By the way, you can not write "*", swears.
The second file is javascript, which changes all text links to real ones. I stole it from userjs.org, and it looks like this:
var urlRegex = /\b(((https?|ftp|irc|file|s?news):\/\/|(mailto|s?news):)[^\s\"<>\{\}\'\(\)]*)/g;
//^^^Medium version
//var urlRegex = /\b(((https?):\/\/)[^\s\"<>\{\}\'\(\)]*)/g;
//^^^Small version
//Set this to a class name if you want it to use a style from a stylesheet.
var linkClass='';
var preCreatedA=null;
var elms = document.evaluate('//body//text()[not(ancestor::a)][not(ancestor::script)][not(ancestor::style)]', document, null, XPathResult.UNORDERED_NODE_SNAPSHOT_TYPE, null);
for (var i = 0, elm; elm = elms.snapshotItem(i); i++) {
linkifyNode(elm,document);
}
function linkifyNode(node,mydoc){
var i,tmpData,foundPos,matchedText,middleText,endText,v;
var newLinkElement,linkTextNode,skip=0;
if(node){
if (node.data){
tmpData=node.data;
foundPos=tmpData.search(urlRegex);
if (foundPos>=0){
matchedText=RegExp.$1;
middleText=node.splitText(foundPos);
middleText.deleteData(0,matchedText.length);
if (preCreatedA){
newLinkElement=preCreatedA.cloneNode(false);
} else{
newLinkElement=mydoc.createElement('a');
newLinkElement.setAttribute('target','_blank');
if (linkClass!=''){
newLinkElement.setAttribute('class',linkClass);
}
preCreatedA=newLinkElement.cloneNode(false);
}
newLinkElement.setAttribute('href',matchedText);
linkTextNode=mydoc.createTextNode(matchedText);
newLinkElement.appendChild(linkTextNode);
node.parentNode.insertBefore(newLinkElement,middleText);
v=node.parentNode.style.display;
//Check if we have a block element, and if not, flash it to
//avoid the redraw bug.
if (v!='block'){
node.parentNode.style.display='none';
node.parentNode.style.display=v;
}
skip=1;
}
}
}
return skip;
}
I removed all sorts of window.body.onload from there because the content scripts are executed after the document is loaded.
To check how everything works, in the shortcut settings for chrome you need to add the path --load-extension = "C: \ Users \ Alex \ Desktop \ chrome-linker" where the last, of course, is the path to the file folder. When restarting, chrome loaded the extension, and going to a typical site with links highlighted all rapidsharnye links. Hooray. It remains to collect the extension in a crx file and put it free.
This process is very simply described here. You need to download Python 2.6 , download the build script from here and execute:
C:\Users\Alex\Downloads>chromium_extension.py --indir=c:\Users\Alex\Desktop\chrome-linker --outfile=chrome-linker.crx
[INFO] Generated extension ID: 23C7C890C288943A468C4316563B9E9712A22ED4
[INFO] created extension package chrome-linker.crx
[INFO] chrome-linker.crx contents:
[INFO] linky.js
[INFO] manifest.json
Done, the file chrome-linker.crx appeared in my download folder. You can download it from my homepage: here it is!
After installation, go to chrome: // extensions / . You should see something like the following:
Hooray! Now all URLs will be links.
UPD 1. ID in the manifest does not need to be specified, it is generated by the build script, I apologize for the misinformation.
, UPD 2. Most likely, communication with content scripts was buggy for me because of my curvature. The subscript extension from google works fine, using communication between toolstripami and content scripts. So I will soon make a new version and describe it in a new post.
P.S. 1. When the API comes out, I will make a new version with normal interfaces, unless of course someone wants.
P.S. 2. In the case, write to komenty, about typos in a personal, that I am a terrible writer, and so I know.
Source: https://habr.com/ru/post/60826/
All Articles