Recommendation Systems: Cold Onset
Recommendation Systems:
- Car Tips
- Cold start
- Introduction to hybrid systems
- artificial immune systems and the effect of idiotypes
For the successful implementation of recommendation systems, it is critical to have a large amount of reference data. But what to do if the necessary data is not at all, or not enough? This condition is called cold start . For example, a new user has registered on the site, and the system still does not know anything about it. Or the store has a new product that no one has ever bought or evaluated. Or really bad, the system has just started its work and it has no data at all. Let's see what can be done in such situations.
If the recommendation system is only one of the capabilities of your service, then you can entertain the user with other functions until the system collects the data it needs. The time required for this is directly dependent on the activity of the user. It is unlikely that it can be accurately calculated, but it is important to imagine in what extent it lies.
')
For systems that collect data openly, this process can be accelerated in some cases, giving the user the opportunity to actively "train" the system. You can partially open the principles of the system and the data it uses, it will help more nimble users to quickly configure the system for themselves.
Some user information can be caught outside your site. You can find out something by analyzing its history of visits to other sites, paying particular attention to search queries (it would be useful to get acquainted with the article " Determining gender by navigation history " as a good example of history analysis). Having some personal information about the user, for example, his email, you can find information about him in his blog or social networks. Fortunately, many services provide open access to information through the API. The resulting data can be used separately, or attributed to the user to some stereotype and make an assumption about its other qualities.
When creating a system, think about what additional sources of information will be available to it, perhaps some of them should be used. These methods can be quite laborious and it is possible that the data will have to be collected bit by bit, but if it is important for the system to know as much about the user as possible and as quickly as possible, then they can help.
The following two methods give more objective results. Their essence is that we can try to predict the attitude of a user to a new object, based on how he evaluated other objects, and how a new object was evaluated by other users.
For example, take one of the collective filtering algorithms - Slope One . To predict the rating, he uses the average difference between the object, which the system is trying to determine, and the object, the rating of which she already knows.
Suppose we have some information about who assessed the product:
Knowing what the average difference between the estimates of product A and B, we can calculate Sasha's score for product B:
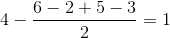
Although the method is rather rough, it works.
The second rather simple, but very elegant and effective method is to represent the compared objects in the form of multidimensional vectors, where the coordinates are numerical representation of some of its properties. Then the quantity characterizing the similarity of these objects will be the cosine of the angle between the vectors. Denote the vectors A and B, then the cosine of the angle between them is equal (by definition of the scalar product ):

where A * B is the scalar product of vectors, and | A || B | - the product of their modules .
Obviously, as a result, we get a number from -1 to 1 inclusive (from 0 to 1, if both vectors are positive). The number 1 means that the vectors are directed in the same way, and the objects are identical; 0 means that the vectors are orthogonal (perpendicular), and the objects have nothing in common; -1 - that the vectors are directed in opposite directions, and our objects are also opposite.
As the coordinates of the vector, you can use any parameters by which you can compare two objects and which can be represented in numerical form. For example, if we need to compare two texts, we can take the words found in them as measurements, and the number of their uses in the text as coordinates (although it is better to use their relevance of the word to the text, obtained, for example, by the TD-IDF method). For more information about the representation of texts in the form of vectors can be found in the article " Vector space model ", and in the article about Slope One there is an example of using a vector with binary values.
Let us return to our example, and try to determine Arthur's assessment of product B, based on the similarity of his opinion with Katya. In the form of vectors, we will represent Arthur and Katya, use the goods as dimensions, and their coordinates will serve as coordinates. Then:

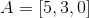

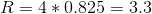
It is obvious that for a similar assessment it is better to take visitors whose opinions coincide.
In the project moismi.ru I used this algorithm to search for similar tags. Here are some illustrative examples of the effectiveness of the vector model (focus on the tag cloud on the right side of the site): " Microsoft ", " browser ", " Google ". Somewhat worse, it works for more rare tags.
Original on my blog
- Car Tips
- Cold start
- Introduction to hybrid systems
- artificial immune systems and the effect of idiotypes
For the successful implementation of recommendation systems, it is critical to have a large amount of reference data. But what to do if the necessary data is not at all, or not enough? This condition is called cold start . For example, a new user has registered on the site, and the system still does not know anything about it. Or the store has a new product that no one has ever bought or evaluated. Or really bad, the system has just started its work and it has no data at all. Let's see what can be done in such situations.
Distract user
If the recommendation system is only one of the capabilities of your service, then you can entertain the user with other functions until the system collects the data it needs. The time required for this is directly dependent on the activity of the user. It is unlikely that it can be accurately calculated, but it is important to imagine in what extent it lies.
')
For systems that collect data openly, this process can be accelerated in some cases, giving the user the opportunity to actively "train" the system. You can partially open the principles of the system and the data it uses, it will help more nimble users to quickly configure the system for themselves.
Use third-party resources
Some user information can be caught outside your site. You can find out something by analyzing its history of visits to other sites, paying particular attention to search queries (it would be useful to get acquainted with the article " Determining gender by navigation history " as a good example of history analysis). Having some personal information about the user, for example, his email, you can find information about him in his blog or social networks. Fortunately, many services provide open access to information through the API. The resulting data can be used separately, or attributed to the user to some stereotype and make an assumption about its other qualities.
When creating a system, think about what additional sources of information will be available to it, perhaps some of them should be used. These methods can be quite laborious and it is possible that the data will have to be collected bit by bit, but if it is important for the system to know as much about the user as possible and as quickly as possible, then they can help.
Statistics
The following two methods give more objective results. Their essence is that we can try to predict the attitude of a user to a new object, based on how he evaluated other objects, and how a new object was evaluated by other users.
For example, take one of the collective filtering algorithms - Slope One . To predict the rating, he uses the average difference between the object, which the system is trying to determine, and the object, the rating of which she already knows.
Suppose we have some information about who assessed the product:
| Item A | Item B | Item B | |
| Sasha | four | didn't rate | eight |
| Katya | 6 | 2 | four |
| Arthur | five | 3 | didn't rate |
Knowing what the average difference between the estimates of product A and B, we can calculate Sasha's score for product B:
Although the method is rather rough, it works.
Vector model
The second rather simple, but very elegant and effective method is to represent the compared objects in the form of multidimensional vectors, where the coordinates are numerical representation of some of its properties. Then the quantity characterizing the similarity of these objects will be the cosine of the angle between the vectors. Denote the vectors A and B, then the cosine of the angle between them is equal (by definition of the scalar product ):
where A * B is the scalar product of vectors, and | A || B | - the product of their modules .
Obviously, as a result, we get a number from -1 to 1 inclusive (from 0 to 1, if both vectors are positive). The number 1 means that the vectors are directed in the same way, and the objects are identical; 0 means that the vectors are orthogonal (perpendicular), and the objects have nothing in common; -1 - that the vectors are directed in opposite directions, and our objects are also opposite.
As the coordinates of the vector, you can use any parameters by which you can compare two objects and which can be represented in numerical form. For example, if we need to compare two texts, we can take the words found in them as measurements, and the number of their uses in the text as coordinates (although it is better to use their relevance of the word to the text, obtained, for example, by the TD-IDF method). For more information about the representation of texts in the form of vectors can be found in the article " Vector space model ", and in the article about Slope One there is an example of using a vector with binary values.
Let us return to our example, and try to determine Arthur's assessment of product B, based on the similarity of his opinion with Katya. In the form of vectors, we will represent Arthur and Katya, use the goods as dimensions, and their coordinates will serve as coordinates. Then:
It is obvious that for a similar assessment it is better to take visitors whose opinions coincide.
In the project moismi.ru I used this algorithm to search for similar tags. Here are some illustrative examples of the effectiveness of the vector model (focus on the tag cloud on the right side of the site): " Microsoft ", " browser ", " Google ". Somewhat worse, it works for more rare tags.
Original on my blog
Source: https://habr.com/ru/post/57885/
All Articles