Seaside 2.9: Partial Sequels
 Some time ago, a topic about “continuation” from HabraUser qmax skipped on Habré . He was very impressed with the idea, but it did not work out in detail. And recently, one of the developers of Seaside, Julian Fitsell, wrote an article that was amazing in its clarity. With his permission, I made her translation and would like to share it with the habrasoobschestvom.
Some time ago, a topic about “continuation” from HabraUser qmax skipped on Habré . He was very impressed with the idea, but it did not work out in detail. And recently, one of the developers of Seaside, Julian Fitsell, wrote an article that was amazing in its clarity. With his permission, I made her translation and would like to share it with the habrasoobschestvom.Immediately I would like to say about the terminology. As a translation of the word continuation, I use the closest in meaning of the sequel. The general terminology of an article for a developer who is inexperienced in Smalltalk may seem unusual. So, instead of the call stack, a “chain of contexts” is used, and instead of a flow, a “process”. If you still have questions after reading - feel free to ask them in the comments. Thank.
This is the second post in a series of reviews of the upcoming Seaside release. Take a look at the first post on exception handling .
Seaside Sequels
Seaside is often referred to as a “continuation-based” web framework, and indeed, at the dawn of development, sequels were used universally, depicting magic. Seaside 2.8 still uses first-class extensions (which I mean later I'll explain) in three different cases:
- to stop processing the request (request) and immediately return a response (response);
- to interrupt the execution of the code and continue it after the user clicks on the link or follows a redirect (for example, to set cookies for the user);
- to implement the call / answer scheme for components.
Nevertheless, the upcoming release of Seaside will completely eliminate the use of continuations in the core of the framework. The first of these cases will be re-implemented using exceptions, and the code for the second and third cases will be moved to an optional, but installable package. This means that you can install Seaside without using extensions at all. This fact should improve portability between Smalltalk dialects, which currently do not support continuations.
')
At the same time, we will also replace the first class continuations with partial continuations, and this article should give an idea of what this means and why we are making these changes. All this can bring down the stalk (especially during debugging!), So do not worry, but let the information settle down, and then go back to it and reread. I simplified several things by donating details, hoping to make this topic more understandable for people who are embarrassed by the very idea of the work of the sequels. I accept any feedback on how I managed to keep this balance.
What is the sequel?
First of all, when I mention the continuations, I mean the continuations of the first class. Seaside also uses the continuation transfer method to implement the rendering cycle (this is the _k parameter that you see in the URLs generated by Seaside). This is a closely related concept, but not what I’m going to talk about next.
Proceedings are often defined as “residual calculations,” but I consider it a bit vague if you don’t understand the essence of this phenomenon. For me, the simplest explanation is that the continuation saves a “snapshot” of the running process, which can be continued later. You call a method that calls another method, that calls another method and so on, and then you take a snapshot of this call chain and save the snapshot object somewhere. In the future, you can restore it at any time by discarding the currently running code, and your program will continue from that very place, from that very method recorded in the “snapshot”. This is the continuation of the first class.
It is easier for Smalltalk users to understand this, because when you save a Smalltalk image and open it later, you see exactly the same picture as when you saved it. You can open the saved image as many times as you like, and each time you will return to the same state. If you save the image to a new file, you can return to the old one. Proceedings, in principle, do the same thing, only instead of the whole image, they retain a single process.
Call and Answer Implementation
One of the most spectacular features of Seaside is the ability to write multistep tasks that require user participation in the usual iterative style:
answer := self confirm: 'Do it?'.
answer ifTrue: [ self doItAlready ]
This is just what becomes easier when using continuations: we want to stop in the middle of the method and ask the user to enter information. If he answers, then we want to continue with the place where we left off. And now let's see how first-class extensions can be used to achieve this.
How to read diagrams
A small digression. The following diagrams depict chains of contexts (although they are rather abstract to call them a stack of frames). Each time you call a method or execute a block, a new context is created at the “top” of the chain. Each time a method returns a value or a block is completed, the context from the “vertex” is deleted. The context of the method knows which method called it, for which object it was called, as well as the value of any variable defined in this method. He also knows the context below it in the chain. If you need help to understand this process, then take a look at the illustration, it is all shown step by step.
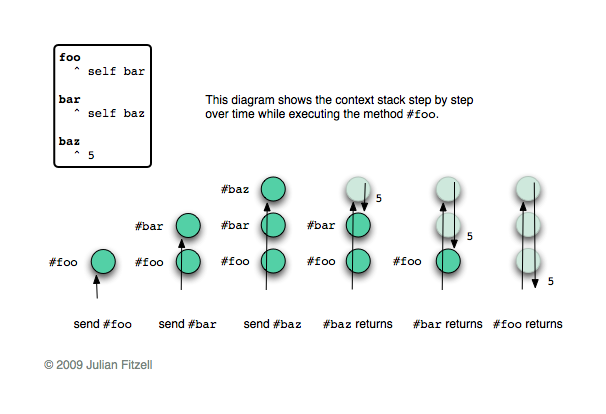
The following diagrams represent a chain of processing contexts for a single HTTP request. Each request is the result of a click on a link, generating the callback execution. Each callback ultimately sends either
#call: or #answer:The diagrams show a chain of contexts at the moment when
#call: or #answer , and depict what happened next. The upward arrows indicate progress as methods are called, and downwards as they are completed. I depict exceptions in the form of a dotted arrow, the tail of which is in the place of the exception, and the head indicates the place of its processing. In the case when the continuation is preserved, both chains are depicted in the diagram: the one that is being executed now and the saved one; while the arrows are directed as usual. Obviously, these are very simplified illustrations: I am more interested in describing a general idea than specific details.To bring clarity, a gray bar is marked on each diagram. All that is above it is the user code: that part of the callback that will be executed. Everything under the line is part of the framework: reading from a socket, session management, etc.
Naïve (fr.) Implementation
Okay, let's take a look at one of the possible implementations using continuations. Imagine that a user is on a web page that contains a “do it” link. Clicking the link performs the callback above as an example, which should ask the user “Do it?”. During the processing of this request, the following occurs:
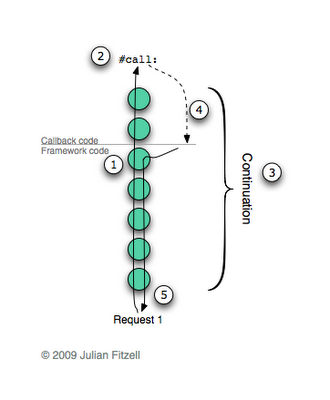
- The framework searches for the correct callback and executes it.
- During callback execution (inside the #inform: in the above example), the message is sent
#call: - The result in each context is saved in continuation for future use.
- An exception is thrown that stops the callback processing and returns control to the framework.
- The framework continues to work and returns a response to the browser (in Seaside, the rendering phase is performed to display the components in the response, but I simplify a little here).
As a result, the browser must display the “Do it?” Prompt and a link or button to confirm the action. When the user clicks on this link (or button), the callback will be activated, which will perform a
self answer: true. . And when the second request is received, the following will occur: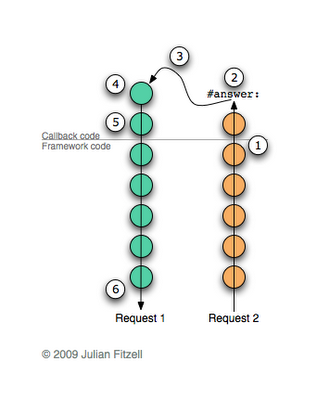
- The framework searches for the appropriate callback and executes it.
- Kolback sends the
#answer:message. - The current chain of contexts is discarded and the one that we saved in continuation is restored to its place. Notice that this method does the return a second time. This is of course strange, but no more strange than to keep the Smalltalk image right in the middle of the calculations. Every time you open an image, you will see the result of the same calculation.
- Now that we have restored the old chain of contexts, execution will continue in the first callback as if our call to
#call:(the place where we saved the continuation) has just ended - The restored callback completes its execution (in our example, it checks the value of the user's response and sends
#doItAlready) - The framework sends a response to the browser.
But there is a problem, and that is why I called this implementation naïve. As you can see, the answer is incorrectly returned on the first request. The socket associated with the first request for disaster has long been closed and the browser no longer waits for a response. The browser expects to receive a response that apparently never comes in the socket associated with the request number two. Woops!
(Almost) Work Call and Answer
So, the first implementation does not work, but I hope it showed what happens with the sequels. The problem is that when we restore the continuation, we don’t want to throw out absolutely everything that the framework has done. At a minimum, we need a context that will return the response to the correct socket.
A simple way to limit the number of contexts captured by the continuation is to create a new process. A new process starts with a new, empty chain of contexts, so when we create a continuation, only the contexts in this chain will be captured. We can use the semaphore to make the first process wait until a new one processes the request. When the second process is complete, it will light the semaphore, and the original process will return the response to the correct socket.
The following diagram depicts this scheme (contexts of different processes are represented by different symbols):

- At some point in the framework code, a new process is created, and the original one is waiting for a semaphore signal.
- The new process finds and executes the corresponding callback.
#call:sends the message#call:- The continuation is saved (note that this time the continuation starts from the start point of the new process).
- An exception is thrown, the callback stops processing and returns control to the framework.
- The framework creates the response for the browser and lights the semaphore.
- The original process continues its execution and returns the response to the browser.
So far, the only advantage is that the sequel is less. But when the second request comes, it becomes obvious how this approach solves our problem:
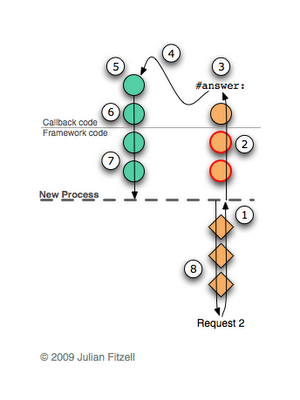
- At some point in the framework code, a new process is created, and the original one is waiting for a semaphore signal.
- The new process finds and executes the corresponding callback.
- Kolback sends the
#answer:message. - The current chain of contexts is discarded and restored to the one that we saved in the continuation (but note that this time only the contexts in the child process are discarded, and the pending process remains unaffected).
- After we have restored the saved chain of contexts, the execution continues as if the call
#call:just completed. - Callback completes execution.
- The framework creates a response for the browser and lights the semaphore, informing the parent process of the completion of its work.
- The original process continues execution, this time correctly returning a response to the browser.
Now we not only made the sequel less, but also ensured that the answer to the second request was returned to its intended purpose. This implementation was used in Seaside 2.8 and earlier versions.
But there are a number of significant problems:
- Creating interprocess communication increases the complexity of the system.
- Exceptions can not overcome the boundary beyond which the new process was created. Indeed, if you throw out an exception, the first process will never know about it (technically, this can be overcome and you can simulate this behavior to some extent, but this complicates the system even more). This means that error handling must be fully performed in the spawned process. This also adds difficulty, for example, when working with a database that uses exceptions to mark objects as dirty, or to indicate the transaction status of the current process.
- Exceptions thrown after recovery will continue to cross the restored chain of contexts. Also, when the exception is processed, the recovered chain of contexts will be promoted, and not the one that was dropped. Look at the framework contexts colored in red on the last diagram: they will not have a chance to complete the execution and all the safety blocks they have identified will never be executed. Believe me, when I say that it can generate some insidious bugs.
- It is necessary to find a compromise between size and accuracy in view of points 2 and 3. If you start a new process immediately before executing a callback, you will get a very small continuation and a shorter exception handling. Unfortunately, your exceptions will not be able to be thrown far enough and the code will end up running in a completely different place, for example, during the rendering phase.
- Debugging turns into a nightmare (well, at least in Squeak), when the code depends on the running process. I am not sure that debuggers will learn to proceed to the process in which the error occurred directly, but at least they will not be able to do it correctly.
Partial sequels
Partial continuations imply that instead of saving the whole chain of contexts, we save only the part that is interesting to us. And when we restore a partial continuation, we replace with them not the whole chain, but only the part that does not represent any interest. Let's take a look at how this works.
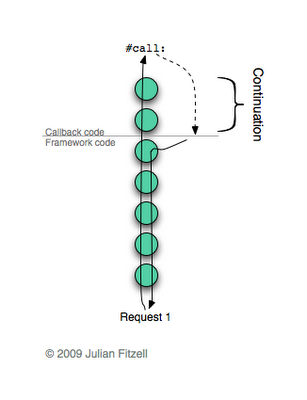
When the first request arrives, everything happens exactly the same as in the first example, so I will not analyze it step by step, except for one thing: using partial continuations, we can specify the exact range of contexts to save in the continuation. In this case, we save only those contexts that are part of the user code - callback. Remember the problem from the first implementation? The framework code processes one specific request; these framework contexts will be absolutely useless when processing any other request (even for the same URL, there will still be a new request). Since a callback can cover several HTTP requests in its execution, we only need to save such callback contexts (called request) contexts for later recovery.
Remember also that the chain of contexts in real life can be much longer than shown in these diagrams: so we save 5 contexts instead of, say, 40! Well, how? Not a bad savings.
And now let's take a look at how the second request is processed. This illustration is slightly different and more complex, because the chain of contexts changes at runtime, so I will look at it step by step:
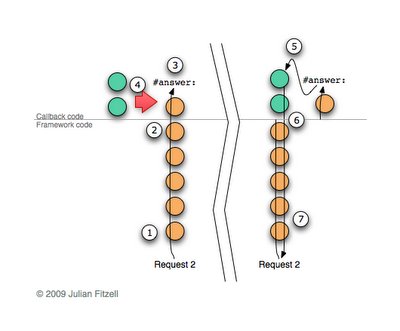
- The request goes to processing.
- The framework searches for an appropriate callback and executes it.
- Kolback sends the
#answer:message. - Then the saved partial continuation is searched instead of the existing callback code and the saved contexts are literally “transplanted” to the current ones, rewriting the message senders. I drive my hands in the air, dropping the details, but you have to believe me, everything actually happens that way. The right side of the diagram shows the state after the completion of “transplantation”. Notice that all framework contexts are unaffected, and we are still within the scope of the original process.
- The saved callback continues to run as if the call to the
#call:method#call:only would have completed. - As soon as the restored callback finishes its execution, it will return control (because we replaced the senders) directly to the framework code that processes the current request.
- Next, a response will be generated and transmitted via the appropriate socket to the browser.
Magic! I am sure that it looks that way, but it works just fine. As a result, we have a short continuation and we do not need to create a new process, and all the framework code gets a chance to complete its execution successfully.
Conclusion
The partial continuation solution is currently implemented in the development version of Seaside and will be included in the next release. Squeak and VisualWorks already support the implementation of partial continuations in the code. GemStone is close to completing their implementation in its VM. Dialects that cannot implement partial continuations have a choice:
- can simulate partial continuations with varying degrees of completeness using first-class extensions;
- may continue to use a system similar to the one that was in Seaside 2.8;
- can leave them alone. As I noted above, we have removed the use of Seaside sequels and cores: the platforms can simply stop supporting the call to
#call:and this is now easy to do, just not provide the Seaside-Flow package.
I hope that this was a useful and interesting piece of reading and I would appreciate your comments on everything that seemed difficult or helpful to understand. Happy Seasiding.
Source: https://habr.com/ru/post/55801/
All Articles