Grab pages with WebHarvest
The task of hornbeat information from web pages is always relevant. As for a project, and in order to more convenient use of the resource. I mean usability or simply the need to see the data in another section. To rob someone else's information and use it for commercial purposes is always bad, they usually try to punish and punish for it. And for personal use, you can use it freely. This can probably be compared with the use of a pencil or colored markers when reading newspapers and magazines. For example, if I am circling ads in red, then in yellow, and some are crossed out in bold, I simply qualitatively change the display of information in the light necessary for my tasks. But lawyers need to be afraid.
About six months ago, a blogcampCEE was scheduled to take place in Kiev and everyone who wanted to take part in the event had to register and fill out their profile. At that time I was little acquainted with the local market of Internet projects, as well as with who does what on the Ukrainian IT and Internet markets. Public profiles of the participants of this event will allow to make a certain picture of the market participants (parties). It is convenient to use such information when it is on one page. In order to collect all these data manually, it would be necessary to spend a lot of time navigating through pages and save-pastes, and it would also have to be updated with pens over time.
Programming skills there, it means you can come up with something. And laziness, as we know, is the engine of progress. Just recently, colleagues at work solved the problem of getting a site rating from Alex’s html page on Alex . And it was hidden behind a bunch of dummy spans with generated styles, which made it impossible to directly draw out this value. So we met then WebHarvest . And they perfectly solved this task, and even with a bunch of similar ones that arise when writing tools for SEO. After all, they need a lot of data, page ranks, persistence of keywords, competitor analysis, etc. etc. And for 80% of the tasks associated with the collection of information, the API does not exist, you just have to run around the pages and collect this info.
So, I want to share my experience of getting the necessary information in a readable form from BlogcampCEE (just a real life example) using WebHarvest library, Java programming language (in the background), Ant build tool and XSLT processor for converting XML to HTML.
')
Found at that time page blogcampcee.com/ru/group/tracker which tracks all open events occurring on the site. Among them is an event of type Usernode, which means the registration of a new user and contains a link to the user profile.
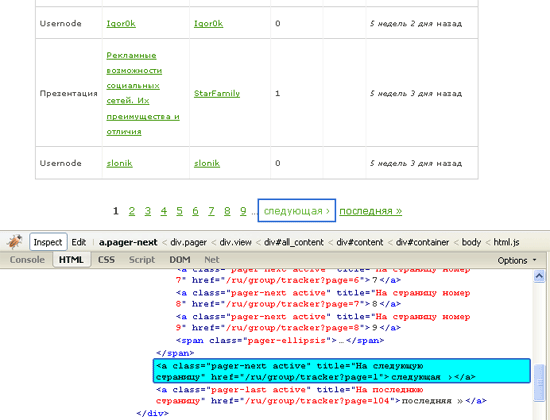
Later, I found the blogcampcee.com/ru/userlist page, where only users are shown, and it would be more logical to take it as an entry point to a task. But it was too late, everything has already been done. She would not really help, except that she accelerated the work due to the absence of uninteresting events and additional type checking. From the clicks would not save for sure.
The task was to scroll through all possible pages, get all the links to the users' pages and then go through each user and collect the necessary information.
It is necessary to write a configuration file in the GUI of Webharvest, not so hot development environment, but nothing is better than it. Debugging is also not easy. But at least the state of the variables can be viewed at any point in the execution. And this is a lot.
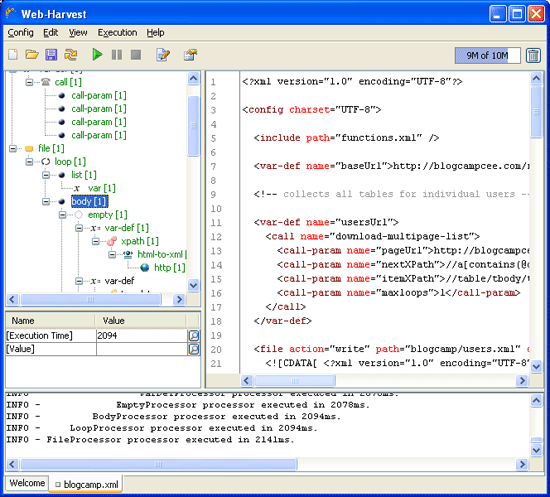
WebHarvest GUI
Functions are taken out in the functions.xml file, which will then be used in the main configuration file. A separate function was used to walk on leaflets and pull links to user pages (borrowed with some changes from the examples on WebHarvest).
The main configuration file blogcamp.xml contains the logic of passing through the pages of users and pulling out some fields, including links to personal pages and sites of projects, which I was most interested in. And all this information in the custom xml format ( users-samples.xml ) is saved to a file.
The XML file is not very convenient to read, so user -style.xsl was written for it to give a readable and convenient look.
And we get this page at the output of the XSLT processor.
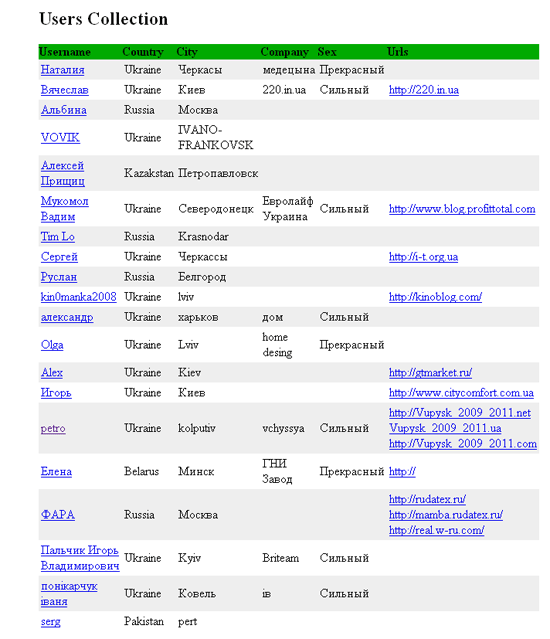
The desired format of the list of users.
WebHarvest is a purely programmer tool which, as a library, is convenient to use in your projects by feeding it the necessary configuration files and getting the desired result. Therefore, we will link the hornbeam and XSL transformation into a single process with the help of Ant, as if it will continue to develop into a complex product or so that it does not have to be remembered in the future, but how did this whole business come about and where did it come from. So build.xml and such structure turned out.

Now, when in the future it is necessary to remember what is happening and what is going on here, and repeating these procedures (and this happens not infrequently and after a long time, when you have time to completely forget what it is all about) it will be very easy to resume, repeat, edit and etc. etc.
Problem solved. The necessary information is on one page in a convenient form for me. The whole process is easily repeated by pressing a single button, which is very important as the number of users increases and over time you will need to update your sheet.
The most important is the absence of multithreading in the hornbeam process. The command line works in this way only. This was not critical for my task. Programmatically you are free to do what you want. And please organize multithreading, parallelization and work in distributed mode on a cluster of N computers. All in your hands.
Not entirely successful structure of the solution itself. When a passage is immediately made to identify all user references, and then processing is already done on them. It is better to do the processing of the user's link as soon as it is received and save the result to a file. Then, at the break of a connection or something else, you will not have to run a hornbeam from the very beginning, but you can continue from the place where everything fell.
There is no sequence number in the resulting HTML, I already noticed that later, and it was too lazy to finish it, because this is XSLT again.
Few comments in all configuration files. Sorry, but it is a scourge that haunts me constantly. Usually they begin to be written after marking the six months of work on the project and you realize that the memory resource has exhausted itself, and the project bells and whistles do not think to stop :)
And many more can be found.
I do not like when reading an article you can not immediately try everything in life. Therefore, I post the archive with the full project , including WebHarvest. For convenient operation, you need to run Ant from the command line anywhere on your system. Important! Do not torment the blogcamp site. Although the event has passed, but anyway, this is after all the hosting and traffic is not necessarily anlim.
If you don't work a lot with XPath, then this is all quickly forgotten. Here are a couple of resources that helped me refresh (learn) the features of these technologies.
XPath specification
XPath writing examples
The main goal is to show the possibility of using WebHarvest tools, as a grabber in their projects.
Tulza has enough features and frills, including using Javascript and XQuery, saving cookies, basic authentication, user-agent substitution, custom request headers, etc. Yes, and you can rewrite a part of the API or cast it beyond recognition, which the father of the creator will not recognize later.
The origin of the task
About six months ago, a blogcampCEE was scheduled to take place in Kiev and everyone who wanted to take part in the event had to register and fill out their profile. At that time I was little acquainted with the local market of Internet projects, as well as with who does what on the Ukrainian IT and Internet markets. Public profiles of the participants of this event will allow to make a certain picture of the market participants (parties). It is convenient to use such information when it is on one page. In order to collect all these data manually, it would be necessary to spend a lot of time navigating through pages and save-pastes, and it would also have to be updated with pens over time.
Finding the way
Programming skills there, it means you can come up with something. And laziness, as we know, is the engine of progress. Just recently, colleagues at work solved the problem of getting a site rating from Alex’s html page on Alex . And it was hidden behind a bunch of dummy spans with generated styles, which made it impossible to directly draw out this value. So we met then WebHarvest . And they perfectly solved this task, and even with a bunch of similar ones that arise when writing tools for SEO. After all, they need a lot of data, page ranks, persistence of keywords, competitor analysis, etc. etc. And for 80% of the tasks associated with the collection of information, the API does not exist, you just have to run around the pages and collect this info.
So, I want to share my experience of getting the necessary information in a readable form from BlogcampCEE (just a real life example) using WebHarvest library, Java programming language (in the background), Ant build tool and XSLT processor for converting XML to HTML.
')
First approach
Found at that time page blogcampcee.com/ru/group/tracker which tracks all open events occurring on the site. Among them is an event of type Usernode, which means the registration of a new user and contains a link to the user profile.
Later, I found the blogcampcee.com/ru/userlist page, where only users are shown, and it would be more logical to take it as an entry point to a task. But it was too late, everything has already been done. She would not really help, except that she accelerated the work due to the absence of uninteresting events and additional type checking. From the clicks would not save for sure.
The task was to scroll through all possible pages, get all the links to the users' pages and then go through each user and collect the necessary information.
It is necessary to write a configuration file in the GUI of Webharvest, not so hot development environment, but nothing is better than it. Debugging is also not easy. But at least the state of the variables can be viewed at any point in the execution. And this is a lot.
WebHarvest GUI
Functions are taken out in the functions.xml file, which will then be used in the main configuration file. A separate function was used to walk on leaflets and pull links to user pages (borrowed with some changes from the examples on WebHarvest).
The main configuration file blogcamp.xml contains the logic of passing through the pages of users and pulling out some fields, including links to personal pages and sites of projects, which I was most interested in. And all this information in the custom xml format ( users-samples.xml ) is saved to a file.
Modernization
The XML file is not very convenient to read, so user -style.xsl was written for it to give a readable and convenient look.
And we get this page at the output of the XSLT processor.
The desired format of the list of users.
The structure of the mini-project
WebHarvest is a purely programmer tool which, as a library, is convenient to use in your projects by feeding it the necessary configuration files and getting the desired result. Therefore, we will link the hornbeam and XSL transformation into a single process with the help of Ant, as if it will continue to develop into a complex product or so that it does not have to be remembered in the future, but how did this whole business come about and where did it come from. So build.xml and such structure turned out.
Now, when in the future it is necessary to remember what is happening and what is going on here, and repeating these procedures (and this happens not infrequently and after a long time, when you have time to completely forget what it is all about) it will be very easy to resume, repeat, edit and etc. etc.
Problem solved. The necessary information is on one page in a convenient form for me. The whole process is easily repeated by pressing a single button, which is very important as the number of users increases and over time you will need to update your sheet.
disadvantages
The most important is the absence of multithreading in the hornbeam process. The command line works in this way only. This was not critical for my task. Programmatically you are free to do what you want. And please organize multithreading, parallelization and work in distributed mode on a cluster of N computers. All in your hands.
Not entirely successful structure of the solution itself. When a passage is immediately made to identify all user references, and then processing is already done on them. It is better to do the processing of the user's link as soon as it is received and save the result to a file. Then, at the break of a connection or something else, you will not have to run a hornbeam from the very beginning, but you can continue from the place where everything fell.
There is no sequence number in the resulting HTML, I already noticed that later, and it was too lazy to finish it, because this is XSLT again.
Few comments in all configuration files. Sorry, but it is a scourge that haunts me constantly. Usually they begin to be written after marking the six months of work on the project and you realize that the memory resource has exhausted itself, and the project bells and whistles do not think to stop :)
And many more can be found.
Materials
I do not like when reading an article you can not immediately try everything in life. Therefore, I post the archive with the full project , including WebHarvest. For convenient operation, you need to run Ant from the command line anywhere on your system. Important! Do not torment the blogcamp site. Although the event has passed, but anyway, this is after all the hosting and traffic is not necessarily anlim.
If you don't work a lot with XPath, then this is all quickly forgotten. Here are a couple of resources that helped me refresh (learn) the features of these technologies.
XPath specification
XPath writing examples
Conclusion
The main goal is to show the possibility of using WebHarvest tools, as a grabber in their projects.
Tulza has enough features and frills, including using Javascript and XQuery, saving cookies, basic authentication, user-agent substitution, custom request headers, etc. Yes, and you can rewrite a part of the API or cast it beyond recognition, which the father of the creator will not recognize later.
Source: https://habr.com/ru/post/53441/
All Articles