From data to information
Recently, in the specialized press, the “mysterious” abbreviation ILM - Information Lifecycle Management appears. Leading developers, one after another, offer solutions for one or another part of ILM, beautifully describing the general data storage scheme in an appropriately reorganized data center. However, a clear understanding of what ILM is, among Russian customers, in our opinion, has not yet been worked out.
The first thing to note is that ILM is not a panacea, not a technology, not a solution, and not a guide to action. This is a concept reflecting a modern view of corporate data; a set of management practices aimed at achieving an optimal balance between the value of information for business and the cost of its storage infrastructure.
ILM, according to SNIA (Storage Networking Industry Association, www.snia.org ), is the policies, processes, practices, services and tools used to relate the value of information from a business point of view to the most appropriate and cost-effective infrastructure, starting since the creation of information and ending with its placement. Information is mapped to business requirements through management policies and service levels associated with applications, data, and metadata.
')
Simply put, this is the concept of automatically placing data in a data center infrastructure based on business requirements for security parameters, availability of information and taking into account its value to the business, relevance and minimizing storage costs. What kind of storage problems does ILM solve?
Do not drown in the ocean of data
It's no secret that the volume of corporate information is increasing every year, and very seriously. According to IDC reports, the growth in the volumes of stored and processed data is more than 70% per year. In an average modern company, three thousand employees daily e-mail a terabyte of data. In total in the world, according to Gartner's calculations, in 2005, 36 billion e-mails were sent per day — three times more than in 2001. In some specific branches, for example, in medicine, an exponential growth of information volumes is observed.
The situation is complicated by the requirements of regulatory acts and corporate standards that prescribe the long-term storage of certain types of information - sometimes for 5--10 years. This means that a company with a modest volume of 1 TB of corporate data and showing a growth of 60% per year (not the largest by modern standards), in 10 years will store 110 TB of information. Increase more than 100 times!
The problem of the explosive growth of data volumes is closely related to another problem: the processes of managing distributed data center infrastructure are constantly becoming more complex. A modern data center consists of thousands of interconnected components — servers, storage elements (logical units, disks, controllers, control servers, tape drives, etc.), storage network elements, and local area networks (routers, host controllers, adapters, and etc.). To manage complex infrastructure, special tools are used, and for each type of infrastructure elements - their own. And the more heterogeneous components in the data center, the more management tools you have to use. Which further increases the complexity of the system.
In addition, the use of specialized infrastructure management tools does not solve the main task - to manage an avalanche-like growing data stream. Companies continue to store information in expensive high-performance systems and, despite the reduction in the cost of equipment, every year they spend more and more money on its storage. The backup process is becoming more complex and takes more and more time. At the same time, the existing management tools do not sufficiently automate the processes of placing information - administrators actually manually allocate storage space, set the binding to the necessary servers, create a backup schedule, determine the sources and destinations.
The current situation in the field of data storage can be described as follows: the volume of data is growing dramatically, and the existing management tools are not able to cope with this .
Does the business need all the data stored in the systems?
Returning to the example of a company that has increased the volume of corporate information 100 times in 10 years, let us ask ourselves: is it really necessary for its business to have these 110 TB of data placed in operational repositories?
Obviously not. Over time, both the value of data and the requirements for its availability and security change. Thus, the value of a financial transaction is maximum during the first month and subsequently steadily decreases. In addition, the financial record in the ERP-system of the company and, say, a personal letter of the employee have different business values at the time of creation.
Meanwhile, in the operational high-performance repositories of the data center there are all data, including obsolete and unnecessary, while only those with high accessibility requirements must be stored there.
An analysis by the Enterprise Storage Group shows how the value of information for a business changes over time depending on its type.
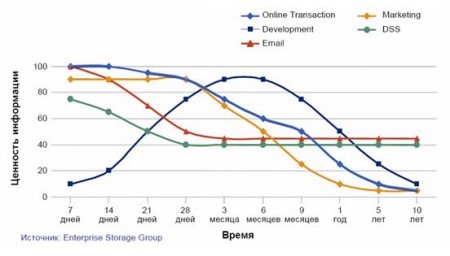
We can make an important conclusion: different classes of information have different business values, and this value changes over time .
The next important property of corporate data is their condition. The created data is stored in the data center for further processing and then changes depending on the tasks solved by the business. While the data changes, they are in the active state and are called operational. But over time there comes a time when the data is “fixed” and no more changes are made. They can be used to generate new documents, summary reports, etc. Such data is called reference data. The natural way to store reference data is an archive.
In modern data centers, operational and reference data are usually placed together in the same repositories, which not only increases the cost of storage, but also creates difficulties in complying with regulations governing the storage of certain types of information.
Finally, there is one more condition - outdated data, which are not used anywhere else, and their storage period, regulated by regulatory acts, has expired. Such data is no longer needed by the business, its value is zero, and it can be deleted. Currently, outdated data are tracked almost manually, their removal from the system is a nightmare for the administrator, and storage is a waste of money.
Forward and upward!
Describing the current data storage situation, we deliberately did not focus on the distinction between data and information. Similarly, these differences are not taken into account in the current practice of organizing processes and storage infrastructure. However, this aspect is one of the most important in the concept of ILM: data information
Data is simply a set of bytes, a way to reflect business information in a storage infrastructure. From this point of view, all of them are of equal value, since their semantics is not defined, and such parameters as reliability of storage, security and availability are important here. These are the characteristics that modern data storage systems and infrastructure management tools operate on.
Information is data that represents a specific meaning for a business. Similar in structure, data equally placed in the storage system may have completely different meanings and, therefore, different values for the company. For example, an employee personal letter sent by e-mail, and a letter from the same employee containing confidential information about the client.
ILM offers to move away from data management and focus on information management. To do this, first of all, it is necessary to change the approach to its storage. ILM proposes to classify the company's business information before it enters the storage infrastructure. Classification is a process necessary for the effective management of the life cycle of information, providing the stored data with adequate semantics.
For this process, the concepts of service level targets (Service Level Objectives - SLO) and “Policies” (Policies) are introduced, on the basis of which information storage will be managed. SLO determines which key performance indicators (reliability, availability, etc.) should be provided by the storage infrastructure for this class of information. “Policies” determine the necessary actions with specific classes of information in the event of certain conditions (for example, at the end of the life of the information). The basis for the formation of SLO and policies are the business requirements and business processes of the company, as well as various regulations.
Thus, the approach to storing data in a data center becomes information-centric.
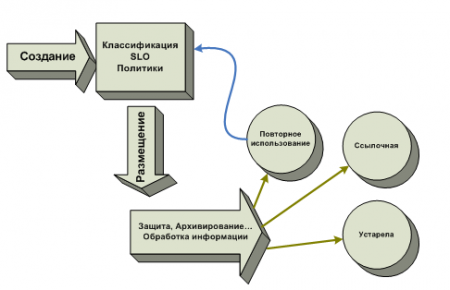
The created information is classified, it is associated with certain SLOs, on the basis of which the management mechanism integrated into the infrastructure allocates this information according to specified policies. This means that information that requires high availability will fall into high-performance storage systems, and that which is not critical for business will be located in low-cost storage facilities.
At the same time, the mechanisms for working with data applications do not change, but management tools constantly monitor the value of information, its state and move it to adequate storage systems according to policies and SLO. At a certain stage of the life cycle, information may become referential, outdated, or reused. Then the control mechanism in the first case will transfer it to the archive, in the second - it will simply remove it, and in the third - re-classify and link it with another SLO.
Thus, the data center, built according to ILM, provides the following main advantages:
The first thing to note is that ILM is not a panacea, not a technology, not a solution, and not a guide to action. This is a concept reflecting a modern view of corporate data; a set of management practices aimed at achieving an optimal balance between the value of information for business and the cost of its storage infrastructure.
ILM, according to SNIA (Storage Networking Industry Association, www.snia.org ), is the policies, processes, practices, services and tools used to relate the value of information from a business point of view to the most appropriate and cost-effective infrastructure, starting since the creation of information and ending with its placement. Information is mapped to business requirements through management policies and service levels associated with applications, data, and metadata.
')
Simply put, this is the concept of automatically placing data in a data center infrastructure based on business requirements for security parameters, availability of information and taking into account its value to the business, relevance and minimizing storage costs. What kind of storage problems does ILM solve?
Do not drown in the ocean of data
It's no secret that the volume of corporate information is increasing every year, and very seriously. According to IDC reports, the growth in the volumes of stored and processed data is more than 70% per year. In an average modern company, three thousand employees daily e-mail a terabyte of data. In total in the world, according to Gartner's calculations, in 2005, 36 billion e-mails were sent per day — three times more than in 2001. In some specific branches, for example, in medicine, an exponential growth of information volumes is observed.
The situation is complicated by the requirements of regulatory acts and corporate standards that prescribe the long-term storage of certain types of information - sometimes for 5--10 years. This means that a company with a modest volume of 1 TB of corporate data and showing a growth of 60% per year (not the largest by modern standards), in 10 years will store 110 TB of information. Increase more than 100 times!
The problem of the explosive growth of data volumes is closely related to another problem: the processes of managing distributed data center infrastructure are constantly becoming more complex. A modern data center consists of thousands of interconnected components — servers, storage elements (logical units, disks, controllers, control servers, tape drives, etc.), storage network elements, and local area networks (routers, host controllers, adapters, and etc.). To manage complex infrastructure, special tools are used, and for each type of infrastructure elements - their own. And the more heterogeneous components in the data center, the more management tools you have to use. Which further increases the complexity of the system.
In addition, the use of specialized infrastructure management tools does not solve the main task - to manage an avalanche-like growing data stream. Companies continue to store information in expensive high-performance systems and, despite the reduction in the cost of equipment, every year they spend more and more money on its storage. The backup process is becoming more complex and takes more and more time. At the same time, the existing management tools do not sufficiently automate the processes of placing information - administrators actually manually allocate storage space, set the binding to the necessary servers, create a backup schedule, determine the sources and destinations.
The current situation in the field of data storage can be described as follows: the volume of data is growing dramatically, and the existing management tools are not able to cope with this .
Does the business need all the data stored in the systems?
Returning to the example of a company that has increased the volume of corporate information 100 times in 10 years, let us ask ourselves: is it really necessary for its business to have these 110 TB of data placed in operational repositories?
Obviously not. Over time, both the value of data and the requirements for its availability and security change. Thus, the value of a financial transaction is maximum during the first month and subsequently steadily decreases. In addition, the financial record in the ERP-system of the company and, say, a personal letter of the employee have different business values at the time of creation.
Meanwhile, in the operational high-performance repositories of the data center there are all data, including obsolete and unnecessary, while only those with high accessibility requirements must be stored there.
An analysis by the Enterprise Storage Group shows how the value of information for a business changes over time depending on its type.
We can make an important conclusion: different classes of information have different business values, and this value changes over time .
The next important property of corporate data is their condition. The created data is stored in the data center for further processing and then changes depending on the tasks solved by the business. While the data changes, they are in the active state and are called operational. But over time there comes a time when the data is “fixed” and no more changes are made. They can be used to generate new documents, summary reports, etc. Such data is called reference data. The natural way to store reference data is an archive.
In modern data centers, operational and reference data are usually placed together in the same repositories, which not only increases the cost of storage, but also creates difficulties in complying with regulations governing the storage of certain types of information.
Finally, there is one more condition - outdated data, which are not used anywhere else, and their storage period, regulated by regulatory acts, has expired. Such data is no longer needed by the business, its value is zero, and it can be deleted. Currently, outdated data are tracked almost manually, their removal from the system is a nightmare for the administrator, and storage is a waste of money.
Forward and upward!
Describing the current data storage situation, we deliberately did not focus on the distinction between data and information. Similarly, these differences are not taken into account in the current practice of organizing processes and storage infrastructure. However, this aspect is one of the most important in the concept of ILM: data information
Data is simply a set of bytes, a way to reflect business information in a storage infrastructure. From this point of view, all of them are of equal value, since their semantics is not defined, and such parameters as reliability of storage, security and availability are important here. These are the characteristics that modern data storage systems and infrastructure management tools operate on.
Information is data that represents a specific meaning for a business. Similar in structure, data equally placed in the storage system may have completely different meanings and, therefore, different values for the company. For example, an employee personal letter sent by e-mail, and a letter from the same employee containing confidential information about the client.
ILM offers to move away from data management and focus on information management. To do this, first of all, it is necessary to change the approach to its storage. ILM proposes to classify the company's business information before it enters the storage infrastructure. Classification is a process necessary for the effective management of the life cycle of information, providing the stored data with adequate semantics.
For this process, the concepts of service level targets (Service Level Objectives - SLO) and “Policies” (Policies) are introduced, on the basis of which information storage will be managed. SLO determines which key performance indicators (reliability, availability, etc.) should be provided by the storage infrastructure for this class of information. “Policies” determine the necessary actions with specific classes of information in the event of certain conditions (for example, at the end of the life of the information). The basis for the formation of SLO and policies are the business requirements and business processes of the company, as well as various regulations.
Thus, the approach to storing data in a data center becomes information-centric.
The created information is classified, it is associated with certain SLOs, on the basis of which the management mechanism integrated into the infrastructure allocates this information according to specified policies. This means that information that requires high availability will fall into high-performance storage systems, and that which is not critical for business will be located in low-cost storage facilities.
At the same time, the mechanisms for working with data applications do not change, but management tools constantly monitor the value of information, its state and move it to adequate storage systems according to policies and SLO. At a certain stage of the life cycle, information may become referential, outdated, or reused. Then the control mechanism in the first case will transfer it to the archive, in the second - it will simply remove it, and in the third - re-classify and link it with another SLO.
Thus, the data center, built according to ILM, provides the following main advantages:
- reducing the cost of storing information (due to the timely transfer of data to low-cost storage systems and the destruction of outdated information);
strict compliance with regulations governing data storage through the automatic application of policies;
achievement of compliance of storage characteristics (reliability, security, availability, etc.) to different classes of information;
eliminating duplication of information (by managing reference data).
And at the same time information is always provided in the right place, at the right time and at the best price.
Source: https://habr.com/ru/post/5093/
All Articles