Panasonic attacks

Most recently, analyzing the causes of network outages, I found a very interesting situation. The investigation lasted for almost a month, and as a result, a chain of events was discovered that, together, are capable of setting up a corporate subnet with a bang.
This article is quite an interesting puzzle, with a detailed analysis of how it was solved. I think this case will be of interest not only to system and network administrators, but also to ordinary users who may not even suspect what could be behind an ordinary MFP, inconspicuously standing in the corner of the office, waiting for its time ...
')
And for those who often use phrases like “this is an inexplicable glitch”, or “the operation of this equipment depends on the weather and precipitation in southern Zimbabwe”, this article is simply “must read”, because I am convinced that any phenomenon can be explained using facts logic and common sense. And this article is a clear confirmation of this.
And so it all began with the fact that in the logs of some switches on the corporate network began to appear messages with the following content: "% SPANTREE-2-LOOPGUARD_BLOCK: Loop guard blocking port FastEthernet0 / 24 on VLAN000X" . Knowledgeable people probably immediately recognized the message in the Cisco IOS style, and for the rest I will explain: the switch fixed a loop in the network, and therefore blocked the traffic of some VLAN X on the 24th port. In this article, under one VLAN you can understand one subnet (but only in this article, and only for understanding the described events). Since we are talking about the access level switch, and the 24th port connects it with the rest of the network, the users who are connected to this switch and located on this very subnet are affected.
Only two things were pleasing: firstly, the port was blocked for less than a second, and secondly, there were no complaints from users. Until. So, it was time to sort out the problem, and without raising excess noise, eliminate it.
An analysis of the available logs showed that the problem manifested itself on average 2-3 times a day and always during working hours. Because of this, it took a long time to collect enough data.
The idea of the existence of a real loop was immediately discarded completely, since it had no right to exist (experience suggested). At that time, it immediately became clear that there was a process on the network that somehow caused the switch to “detect the loop”.
First of all, I rummaged through all the logs in search of the correlation of several events in time. And I discovered that every time such a “loop detection” occurs, the connection is broken with one of the Canon network printers located in the same VLAN. Since this happened with a difference of 2-3 seconds, I came to the conclusion that he, too, hears something on the network that makes him feel bad, and he distorts the network port, and maybe it is completely overloaded. He was too lazy to go, but obviously he was ill for the same reasons.
The only thing that all participants of one VLAN could hear, which means a single broadcast domain on the 2nd level, is of course broadcast, i.e. actually broadcast package.
Well, since this broadcast is most likely, then I can also hear it. I installed a separate car, connected it to the desired VLAN, and launched a sniffer on it with a protocol analyzer, which wrote everything to the disk all day and night. Absolutely everything, but only what he could hear. And what could he hear? And he could hear his own traffic, which was of no interest, and all the broadcast traffic on the network. And we do not need more.
The first results of the sniffer's work surprised me ... well, to put it mildly. For this network segment, well, i. for all this VLAN, the norm was 500-1000 broadcast packets per second.
Here I probably will make a small digression. Some will be indignant at once, saying that there is so much traffic from! First of all, the network segment is quite large - to roll out 200-300 cars. Secondly, IPX traffic is redirected to this segment, which uses broadcasting very actively. So these traffic intensity values did not surprise me at all.
But it surprised:
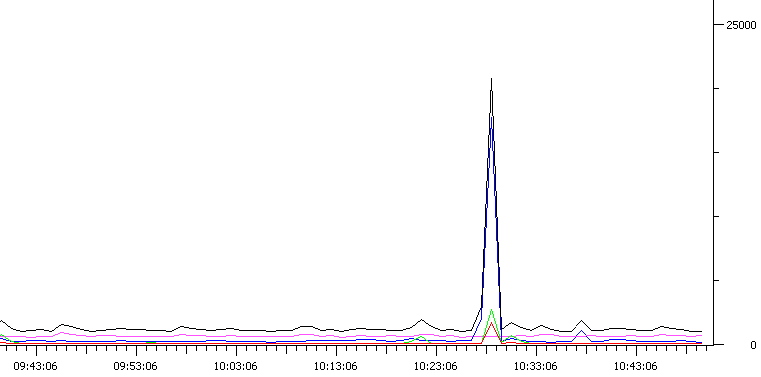
At the very moment when some network switches fixed a “loop”, the broadcast traffic on the network went offboard at 20'000 packets per second! But from where?
At this point several points have already become clear. "Loop" was fixed only by Cisco2950 series switches, of which there are only two in the network. Most often, this event occurred immediately on both switches, but from time to time the problem manifested itself only on one of them, without touching the second one. The most interesting thing turned out to be that the problem manifested itself every day twice at exactly the same time, and 1-3 times at the time points that were absolutely not repeated. The graph shows the manifestation of the problem at 10:27 in the morning. The second hour of X was 9:34 am. Every day at this time the situation was repeated. This was the first clue.
On the graph, the top black line is all traffic caught by the sniffer. And blue is all ARP requests. As you know, an ARP request is sent by a broadcast packet, and the presence of this traffic fits into the framework of my understanding. But it is from ARP requests that the whole crest of this wave itself consists of 20'000 packets! It is also worth noting a small splash of the green line. This is SNMP traffic (in a nutshell, the network management protocol). And also a red splash is a unicast flood. But we will return to them later.
Analysis sniffer logs dragged on for more than one day. I also found that at the time of the problem, the network was filling with unicast-flood, i.e. in a slightly simpler language, a large number of switches like Cisco3560 (this is not a switch for 500 rubles, this is a managed enterprise-level network equipment with a corresponding cost) for some period of time began to work as a stupid hub. It completely baffled. The situation developed as in a fairy tale - the further the worse. And I had to face a kind of monster who could do this!
And among the squall of ARP requests and the flood of unicast traffic, I managed to pick out four packets. Four packages that always appeared at the time of the problem, and most importantly the first one always appeared BEFORE this wave appeared.
What were these packages like? Four exactly the same broadcast packets from one source. More precisely, at 9:34 from one, and at 10:27 from another, and sometimes from the third at arbitrary moments of time. And so, this is what this package was:
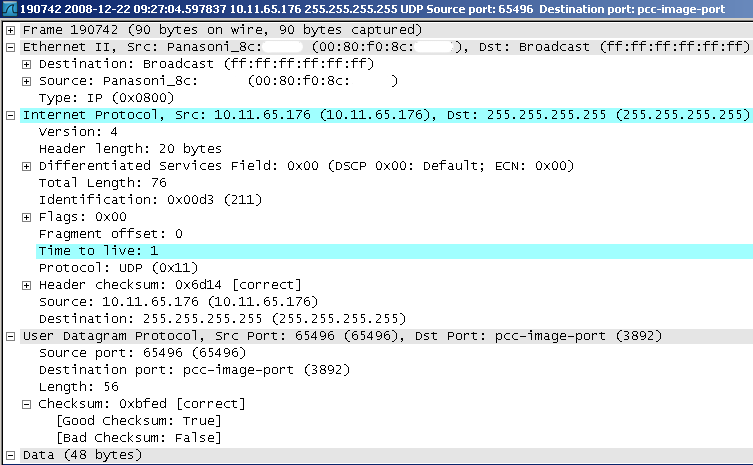
Generally speaking, nothing criminal. Only a certain Panasonic MFP publicly announced itself by sending a broadcast packet with TTL = 1 within its subnet to UDP-port 3892 (pcc-image-port). So what's so terrible?
At first glance, really nothing. But here the interest to look at this miracle of technology of Japanese developers overpowered laziness. Having a MAC address, I quickly determined the location of this device and headed towards it. I did not see anything high-tech, well, like an MFP like, an MFP. But then a thought arose. The switch ports to which the MFP data is connected were always juggled (link up / down) before they formed such a packet. There were two options. Either it reboots and forms it, or for some reason it reboots its network interface. In any case, restarting this MFP could simulate this situation.
This was a headshot! Rebooting the MFP, I modeled this situation again and again. There was no doubt - here it is - EVIL!
But finding a problem is half the battle, it’s much more difficult, but also more interesting, to understand why it happens this way, and especially, why it happens every time at the same time? What is the first thought? Of course, reboot the MFP on a schedule! I found out that there are three such multifunction devices in this network segment, and they were installed just a month or two ago. Having gained access to the web interface of these pieces of iron, I rummaged through them up and down, but there was no question of any reloads on a schedule. And here ... and here I noticed that the system time on these multifunction devices did not correspond to the real one. And it was different at ... 9 hours 34 minutes on one and at 10 hours and 27 minutes on the other! Those. they rebooted exactly at midnight, exactly at 00:00, but according to their internal clock.
Signalers confirmed that Panas PBX-ok has such a feature - to rebel at midnight. Apparently the MFP received an ATC-ing inheritance, because its direct ancestor was clearly facsimile machines. As for the third multifunction device, it seems that it was often reloaded with hands, pulling out of the socket, which caused the occurrence of the problem at arbitrary moments of time.
Thus, the culprit was clearly identified - Panasonic MFP. And it became clear why these events occur at fixed points in time, exactly as it became clear why there are problems at random points in time. But it was still necessary to understand why there was so much ARP traffic on the network, why the switches were bad, and where the flood came from.
I will omit the subsequent investigation details. Let me just say that further research was carried out on a machine with a sniffer after it was installed on the native software from Panasonic, in which there was a snag. But his study was no longer so fascinating, so we turn immediately to the facts and results.
So. The complete chronology of events occurring on the network at the moment when any of the suspected MFPs is turned on (as you go, count the number of broadcast packets for each event):
1. When enabled, a packet is formed, the dump of which was given above, and is distributed throughout the network. The package is sent 4 times, but the benefit of all those devices that receive this package, react only to the first such package, ignoring the rest. Otherwise, the wave of broadcast traffic would be 4 times more! And now we note that this is actually 4 broadcast packets .
2. The software installed on client machines (PCCMFLPD.EXE, which just listens to this very 3892nd port) receives this packet. For example, let us point out that we have 60 such clients, 20 for each multifunction device (yes, such large rooms).
3. And here comes the unexpected. This software communicates with the MFP via the SNMP protocol. And all clients who receive such a packet send out an SNMP broadcast get-next-request request. Note that this is another 60 broadcast packets .
4. Each device operating via SNMP, having received such a packet, wants to respond to it. And that means that he needs to know the MAC address of the one who sent this request. And now let's imagine that we have 100 devices on the network, including these 3 multifunction devices, which work using the SNMP protocol. Why so much? Well, basically these are HP print servers that are used for printing. And what do we get? each of the 100 devices wants to respond to each of the 60 customers. Thus, each such device sends 60 ARP requests. And for ourselves, we note 6000 broadcast requests on the network. ARP requests, by the way. Yeah, it already smells fried, but this is only the beginning =).
5. And now let's remember about our two switches, from which it all started. Yes, those Cisco2950. The fact is that when they scrape such a quantity of broadcast traffic, they perceive it as a broadcast-storm. This phenomenon usually accompanies loops in the network when one packet goes endlessly in a circle. But these switches explain the blocking of their ports in this way: “Loop guard blocking port” , i.e. “Blocking the port to protect against looping” (it sounds crooked, but clearly I think). Well, the port is blocked, well, it would seem like a fool. But no! When the port is unblocked, the switch sends its TCN (Topology Change Notifier) message to its root in this instance of the STP tree. notice of topology change. And how does the Root switch of this STP tree react to such a message? Of course, it sends to all-all-all TC (Topology Change). All switches that received a TC are known to reset the age-time MAC address tables. Firstly, this is how we get unicast-flood on the network, and secondly, on switches that perform routing to other networks, the induced problem occurs. They cannot route packets to a destination whose MAC address is not known, and what do they do? ARP request! Those. all interfaces on which the routing for a given VLAN is raised interrogate all the nodes of this network according to their ARP table, thereby specifying the correctness of the information stored in them. Well, we note for ourselves many more ARP-requests . Well, here's your ARP squall!
In fact, the 5th paragraph of our chronology is not exact and stingy with facts. There are a lot of fine points there, and generally speaking, everything is not quite so, although very close. But this was done deliberately, so that the meaning of this troc was clear to the maximum possible number of readers, and the volume did not go off scale in a few pages. In addition, even a brief description of the principles of STP and the causes of unicast-flood'a pull on two or three articles.
PS In general, where does Panasonic? Adjust the time on the MFP correctly, and there would be no problem. At night, all the users' machines are turned off, and there is no one on the network who would hear that very first packet. So there are no complaints about Panasonic, and there can not be. Partly to blame. But technically, it is generally a good idea to reboot the equipment at midnight exactly, it's a pity that you can not turn off or change the settings.
PS2 And then Cisco? Yes, and no complaints to Cisco. 2950s glands are weak, honestly struggling with a broadcasting storm, blocking the port. The 3560s no less honestly react to TC, causing flooding (I repeat, there are still many subtleties on this subject).
PS3 And here users? And nothing to do with! As it turned out, there are no users in those 2950s switches in this network segment. Simply, these switches are the only ones who respond to this problem. It is worth noting that they block the port not completely, but only on this VLAN, but all the other VLANs work without interruption. Those. and there was really no problem. But what a potential! But if there were users ... they would definitely say that the work of the network depends on the weather and rainfall in southern Zimbabwe. As you can see, you can explain everything, except what you don’t want to explain.
PS4 This is such a small victory in the fields of the invisible front ... only now it’s difficult to look at those Panasonic MFPs without a shudder ... ideas for life, damn it! =)
Source: https://habr.com/ru/post/50690/
All Articles