Laws for life
"Without fools"
 As before, I will try to refer to well-known interpretations of laws. I do not express my attitude, my opinion may not coincide with that published in the text.
As before, I will try to refer to well-known interpretations of laws. I do not express my attitude, my opinion may not coincide with that published in the text.This is a continuation of the attempt to talk about computer science and its laws and their imprint in everyday life. An imprint is a shadow, or an illusion in general - it's up to everyone. But if we ourselves invented all the sciences in order to know the world, it’s strange not to see nature in physics, to know the strength of the material and not to admire architecture, not to write a program as a novel ... laws of existence. The question is, what if one thinks and understands not like the other? Who is right and who is not, who is called a fool, and who is smart? Perhaps the one who knows more and has more information ... Perhaps this is so. But what is information that has become today the most important economic value in the world and marked the replacement of machine technology as the main production resource of the industrial era with knowledge and intelligence? Perhaps by answering this question, we can understand who is stupid and who is smart and why.
Around the 1949th year, Claude Elwood Shannon determined information through informational entropy - the uncertainty of the appearance of any symbol of the primary alphabet. For independent random events x with n possible states (from 1 to n) is calculated by the formula:
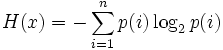
Shannon writes: "The value of H plays a central role in information theory as a measure of the amount of information, choice and uncertainty."
')
Informational entropy is a measure of unpredictability. The concepts of message entropy and redundancy naturally correspond to intuitive ideas about the measure of information. The more unpredictable the message (and the greater its entropy, because the less likelihood) - the more information it carries. Sensation is a rare event, the predictability of which is very low, and therefore its information value is great. Often information is called news — reports of events that have just occurred, about which we do not yet know. But if they tell us what happened the second and third time, the message redundancy becomes very great, its unpredictability will drop to zero.
Let the source of the message convey a sentence of a real language. Which character follows next depends on the characters already transferred. For example, in Russian after the symbol "b" can not go the symbol of a consonant sound. After two consecutive vowels "E", the third vowel "E" follows extremely rarely (for example, in the word "long-necked"). Thus, each next character is to some extent predetermined, so we can talk about the conditional entropy of the character.
According to Erokhin ("Information Theory. Part 1.") the redundancy of the Russian language is 73%, the redundancy of the French language is 71%, German - 66%. “Special languages” have the greatest redundancy, such as the language of “airport dispatchers” or the language of legal documents, the literary language is less redundant, and live speech is even less redundant. For example, for the Russian language: live speech: 72%; literary text: 76%; legal text: 83%. These data can be supplemented by comparing the Russian and French languages:
| Russian language | French | |
| Language in general | 72.6% | 70.6% |
| Colloquial speech | 72.0% | 68.4% |
| Literary text | 76.2% | 71.0% |
| Business text | 83.4% | 74.4% |
In principle, it is possible to build a completely non-redundant language, the so-called optimal code. In it, every random combination of letters would mean a meaningful word. But it would be impossible to use it. Here is what Alexander Karavaikin writes (“Some issues of non-electromagnetic cybernetics”): “Increasing information is equivalent to reducing entropy. This is one of the basic laws of the universe! For the transmission of information, one has to pay with increased entropy, while the system that received the information automatically reduces its “own” entropy.
What is the measure of information? According to Shannon, the basic unit of measurement of the amount of information is equal to the amount of information contained in the experiment, which has two equally probable outcomes. This is identical to the amount of information in the answer to the question, allowing answers “yes” or “no” and no other (that is, a quantity of information that allows you to unequivocally answer the question posed). Back in 1946, the American statistical scientist John Tukey suggested the name BIT (BIT is an abbreviation of BInary digiT), one of the main concepts of the 20th century. Tukey chose a bit to indicate one binary digit capable of taking the value 0 or 1, Shannon used the bit as a unit of information.
Only two answers "Yes" or "No", the third is not given. This fact can be considered a manifestation of the law of parity. Here is what Igor Mikhailovich Dmitrievsky says: “The law of conservation of parity is the symmetry between the left and the right. It turns out that not a single natural process allows one to poke a finger and say that it is left or it is right. Nature is indifferent, it does not give an answer. It is symmetrical. She knows the difference between the left and the right, but which of them is left and right is what we agree on. ” In his lectures, Dmitrievsky continued this thought: “... who is a fool and who is smart? It turns out for nature there is no value. "
“A fool is a dissident or an insensitive.”
Arkady and Boris Strugatsky
"Passion for cars"
Source: https://habr.com/ru/post/50643/
All Articles